
我們之前學習創建線程有Thread和Runnable兩種方式,但是兩種方式都無法獲得執行的結果。 而Callable和Future在任務完成後得到結果。 Future是一個介面,表示一個任務的周期,並提供了相應的方法來判斷是否已經完成或者取消任務,以及獲取任務的結果和取消任務。 FutureTask ...
我們之前學習創建線程有Thread和Runnable兩種方式,但是兩種方式都無法獲得執行的結果。 而Callable和Future在任務完成後得到結果。 Future是一個介面,表示一個任務的周期,並提供了相應的方法來判斷是否已經完成或者取消任務,以及獲取任務的結果和取消任務。 FutureTask可用於非同步獲取執行結果或取消執行任務的場景。通過傳入Runnable或者Callable的任務給FutureTask,直接調用其run方法或者放入線程池執行,之後可以在外部通過FutureTask的get方法非同步獲取執行結果,因此,FutureTask非常適合用於耗時的計算,主線程可以在完成自己的任務後,再去獲取結果。另外,FutureTask還可以確保即使調用了多次run方法,它都只會執行一次Runnable或者Callable任務,或者通過cancel取消FutureTask的執行等。 Future介面
import lombok.extern.slf4j.Slf4j; import java.util.concurrent.Callable; import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; import java.util.concurrent.Future; @Slf4j public class FutureExample { static class MyCallable implements Callable<String> { @Override public String call() throws Exception { log.info("do something in callable"); Thread.sleep(5000); return "Done"; } } public static void main(String[] args) throws Exception { ExecutorService executorService = Executors.newCachedThreadPool(); Future<String> future = executorService.submit(new MyCallable()); log.info("do something in main"); //Thread.sleep(10000); log.info("這裡不阻塞,可以繼續非同步執行"); String result = future.get(); //get方法會發生阻塞,如果判斷任務是否執行完成使用isDone()方法 log.info("result:{}", result); } }
FutureTask
import lombok.extern.slf4j.Slf4j; import java.util.concurrent.Callable; import java.util.concurrent.FutureTask; @Slf4j public class FutureTaskExample { public static void main(String[] args) throws Exception { FutureTask<String> futureTask = new FutureTask<String>(new Callable<String>() { @Override public String call() throws Exception { log.info("do something in callable"); Thread.sleep(5000); return "Done"; } }); new Thread(futureTask).start(); log.info("do something in main"); Thread.sleep(1000); String result = futureTask.get(); log.info("result:{}", result); } }
Fork/Join
用於並行執行任務的框架,將大任務分割成小任務,最終將每個小任務的結果彙總得到大任務結果的框架。
思想和map/reduce非常像,Fork就是講大任務分割成小任務,Join就是合併子任務的結果。
工作竊取演算法
工作竊取(work-stealing)演算法是指某個線程從其他隊列里竊取任務來執行。工作竊取的運行流程圖如下:
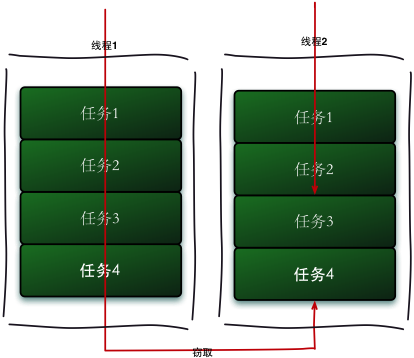
那麼為什麼需要使用工作竊取演算法呢?假如我們需要做一個比較大的任務,我們可以把這個任務分割為若幹互不依賴的子任務,為了減少線程間的競爭,於是把這些子任務分別放到不同的隊列里,併為每個隊列創建一個單獨的線程來執行隊列里的任務,線程和隊列一一對應,比如A線程負責處理A隊列里的任務。但是有的線程會先把自己隊列里的任務幹完,而其他線程對應的隊列里還有任務等待處理。幹完活的線程與其等著,不如去幫其他線程幹活,於是它就去其他線程的隊列里竊取一個任務來執行。而在這時它們會訪問同一個隊列,所以為了減少竊取任務線程和被竊取任務線程之間的競爭,通常會使用雙端隊列,被竊取任務線程永遠從雙端隊列的頭部拿任務執行,而竊取任務的線程永遠從雙端隊列的尾部拿任務執行。
工作竊取演算法的優點是充分利用線程進行並行計算,並減少了線程間的競爭,其缺點是在某些情況下還是存在競爭,比如雙端隊列里只有一個任務時。並且消耗了更多的系統資源,比如創建多個線程和多個雙端隊列。
Fork/Join使用兩個類來完成以上兩件事情:
ForkJoinPool :它負責實現,包括我們的工作竊取演算法,它管理工作線程和任務狀態以及執行信息
ForkJoinTask:主要提供fork和join的機制
import lombok.extern.slf4j.Slf4j; import java.util.concurrent.ForkJoinPool; import java.util.concurrent.Future; import java.util.concurrent.RecursiveTask; @Slf4j public class ForkJoinTaskExample extends RecursiveTask<Integer> { public static final int threshold = 2; private int start; private int end; public ForkJoinTaskExample(int start, int end) { this.start = start; this.end = end; } @Override protected Integer compute() { int sum = 0; //如果任務足夠小就計算任務 boolean canCompute = (end - start) <= threshold; if (canCompute) { for (int i = start; i <= end; i++) { sum += i; } } else { // 如果任務大於閾值,就分裂成兩個子任務計算 int middle = (start + end) / 2; ForkJoinTaskExample leftTask = new ForkJoinTaskExample(start, middle); ForkJoinTaskExample rightTask = new ForkJoinTaskExample(middle + 1, end); // 執行子任務 leftTask.fork(); rightTask.fork(); // 等待任務執行結束合併其結果 int leftResult = leftTask.join(); int rightResult = rightTask.join(); // 合併子任務 sum = leftResult + rightResult; } return sum; } public static void main(String[] args) { ForkJoinPool forkjoinPool = new ForkJoinPool(); //生成一個計算任務,計算1+2+3+4 ForkJoinTaskExample task = new ForkJoinTaskExample(1, 100); //執行一個任務 Future<Integer> result = forkjoinPool.submit(task); try { log.info("result:{}", result.get()); } catch (Exception e) { log.error("exception", e); } } }
BlockingQueue
在新增的Concurrent包中,BlockingQueue很好的解決了多線程中,如何高效安全“傳輸”數據的問題。通過這些高效並且線程安全的隊列類,為我們快速搭建高質量的多線程程式帶來極大的便利。認識BlockingQueue
阻塞隊列,顧名思義,首先它是一個隊列,而一個隊列在數據結構中所起的作用大致如下圖所示:

從上圖我們可以很清楚看到,通過一個共用的隊列,可以使得數據由隊列的一端輸入,從另外一端輸出;
常用的隊列主要有以下兩種:(當然通過不同的實現方式,還可以延伸出很多不同類型的隊列,DelayQueue就是其中的一種)
先進先出(FIFO):先插入的隊列的元素也最先出隊列,類似於排隊的功能。從某種程度上來說這種隊列也體現了一種公平性。
後進先出(LIFO):後插入隊列的元素最先出隊列,這種隊列優先處理最近發生的事件。
多線程環境中,通過隊列可以很容易實現數據共用,比如經典的“生產者”和“消費者”模型中,通過隊列可以很便利地實現兩者之間的數據共用。假設我們有若幹生產者線程,另外又有若幹個消費者線程。如果生產者線程需要把準備好的數據共用給消費者線程,利用隊列的方式來傳遞數據,就可以很方便地解決他們之間的數據共用問題。但如果生產者和消費者在某個時間段內,萬一發生數據處理速度不匹配的情況呢?理想情況下,如果生產者產出數據的速度大於消費者消費的速度,並且當生產出來的數據累積到一定程度的時候,那麼生產者必須暫停等待一下(阻塞生產者線程),以便等待消費者線程把累積的數據處理完畢,反之亦然。然而,在concurrent包發佈以前,在多線程環境下,我們每個程式員都必須去自己控制這些細節,尤其還要兼顧效率和線程安全,而這會給我們的程式帶來不小的複雜度。好在此時,強大的concurrent包橫空出世了,而他也給我們帶來了強大的BlockingQueue。(在多線程領域:所謂阻塞,在某些情況下會掛起線程(即阻塞),一旦條件滿足,被掛起的線程又會自動被喚醒)
下麵兩幅圖演示了BlockingQueue的兩個常見阻塞場景:
 如上圖所示:當隊列中沒有數據的情況下,消費者端的所有線程都會被自動阻塞(掛起),直到有數據放入隊列。
如上圖所示:當隊列中沒有數據的情況下,消費者端的所有線程都會被自動阻塞(掛起),直到有數據放入隊列。

如上圖所示:當隊列中填滿數據的情況下,生產者端的所有線程都會被自動阻塞(掛起),直到隊列中有空的位置,線程被自動喚醒。


1. ArrayBlockingQueue
基於數組的阻塞隊列實現,在ArrayBlockingQueue內部,維護了一個定長數組,以便緩存隊列中的數據對象,這是一個常用的阻塞隊列,除了一個定長數組外,ArrayBlockingQueue內部還保存著兩個整形變數,分別標識著隊列的頭部和尾部在數組中的位置。
ArrayBlockingQueue在生產者放入數據和消費者獲取數據,都是共用同一個鎖對象,由此也意味著兩者無法真正並行運行,這點尤其不同於LinkedBlockingQueue
2. LinkedBlockingQueue
基於鏈表的阻塞隊列,同ArrayListBlockingQueue類似,其內部也維持著一個數據緩衝隊列(該隊列由一個鏈表構成),當生產者往隊列中放入一個數據時,隊列會從生產者手中獲取數據,並緩存在隊列內部,而生產者立即返回;只有當隊列緩衝區達到最大值緩存容量時(LinkedBlockingQueue可以通過構造函數指定該值),才會阻塞生產者隊列,直到消費者從隊列中消費掉一份數據,生產者線程會被喚醒,反之對於消費者這端的處理也基於同樣的原理。而LinkedBlockingQueue之所以能夠高效的處理併發數據,還因為其對於生產者端和消費者端分別採用了獨立的鎖來控制數據同步,這也意味著在高併發的情況下生產者和消費者可以並行地操作隊列中的數據,以此來提高整個隊列的併發性能。
作為開發者,我們需要註意的是,如果構造一個LinkedBlockingQueue對象,而沒有指定其容量大小,LinkedBlockingQueue會預設一個類似無限大小的容量(Integer.MAX_VALUE),這樣的話,如果生產者的速度一旦大於消費者的速度,也許還沒有等到隊列滿阻塞產生,系統記憶體就有可能已被消耗殆盡了。
ArrayBlockingQueue和LinkedBlockingQueue是兩個最普通也是最常用的阻塞隊列,一般情況下,在處理多線程間的生產者消費者問題,使用這兩個類足以。


