
摘要(面試必問題之HashMap) HashMap是Java程式員使用頻率最高的用於映射(鍵值對)處理的數據類型。隨著JDK(Java Developmet Kit)版本的更新,JDK1.8對HashMap底層的實現進行了優化,例如引入紅黑樹的數據結構和擴容的優化等。本文結合JDK1.7和JDK1. ...
摘要(面試必問題之HashMap)
HashMap是Java程式員使用頻率最高的用於映射(鍵值對)處理的數據類型。隨著JDK(Java Developmet Kit)版本的更新,JDK1.8對HashMap底層的實現進行了優化,例如引入紅黑樹的數據結構和擴容的優化等。本文結合JDK1.7和JDK1.8的區別,深入探討
HashMap的結構實現和功能原理。
簡介
Java為數據結構中的映射定義了一個介面java.util.Map,此介面主要有四個常用的實現類,分別是HashMap、Hashtable、LinkedHashMap和TreeMap,類繼承關係如下圖所示:

java.util.map類圖
下麵針對各個實現類的特點做一些說明:
(1) HashMap:它根據鍵的hashCode值存儲數據,大多數情況下可以直接定位到它的值,因而具有很快的訪問速度,但遍歷順序卻是不確定的。 HashMap最多只允許一條記錄的鍵為null,允許多條記錄的值為null。HashMap非線程安全,即任一時刻可以有多個線程同時寫HashMap,可能會導致數據的不一致。如果需要滿足線程安全,可以用 Collections的synchronizedMap方法使HashMap具有線程安全的能力,或者使用ConcurrentHashMap。
(2) Hashtable:Hashtable是遺留類,很多映射的常用功能與HashMap類似,不同的是它承自Dictionary類,並且是線程安全的,任一時間只有一個線程能寫Hashtable,併發性不如ConcurrentHashMap,因為ConcurrentHashMap引入了分段鎖。Hashtable不建議在新代碼中使用,不需要線程安全的場合可以用HashMap替換,需要線程安全的場合可以用ConcurrentHashMap替換。
(3) LinkedHashMap:LinkedHashMap是HashMap的一個子類,保存了記錄的插入順序,在用Iterator遍歷LinkedHashMap時,先得到的記錄肯定是先插入的,也可以在構造時帶參數,按照訪問次序排序。
(4) TreeMap:TreeMap實現SortedMap介面,能夠把它保存的記錄根據鍵排序,預設是按鍵值的升序排序,也可以指定排序的比較器,當用Iterator遍歷TreeMap時,得到的記錄是排過序的。如果使用排序的映射,建議使用TreeMap。在使用TreeMap時,key必須實現Comparable介面或者在構造TreeMap傳入自定義的Comparator,否則會在運行時拋出java.lang.ClassCastException類型的異常。
對於上述四種Map類型的類,要求映射中的key是不可變對象。不可變對象是該對象在創建後它的哈希值不會被改變。如果對象的哈希值發生變化,Map對象很可能就定位不到映射的位置了。
通過上面的比較,我們知道了HashMap是Java的Map家族中一個普通成員,鑒於它可以滿足大多數場景的使用條件,所以是使用頻度最高的一個。下文我們主要結合源碼,從存儲結構、常用方法分析、擴容以及安全性等方面深入講解HashMap的工作原理。
內部實現
搞清楚HashMap,首先需要知道HashMap是什麼,即它的存儲結構-欄位;其次弄明白它能幹什麼,即它的功能實現-方法。下麵我們針對這兩個方面詳細展開講解。
存儲結構-欄位
從結構實現來講,HashMap是數組+鏈表+紅黑樹(JDK1.8增加了紅黑樹部分)實現的,如下如所示。
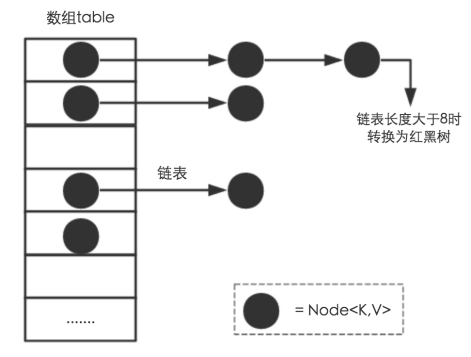
hashMap記憶體結構圖
這裡需要講明白兩個問題:數據底層具體存儲的是什麼?這樣的存儲方式有什麼優點呢?
(1) 從源碼可知,HashMap類中有一個非常重要的欄位,就是 Node[] table,即哈希桶數組,明顯它是一個Node的數組。我們來看Node[JDK1.8]是何物。 static class Node<K,V> implements Map.Entry<K,V> {
final int hash; //用來定位數組索引位置 final K key;
V value;
Node<K,V> next; //鏈表的下一個node
Node(int hash, K key, V value, Node<K,V> next) { ... }
public final K getKey(){ ... }
public final V getValue() { ... }
public final String toString() { ... }
public final int hashCode() { ... }
public final V setValue(V newValue) { ... }
public final boolean equals(Object o) { ... }
}
Node是HashMap的一個內部類,實現了Map.Entry介面,本質是就是一個映射(鍵值對)。上圖中的每個黑色圓點就是一個Node對象。
(2) HashMap就是使用哈希表來存儲的。哈希表為解決衝突,可以採用開放地址法和鏈地址法等來解決問題,Java中HashMap採用了鏈地址法。鏈地址法,簡單來說,就是數組加鏈表的結合。在每個數組元素上都一個鏈表結構,當數據被Hash後,得到數組下標,把數據放在對應下標元素的鏈表上。例如程式執行下麵代碼:
map.put("美團","小美");
系統將調用"美團"這個key的hashCode()方法得到其hashCode 值(該方法適用於每個Java對象),然後再通過Hash演算法的後兩步運算(高位運算和取模運算,下文有介紹)來定位該鍵值對的存儲位置,有時兩個key會定位到相同的位置,表示發生了Hash碰撞。當然Hash演算法計算結果越分散均勻,Hash碰撞的概率就越小,map的存取效率就會越高。如果哈希桶數組很大,即使較差的Hash演算法也會比較分散,如果哈希桶數組數組很小,即使好的Hash演算法也會出現較多碰撞,所以就需要在空間成本和時間成本之間權衡,其實就是在根據實際情況確定哈希桶數組的大小,併在此基礎上設計好的hash演算法減少Hash碰撞。那麼通過什麼方式來控制map使得Hash碰撞的概率又小,哈希桶數組(Node[] table)占用空間又少呢?答案就是好的Hash演算法和擴容機制。
在理解Hash和擴容流程之前,我們得先瞭解下HashMap的幾個欄位。從HashMap的預設構造函數源碼可知,構造函數就是對下麵幾個欄位進行初始化,源碼如下:
int threshold; // 所能容納的key-value對極限
final float loadFactor;// 負載因數
int modCount;
int size;
首先,Node[] table的初始化長度length(預設值是16),Load factor為負載因數(預設值是0.75),threshold是HashMap所能容納的最大數據量的Node(鍵值對)個數。threshold = length * Load factor。也就是說,在數組定義好長度之後,負載因數越大,所能容納的鍵值對個數越多。
結合負載因數的定義公式可知,threshold就是在此Load factor和length(數組長度)對應下允許的最大元素數目,超過這個數目就重新resize(擴容),擴容後的HashMap容量是之前容量的兩倍。預設的負載因數0.75是對空間和時間效率的一個平衡選擇,建議大家不要修改,除非在時間和空間比較特殊的情況下,如果記憶體空間很多而又對時間效率要求很高,可以降低負載因數Load factor的值;相反,如果記憶體空間緊張而對時間效率要求不高,可以增加負載因數loadFactor的值,這個值可以大於1。size這個欄位其實很好理解,就是HashMap中實際存在的鍵值對數量。註意和table的長度length、容納最大鍵值對數量threshold的區別。而modCount欄位主要用來記錄HashMap內部結構發生變化的次數,主要用於迭代的快速失敗。強調一點,內部結構發生變化指的是結構發生變化,例如put新鍵值對,但是某個key對應的value值被覆蓋不屬於結構變化。
在HashMap中,哈希桶數組table的長度length大小必須為2的n次方(一定是合數),這是一種非常規的設計,常規的設計是把桶的大小設計為素數。相對來說素數導致衝突的概率要小於合數,具體證明可以參考http://blog.csdn.net/liuqiyao_01/article/details/14475159,Hashtable初始化桶大小為11,就是桶大小設計為素數的應用(Hashtable擴容後不能保證還是素數)。HashMap採用這種非常規設計,主要是為了在取模和擴容時做優化,同時為了減少衝突,HashMap定位哈希桶索引位置時,也加入了高位參與運算的過程。
這裡存在一個問題,即使負載因數和Hash演算法設計的再合理,也免不了會出現拉鏈過長的情況,一旦出現拉鏈過長,則會嚴重影響HashMap的性能。於是,在JDK1.8版本中,對數據結構做了進一步的優化,引入了紅黑樹。而當鏈表長度太長(預設超過8)時,鏈表就轉換為紅黑樹,利用紅黑樹快速增刪改查的特點提高HashMap的性能,其中會用到紅黑樹的 插入、刪除、查找等演算法。本文不再對紅黑樹展開討論,想瞭解更多紅黑樹數據結構的工作原理可以參考http://blog.csdn.net/v_july_v/article/details/6105630。
功能實現-方法
HashMap的內部功能實現很多,本文主要從根據key獲取哈希桶數組索引位置、put方法的詳細執行、擴容過程三個具有代表性的點深入展開講解。
1. 確定哈希桶數組索引位置
不管增加、刪除、查找鍵值對,定位到哈希桶數組的位置都是很關鍵的第一步。前面說過HashMap的數據結構是數組和鏈表的結合,所以我們當然希望這個HashMap裡面的元素位置儘量分佈均勻些,儘量使得每個位置上的元素數量只有一個,那麼當我們用hash演算法求得這個位置的時候,馬上就可以知道對應位置的元素就是我們要的,不用遍歷鏈表,大大優化了查詢的效率。HashMap定位數組索引位置,直接決定了hash方法的離散性能。先看看源碼的實現(方法一+方法二):
方法一:
static final int hash(Object key) { //jdk1.8 & jdk1.7
int h;
// h = key.hashCode() 為第一步取hashCode值
// h ^ (h >>> 16) 為第二步高位參與運算
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
方法二:
static int indexFor(int h, int length) { //jdk1.7的源碼,jdk1.8沒有這個方法,但是實現原理一樣的
return h & (length-1); //第三步取模運算
}
這裡的Hash演算法本質上就是三步:取key的hashCode值、高位運算、取模運算。對於任意給定的對象,只要它的hashCode()返回值相同,那麼程式調用方法一所計算得到的Hash碼值總是相同的。我們首先想到的就是把hash值對數組長度取模運算,這樣一來,元素的分佈相對來說是比較均勻的。但是,模運算的消耗還是比較大的,在HashMap中是這樣做的:調用方法二來計算該對象應該保存在table數組的哪個索引處。
這個方法非常巧妙,它通過h & (table.length -1)來得到該對象的保存位,而HashMap底層數組的長度總是2的n次方,這是HashMap在速度上的優化。當length總是2的n次方時, h& (length-1)運算等價於對length取模,也就是h%length,但是&比%具有更高的效率。在JDK1.8的實現中,優化了高位運算的演算法,通過hashCode()的高16位異或低16位實現的:(h = k.hashCode()) ^ (h >>> 16),主要是從速度、功效、質量來考慮的,這麼做可以在數組table的length比較小的時候,也能保證考慮到高低Bit都參與到Hash的計算中,同時不會有太大的開銷。
下麵舉例說明下,n為table的長度。
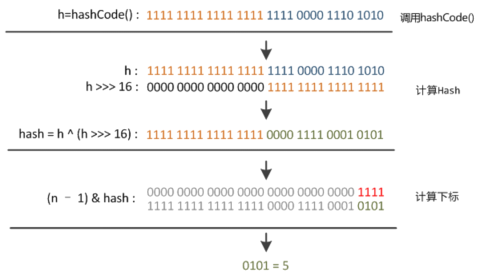
hashMap哈希演算法例圖
2. 分析HashMap的put方法
HashMap的put方法執行過程可以通過下圖來理解,自己有興趣可以去對比源碼更清楚地研究學習。

hashMap put方法執行流程圖
①. 判斷鍵值對數組table[i]是否為空或為null,否則執行resize()進行擴容;
②. .根據鍵值key計算hash值得到插入的數組索引i,如果table[i]==null,直接新建節點添加,轉向⑥,如果table[i]不為空,轉向③;
③. .判斷table[i]的首個元素是否和key一樣,如果相同直接覆蓋value,否則轉向④,這裡的相同指的是hashCode以及equals;
④.判斷table[j]是否為treeNode ,即table[門是否是紅黑樹,如果是紅黑樹,則直接在樹中插入鍵值對,否則轉向⑤;⑤.遍歷table[j] ,判斷鏈表長度是否大於8 ,大於8的話把鏈表轉換為紅黑樹,在紅黑樹中執行插入操作,否則進行鏈表的插入操作;遍歷過程中若發現key已經存在直接覆蓋value即可;
⑥插入成功後,判斷實際存在的鍵值對數量size是否超多了最大容量threshold ,如果超過,進行擴容。
JDK1.8HashMap的put方法源碼如下:



3.擴容機制
擴容(resize)就是重新計算容量,向HashMap對象里不停的添加元素,而HashMap對象內部的數組無法裝載更多的元素時,對象就需要擴大數組的長度,以便能裝入更多的元素。當然Java里的數組是無法自動擴容的,方法是使用一個新的數組代替已有的容量小的數組,就像我們用一個小桶裝水,如果想裝更多的水,就得換大水桶。
我們分析下resize的源碼,鑒於JDK1 8融入了紅黑樹,較複雜,為了便於理解我們仍然使用JDK1.7的代碼,好理解一一些,本質上區別不大,具體區別後文再說。
 這裡就是使用一個容量更大的數組來代替已有的容量小的數組, transfer(方法將原有Entry數組的元素拷貝到新的Entry數組裡。
這裡就是使用一個容量更大的數組來代替已有的容量小的數組, transfer(方法將原有Entry數組的元素拷貝到新的Entry數組裡。


newTable們j]的引用賦給了e.next ,也就是使用了單鏈表的頭插入方式,同一位置上新元素總會被放在鏈表的頭部位置;這樣先放在-一個索引上的元素終會被放到Entry鏈的尾部(如果發生了hash衝突的話) , 這一點和dk1.8有區別,下文詳解。在舊數組中同一條Entry鏈上的元素,通過重新計算索引位置後,有可能被放到了新數組的不同位置上。
下麵舉個例子說明下擴容過程。假設了我們的hash演算法就是簡單的用key mod -下表的大小(也就是數組的長度)。其中的哈希桶數組table的size=2,所以key=3、7、5, put順序依次為5、7、3。在mod 2以後都衝突在table[1]這裡了。這裡假設負載因數loadFactor=1 ,即當鍵值對的實際大小size大於table的實際大小時進行擴容。接下來的三個步驟是哈希桶數組resize成4 ,然後所有的Node重新rehash的過程。

下麵我們講解下JDK1.8做了哪些優化。經過觀測可以發現,我們使用的是2次冪的擴展(指長度擴為原來2倍) ,所以,元素的位置要麼是在原位置,要麼是在原位置再移動2次冪的位置。看下圖可以明白這句話的意思, n為table的長度,圖(a )表示擴容前的key1和key2兩種key確定索引位置的示例,圖(b)表示擴容後key1和key2兩種key確定索引|位置的示例,其中hash1是key1對應的哈希與高位運算結果。

元素在重新計算hash之後,因為n變為2倍,那麼n-1的mask範圍在高位多1bit(紅色),因此新的index就會發生這樣的變化:

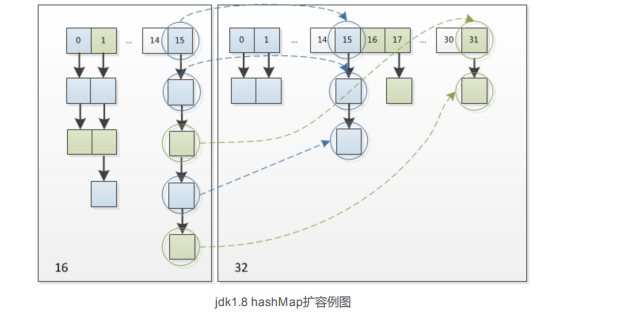 這個設計確實非常的巧妙,既省去了重新計算hash值的時間,而且同時,由於新增的1bit是0還是1可以認為是隨機的,因此resize的過程,均勻的把之前的衝突的節點分散到新的bucket了。這一塊就是JDK1 8新增的優化點。有一點註意區別, JDK1.7中rehash的時候,舊鏈表遷移新鏈表的時候,如果在新表的數組索引|位置相同,則鏈表元素會倒置,但是從上圖可以看出,JDK1.8不會倒置。有興趣的可以研究下JDK1 8的resize源碼,寫的很贊,如下:
這個設計確實非常的巧妙,既省去了重新計算hash值的時間,而且同時,由於新增的1bit是0還是1可以認為是隨機的,因此resize的過程,均勻的把之前的衝突的節點分散到新的bucket了。這一塊就是JDK1 8新增的優化點。有一點註意區別, JDK1.7中rehash的時候,舊鏈表遷移新鏈表的時候,如果在新表的數組索引|位置相同,則鏈表元素會倒置,但是從上圖可以看出,JDK1.8不會倒置。有興趣的可以研究下JDK1 8的resize源碼,寫的很贊,如下:




在多線程使用場景中,應該儘量避免使用線程不安全的HashMap ,而使用線程安全的
ConcurrentHashMap。那麼為什麼說HashMap是線程不安全的,下麵舉例子說明在併發的多線程使用場景中使用HashMap可能造成死迴圈。代碼例子如下(便於理解,仍然使用JDK1.7的環境) :


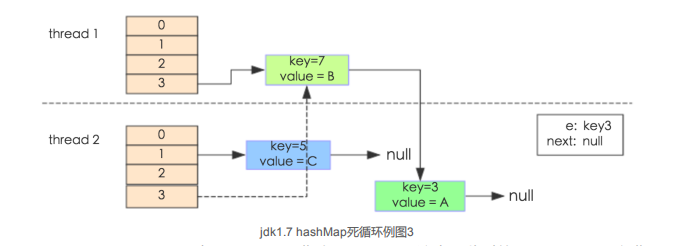
通過設置斷點讓線程1和線程2同時debug到transfer方法(3.3小節代碼塊)的首行。註意此時兩個線程已經成功添加數據。放開thread1的斷點至transfer方法的 "Entry next=e.next;,"這一行;然後放開線程2的的斷點,讓線程2進行resize。結果如下圖。
 註意, Thread1的e指向了key(3),而next指向了key(7),其線上程二.rehash後, 指向了線程二重組後的鏈表。
註意, Thread1的e指向了key(3),而next指向了key(7),其線上程二.rehash後, 指向了線程二重組後的鏈表。線程一被調度回來執行,先是執行newTalbe[j] = e,然後是e = next,導致了e指向了key(7) ,而下一-次迴圈的next = e.next導致了next指向了key(3)。

HashMap中,如果key經過hash演算法得出的數組索引|位置全部不相同,即Hash演算法非常好,那樣的話, getKey方法的時間複雜度就是O(1),如果Hash演算法技術的結果碰撞非常多,假如Hash算極其差,所有的Hash演算法結果得出的索引位置-樣,那樣所有的鍵值對都集中到一個桶中,或者在一個鏈表中,或者在一一個紅黑樹中,時間複雜度分別為O(n)和O(lgn)。鑒於JDK1.8做 了多方面的優化,總體性能優於JDK1.7 ,下麵我們從兩個方面用例子證明這一點。 Hash較均勻的情況
為了便於測試,我們先寫一個類Key,如下:


這個類覆寫了equals方法,並且提供了相當好的hashCode函數,任何一個值的hashCode都不會相同,因為直接使用value當做hashcode。為了避免頻繁的GC ,我將不變的Key實例緩存了起來,而不是一遍-遍的創建它們。代碼如下:

現在開始我們的試驗,測試需要做的僅僅是,創建不同size的HashMap(1、10、100、...10000000屏蔽了擴容的情況,代碼如下:

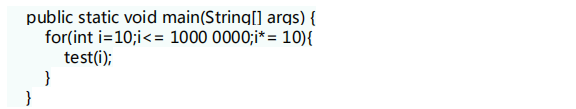
 通過觀測測試結果可知, JDK1.8的性能要高於JDK1.715%以上,在某些size的區域上,甚至高於100%。由於Hash演算法較均勻, JDK1.8引入的紅黑樹效果不明顯,下麵我們看看Hash不均勻的的情況。
Hash極不均勻的情況
通過觀測測試結果可知, JDK1.8的性能要高於JDK1.715%以上,在某些size的區域上,甚至高於100%。由於Hash演算法較均勻, JDK1.8引入的紅黑樹效果不明顯,下麵我們看看Hash不均勻的的情況。
Hash極不均勻的情況假設我們又一一個非常差的Key,它們所有的實例都返回相同的hashCode值。這是使用HashMap最壞的情況。代碼修改如下:
 仍然執行main方法,得出的結果如下表所示:
仍然執行main方法,得出的結果如下表所示:
 從表中結果中可知,隨者isize的變大,JDK1.7的花費時間是增長的趨勢,而JDK1.8是明顯的降低趨勢,並且呈現對數增長穩定。當一個鏈表太長的時候, HashMap會動態的將它替換成一個紅黑樹,這話的話會將時間複雜度從O(n)降為O(logn)。hash演算法均勻和不均勻所花費的時間明顯也不相同,這兩種情況的相對比較,可以說明一一個好的hash演算法的重要性。
小結
從表中結果中可知,隨者isize的變大,JDK1.7的花費時間是增長的趨勢,而JDK1.8是明顯的降低趨勢,並且呈現對數增長穩定。當一個鏈表太長的時候, HashMap會動態的將它替換成一個紅黑樹,這話的話會將時間複雜度從O(n)降為O(logn)。hash演算法均勻和不均勻所花費的時間明顯也不相同,這兩種情況的相對比較,可以說明一一個好的hash演算法的重要性。
小結(1)擴容是一個特別耗性能的操作,所以當程式員在使用HashMap的時候,估算map的大小,初始化的時候給一個大致的數值,避免map進行頻繁的擴容。
(2)負載因數是可以修改的,也可以大於1,但是建議不要輕易修改,除非情況非常特殊。 (3) HashMap是線程不安全的,不要在併發的環境中同時操作HashMap ,建議使用ConcurrentHashMap. (4)JDK1.8引入紅黑樹大程度優化了HashMap的性能。


