
之前說過Python的多線程只能運行在一個單核上,也就是各線程是以併發的方式非同步執行的 這篇文章我們來聊聊Python多進程的方式 多進程依賴於所在機器的處理器個數,在多核機器上進行多進程編程時,各核上運行的進程之間是並行執行的,可以利用進程池,是每一個內核上運行一個進程,當翅中的進程數量大於內核總 ...

之前說過Python的多線程只能運行在一個單核上,也就是各線程是以併發的方式非同步執行的
這篇文章我們來聊聊Python多進程的方式
多進程依賴於所在機器的處理器個數,在多核機器上進行多進程編程時,各核上運行的進程之間是並行執行的,可以利用進程池,是每一個內核上運行一個進程,當翅中的進程數量大於內核總數時,待運行的進程會等待,直至其他進程運行完畢讓出內核
多進程就相當於下麵這種賣票的行為
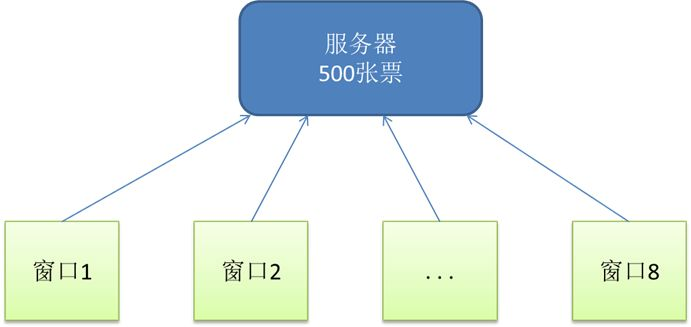
在這裡要註意,當系統內只有一個單核CPU是,多進程並不會發生,此時各進程會依次占用CPU運行至完成
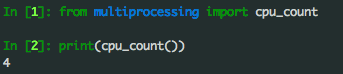
我們可以通過Python的語句會的CPU可用的核數,如下圖
為了形成比較,我們還是使用之前的那個例子,噹噹圖書,搜索關鍵字商品信息的抓取
首先寫出多進程主方法
# coding=utf-8
__Author__ = "susmote"
from multi_threading import mining_func
import multiprocessing
import time
def multiple_process_test():
start_time = time.time()
page_range_list = [
(1, 10),
(11, 20),
(21, 32),
]
pool = multiprocessing.Pool(processes=3)
for page_range in page_range_list:
pool.apply_async(mining_func.get_urls_in_pages, (page_range[0], page_range[1]))
pool.close()
pool.join()
end_time = time.time()
print("抓取時間:", end_time - start_time)
return end_time - start_time
在這裡面,我簡單解釋一下有關多進程的操作
pool被定義為可同時並行3個進程的進程池,然後通過迴圈,使用apply_async方法使進入進程池的進程以非同步的方式並行運行
下麵是主函數
# coding=utf-8
__Author__ = "susmote"
from process_func import multiple_process_test
if __name__ == "__main__":
pt = multiple_process_test()
print("pt : ", pt)
把代碼運行起來,得到如下結果

5.908
再運行一次

3.954
最後一次

4.163
取平均時間

4.341秒
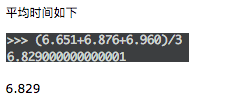
這時我們再回顧上篇文章多線程的情況(同樣網路條件下):
多線程
單線程
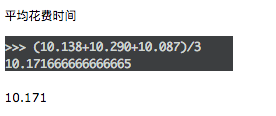
可以看到,差距非常明顯,多進程占絕大優勢
多進程就是這些,你也可以找一個更大的數據池,去試驗這些方法


