
1 資料庫事務處理 一個資料庫事務通常包含對資料庫進行讀或寫的一個操作序列 . 當一個事務被提交給了DBMS(資料庫管理系統),則DBMS需要確保該事務中的所有操作都成功完成且其結果被永久保存在資料庫中,如果事務中有的操作沒有成功完成,則事務中的所有操作都需要被回滾. 1 為資料庫提供了一個從失敗恢 ...
1 資料庫事務處理
一個資料庫事務通常包含對資料庫進行讀或寫的一個操作序列 . 當一個事務被提交給了DBMS(資料庫管理系統),則DBMS需要確保該事務中的所有操作都成功完成且其結果被永久保存在資料庫中,如果事務中有的操作沒有成功完成,則事務中的所有操作都需要被回滾.
1 為資料庫提供了一個從失敗恢復到正常狀態的方法 , 同時提供了資料庫在異常狀態下仍然能保持一致性方法
2 當多個應用程式併發訪問資料庫時,可以在這些應用程式之間提供隔離方法,以防止彼此的操作互相干擾
事務具有的特性:
原子性(Atomicity):事務作為一個整體被執行,對資料庫的操作要麼全部被執行,要麼都不執行。
一致性(Consistency):事務應確保資料庫的狀態從一個一致狀態轉變為另一個一致狀態。一致狀態的含義是資料庫中的數據應滿足完整性約束。
隔離性(Isolation):多個事務併發執行時,一個事務的執行不應影響其他事務的執行。
持久性(Durability):一個事務一旦提交,他對資料庫的修改應該永久保存在資料庫中。
爬蟲資料庫操作封裝
import pymysql
'''爬蟲資料庫存儲'''
class Sql(object):
def __init__(self):
#創建連接
self.conn = pymysql.connect(host='xxx', port=3306, user= 'root', passwd = 'xxx', database = 'douban',charset = 'utf8')
#創建游標
self.cursor = self.conn.cursor()
#執行sql清空Movie
self.cursor.execute("truncate table Movie")
self.conn.commit()
def process_item(self, item, spider):
try:
#執行sql插入語句
self.cursor.execute("insert into Movie (name,movieInfo,star,quote) VALUES (%s,%s,%s,%s)",(item['name'], item['movieInfo'], item['star'], item['quote']))
#提交數據
self.conn.commit()
except pymysql.Error:
print("Error%s,%s,%s,%s" % (item['name'], item['movieInfo'], item['star'], item['quote']))
return item
def close_spider(self, spider):
#關閉
self.cursor.close()
self.conn.close()2 資料庫索引
1 索引概述
索引(Index)是幫助MySQL高效獲取數據的數據結構, 資料庫查詢是最重要,最基本功能之一.
常見的查詢演算法:
>1 順序查找 , 數據量大時,肯定不行
>
>2 二分查找, 但要求數據有序
>
>3 二叉樹查找,只能應用在二叉樹上
>
>4 為了適應各種複雜的數據結構, 資料庫系統還維護著滿足特定查找演算法的數據結構,這些數據結構以某種方式引用(指向)數據,這樣就可以在這些數據結構上實現高級查找演算法。這種數據結構,就是索引索引方式
2 聚焦索引與非聚焦索引
聚焦索引
目前大部分的資料庫系統及文件系統都是採用B-Tree與 B+Tree實現的即平衡樹的數據結構.
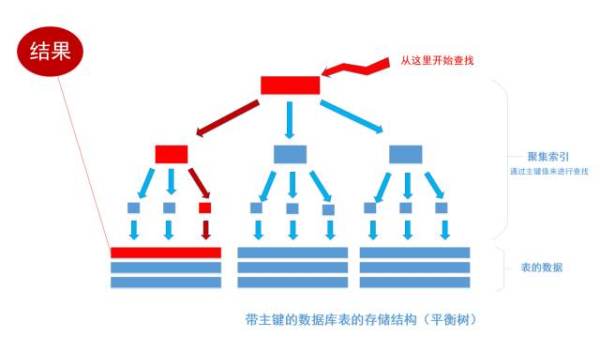
我們平時建表的時候都會為表加上主鍵, 在某些關係資料庫中, 如果建表時不指定主鍵,資料庫會拒絕建表的語句執行。 事實上, 一個加了主鍵的表,並不能被稱之為「表」。一個沒加主鍵的表,它的數據無序的放置在磁碟存儲器上,一行一行的排列的很整齊, 跟我認知中的「表」很接近。如果給表上了主鍵,那麼表在磁碟上的存儲結構就由整齊排列的結構轉變成了樹狀結構,也就是上面說的「平衡樹」結構,換句話說,就是整個表就變成了一個索引。沒錯, 再說一遍, 整個表變成了一個索引,也就是所謂的「聚集索引」。 這就是為什麼一個表只能有一個主鍵, 一個表只能有一個「聚集索引」,因為主鍵的作用就是把「表」的數據格式轉換成「索引(平衡樹)」的格式放置 , 這樣原本大量查詢的數據查詢次數計算 , 查找次數是以樹的分叉數為底,記錄總數的對數,大大降低次數數量級.
索引能讓資料庫查詢數據的速度上升, 而使寫入數據的速度下降,原因很簡單的, 因為平衡樹這個結構必須一直維持在一個正確的狀態, 增刪改數據都會改變平衡樹各節點中的索引數據內容,破壞樹結構, 因此,在每次數據改變時, DBMS必須去重新梳理樹(索引)的結構以確保它的正確,這會帶來不小的性能開銷,也就是為什麼索引會給查詢以外的操作帶來副作用的原因。
非聚焦索引即常規索引
非聚焦索引即 每次給欄位建一個新索引, 欄位中的數據就會被覆制一份出來, 用於生成索引。 因此, 給表添加索引,會增加表的體積, 占用磁碟存儲空間。
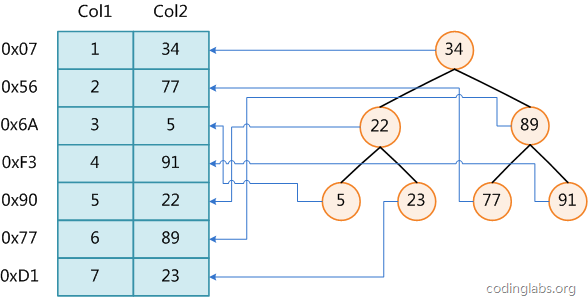
非聚集索引和聚集索引的區別在於, 通過聚集索引可以查到需要查找的數據, 而通過非聚集索引可以查到記錄對應的主鍵值 , 再使用主鍵的值通過聚集索引查找到需要的數據,如下圖

不管以任何形式查詢表,絕大部分都要通過聚焦索引來進行定位, 聚集索引(主鍵)是通往真實數據所在的主要路徑。
非聚焦索引流程
#創建索引
create index_age name on user_info(age);
#查詢年齡為20的用戶名
select name from user_info where index_age = 20;首先,通過非聚集索引index_age查找age等於20的所有記錄的主鍵ID值
然後,通過得到的主鍵ID值執行聚集索引查找,找到主鍵ID值對就的真實數據(數據行)存儲的位置
最後, 從得到的真實數據中取得naem欄位的值返回, 也就是取得最終的結果
複合索引即多欄位查詢
#創建複合索引
create index index_birthday_and_user_name on user_info(birthday, user_name);
#查詢生日為1993-11-1的用戶名
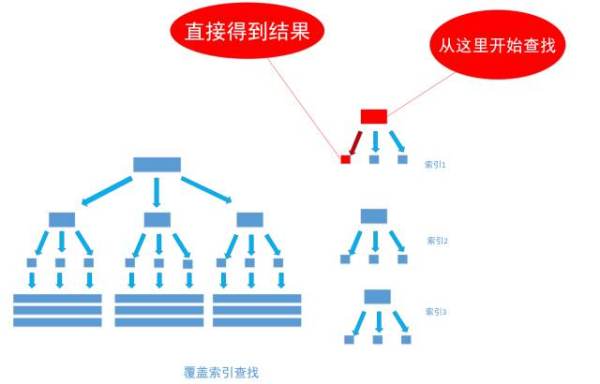
select user_name from user_info where birthday = '1993-11-1'通過非聚集索引index_birthday_and_user_name查找birthday等於1993-11-1的葉節點的內容,然而, 葉節點中除了有user_name表主鍵ID的值以外, user_name欄位的值也在裡面, 因此不需要通過主鍵ID值的查找數據行的真實所在, 直接取得葉節點中user_name的值返回即可。 通過這種覆蓋索引直接查找的方式, 可以省略不使用覆蓋索引查找的後面兩個步驟, 大大的提高了查詢性能
創建索引的語句
創建索引
CREATE INDEX name_index
ON Employee (Employee_Name)聯合索引
CREATE INDEX name_index
ON Employee (Employee_Name, Employee_Age)3 Redis原理
概述
- 是一個完全開源免費的key-value記憶體資料庫
- 通常被認為是一個數據結構伺服器,主要是因為其有著豐富的數據結構 strings、map、 list、sets、 sorted sets
Redis資料庫
Redis也以消息隊列的形式存在,作為內嵌的List存在,滿足實時的高併發需求。在使用緩存的時候,redis比memcached具有更多的優勢,並且支持更多的數據類型,把redis當作一個中間存儲系統,用來處理高併發的資料庫操作.
Redis存儲的優點:
- 速度快:使用標準C寫,所有數據都在記憶體中完成,讀寫速度分別達到10萬/20萬
- 持久化:對數據的更新採用Copy-on-write技術,可以非同步地保存到磁碟上,主要有兩種策略,一是根據時間,更新次數的快照(save 300 10 )二是基於語句追加方式(Append-only file,aof)
- 自動操作:對不同數據類型的操作都是自動的,很安全
- 快速的主--從複製,官方提供了一個數據,Slave在21秒即完成了對Amazon網站10G key set的複製。
- Sharding技術: 很容易將數據分佈到多個Redis實例中,資料庫的擴展是個永恆的話題,在關係型資料庫中,主要是以添加硬體、以分區為主要技術形式的縱向擴展解決了很多的應用場景,但隨著web2.0、移動互聯網、雲計算等應用的興起,這種擴展模式已經不太適合了,所以近年來,像採用主從配置、資料庫複製形式的,Sharding這種技術把負載分佈到多個特理節點上去的橫向擴展方式用處越來越多。
Redis缺點
- 是資料庫容量受到物理記憶體的限制,不能用作海量數據的高性能讀寫,因此Redis適合的場景主要局限在較小數據量的高性能操作和運算上。
- Redis較難支持線上擴容,在集群容量達到上限時線上擴容會變得很複雜。為避免這一問題,運維人員在系統上線時必須確保有足夠的空間,這對資源造成了很大的浪費。
Redis的常見應用場景
一:緩存——熱數據
熱點數據(經常會被查詢,但是不經常被修改或者刪除的數據),首選是使用redis緩存
- Select 資料庫前查詢redis,有的話使用redis數據,放棄select 資料庫,沒有的話,select 資料庫,然後將數據插入redis
- update或者delete資料庫錢,查詢redis是否存在該數據,存在的話先刪除redis中數據,然後再update或者delete資料庫中的數據
二:計數器
諸如統計點擊數等應用。由於單線程,可以避免併發問題,保證不會出錯,而且100%毫秒級性能! redis只是存了記憶體,記住要持久化,命令用 INCRBY
INCR user:<id> EXPIRE
三:隊列
- 由於redis把數據添加到隊列是返回添加元素在隊列的第幾位,所以可以判斷用戶是第幾個訪問這種業務
- 隊列不僅可以把併發請求變成串列,並且還可以做隊列或者棧使用
四:位操作(大數據處理)
用於數據量上億的場景下,例如幾億用戶系統的簽到,去重登錄次數統計,某用戶是否線上狀態等等。
原理是:
redis內構建一個足夠長的數組,每個數組元素只能是0和1兩個值,然後這個數組的下標index用來表示我們上面例子裡面的用戶id(必須是數字哈),那麼很顯然,這個幾億長的大數組就能通過下標和元素值(0和1)來構建一個記憶系統,上面我說的幾個場景也就能夠實現。用到的命令是:setbit、getbit、bitcount
五:分散式鎖與單線程機制
驗證前端的重覆請求(可以自由擴展類似情況),可以通過redis進行過濾:每次請求將request Ip、參數、介面等hash作為key存儲redis,設置多長時間有效期,然後下次請求過來的時候先在redis中檢索有沒有這個key,進而驗證是不是一定時間內過來的重覆提交
六:最新列表
例如新聞列表頁面最新的新聞列表,如果總數量很大的情況下,儘量不要使用select a from A limit 10,嘗試redis的 LPUSH命令構建List,一個個順序都塞進去就可以啦。用mysql查詢並且初始化一個List到redis中。
七:排行榜
這個需求與上面需求的不同之處在於,取最新N個數據的操作以時間為權重,這個是以某個條件為權重,比如按頂的次數排序,這時候就需要我們的sorted set出馬了,將你要排序的值設置成sorted set的score,將具體的數據設置成相應的value,每次只需要執行一條ZADD命令即可。
//將登錄次數和用戶統一存儲在一個sorted set里 zadd login:login_times 5 1 zadd login:login_times 1 2 zadd login:login_times 2 3 //當用戶登錄時,對該用戶的登錄次數自增1 ret = r.zincrby("login:login_times", 1, uid) //那麼如何獲得登錄次數最多的用戶呢,逆序排列取得排名前N的用戶 ret = r.zrevrange("login:login_times", 0, N-1)
4 MVCC多版本併發控制
概述
全稱是Multi-Version Concurrent Control,即多版本併發控制,在MVCC協議下,每個讀操作會看到一個一致性的snapshot,並且可以實現非阻塞的讀。MVCC允許數據具有多個版本,這個版本可以是時間戳或者是全局遞增的事務ID,在同一個時間點,不同的事務看到的數據是不同的。
mysql中innodb實現
innodb會為每一行添加兩個欄位,分別表示該行創建的版本和刪除的版本,填入的是事務的版本號,這個版本號隨著事務的創建不斷遞增。在repeated read的隔離級別(事務的隔離級別請看這篇文章)下,具體各種資料庫操作的實現:select,insert,delete,update
MyISAM 適合於一些需要大量查詢的應用,但其對於有大量寫操作並不是很好.


