
[TOC] 3.1 配置各節點SSH無密鑰登錄 【操作目的】 Hadoop的進程間通信使用SSH(Secure Shell)方式。SSH是一種通信加密協議,使用非對稱加密方式,可以避免網路竊聽。為了使Hadoop各節點之間能夠無密碼相互訪問,需要配置各節點的SSH無秘鑰登錄。 【登錄原理】 SSH無 ...
目錄
3.1 配置各節點SSH無密鑰登錄
【操作目的】
Hadoop的進程間通信使用SSH(Secure Shell)方式。SSH是一種通信加密協議,使用非對稱加密方式,可以避免網路竊聽。為了使Hadoop各節點之間能夠無密碼相互訪問,需要配置各節點的SSH無秘鑰登錄。
【登錄原理】
SSH無密鑰登錄的原理如下圖:
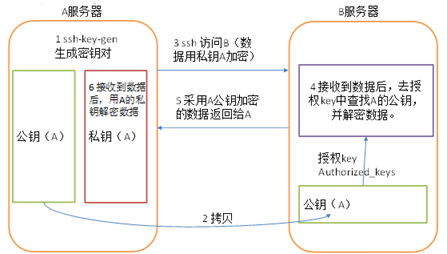
【操作步驟】
方法一:
1.將各節點的秘鑰加入到同一個授權文件中
無秘鑰登錄的原理是,登錄節點的秘鑰信息是否存在於被登錄節點的授權文件中,如果存在,則允許登錄。為了所有節點之間 能夠相互登錄,首先我們需要將各個節點的秘鑰加入到同一個授權文件中,步驟如下:
(1)在centos01節點中,生成秘鑰文件,並將秘鑰信息加入到授權文件中。所需命令如下:
cd ~/.ssh/ # 若沒有該目錄,請先執行一次ssh localhost
ssh-keygen -t rsa # 生成秘鑰文件,會有提示,都按回車就可以
cat ./id_rsa.pub >> ./authorized_keys # 將秘鑰內容加入到授權文件中(2)在centos02節點中,生成秘鑰文件,並將秘鑰文件遠程拷貝到centos01節點的相同目錄,且重命名為id_rsa.pub.centos02。相關命令如下:
cd ~/.ssh/ # 若沒有該目錄,請先執行一次ssh localhost
ssh-keygen -t rsa # 生成秘鑰文件,會有提示,都按回車就可以
scp ~/.ssh/id_rsa.pub hadoop@centos01:~/.ssh/id_rsa.pub.centos02 #遠程拷貝(3)在centos03節點中,執行與centos02相同的操作(生成秘鑰文件,並將秘鑰文件遠程拷貝到centos01節點的相同目錄,且重命名為id_rsa.pub.centos03)。相關命令如下:
cd ~/.ssh/ # 若沒有該目錄,請先執行一次ssh localhost
ssh-keygen -t rsa # 生成秘鑰文件,會有提示,都按回車就可以
scp ~/.ssh/id_rsa.pub hadoop@centos01:~/.ssh/id_rsa.pub.centos03 #遠程拷貝(4)回到centos01節點,將centos02和centos03節點的秘鑰文件信息都加入到授權文件中。相關命令如下:
cat ./id_rsa.pub.centos02 >> ./authorized_keys #將centos02的秘鑰加入到授權文件中
cat ./id_rsa.pub.centos03 >> ./authorized_keys #將centos03的秘鑰加入到授權文件中2.拷貝授權文件到各個節點
將centos01節點中的授權文件遠程拷貝到其它節點,命令如下:
scp ~/.ssh/authorized_keys hadoop@centos02:~/.ssh/
scp ~/.ssh/authorized_keys hadoop@centos03:~/.ssh/3.測試無秘鑰登錄
接下來可以測試從centos01無秘鑰登錄到centos02,命令如下:
ssh centos02如果登錄失敗,可能的原因是授權文件authorized_keys許可權過高,分別在每個節點上執行如下命令,更改文件許可權:
chmod 700 ~/.ssh #只有擁有者有讀寫許可權。
chmod 600 ~/.ssh/authorized_keys #只有擁有者有讀、寫、執行許可權。到此,各節點的SSH無秘鑰登錄就配置完成了。
方法二:
ssh-copy-id命令可以把本地主機的公鑰複製並追加到遠程主機的authorized_keys文件中,ssh-copy-id命令也會給遠程主機的用戶主目錄(home)和~/.ssh, 和~/.ssh/authorized_keys設置合適的許可權。
(1)分別在三個節點中執行以下命令,生成秘鑰文件:
cd ~/.ssh/ # 若沒有該目錄,請先執行一次ssh localhost
ssh-keygen -t rsa # 生成秘鑰文件,會有提示,都按回車就可以(2)分別在三個節點中執行以下命令,將公鑰信息拷貝並追加到對方節點的授權文件authorized_keys中:
ssh-copy-id centos01
ssh-copy-id centos02
ssh-copy-id centos03最後測試SSH無秘鑰登錄。
3.2 搭建Hadoop集群
【操作目的】
本例的搭建思路是,在節點centos01中安裝Hadoop並修改配置文件,然後將配置好的Hadoop安裝文件遠程拷貝到集群中其它節點。各節點的角色分配如下表:
| 節點 | 角色 |
|---|---|
| centos01 | NameNode SecondaryNameNode DataNode ResourceManager NodeManager |
| centos02 | DataNode NodeManager |
| centos03 | DataNode NodeManager |
【操作步驟】
Hadoop集群搭建的操作步驟如下:
1.上傳Hadoop並解壓
在centos01節點中,將Hadoop安裝文件hadoop-2.7.1.tar.gz上傳到/opt/softwares/目錄,進入該目錄,解壓hadoop到/opt/modules/,命令如下:
[hadoop@centos01 ~]$ cd /opt/softwares/
[hadoop@centos01 softwares]$ tar -zxf hadoop-2.7.1.tar.gz -C /opt/modules/2.配置Hadoop環境變數
Hadoop所有的配置文件都存在於安裝目錄下的/etc/hadoop中,修改如下配置文件:
hadoop-env.sh
mapred-env.sh
yarn-env.sh三個文件分別加入JAVA_HOME環境變數,如下:
export JAVA_HOME=/opt/modules/jdk1.8.0_1013.配置HDFS
(1)修改配置文件core-site.xml,加入以下內容:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://centos01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/opt/modules/hadoop-2.7.1/tmp</value>
</property>
</configuration>參數解析:
fs.defaultFS:HDFS的預設訪問路徑。
hadoop.tmp.dir:Hadoop臨時文件的存放目錄,可自定義。
(2)修改配置文件hdfs-site.xml,加入以下內容:
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property><!--不檢查用戶許可權-->
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/modules/hadoop-2.7.1/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/modules/hadoop-2.7.1/tmp/dfs/data</value>
</property>
</configuration>參數解析:
dfs.replication:文件在HDFS系統中的副本數。
dfs.namenode.name.dir:HDFS名稱節點數據在本地文件系統的存放位置。
dfs.datanode.data.dir:HDFS數據節點數據在本地文件系統的存放位置。
(3)修改slaves文件,配置DataNode節點。slaves文件原本無任何內容,需要將所有DataNode節點的主機名都添加進去,每個主機名占一整行。本例中,DataNode為三個節點,因此slaves文件的內容如下:
centos01
centos02
centos034.配置YARN
(1)重命名mapred-site.xml.template文件為mapred-site.xml,修改mapred-site.xml文件,添加以下內容,指定使用yarn來運行mapreduce任務。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>(2)修改yarn-site.xml文件,添加以下內容:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>參數解析:
yarn.nodemanager.aux-services :NodeManager上運行的附屬服務。需配置成mapreduce_shuffle才可運行MapReduce程式。
5.拷貝Hadoop安裝文件到其它主機
在centos01節點上,將配置好的整個Hadoop安裝目錄,拷貝到其它節點(centos02與centos03)。命令如下:
[hadoop@centos01 modules]$ scp -r hadoop-2.7.1/ hadoop@centos02:/opt/modules/
[hadoop@centos01 modules]$ scp -r hadoop-2.7.1/ hadoop@centos03:/opt/modules/6.啟動Hadoop
啟動Hadoop之前,需要先格式化NameNode。格式化NameNode可以初始化HDFS文件系統的一些目錄和文件,在centos01節點上執行以下命令,進行格式化操作:
hadoop namenode -format格式化成功後,在centos01節點上執行以下命令,啟動Hadoop集群:
start-all.sh也可以執行start-dfs.sh和start-yarn.sh分別啟動HDFS和YARN集群。
7.查看各節點啟動進程
集群啟動成功後,分別在各個節點上執行jps命令,查看啟動的Java進程。可以看到,各節點的Java進程如下:
centos01節點的進程:
[hadoop@centos01 hadoop-2.7.1]$ jps
13524 SecondaryNameNode
13813 NodeManager
13351 DataNode
13208 NameNode
13688 ResourceManager
14091 Jpscentos02節點的進程:
[hadoop@centos02 ~]$ jps
7585 NodeManager
7477 DataNode
7789 Jpscentos03節點的進程:
[hadoop@centos03 ~]$ jps
8308 Jps
8104 NodeManager
7996 DataNode8.測試HDFS
在centos01節點的HDFS根目錄創建文件夾input,並將Hadoop安裝目錄下的文件README.txt上傳到新建的input文件夾中。命令如下:
hdfs dfs -mkdir /input
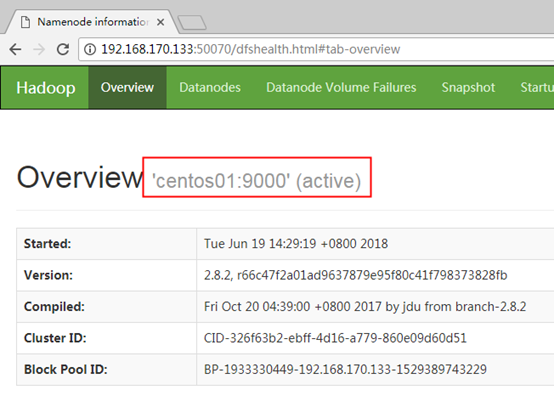
hdfs dfs -put /opt/modules/hadoop-2.7.1/README.txt /input訪問網址:http://192.168.170.133:50070 可以查看HDFS的NameNode信息,界面如下:
9.測試MapReduce
在centos01節點中執行以下命令,運行Hadoop自帶的MapReduce單詞計數程式,統計/input文件夾中的所有文件的單詞數量:
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar /input /output統計完成後,執行以下命令,查看MapReduce執行結果:
hdfs dfs -cat /output/*如果以上測試沒有問題,則Hadoop集群搭建成功。
原創文章,轉載請註明出處!!


