
1.Linux操作系統的簡易介紹 Linux系統一般有4個主要部分:內核、shell、文件系統和應用程式。內核、shell和文件系統一起形成了基本的操作系統結構,它們使得用戶可以運行程式、管理文件並使用系統。 (1)內核 內核是操作系統的核心,具有很多最基本功能,如虛擬記憶體、多任務、共用庫、需求載入 ...
1.Linux操作系統的簡易介紹
Linux系統一般有4個主要部分:內核、shell、文件系統和應用程式。內核、shell和文件系統一起形成了基本的操作系統結構,它們使得用戶可以運行程式、管理文件並使用系統。
(1)內核
內核是操作系統的核心,具有很多最基本功能,如虛擬記憶體、多任務、共用庫、需求載入、可執行程式和TCP/IP網路功能。Linux內核的模塊分為以下幾個部分:存儲管理、CPU和進程管理、文件系統、設備管理和驅動、網路通信、系統的初始化和系統調用等。
(2)shell
shell是系統的用戶界面,提供了用戶與內核進行交互操作的一種介面。它接收用戶輸入的命令並把它送入內核去執行,是一個命令解釋器。另外,shell編程語言具有普通編程語言的很多特點,用這種編程語言編寫的shell程式與其他應用程式具有同樣的效果。
(3)文件系統
文件系統是文件存放在磁碟等存儲設備上的組織方法。Linux系統能支持多種目前流行的文件系統,如EXT2、EXT3、FAT、FAT32、VFAT和ISO9660。
(4)應用程式
標準的Linux系統一般都有一套都有稱為應用程式的程式集,它包括文本編輯器、編程語言、XWindow、辦公套件、Internet工具和資料庫等。
2.Linux操作系統的進程組織
(1)什麼是進程
進程是處於執行期的程式以及它所包含的所有資源的總稱,包括虛擬處理器,虛擬空間,寄存器,堆棧,全局數據段等。
在Linux中,每個進程在創建時都會被分配一個數據結構,稱為進程式控制制(Process Control Block,簡稱PCB)。PCB中包含了很多重要的信息,供系統調度和進程本身執行使用。所有進程的PCB都存放在內核空間中。PCB中最重要的信息就是進程PID,內核通過這個PID來唯一標識一個進程。PID可以迴圈使用,最大值是32768。init進程的pid為1,其他進程都是init進程的後代。
除了進程式控制制塊(PCB)以外,每個進程都有獨立的內核堆棧(8k),一個進程描述符結構,這些數據都作為進程的控制信息儲存在內核空間中;而進程的用戶空間主要存儲代碼和數據。
查看進程:
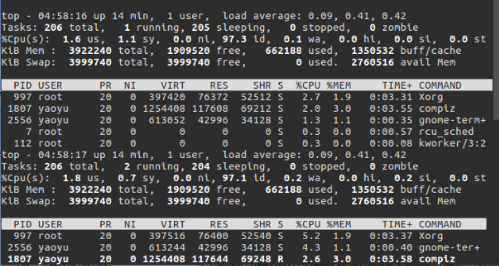
(2)進程創建
進程是通過調用::fork(),::vfork()【只複製task_struct和內核堆棧,所以生成的只是父進程的一個線程(無獨立的用戶空間)。】和::clone()【功能強大,帶了許多參數。::clone()可以讓你有選擇性的繼承父進程的資源,既可以選擇像::vfork()一樣和父進程共用一個虛擬空間,從而使創造的是線程,你也可以不和父進程共用,你甚至可以選擇創造出來的進程和父進程不再是父子關係,而是兄弟關係。】系統調用創建新進程。在內核中,它們都是調用do_fork實現的。傳統的fork函數直接把父進程的所有資源複製給子進程。而Linux的::fork()使用寫時拷貝頁實現,也就是說,父進程和子進程共用同一個資源拷貝,只有當數據發生改變時,數據才會發生複製。通常的情況,子進程創建後會立即調用exec(),這樣就避免複製父進程的全部資源。
#fork():父進程的所有數據結構都會複製一份給子進程(寫時拷貝頁)。當執行fork()函數後,會生成一個子進程,子進程的執行從fork()的返回值開始,且代碼繼續往下執行
以下代碼中,使用fork()創建了一個子進程。返回值pId有兩個作用:一是判斷fork()是否正常執行;二是判斷fork()正常執行後如何區分父子進程。
1 #代碼示例: 2 #include <stdio.h> 3 #include <stdlib.h> 4 #include <unistd.h> 5 6 int main (int argc, char ** argv) { 7 int flag = 0; 8 pid_t pId = fork(); 9 if (pId == -1) { 10 perror("fork error"); 11 exit(EXIT_FAILURE); 12 } else if (pId == 0) { 13 int myPid = getpid(); 14 int parentPid = getppid(); 15 16 printf("Child:SelfID=%d ParentID=%d \n", myPid, parentPid); 17 flag = 123; 18 printf("Child:flag=%d %p \n", flag, &flag); 19 int count = 0; 20 do { 21 count++; 22 sleep(1); 23 printf("Child count=%d \n", count); 24 if (count >= 5) { 25 break; 26 } 27 } while (1); 28 return EXIT_SUCCESS; 29 } else { 30 printf("Parent:SelfID=%d MyChildPID=%d \n", getpid(), pId); 31 flag = 456; 32 printf("Parent:flag=%d %p \n", flag, &flag); // 連地址都一樣,說明是真的完全拷貝,但值已經是不同的了.. 33 int count = 0; 34 do { 35 count++; 36 sleep(1); 37 printf("Parent count=%d \n", count); 38 if (count >= 2) { 39 break; 40 } 41 } while (1); 42 } 43 44 return EXIT_SUCCESS; 45 }
(3)進程撤銷
進程通過調用exit()退出執行,這個函數會終結進程並釋放所有的資源。父進程可以通過wait4()查詢子進程是否終結。進程退出執行後處於僵死狀態,直到它的父進程調用wait()或者waitpid()為止。父進程退出時,內核會指定線程組的其他進程或者init進程作為其子進程的新父進程。當進程接收到一個不能處理或忽視的信號時,或當在內核態產生一個不可恢復的CPU異常而內核此時正代表該進程在運行,內核可以強迫進程終止。
(4)進程管理
內核把進程信息存放在叫做任務隊列(task list)的雙向迴圈鏈表中(內核空間)。鏈表中的每一項都是類型為task_struct,稱為進程描述符結構(process descriptor),包含了一個具體進程的所有信息,包括打開的文件,進程的地址空間,掛起的信號,進程的狀態等。
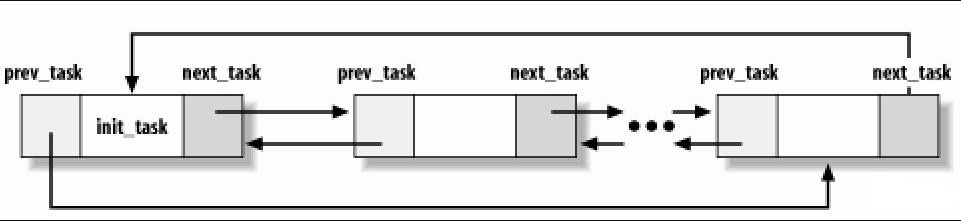
Linux通過slab分配器分配task_struct,這樣能達到對象復用和緩存著色(通過預先分配和重覆使用task_struct,可以避免動態分配和釋放所帶來的資源消耗)。

struct task_struct { volatile long state; pid_t pid; unsigned long timestamp; unsigned long rt_priority; struct mm_struct *mm, *active_mm }
對於向下增長的棧來說,只需要在棧底(對於向上增長的棧則在棧頂)創建一個新的結構struct thread_info,使得在彙編代碼中計算其偏移量變得容易。
#在x86上,thread_info結構在文件<asm/thread_info.h>中定義如下:
struct thread_info{ struct task_struct *任務 struct exec_domain *exec_domain; unsigned long flags; unsigned long status; __u32 cpu; __s32 preempt_count; mm_segment_t addr_limit; struct restart_block restart_block; unsigned long previous_esp; _u8 supervisor_stack[0]; };
內核把所有處於TASK_RUNNING狀態的進程組織成一個可運行雙向迴圈隊列。調度函數通過掃描整個可運行隊列,取得最值得執行的進程投入執行。避免掃描所有進程,提高調度效率。
#進程調度使用schedule()函數來完成,下麵我們從分析該函數開始,代碼如下: 1 asmlinkage __visible void __sched schedule(void) 2 { 3 struct task_struct *tsk = current; 4 5 sched_submit_work(tsk); 6 __schedule(); 7 } 8 EXPORT_SYMBOL(schedule);
#在第4段進程調度中將具體講述功能實現
(5)進程內核堆棧
Linux為每個進程分配一個8KB大小的記憶體區域,用於存放該進程兩個不同的數據結構:thread_info和進程的內核堆棧。
進程處於內核態時使用不同於用戶態堆棧,內核控制路徑所用的堆棧很少,因此對棧和描述符來說,8KB足夠了。
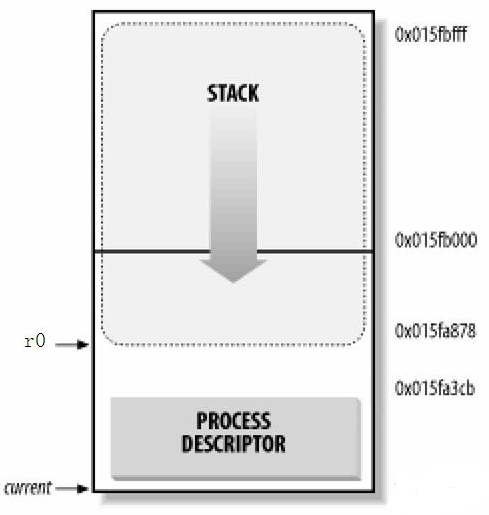
3.Linux操作系統的進程狀態轉換
有以下進程狀態:
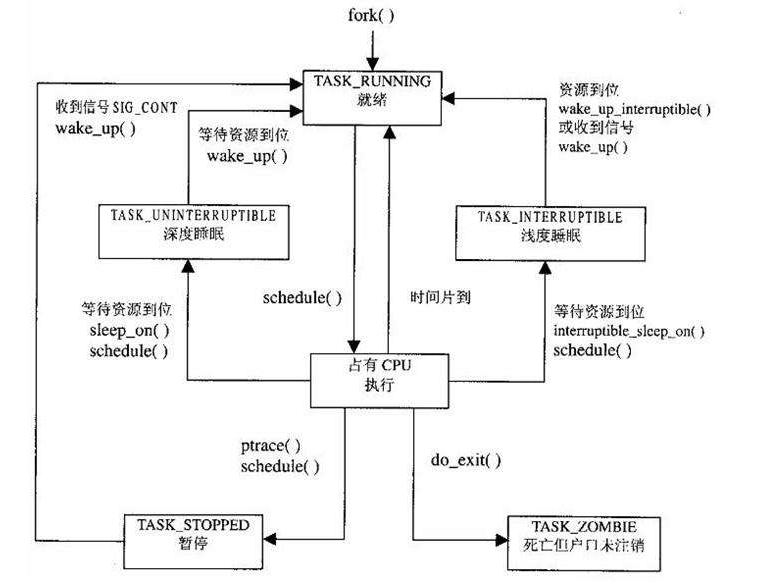
進程狀態的轉換:
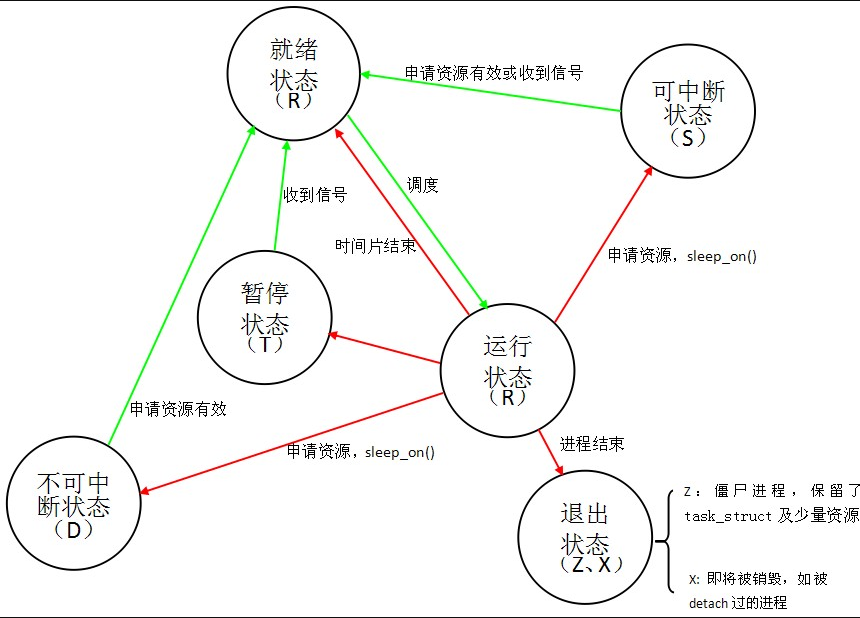
具體轉換分析:
(1)進程的初始狀態
進程是通過fork系列的系統調用(fork、clone、vfork)來創建的,內核(或內核模塊)也可以通過kernel_thread函數創建內核進程。這些創建子進程的函數本質上都完成了相同的功能——將調用進程複製一份,得到子進程。(可以通過選項參數來決定各種資源是共用、還是私有。)那麼既然調用進程處於TASK_RUNNING狀態(否則,它若不是正在運行,又怎麼進行調用?),則子進程預設也處於TASK_RUNNING狀態。另外,在系統調用調用clone和內核函數kernel_thread也接受CLONE_STOPPED選項,從而將子進程的初始狀態置為 TASK_STOPPED。
(2)進程狀態變遷
進程自創建以後,狀態可能發生一系列的變化,直到進程退出。而儘管進程狀態有好幾種,但是進程狀態的變遷卻只有兩個方向——從TASK_RUNNING狀態變為非TASK_RUNNING狀態、或者從非TASK_RUNNING狀態變為TASK_RUNNING狀態。也就是說,如果給一個TASK_INTERRUPTIBLE狀態的進程發送SIGKILL信號,這個進程將先被喚醒(進入 TASK_RUNNING狀態),然後再響應SIGKILL信號而退出(變為TASK_DEAD狀態)。並不會從TASK_INTERRUPTIBLE狀態直接退出。進程從非TASK_RUNNING狀態變為TASK_RUNNING狀態,是由別的進程(也可能是中斷處理程式)執行喚醒操作來實現的。執行喚醒的進程設置被喚醒進程的狀態為TASK_RUNNING,然後將其task_struct結構加入到某個CPU的可執行隊列中。於是被喚醒的進程將有機會被調度執行。
而進程從TASK_RUNNING狀態變為非TASK_RUNNING狀態,則有兩種途徑:
- 響應信號而進入TASK_STOPED狀態、或TASK_DEAD狀態;
- 執行系統調用主動進入TASK_INTERRUPTIBLE狀態(如nanosleep系統調用)、或TASK_DEAD狀態(如exit 系統調用);或由於執行系統調用需要的資源得不到滿足,而進入TASK_INTERRUPTIBLE狀態或TASK_UNINTERRUPTIBLE狀態(如select系統調用)。
4.Linux操作系統的進程調度
毋庸置疑,我們使用schedule()函數來完成進程調度,接下來就來看看進程調度的代碼以及實現過程吧。
1 asmlinkage __visible void __sched schedule(void) 2 { 3 struct task_struct *tsk = current; 4 5 sched_submit_work(tsk); 6 __schedule(); 7 } 8 EXPORT_SYMBOL(schedule);
第3行獲取當前進程描述符指針,存放在本地變數tsk中。第6行調用__schedule(),代碼如下(kernel/sched/core.c):


1 static void __sched __schedule(void) 2 { 3 struct task_struct *prev, *next; 4 unsigned long *switch_count; 5 struct rq *rq; 6 int cpu; 7 8 need_resched: 9 preempt_disable(); 10 cpu = smp_processor_id(); 11 rq = cpu_rq(cpu); 12 rcu_note_context_switch(cpu); 13 prev = rq->curr; 14 15 schedule_debug(prev); 16 17 if (sched_feat(HRTICK)) 18 hrtick_clear(rq); 19 20 /* 21 * Make sure that signal_pending_state()->signal_pending() below 22 * can't be reordered with __set_current_state(TASK_INTERRUPTIBLE) 23 * done by the caller to avoid the race with signal_wake_up(). 24 */ 25 smp_mb__before_spinlock(); 26 raw_spin_lock_irq(&rq->lock); 27 28 switch_count = &prev->nivcsw; 29 if (prev->state && !(preempt_count() & PREEMPT_ACTIVE)) { 30 if (unlikely(signal_pending_state(prev->state, prev))) { 31 prev->state = TASK_RUNNING; 32 } else { 33 deactivate_task(rq, prev, DEQUEUE_SLEEP); 34 prev->on_rq = 0; 35 36 /* 37 * If a worker went to sleep, notify and ask workqueue 38 * whether it wants to wake up a task to maintain 39 * concurrency. 40 */ 41 if (prev->flags & PF_WQ_WORKER) { 42 struct task_struct *to_wakeup; 43 44 to_wakeup = wq_worker_sleeping(prev, cpu); 45 if (to_wakeup) 46 try_to_wake_up_local(to_wakeup); 47 } 48 } 49 switch_count = &prev->nvcsw; 50 } 51 52 if (prev->on_rq || rq->skip_clock_update < 0) 53 update_rq_clock(rq); 54 55 next = pick_next_task(rq, prev); 56 clear_tsk_need_resched(prev); 57 clear_preempt_need_resched(); 58 rq->skip_clock_update = 0; 59 60 if (likely(prev != next)) { 61 rq->nr_switches++; 62 rq->curr = next; 63 ++*switch_count; 64 65 context_switch(rq, prev, next); /* unlocks the rq */ 66 /* 67 * The context switch have flipped the stack from under us 68 * and restored the local variables which were saved when 69 * this task called schedule() in the past. prev == current 70 * is still correct, but it can be moved to another cpu/rq. 71 */ 72 cpu = smp_processor_id(); 73 rq = cpu_rq(cpu); 74 } else 75 raw_spin_unlock_irq(&rq->lock); 76 77 post_schedule(rq); 78 79 sched_preempt_enable_no_resched(); 80 if (need_resched()) 81 goto need_resched; 82 }static void __sched __schedule(void)
第9行禁止內核搶占。第10行獲取當前的cpu號。第11行獲取當前cpu的進程運行隊列。第13行將當前進程的描述符指針保存在prev變數中。第55行將下一個被調度的進程描述符指針存放在next變數中。第56行清除當前進程的內核搶占標記。第60行判斷當前進程和下一個調度的是不是同一個進程,如果不是的話,就要進行調度。第65行,對當前進程和下一個進程的上下文進行切換(調度之前要先切換上下文)。下麵看看該函數(kernel/sched/core.c):
1 context_switch(struct rq *rq, struct task_struct *prev, 2 struct task_struct *next) 3 { 4 struct mm_struct *mm, *oldmm; 5 6 prepare_task_switch(rq, prev, next); 7 8 mm = next->mm; 9 oldmm = prev->active_mm; 10 /* 11 * For paravirt, this is coupled with an exit in switch_to to 12 * combine the page table reload and the switch backend into 13 * one hypercall. 14 */ 15 arch_start_context_switch(prev); 16 17 if (!mm) { 18 next->active_mm = oldmm; 19 atomic_inc(&oldmm->mm_count); 20 enter_lazy_tlb(oldmm, next); 21 } else 22 switch_mm(oldmm, mm, next); 23 24 if (!prev->mm) { 25 prev->active_mm = NULL; 26 rq->prev_mm = oldmm; 27 } 28 /* 29 * Since the runqueue lock will be released by the next 30 * task (which is an invalid locking op but in the case 31 * of the scheduler it's an obvious special-case), so we 32 * do an early lockdep release here: 33 */ 34 #ifndef __ARCH_WANT_UNLOCKED_CTXSW 35 spin_release(&rq->lock.dep_map, 1, _THIS_IP_); 36 #endif 37 38 context_tracking_task_switch(prev, next); 39 /* Here we just switch the register state and the stack. */ 40 switch_to(prev, next, prev); 41 42 barrier(); 43 /* 44 * this_rq must be evaluated again because prev may have moved 45 * CPUs since it called schedule(), thus the 'rq' on its stack 46 * frame will be invalid. 47 */ 48 finish_task_switch(this_rq(), prev); 49 }context_switch(struct rq *rq, struct task_struct *prev, struct task_struct *next)
上下文切換一般分為兩個,一個是硬體上下文切換(指的是cpu寄存器,要把當前進程使用的寄存器內容保存下來,再把下一個程式的寄存器內容恢復),另一個是切換進程的地址空間(說白了就是程式代碼)。進程的地址空間(程式代碼)主要保存在進程描述符中的struct mm_struct結構體中,因此該函數主要是操作這個結構體。第17行如果被調度的下一個進程地址空間mm為空,說明下個進程是個線程,沒有獨立的地址空間,共用所屬進程的地址空間,因此第18行將上個進程所使用的地址空間active_mm指針賦給下一個進程的該域,下一個進程也使用這個地址空間。第22行,如果下個進程地址空間不為空,說明下個進程有自己的地址空間,那麼執行switch_mm切換進程頁表。第40行切換進程的硬體上下文。 switch_to函數代碼如下(arch/x86/include/asm/switch_to.h):
1 __visible __notrace_funcgraph struct task_struct * 2 __switch_to(struct task_struct *prev_p, struct task_struct *next_p) 3 { 4 struct thread_struct *prev = &prev_p->thread, 5 *next = &next_p->thread; 6 int cpu = smp_processor_id(); 7 struct tss_struct *tss = &per_cpu(init_tss, cpu); 8 fpu_switch_t fpu; 9 10 /* never put a printk in __switch_to... printk() calls wake_up*() indirectly */ 11 12 fpu = switch_fpu_prepare(prev_p, next_p, cpu); 13 14 /* 15 * Reload esp0. 16 */ 17 load_sp0(tss, next); 18 19 /* 20 * Save away %gs. No need to save %fs, as it was saved on the 21 * stack on entry. No need to save %es and %ds, as those are 22 * always kernel segments while inside the kernel. Doing this 23 * before setting the new TLS descriptors avoids the situation 24 * where we temporarily have non-reloadable segments in %fs 25 * and %gs. This could be an issue if the NMI handler ever 26 * used %fs or %gs (it does not today), or if the kernel is 27 * running inside of a hypervisor layer. 28 */ 29 lazy_save_gs(prev->gs); 30 31 /* 32 * Load the per-thread Thread-Local Storage descriptor. 33 */ 34 load_TLS(next, cpu); 35 36 /* 37 * Restore IOPL if needed. In normal use, the flags restore 38 * in the switch assembly will handle this. But if the kernel 39 * is running virtualized at a non-zero CPL, the popf will 40 * not restore flags, so it must be done in a separate step. 41 */ 42 if (get_kernel_rpl() && unlikely(prev->iopl != next->iopl)) 43 set_iopl_mask(next->iopl); 44 45 /* 46 * If it were not for PREEMPT_ACTIVE we could guarantee that the 47 * preempt_count of all tasks was equal here and this would not be 48 * needed. 49 */ 50 task_thread_info(prev_p)->saved_preempt_count = this_cpu_read(__preempt_count); 51 this_cpu_write(__preempt_count, task_thread_info(next_p)->saved_preempt_count); 52 53 /* 54 * Now maybe handle debug registers and/or IO bitmaps 55 */ 56 if (unlikely(task_thread_info(prev_p)->flags & _TIF_WORK_CTXSW_PREV || 57 task_thread_info(next_p)->flags & _TIF_WORK_CTXSW_NEXT)) 58 __switch_to_xtra(prev_p, next_p, tss); 59 60 /* 61 * Leave lazy mode, flushing any hypercalls made here. 62 * This must be done before restoring TLS segments so 63 * the GDT and LDT are properly updated, and must be 64 * done before math_state_restore, so the TS bit is up 65 * to date. 66 */ 67 arch_end_context_switch(next_p); 68 69 this_cpu_write(kernel_stack, 70 (unsigned long)task_stack_page(next_p) + 71 THREAD_SIZE - KERNEL_STACK_OFFSET); 72 73 /* 74 * Restore %gs if needed (which is common) 75 */ 76 if (prev->gs | next->gs) 77 lazy_load_gs(next->gs); 78 79 switch_fpu_finish(next_p, fpu); 80 81 this_cpu_write(current_task, next_p); 82 83 return prev_p; 84 }__visible __notrace_funcgraph struct task_struct * __switch_to(struct task_struct *prev_p, struct task_struct *next_p)
該函數主要是對剛切換過來的新進程進一步做些初始化工作。比如第34將該進程使用的線程局部存儲段(TLS)裝入本地cpu的全局描述符表。第84行返回語句會被編譯成兩條彙編指令,一條是將返回值prev_p保存到eax寄存器,另外一個是ret指令,將內核棧頂的元素彈出eip寄存器,從這個eip指針處開始執行,也就是上個函數第17行所壓入的那個指針。一般情況下,被壓入的指針是上個函數第20行那個標號1所代表的地址,那麼從__switch_to函數返回後,將從標號1處開始運行。
需要註意的是,對於已經被調度過的進程而言,從__switch_to函數返回後,將從標號1處開始運行;但是對於用fork(),clone()等函數剛創建的新進程(未調度過),將進入ret_from_fork()函數,因為do_fork()函數在創建好進程之後,會給進程的thread_info.ip賦予ret_from_fork函數的地址,而不是標號1的地址,因此它會跳入ret_from_fork函數。後邊我們在分析fork系統調用的時候,就會看到。
5.對於Linux操作系統進程模型的一些個人看法
有一個形象的比喻:想象一位知識淵博、經驗豐富的工程建築設計師正在為一個公司設計總部。他有公司建築的設計圖,有所需的建築材料和工具:水泥、鋼筋、木板、挖掘機、弔升機、石鑽頭等。在這個比喻中,設計圖就是程式(即用適當形式描述的演算法),工程建築師就是處理器(CPU),而建築的各種材料就是輸入數據。進程就是建築工程設計師閱讀設計圖、取來各種材料和工具以及管理工人員工和分配資源、最後施工等一系列動作的總和,在過程中工程建築師還需要遵循許多設計的規範和理念(模型),最後完成的公司總部就是軟體或者可以實現某種功能的源代碼。
這裡說明的是進程是某種類型的一個活動,它有程式、輸入、輸出以及狀態。單個處理器可以被若幹進程共用,它使用某種調度演算法決定何時停止一個進程的工作,並轉而為另一個進程提供服務。那麼Linux操作系統進程模型就是活動的規範,規範的出現創新讓許多實現過程更加系統完整、安全可靠、速度效率等。
就像人類基於理論實踐偉大的工程設計智慧經驗結晶,Linux操作系統是系統、效率、安全的,而且通過商業公司、龐大的社區群體、操作系統愛好者是在往前改善的,但如果有一天Linux操作系統閉源了,只有國內開放了源代碼,還尚未掌握核心技術,卡住脖子怎麼辦?我們不能擁有完完全全拿來即用的心態,還需扎實掌握基礎知識,提高自我創新意識。對於Linux操作系統進程模型,深入理解它,你會發現在Linux操作系統的應用實踐上會愈加效率,同時通過它你可以實現更多好玩的操作。
6.參考資料
源碼地址(https://elixir.bootlin.com/linux/v4.6/source)
腳本之家(http://www.jb51.net/)
CSDN博客(https://blog.csdn.net/)
百度知道(https://zhidao.baidu.com/)


