
Scala概述 什麼是Scala Scala是一種多範式的編程語言,其設計的初衷是要集成面向對象編程和函數式編程的各種特性。Scala運行於Java平臺(Java虛擬機),並相容現有的Java程式。http://www.scala-lang.org 為什麼要學Scala 1、優雅:這是框架設計師第一 ...
Scala概述
什麼是Scala
Scala是一種多範式的編程語言,其設計的初衷是要集成面向對象編程和函數式編程的各種特性。Scala運行於Java平臺(Java虛擬機),並相容現有的Java程式。http://www.scala-lang.org
為什麼要學Scala
1、優雅:這是框架設計師第一個要考慮的問題,框架的用戶是應用開發程式員,API是否優雅直接影響用戶體驗。
2、速度快:Scala語言表達能力強,一行代碼抵得上Java多行,開發速度快;Scala是靜態編譯的,所以和JRuby,Groovy比起來速度會快很多。
3、能融合到Hadoop生態圈:Hadoop現在是大數據事實標準,Spark並不是要取代Hadoop,而是要完善Hadoop生態。JVM語言大部分可能會想到Java,但Java做出來的API太醜,或者想實現一個優雅的API太費勁。

Scala編譯器安裝
安裝JDK
因為Scala是運行在JVM平臺上的,所以安裝Scala之前要安裝JDK。
安裝Scala
Windows安裝Scala編譯器
訪問Scala官網http://www.scala-lang.org/下載Scala編譯器安裝包,目前最新版本是2.12.x,這裡下載scala-2.11.8.msi後點擊下一步就可以了(自動配置上環境變數)。也可以下載scala-2.11.8.zip,解壓後配置上環境變數就可以了。
Linux安裝Scala編譯器
下載Scala地址https://www.scala-lang.org/download/2.11.8.html
然後解壓Scala到指定目錄
tar -zxvf scala-2.11.8.tgz -C /usr/java
配置環境變數,將scala加入到PATH中
vi /etc/profile export JAVA_HOME=/usr/java/jdk1.8 export PATH=$PATH:$JAVA_HOME/bin:/usr/java/scala-2.11.8/bin
Scala開發工具安裝
目前Scala的開發工具主要有兩種:Eclipse和IDEA,這兩個開發工具都有相應的Scala插件,如果使用Eclipse,直接到Scala官網下載即可http://scala-ide.org/download/sdk.html。
由於IDEA的Scala插件更優秀,大多數Scala程式員都選擇IDEA,可以到http://www.jetbrains.com/idea/download/下載,點擊下一步安裝即可,安裝時如果有網路可以選擇線上安裝Scala插件。
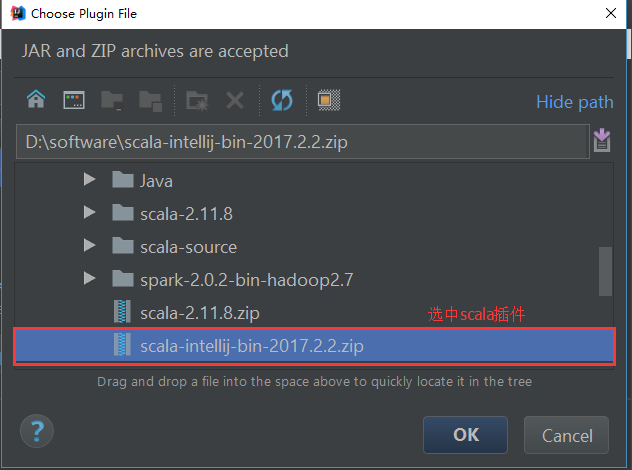
這裡我們使用離線安裝Scala插件:
1.安裝IDEA,點擊下一步即可。
2.下載IEDA的scala插件
插件地址: https://plugins.jetbrains.com/plugin/1347-scala
3.安裝Scala插件:Configure -> Plugins -> Install plugin from disk -> 選擇Scala插件 -> OK -> 重啟IDEA



Scala基礎
聲明變數
package cn.itcast.scala object VariableDemo { def main(args: Array[String]) { //使用val定義的變數值是不可變的,相當於java里用final修飾的變數 val i = 1 //使用var定義的變數是可變得,在Scala中鼓勵使用val var s = "hello" //Scala編譯器會自動推斷變數的類型,必要的時候可以指定類型 //變數名在前,類型在後 val str: String = "hello" } }
常用類型
Scala和Java一樣,有7種數值類型Byte、Char、Short、Int、Long、Float、Double類型和1個Boolean類型。
條件表達式
Scala的條件表達式比較簡潔,定義變數時加上if else判斷條件。例如:
package cn.itcast.scala object ConditionDemo { def main(args: Array[String]) { val x = 1 //判斷x的值,將結果賦給y val y = if (x > 0) 1 else -1 //列印y的值 println(y) //支持混合類型表達式 val z = if (x > 1) 1 else "error" //列印z的值 println(z) //如果缺失else,相當於if (x > 2) 1 else () val m = if (x > 2) 1 println(m) //在scala中每個表達式都有值,scala中有個Unit類,用作不返回任何結果的方法的結果類型,相當於Java中的void,Unit只有一個實例值,寫成()。 val n = if (x > 2) 1 else () println(n) //if和else if val k = if (x < 0) 0 else if (x >= 1) 1 else -1 println(k) } }
塊表達式
定義變數時用 {} 包含一系列表達式,其中塊的最後一個表達式的值就是塊的值。
package cn.itcast.scala object BlockExpressionDemo { def main(args: Array[String]) { val a = 10 val b = 20 //在scala中{}中包含一系列表達式,塊中最後一個表達式的值就是塊的值 //下麵就是一個塊表達式 val result = { val c=b-a val d=b-c d //塊中最後一個表達式的值 } //result的值就是塊表達式的結果 println(result) } }
迴圈
在scala中有for迴圈和while迴圈,用for迴圈比較多
for迴圈語法結構:for (i <- 表達式/數組/集合)
package cn.itcast.scala object ForDemo { def main(args: Array[String]) { //for(i <- 表達式),表達式1 to 10返回一個Range(區間) //每次迴圈將區間中的一個值賦給i for (i <- 1 to 10) println(i) //for(i <- 數組) val arr = Array("a", "b", "c") for (i <- arr) println(i) //高級for迴圈 //每個生成器都可以帶一個條件,註意:if前面沒有分號 for(i <- 1 to 3; j <- 1 to 3 if i != j) print((10 * i + j) + " ") println() //for推導式:如果for迴圈的迴圈體以yield開始,則該迴圈會構建出一個集合 //每次迭代生成集合中的一個值 val v = for (i <- 1 to 10) yield i * 10 println(v) } }
調用方法和函數
Scala中的+ - * / %等操作符的作用與Java一樣,位操作符 & | ^ >> <<也一樣。只是有一點特別的:這些操作符實際上是方法。例如:
a + b
是如下方法調用的簡寫:
a.+(b)
a 方法 b可以寫成 a.方法(b)
定義方法和函數
定義方法

方法的返回值類型可以不寫,編譯器可以自動推斷出來,但是對於遞歸函數,必須指定返回類型
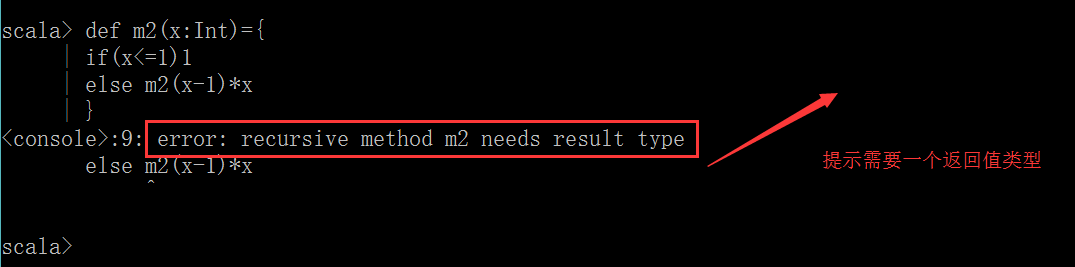
定義函數
方法和函數的區別
在函數式編程語言中,函數是“頭等公民”,它可以像任何其他數據類型一樣被傳遞和操作,函數是一個對象,繼承自FuctionN。
函數對象有apply、curried、toString、tupled這些方法。而方法不具有這些特性。
如果想把方法轉換成一個函數,可以用方法名跟上下劃線的方式。
案例:首先定義一個方法,再定義一個函數,然後將函數傳遞到方法裡面

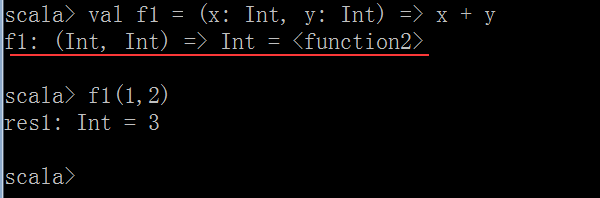
package cn.itcast.scala object MethodAndFunctionDemo { //定義一個方法 //方法m2參數要求是一個函數,函數的參數必須是兩個Int類型 //返回值類型也是Int類型 def m1(f: (Int, Int) => Int) : Int = { f(2, 6) } //定義一個函數f1,參數是兩個Int類型,返回值是一個Int類型 val f1 = (x: Int, y: Int) => x + y //再定義一個函數f2 val f2 = (m: Int, n: Int) => m * n //main方法 def main(args: Array[String]) { //調用m1方法,並傳入f1函數 val r1 = m1(f1) println(r1) //調用m1方法,並傳入f2函數 val r2 = m1(f2) println(r2) } }
將方法轉換成函數(神奇的下劃線)
將方法轉換成函數,只需要在方法的後面加上一個下劃線

數組、映射、元組、集合
數組
定長數組和變長數組
(1)定長數組定義格式:
val arr=new Array[T](數組長度)
val arr=Array(1,2,3,4,5)
(2)變長數組定義格式:
valarr = ArrayBuffer[T]()
註意需要導包:import scala.collection.mutable.ArrayBuffer
package cn.itcast.scala import scala.collection.mutable.ArrayBuffer object ArrayDemo { def main(args: Array[String]) { //初始化一個長度為8的定長數組,其所有元素均為0 val arr1 = new Array[Int](8) //直接列印定長數組,內容為數組的hashcode值 println(arr1) //將數組轉換成數組緩衝,就可以看到原數組中的內容了 //toBuffer會將數組轉換長數組緩衝 println(arr1.toBuffer) //註意:如果new,相當於調用了數組的apply方法,直接為數組賦值 //初始化一個長度為1的定長數組 val arr2 = Array[Int](10) println(arr2.toBuffer) //定義一個長度為3的定長數組 val arr3 = Array("hadoop", "storm", "spark") //使用()來訪問元素 println(arr3(2)) //變長數組(數組緩衝) //如果想使用數組緩衝,需要導入import scala.collection.mutable.ArrayBuffer包 val ab = ArrayBuffer[Int]() //向數組緩衝的尾部追加一個元素 //+=尾部追加元素 ab += 1 //追加多個元素 ab += (2, 3, 4, 5) //追加一個數組++= ab ++= Array(6, 7) //追加一個數組緩衝 ab ++= ArrayBuffer(8,9) //列印數組緩衝ab //在數組某個位置插入元素用insert,從某下標插入 ab.insert(0, -1, 0) //刪除數組某個位置的元素用remove 按照下標刪除 ab.remove(0) ab -=3 ab --=Array(1,2) println(ab) } }
遍曆數組
1.增強for迴圈
2.好用的until會生成腳標,0 until 10 包含0不包含10

package cn.itcast.scala object ForArrayDemo { def main(args: Array[String]) { //初始化一個數組 val arr = Array(1,2,3,4,5,6,7,8) //增強for迴圈 for(i <- arr) println(i) //好用的until會生成一個Range //reverse是將前面生成的Range反轉 for(i <- (0 until arr.length).reverse) println(arr(i)) } }
數組轉換
yield關鍵字將原始的數組進行轉換會產生一個新的數組,原始的數組不變

package cn.itcast.scala object ArrayYieldDemo { def main(args: Array[String]) { //定義一個數組 val arr = Array(1, 2, 3, 4, 5, 6, 7, 8, 9) //將偶數取出乘以10後再生成一個新的數組 val res = for (e <- arr if e % 2 == 0) yield e * 10 println(res.toBuffer) //更高級的寫法,用著更爽 //filter是過濾,接收一個返回值為boolean的函數 //map相當於將數組中的每一個元素取出來,應用傳進去的函數 val r = arr.filter(_ % 2 == 0).map(_ * 10) println(r.toBuffer) } }
數組常用演算法
在Scala中,數組上的某些方法對數組進行相應的操作非常方便!

映射
在Scala中,把哈希表這種數據結構叫做映射。
構建映射
(1)構建映射格式
1、val map=Map(鍵 -> 值,鍵 -> 值....)
2、利用元組構建 val map=Map((鍵,值),(鍵,值),(鍵,值)....)

獲取和修改映射中的值
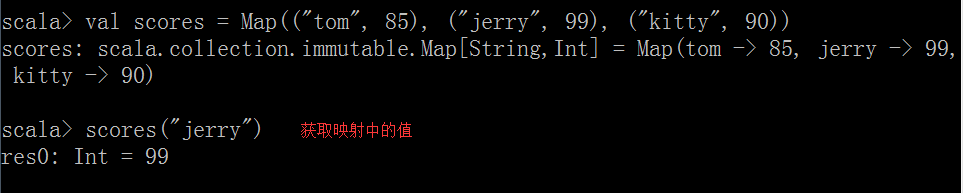
(1)獲取映射中的值:
值=map(鍵)
好用的getOrElse

註意:在Scala中,有兩種Map,一個是immutable包下的Map,該Map中的內容不可變;另一個是mutable包下的Map,該Map中的內容可變
例子:

註意:通常我們在創建一個集合是會用val這個關鍵字修飾一個變數(相當於java中的final),那麼就意味著該變數的引用不可變,該引用中的內容是不是可變,取決於這個引用指向的集合的類型
元組
映射是K/V對偶的集合,對偶是元組的最簡單形式,元組可以裝著多個不同類型的值。
創建元組
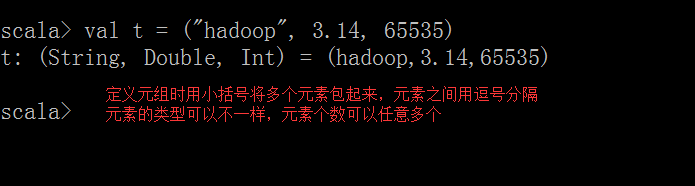
(1)元組是不同類型的值的聚集;對偶是最簡單的元組。
(2)元組表示通過將不同的值用小括弧括起來,即表示元組。
創建元組格式:
val tuple=(元素,元素...)
獲取元組中的值
(1) 獲取元組中的值格式:
使用下劃線加腳標 ,例如 t._1 t._2 t._3
註意:元組中的元素腳標是從1開始的

將對偶的集合轉換成映射
將對偶的集合轉換成映射:
調用其toMap 方法

拉鏈操作
1.使用zip命令可以將多個值綁定在一起
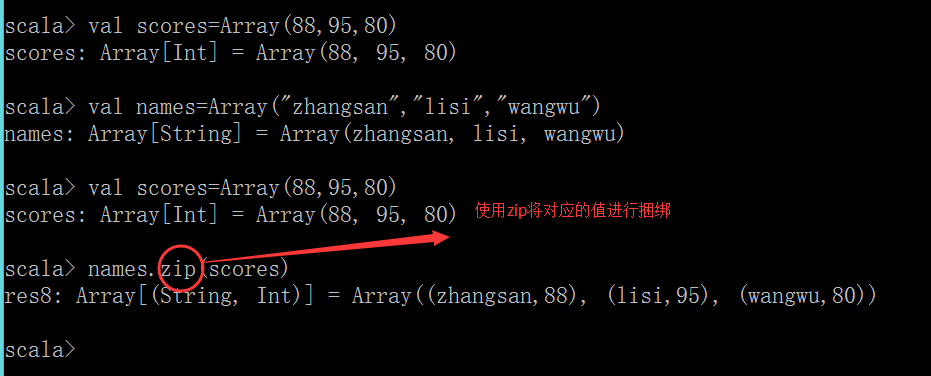
註意:如果兩個數組的元素個數不一致,拉鏈操作後生成的數組的長度為較小的那個數組的元素個數
2.如果其中一個元素的個數比較少,可以使用zipAll用預設的元素填充

集合
Scala的集合有三大類:序列Seq、Set、映射Map,所有的集合都擴展自Iterable特質,在Scala中集合有可變(mutable)和不可變(immutable)兩種類型,immutable類型的集合初始化後就不能改變了(註意與val修飾的變數進行區別)。
List
(1)不可變的序列 import scala.collection.immutable._
在Scala中列表要麼為空(Nil表示空列表) 要麼是一個head元素加上一個tail列表。
9 :: List(5, 2) :: 操作符是將給定的頭和尾創建一個新的列表
註意::: 操作符是右結合的,如9 :: 5 :: 2 :: Nil相當於 9 :: (5 :: (2 :: Nil))
list常用的操作符:
+: (elem: A): List[A] 在列表的頭部添加一個元素
:: (x: A): List[A] 在列表的頭部添加一個元素
:+ (elem: A): List[A] 在列表的尾部添加一個元素
++[B](that: GenTraversableOnce[B]): List[B] 從列表的尾部添加 另外一個列表
::: (prefix: List[A]): List[A] 在列表的頭部添加另外一個列表
val left = List(1,2,3)
val right = List(4,5,6)
//以下操作等價
left ++ right // List(1,2,3,4,5,6)
right.:::(left) // List(1,2,3,4,5,6)
//以下操作等價
0 +: left //List(0,1,2,3)
left.+:(0) //List(0,1,2,3)
//以下操作等價
left :+ 4 //List(1,2,3,4)
left.:+(4) //List(1,2,3,4)
//以下操作等價
0 :: left //List(0,1,2,3)
left.::(0) //List(0,1,2,3)
例子:
package cn.itcast.collect /** * 不可變List集合操作 */ object ImmutListDemo { def main(args: Array[String]) { //創建一個不可變的集合 val lst1 = List(1,2,3) //補充:另一種定義list方法 val other_lst=2::Nil //獲取集合的第一個元素 val first=lst1.head //獲取集合中除第一個元素外的其他元素集合, val tail=lst1.tail //補充:其中如果 List 中只有一個元素,那麼它的 head 就是這個元素,它的 tail 就是 Nil; println(other_lst.head+"----"+other_lst.tail) //將0插入到lst1的前面生成一個新的List val lst2 = 0 :: lst1 val lst3 = lst1.::(0) val lst4 = 0 +: lst1 val lst5 = lst1.+:(0) //將一個元素添加到lst1的後面產生一個新的集合 val lst6 = lst1 :+ 3 val lst0 = List(4,5,6) //將2個list合併成一個新的List val lst7 = lst1 ++ lst0 //將lst0插入到lst1前面生成一個新的集合 val lst8 = lst1 ++: lst0 //將lst0插入到lst1前面生成一個新的集合 val lst9 = lst1.:::(lst0) println(other_lst) println(lst1) println(first) println(tail) println(lst2) println(lst3) println(lst4) println(lst5) println(lst6) println(lst7) println(lst8) println(lst9) } }
(2)可變的序列 import scala.collection.mutable._
package cn.itcast.collect import scala.collection.mutable.ListBuffer object MutListDemo extends App{ //構建一個可變列表,初始有3個元素1,2,3 val lst0 = ListBuffer[Int](1,2,3) //創建一個空的可變列表 val lst1 = new ListBuffer[Int] //向lst1中追加元素,註意:沒有生成新的集合 lst1 += 4 lst1.append(5) //將lst1中的元素添加到lst0中, 註意:沒有生成新的集合 lst0 ++= lst1 //將lst0和lst1合併成一個新的ListBuffer 註意:生成了一個集合 val lst2= lst0 ++ lst1 //將元素追加到lst0的後面生成一個新的集合 val lst3 = lst0 :+ 5 //刪除元素,註意:沒有生成新的集合 val lst4 = ListBuffer[Int](1,2,3,4,5) lst4 -= 5 //刪除一個集合列表,生成了一個新的集合 val lst5=lst4--List(1,2) //把可變list 轉換成不可變的list 直接加上toList val lst6=lst5.toList //把可變list 轉變數組用toArray val lst7=lst5.toArray println(lst0) println(lst1) println(lst2) println(lst3) println(lst4) println(lst5) println(lst6) println(lst7) }
Set
(1)不可變的Set import scala.collection.immutable._
Set代表一個沒有重覆元素的集合;將重覆元素加入Set是沒有用的,而且 Set 是不保證插入順序的,即 Set 中的元素是亂序的。
定義:val set=Set(元素,元素,.....)
//定義一個不可變的Set集合 scala> val set =Set(1,2,3,4,5,6,7) set: scala.collection.immutable.Set[Int] = Set(5, 1, 6, 2, 7, 3, 4) //元素個數 scala> set.size res0: Int = 7 //取集合最小值 scala> set.min res1: Int = 1 //取集合最大值 scala> set.max res2: Int = 7 //將元素和set1合併生成一個新的set,原有set不變 scala> set + 8 res3: scala.collection.immutable.Set[Int] = Set(5, 1, 6, 2, 7, 3, 8, 4) scala> val set1=Set(7,8,9) set1: scala.collection.immutable.Set[Int] = Set(7, 8, 9) //兩個集合的交集 scala> set & set1 res4: scala.collection.immutable.Set[Int] = Set(7) //兩個集合的並集 scala> set ++ set1 res5: scala.collection.immutable.Set[Int] = Set(5, 1, 6, 9, 2, 7, 3, 8, 4) //在第一個set基礎上去掉第二個set中存在的元素 scala> set -- set1 res6: scala.collection.immutable.Set[Int] = Set(5, 1, 6, 2, 3, 4) //返回第一個不同於第二個set的元素集合 scala> set &~ set1 res7: scala.collection.immutable.Set[Int] = Set(5, 1, 6, 2, 3, 4) //計算符合條件的元素個數 scala> set.count(_ >5) res8: Int = 2 /返回第一個不同於第二個的元素集合 scala> set.diff(set1) res9: scala.collection.immutable.Set[Int] = Set(5, 1, 6, 2, 3, 4) /返回第一個不同於第二個的元素集合 scala> set1.diff(set) res10: scala.collection.immutable.Set[Int] = Set(8, 9) //取子set(2,5為元素位置, 從0開始,包含頭不包含尾) scala> set.slice(2,5) res11: scala.collection.immutable.Set[Int] = Set(6, 2, 7) //迭代所有的子set,取指定的個數組合 scala> set1.subsets(2).foreach(x=>println(x)) Set(7, 8) Set(7, 9) Set(8, 9)
(2)可變的Set import scala.collection.mutable._
//導入包 scala> import scala.collection.mutable import scala.collection.mutable //定義一個可變的Set scala> val set1=new HashSet[Int]() set1: scala.collection.mutable.HashSet[Int] = Set() //添加元素 scala> set1 += 1 res1: set1.type = Set(1) //添加元素 add等價於+= scala> set1.add(2) res2: Boolean = true scala> set1 res3: scala.collection.mutable.HashSet[Int] = Set(1, 2) //向集合中添加元素集合 scala> set1 ++=Set(1,4,5) res5: set1.type = Set(1, 5, 2, 4) //刪除一個元素 scala> set1 -=5 res6: set1.type = Set(1, 2, 4) //刪除一個元素 scala> set1.remove(1) res7: Boolean = true scala> set1 res8: scala.collection.mutable.HashSet[Int] = Set(2, 4)
Map
(1)不可變的Map import scala.collection.immutable._
定義Map集合 1.val map=Map(鍵 -> 值 , 鍵 -> 值...) 2.利用元組構建 val map=Map((鍵,值), (鍵,值) , (鍵,值)....) 展現形式: val map = Map(“zhangsan”->30,”lisi”->40) val map = Map((“zhangsan”,30),(“lisi”,40)) 3.操作map集合 獲取值: 值=map(鍵) 原則:通過先獲取鍵,在獲取鍵對應值。 4.遍歷map集合 scala> val imap=Map("zhangsan" -> 20,"lisi" ->30) imap: scala.collection.immutable.Map[String,Int] = Map(zhangsan -> 20, lisi -> 30) //方法一:顯示所有的key scala> imap.keys res0: Iterable[String] = Set(zhangsan, lisi) //方法二:顯示所有的key scala> imap.keySet res1: scala.collection.immutable.Set[String] = Set(zhangsan, lisi) //通過key獲取value scala> imap("lisi") res2: Int = 30 //通過key獲取value 有key對應的值則返回,沒有就返回預設值0, scala> imap.getOrElse("zhangsan",0) res4: Int = 20 //沒有對應的key,返回預設0 scala> imap.getOrElse("zhangsan1",0) res5: Int = 0 //由於是不可變map,故不能向其添加、刪除、修改鍵值對
(2)可變的Map import scala.collection.mutable._
//導包 import scala.collection.mutable //聲明一個可變集合 scala> val user =mutable.HashMap("zhangsan"->50,"lisi" -> 100) user: scala.collection.mutable.HashMap[String,Int] = Map(lisi -> 100, zhangsan -> 50) //添加鍵值對 scala> user +=("wangwu" -> 30) res0: user.type = Map(lisi -> 100, zhangsan -> 50, wangwu -> 30) //添加多個鍵值對 scala> user += ("zhangsan0" -> 30,"lisi0" -> 20) res1: user.type = Map(zhangsan0 -> 30, lisi -> 100, zhangsan -> 50, lisi0 -> 20,wangwu -> 30) //方法一:顯示所有的key scala> user.keys res2: Iterable[String] = Set(zhangsan0, lisi, zhangsan, lisi0, wangwu) //方法二:顯示所有的key scala> user.keySet res3: scala.collection.Set[String] = Set(zhangsan0, lisi, zhangsan, lisi0, wangwu) //通過key獲取value scala> user("zhangsan") res4: Int = 50 //通過key獲取value 有key對應的值則返回,沒有就返回預設值0, scala> user.getOrElse("zhangsan",0) res5: Int = 50 //沒有對應的key,返回預設0 scala> user.getOrElse("zhangsan1",0) res6: Int = 0 //更新鍵值對 scala> user("zhangsan") = 55 scala> user("zhangsan") res8: Int = 55 //更新多個鍵值對 scala> user += ("zhangsan" -> 60, "lisi" -> 50) res9: user.type = Map(zhangsan0 -> 30, lisi -> 50, zhangsan -> 60, lisi0 -> 20,wangwu -> 30) //刪除key scala> user -=("zhangsan") res14: user.type = Map(zhangsan0 -> 30, lisi -> 50, lisi0 -> 20, wangwu -> 30) //刪除key scala>user.remove("zhangsan0") //遍歷map 方法一:通過key值 scala> for(x<- user.keys) println(x+" -> "+user(x)) lisi -> 50 lisi0 -> 20 wangwu -> 30 //遍歷map 方法二:模式匹配 scala> for((x,y) <- user) println(x+" -> "+y) lisi -> 50 lisi0 -> 20 wangwu -> 30 //遍歷map 方法三:通過foreach scala> user.foreach{case (x,y) => println(x+" -> "+y)} lisi -> 50 lisi0 -> 20 wangwu -> 30
類、對象、繼承、特質
Scala的類與Java、C++的類比起來更簡潔,學完之後你會更愛Scala!!!
類
類的定義
package cn.itcast.class_demo /** * 在Scala中,類並不用聲明為public類型的。 * Scala源文件中可以包含多個類,所有這些類都具有共有可見性。 */ class Person { //用val修飾的變數是可讀屬性,有getter但沒有setter(相當與Java中用final修飾的變數) val id="9527" //用var修飾的變數都既有getter,又有setter var age:Int=18 //類私有欄位,只能在類的內部使用或者伴生對象中訪問 private var name : String = "唐伯虎" //類私有欄位,訪問許可權更加嚴格的,該欄位在當前類中被訪問 //在伴生對象裡面也不可以訪問 private[this] var pet = "小強" } //伴生對象(這個名字和類名相同,叫伴生對象) object Person{ def main(args: Array[String]): Unit = { val p=new Person //如果是下麵的修改,發現下麵有紅線,說明val類型的不支持重新賦值,但是可以獲取到值 //p.id = "123" println(p.id) //列印age println(p.age) //列印name,伴生對象中可以在訪問private變數 println(p.name) //由於pet欄位用private[this]修飾,伴生對象中訪問不到pet變數 //p.pet(訪問不到) } }
構造器
Scala中的每個類都有主構造器,主構造器的參數直接放置類名後面,與類交織在一起。
註意:主構造器會執行類定義中的所有語句。
package cn.itcast.class_demo /** *每個類都有主構造器,主構造器的參數直接放置類名後面,與類交織在一起 */ class Student(val name:String,var age:Int) { //主構造器會執行類定義的所有語句 println("執行主構造器") private var gender="male" def this(name:String,age:Int,gender:String){ //每個輔助構造器執行必須以主構造器或者其他輔助構造器的調用開始 this(name,age) println("執行輔助構造器") this.gender=gender } } object Student { def main(args: Array[String]): Unit = { val s1=new Student("zhangsan",20) val s2=new Student("zhangsan",20,"female") } }
Scala面向對象編程之對象
Scala中的object
- object 相當於 class 的單個實例,通常在裡面放一些靜態的 field 或者 method;
在Scala中沒有靜態方法和靜態欄位,但是可以使用object這個語法結構來達到同樣的目的。
object作用:
1.存放工具方法和常量
2.高效共用單個不可變的實例
3.單例模式
- 舉例說明:
- 如果有一個class文件,還有一個與class同名的object文件,那麼就稱這個object是class的伴生對象,class是object的伴生類;
- 伴生類和伴生對象必須存放在一個.scala文件中;
- 伴生類和伴生對象的最大特點是,可以相互訪問;
- 舉例說明:
package cn.itcast.object_demo import scala.collection.mutable.ArrayBuffer class Session{} object SessionFactory{ //該部分相當於java中的靜態塊 val session=new Session //在object中的方法相當於java中的靜態方法 def getSession(): Session ={ session } } object SingletonDemo { def main(args: Array[String]) { //單例對象,不需要new,用【單例對象名稱.方法】調用對象中的方法 val session1 = SessionFactory.getSession() println(session1) //單例對象,不需要new,用【單例對象名稱.變數】調用對象中成員變數 val session2=SessionFactory.session println(session2) } }
Scala中的伴生對象
package cn.itcast.object_demo //伴生類 class Dog { val id = 1 private var name = "itcast" def printName(): Unit ={ //在Dog類中可以訪問伴生對象Dog的私有屬性 println(Dog.CONSTANT + name ) } } //伴生對象 object Dog { //伴生對象中的私有屬性 private val CONSTANT = "汪汪汪 : " def main(args: Array[String]) { val p = new Dog //訪問私有的欄位name p.name = "123" p.printName() } } //執行結果 汪汪汪 : 123
Scala中的apply方法
- object 中非常重要的一個特殊方法,就是apply方法;
- apply方法通常是在伴生對象中實現的,其目的是,通過伴生類的構造函數功能,來實現伴生對象的構造函數功能;
- 通常我們會在類的伴生對象中定義apply方法,當遇到類名(參數1,...參數n)時apply方法會被調用;
- 在創建伴生對象或伴生類的對象時,通常不會使用new class/class() 的方式,而是直接使用 class(),隱式的調用伴生對象的 apply 方法,這樣會讓對象創建的更加簡潔;
- 舉例說明:
package cn.itcast.object_demo /** * Array 類的伴生對象中,就實現了可接收變長參數的 apply 方法, * 並通過創建一個 Array 類的實例化對象,實現了伴生對象的構造函數功能 */ // 指定 T 泛型的數據類型,並使用變長參數 xs 接收傳參,返回 Array[T] 數組 // 通過 new 關鍵字創建 xs.length 長的 Array 數組 // 其實就是調用Array伴生類的 constructor進行 Array對象的初始化 // def apply[T: ClassTag](xs: T*): Array[T] = { // val array = new Array[T](xs.length) // var i = 0 // for (x <- xs.iterator) { array(i) = x; i += 1 } // array // } object ApplyDemo { def main(args: Array[String]) { //調用了Array伴生對象的apply方法 //def apply(x: Int, xs: Int*): Array[Int] //arr1中只有一個元素5 val arr1 = Array(5) //new了一個長度為5的array,數組裡麵包含5個null var arr2 = new Array(5) println(arr1.toBuffer) } }
Scala中的main方法
- 同Java一樣,如果要運行一個程式,必須要編寫一個包含 main 方法的類;
- 在 Scala 中,也必須要有一個 main 方法,作為入口;
- Scala 中的 main 方法定義為 def main(args: Array[String]),而且必須定義在 object 中;
- 除了自己實現 main 方法之外,還可以繼承 App Trait,然後,將需要寫在 main 方法中運行的代碼,直接作為 object 的 constructor 代碼即可,而且還可以使用 args 接收傳入的參數;
- 案例說明:
package cn.itcast.object_demo //1.在object中定義main方法 object Main_Demo1 { def main(args: Array[String]) { if(args.length > 0){ println("Hello, " + args(0)) }else{ println("Hello World!") } } } //2.使用繼承App Trait ,將需要寫在 main 方法中運行的代碼 // 直接作為 object 的 constructor 代碼即可, // 而且還可以使用 args 接收傳入的參數。 object Main_Demo2 extends App{ if(args.length > 0){ println("Hello, " + args(0)) }else{ println("Hello World!") } }
Scala面向對象編程之繼承
Scala中繼承(extends)的概念
- Scala 中,讓子類繼承父類,與 Java 一樣,也是使用 extends 關鍵字;
- 繼承就代表,子類可繼承父類的 field 和 method ,然後子類還可以在自己的內部實現父類沒有的,子類特有的 field 和method,使用繼承可以有效復用代碼;
- 子類可以覆蓋父類的 field 和 method,但是如果父類用 final 修飾,或者 field 和 method 用 final 修飾,則該類是無法被繼承的,或者 field 和 method 是無法被覆蓋的。
- private 修飾的 field 和 method 不可以被子類繼承,只能在類的內部使用;
- field 必須要被定義成 val 的形式才能被繼承,並且還要使用 override 關鍵字。 因為 var 修飾的 field 是可變的,在子類中可直接引用被賦值,不需要被繼承;即 val 修飾的才允許被繼承,var 修飾的只允許被引用。繼承就是改變、覆蓋的意思。
- Java 中的訪問控制許可權,同樣適用於 Scala
|
|
類內部 |
本包 |
子類 |
外部包 |
|
public |
√ |
√ |
√ |
√ |
|
protected |
√ |
√ |
√ |
× |
|
default |
√ |
√ |
× |
× |
|
private |
√ |
× |
× |
× |
- 舉例說明:
package cn.itcast.extends_demo class Person { val name="super" def getName=this.name } class Student extends Person{ //繼承加上關鍵字 override val name="sub" //子類可以定義自己的field和method val score="A" def getScore=this.score }
Scala中override 和 super 關鍵字
- Scala中,如果子類要覆蓋父類中的一個非抽象方法,必須要使用 override 關鍵字;子類可以覆蓋父類的 val 修飾的field,只要在子類中使用 override 關鍵字即可。
- override 關鍵字可以幫助開發者儘早的發現代碼中的錯誤,比如, override 修飾的父類方法的方法名拼寫錯誤。
- 此外,在子類覆蓋父類方法後,如果

