
簡介 Hive 是基於 Hadoop 的一個數據倉庫工具,可以將結構化的數據文件 映射為一張資料庫表,並提供類 SQL 查詢功能。 本質是將 SQL 轉換為 MapReduce 程式。 Hive組件 用戶介面:包括 CLI、JDBC/ODBC、WebGUI。其中,CLI(command linein ...
簡介

Hive 是基於 Hadoop 的一個數據倉庫工具,可以將結構化的數據文件 映射為一張資料庫表,並提供類 SQL 查詢功能。
本質是將 SQL 轉換為 MapReduce 程式。
Hive組件
用戶介面:包括 CLI、JDBC/ODBC、WebGUI。其中,CLI(command lineinterface)為 shell 命令行;JDBC/ODBC 是 Hive 的 JAVA 實現,與傳統資料庫JDBC 類似;WebGUI 是通過瀏覽器訪問 Hive。
元數據存儲:通常是存儲在關係資料庫如 mysql/derby 中。Hive 將元數據存儲在資料庫中。Hive 中的元數據包括表的名字,表的列和分區及其屬性,表的屬性(是否為外部表等),表的數據所在目錄等。
解釋器、編譯器、優化器、執行器:完成 HQL 查詢語句從詞法分析、語法分析、編譯、優化以及查詢計劃的生成。生成的查詢計劃存儲在 HDFS 中,併在隨後有 MapReduce 調用執行。
Hive 與 Hadoop 的關係
Hive 利用HDFS 存儲數據,利用 MapReduce 查詢分析數據
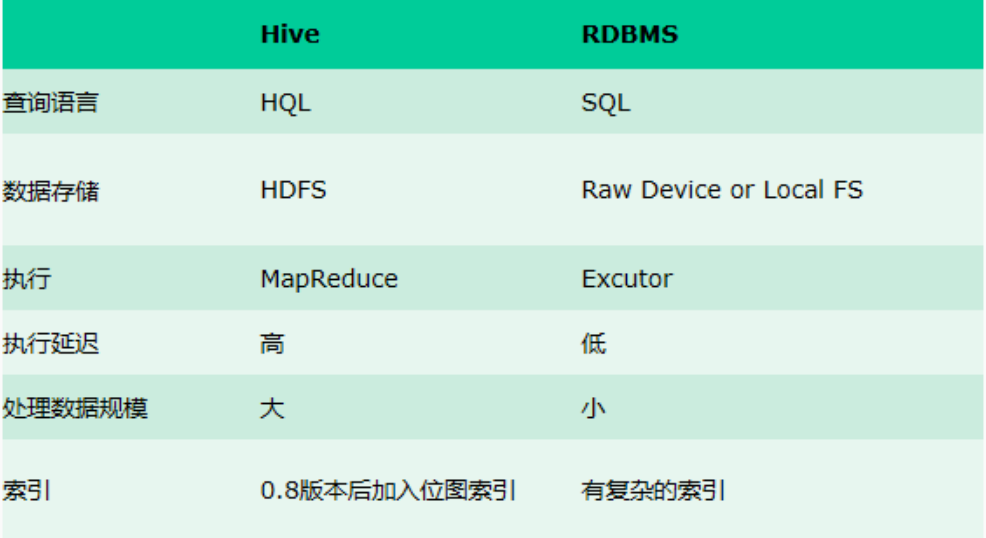
Hive 與傳統資料庫 對比
hive 用於海量數據的離線數據分析。
hive 具有 sql 資料庫的外表,但應用場景完全不同,hive 只適合用來做批量數據統計分析。
2、具備ETL的能力,使用Hadoop MapReduce進行數據的ETL (提供sql轉化成MapReduce的能力)
Hive數據模型
Hive 中所有的數據都存儲在 HDFS 中,沒有專門的數據存儲格式,在創建表時指定數據中的分隔符,Hive 就可以映射成功,解析數據。
Hive 中包含以下數據模型:
db :在 hdfs 中表現為 hive.metastore.warehouse.dir 目錄下一個文件夾
table :在 hdfs 中表現所屬 db 目錄下一個文件夾
external table :數據存放位置可以在 HDFS 任意指定路徑
partition :在 hdfs 中表現為 table 目錄下的子目錄
bucket :在 hdfs 中表現為同一個表目錄下根據 hash 散列之後的多個文件
一些專業術語
增量(上次導出之後的新數據):i_s.Peking.orders_20130711_000.lzo
加密:i_s.peking.orders_20130711_000.md5
表結構:i_s.peking.orders_20130711_000.xml
全量(表中所有的數據):a_s.Peking.orders_20130711_000.lzo
加密:a_s.peking.orders_20130711_000.md5
表結構:a_s.peking.orders_20130711_000.xml
PV:頁面訪問量,即PageView,用戶每次對網站的訪問均被記錄,用戶對同一頁面的多次訪問,訪問量累計。
UV:獨立訪問用戶數:即UniqueVisitor,訪問網站的一臺電腦客戶端為一個訪客。一天內相同的客戶端只被計算一次。
數據倉庫:Data Warehouse,簡寫為 DW 或 DWH
資料庫:database,簡寫DB
聯機事務處理 OLTP(On-Line Transaction Processing) --> 關係型資料庫RDBMS
聯機分析處理 OLAP(On-Line Analytical Processing) --> 數據倉庫
ETL(抽取 Extra, 轉化 Transfer, 裝載 Load)
源數據層(ODS)
數據倉庫層(DW)
數據應用層(DA 或 APP)
元數據(Meta Date)
Hive MySQL版本的安裝
內置derby版缺點:不同路徑啟動 hive,每一個 hive 擁有一套自己的元數據,無法共用
-
安裝hive
上傳hive的安裝包並解壓
切換到hive安裝目錄的配置文件路徑中修改配置信息
cd /export/servers/hive/conf
vi hive-env.sh
export HADOOP_HOME=/export/servers/hadoop-2.7.4
vi hive-site.xml
<configuration> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value> <description>JDBC connect string for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> <description>Driver class name for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> <description>username to use against metastore database</description> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>hadoop</value> <description>password to use against metastore database</description> </property> </configuration>
-
安裝mysql
yum install -y mysql mysql-server mysql-devel
#啟動mysql服務
/etc/init.d/mysqld start
mysql
USE mysql;
#設置用戶及密碼
UPDATE user SET Password=PASSWORD('hadoop') WHERE user='root';
#刷新許可權
FLUSH PRIVILEGES;
#設置許可權
GRANT ALL PRIVILEGES ON . TO 'root'@'%' IDENTIFIED BY 'hadoop' WITH GRANT OPTION;
#設置開機啟動mysql服務
chkconfig mysqld on
註意把mysql資料庫驅動mysql-connector-java-5.1.32.jar放置在hive lib/目錄中
啟動hive前,先啟動HDFS及YARN集群
Hive幾種使用方式:
1.Hive交互shell bin/hive
2.Hive JDBC服務(參考java jdbc連接mysql)
3.hive啟動為一個伺服器,來對外提供服務
bin/hiveserver2
nohup bin/hiveserver2 1>/var/log/hiveserver.log 2>/var/log/hiveserver.err &
啟動成功後,可以在別的節點上用beeline去連接
bin/beeline -u jdbc:hive2://mini1:10000 -n root
或者
bin/beeline
! connect jdbc:hive2://mini1:10000
4.Hive命令
hive -e ‘sql’
bin/hive -e 'select * from t_test'

