
本文由 網易雲 發佈。 在之前的文章中簡要介紹了Join在大數據領域中的使用背景以及常用的幾種演算法-broadcast hash join 、shuffle hash join以及 sort merge join等,對每一種演算法的核心應用場景也做了相關介紹,這裡再重點說明一番:大表與小表進行join ...
本文由 網易雲 發佈。
在之前的文章中簡要介紹了Join在大數據領域中的使用背景以及常用的幾種演算法-broadcast hash join 、shuffle hash join以及 sort merge join等,對每一種演算法的核心應用場景也做了相關介紹,這裡再重點說明一番:大表與小表進行join會使用broadcast hash join,一旦小表稍微大點不再適合廣播分發就會選擇shuffle hash join,最後,兩張大表的話無疑選擇sort merge join。
好了,問題來了,說是這麼一說,但到底選擇哪種演算法歸根結底是SQL執行引擎乾的事情,按照上文邏輯,SQL執行引擎肯定要知 道參與Join的兩表大小,才能選擇最優的演算法嘍!那麼斗膽問一句,怎麼知道兩表大小?衡量兩表大小的是物理大小還是紀錄多少 抑或兩者都有?其實,這是另一門學問-基於代價優化(Cost Based Optimization,簡稱CBO),它不僅能夠解釋Join演算法的選 擇問題,更重要的,它還能確定多表聯合Join場景下的Join順序問題。
是不是對CBO很期待呢?好吧,這裡先刨個坑,下一個話題我們再聊。那今天要聊點什麼呢?Join演算法選擇、Join順序選擇確實對 Join性能影響極大,但,還有一個很重要的因素對Join的性能至關重要,那就是Join演算法優化!無論是broadcast hash join、 shuffle hash join還是sort merge join,都是最基礎的join演算法,有沒有什麼優化方案呢?還真有,這就是今天要聊的主角- Runtime Filter(下文簡稱RF)。
RF預備知識:bloom filter
RF說白了是使用bloomfilter對參與join的表進行過濾,減少實際參與join的數據量。為了下文詳細解釋整個流程,有必要先解釋一 下bloomfilter這個數據結構(對之熟悉的看官可以繞道)。Bloom Filter使用位數組來實現過濾,初始狀態下位數組每一位都為 0,如下圖所示:

假如此時有一個集合S = {x1,x2,...,xn},Bloom Filter使用k個獨立的hash函數,分別將集合中的每一個元素映射到{1,…,m}的範圍。 對於任何一個元素,被映射到的數字作為對應的位數組的索引,該位會被置為1。比如元素x1被hash函數映射到數字8,那麼位數組 的第8位就會被置為1。下圖中集合S只有兩個元素x和y,分別被3個hash函數進行映射,映射到的位置分別為(0,3,6)和(4,7,10),對 應的位會被置為1:
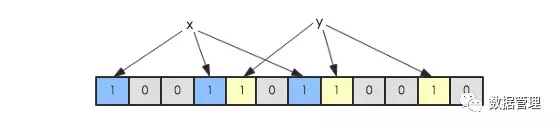
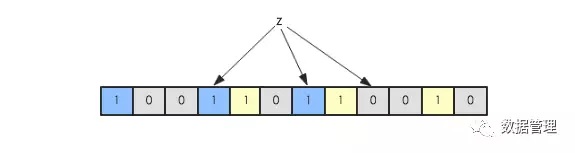
現在假如要判斷另一個元素是否是在此集合中,只需要被這3個hash函數進行映射,查看對應的位置是否有0存在,如果有的話,表 示此元素肯定不存在於這個集合,否則有可能存在。下圖所示就表示z肯定不在集合{x,y}中:
RF演算法理論
為了更好地說明整個過程,這裡使用一個SQL示例對RF演算法進行完整講解,SQL:select item.name,order.* from order,item where order.item_id = item.id and item.category = ‘book’,其中order為訂單表,item為商品表,兩張表根據商品id欄位 進行join,該SQL意為取出商品類別為書籍的所有訂單詳情。假設商品類型為書籍的商品並不多,join演算法因此確定為broadcast hash join。整個流程如下圖所示:
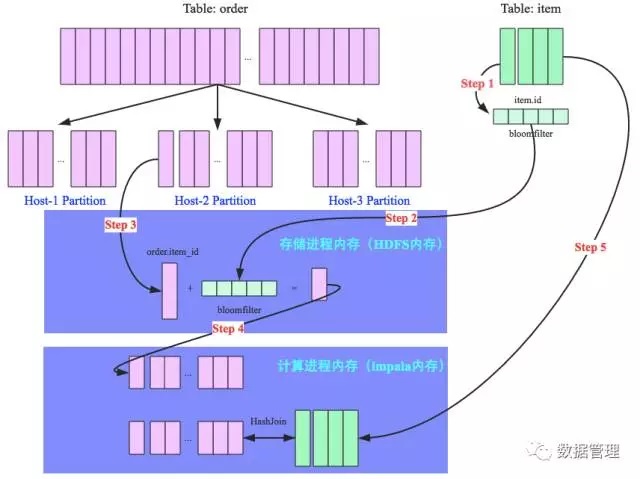
Step 1:將item表的join欄位(item.id)經過多個hash函數映射處理為一個bloomfilter(如果對bloomfilter不瞭解,自行 google);
Step 2:將映射好的bloomfilter分別廣播到order表的所有partition上,準備進行過濾;
Step 3:以Partition2為例,存儲進程(比如DataNode進程)將order表中join列(order.item_id)數據一條一條讀出來,使用 bloomfilter進行過濾。淘汰該訂單數據不是書籍相關商品的訂單,這條數據直接跳過;否則該條訂單數據有可能是待檢索訂單,將 該行數據全部掃描出來;
Step 4:將所有未被bloomfilter過濾掉的訂單數據,通過本地socket通信發送到計算進程(impalad);
Step 5:再將所有書籍商品數據廣播到所有Partition節點與step4所得訂單數據進行真正的hashjoin操作,得到最終的選擇結果。
RF演算法分析
上面通過一個SQL示例簡單演示了整個RF演算法在broadcast hash join中的操作流程,根據流程對該演算法進行一下理論層次分析:
RF本質:通過謂詞( bloomfilter)下推,在存儲層通過bloomfilter對數據進行過濾,可以從三個方面實現對Join的優化。其一, 如果可以跳過很多記錄,就可以減少了數據IO掃描次數。這點需要重點解釋一下,許多朋友會有這樣的疑問:既然需要把數據掃描 出來使用BloomFilter進行過濾,為什麼還會減少IO掃描次數呢?這裡需要關註一個事實:大多數表存儲行為都是列存,列之間獨 立存儲,掃描過濾只需要掃描join列數據(而不是所有列),如果某一列被過濾掉了,其他對應的同一行的列就不需要掃描了,這 樣減少IO掃描次數。其二,減少了數據從存儲層通過socket(甚至TPC)發送到計算層的開銷,其三,減少了最終hash join執行的 開銷。
RF代價:對照未使用RF的Broadcast Hash Join來看,前者主要增加了bloomfilter的生成、廣播以及大表根據bloomfilter進行過 濾這三個開銷。通常情況下,這幾個步驟在小表較小的情況下代價並不大,基本可以忽略。
RF優化效果:基本取決於bloomfilter的過濾效果,如果大量數據被過濾掉了,那麼join的性能就會得到極大提升;否則性能提升就 會有限。
RF實現:和常見的謂詞下推(’=‘,’>’,’<‘等)一樣,RF實現需要在計算層以及存儲層分別進行相關邏輯實現,計算層 要構造bloomfilter並將bloomfilter下傳到存儲層,存儲層要實現使用該bloomfilter對指定數據進行過濾。
RF效果驗證
事實上,RF這個東東的優化效果是在組內同事何大神做impala on parquet以及impala on kudu的基準對比測試的時候分析發現 的。實際測試中,impala on parquet 比之impala on kudu性能有明顯優勢,目測至少10倍性能提升。同一SQL解析引擎,不同 存儲引擎,性能竟然天壤之別!為了分析具體原因,同事就使用impala的執行計劃分析工具對兩者的執行計劃分別進行了分析,才 透過蛛絲馬跡發現前者使用了RF,而後者並沒有(當然可能還有其他因素,但RF肯定是原因之一)。
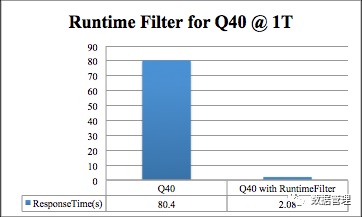
簡單復盤一下這次測試吧,基準測試使用TPCDS測試,數據規模為1T,本文使用測試過程中的一個典型SQL(Q40)作為示例對RF 的神奇功效進行回放演示。下圖是Q40的對比性能,直觀上來看RF可以直接帶來40x的性能提升,40倍哎,這到底是怎麼做到的?
先來簡單看看Q40的SQL語句,如下所示,看起來比較複雜,核心涉及到3個表(catalog_sales join date_dim 、catalog_sales join warehouse 、catalog_sales join item)的join操作:
select
w_state, i_item_id,
sum(case when (cast(d_date as date) <
cast ('1998-04-08' as date))
then cs_sales_price –
coalesce(cr_refunded_cash,0)
else 0 end) as sales_before,
sum(case when (cast(d_date as date) >=
cast ('1998-04-08' as date))
then cs_sales_price –
coalesce(cr_refunded_cash,0)
else 0 end) as sales_after
from
catalog_sales left outer join catalog_returns
on
(catalog_sales.cs_order_number =
catalog_returns.cr_order_number
and catalog_sales.cs_item_sk =
catalog_returns.cr_item_sk),
warehouse, item, date_dim where
i_current_price between 0.99 and 1.49
and item.i_item_sk = catalog_sales.cs_item_sk
and catalog_sales.cs_warehouse_sk =
warehouse.w_warehouse_sk
and catalog_sales.cs_sold_date_sk =
date_dim.d_date_sk
and date_dim.d_date between
'1998-03-09' and '1998-05-08' group by w_state, i_item_id order by w_state, i_item_id limit 100;
典型的星型結構,其中catalog_sales是事實表,其他表為緯度表。本次分析選擇其中catalog_sales join item這個緯度的join。因 為對比測試中兩者的SQL解析引擎都是使用impala,所以SQL執行計劃基本都相同。在此基礎上,來看看執行計劃中單個執行節點 在執行catalog_sales join item操作時由先到後的主要階段耗時,其中只貼出來重要耗時階段(Q40中Join演算法為shuffle hash join,與上文所舉broadcast hash join示例略有不同,不過不影響結論):
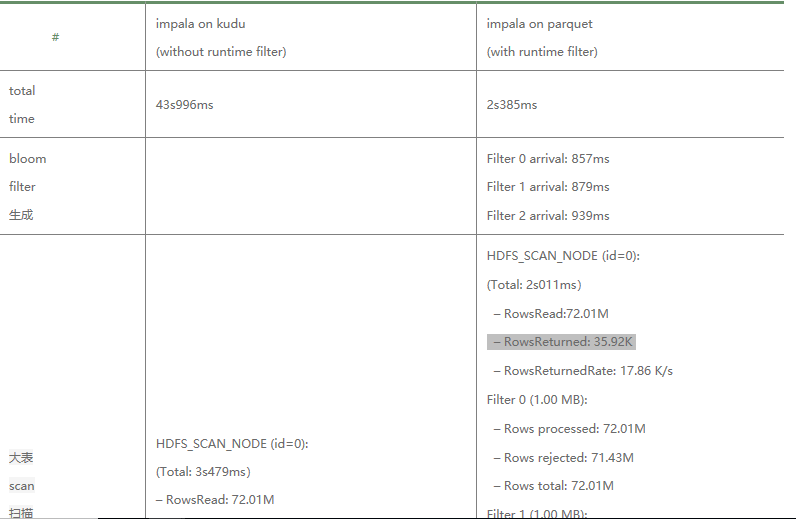
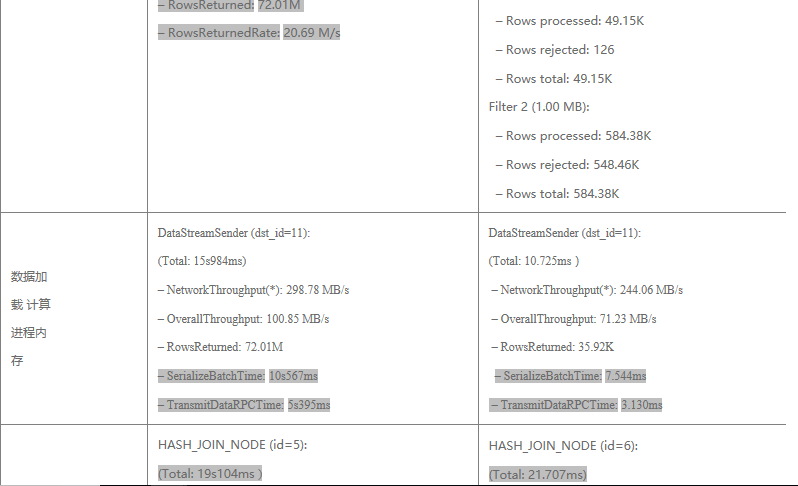
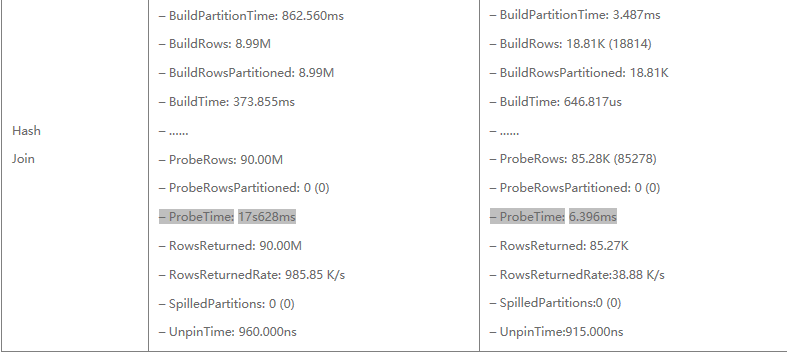
經過對兩種場景執行計劃的解析,可以基本驗證上文所做的基本理論結果:
1. 確認經過RF之後大表的數據量得到大量濾除,只剩下少量數據參與最終的HashJoin。參見第二行大表scan掃描結果,未使用rf的 返回結果有7千萬行+紀錄,而經過RF過濾之後滿足條件的只有3w+紀錄。3萬相比7千萬,性能優化效果自然不言而喻。
2. 經過RF濾除之後,少量數據經過網路從存儲進程載入到計算進程記憶體的網路耗時大量減少。參見第三行“數據載入到計算進程內 存”,前者耗時15s,後者耗時僅僅11ms。主要耗時分為兩部分,其中數據序列化時間占到2/3-10s左右,數據經過RPC傳輸時間 占另外1/3 -5s左右。
3.最後,經過RF濾除之後,參與到最終Hash Join的數量大幅減少,Hash Join 耗時前者是19s,後者是21ms左右,主要耗時在於大表Probe Time,前者消耗了17s左右,而後者僅需6ms。
說好的謂詞下推?
講真,剛開始接觸RF的時候覺得這簡直是一個實實在在的神器,崇拜之情溢於言表。然而,經過一段時間的探索消化,直至把這篇 文章寫完,也就是此時此刻,忽然覺得它並不高深莫測,說白了就是一個謂詞下推,不同的是這裡的謂詞稍微奇怪一點,是一個 bloomfilter而已。
提到謂詞下推,這裡再引申一下下。以前經常滿大街聽到謂詞下推,然而對謂詞下推卻總感覺懵懵懂懂,並不明白的很真切。經過 RF的洗禮,現在確信有了更進一步的理解。這裡拿出來和大家交流交流。個人認為謂詞下推有兩個層面的理解:
其一是邏輯執行計劃優化層面的說法,比如SQL語句:select * from order ,item where item.id = order.item_id and item.category = ‘book’,正常情況語法解析之後應該是先執行Join操作,再執行Filter操作。通過謂詞下推,可以將Filter操作 下推到Join操作之前執行。即將where item.category = ‘book’下推到 item.id = order.item_id之前先行執行。
其二是真正實現層面的說法,謂詞下推是將過濾條件從計算進程下推到存儲進程先行執行,註意這裡有兩種類型進程:計算進程以 及存儲進程。計算與存儲分離思想,這在大數據領域相當常見,比如最常見的計算進程有SparkSQL、Hive、impala等,負責SQL 解析優化、數據計算聚合等,存儲進程有HDFS(DataNode)、Kudu、HBase,負責數據存儲。正常情況下應該是將所有數據從 存儲進程載入到計算進程,再進行過濾計算。謂詞下推是說將一些過濾條件下推到存儲進程,直接讓存儲進程將數據過濾掉。這樣 的好處顯而易見,過濾的越早,數據量越少,序列化開銷、網路開銷、計算開銷這一系列都會減少,性能自然會提高。
寫到這裡,忽然意識到筆者在上文出現了一個很嚴重的認知錯誤:RF機制並不僅僅是一個簡單的謂詞下推,它的精髓在於提出了一 個重要的謂詞-bloomfilter。當前對RF支持的系統並不多,筆者只知道目前唯有Impala on Parquet進行了支持。Impala on Kudu雖說Impala支持,但Kudu並不支持。SparkSQL on Parqeut中雖有存儲系統支持,無奈計算引擎-SparkSQL目前還不支 持。
本文主要介紹了一種類似於semi-join的優化方法,對優化細節進行了深入地探討,並結合分析過程對謂詞下推技術談了談自己的理 解。後續將會為各位看官帶來基於代價優化(CBO)相關的議題,敬請期待!
網易有數
企業級大數據可視化分析平臺。面向業務人員的自助式敏捷分析平臺,採用PPT模式的報告製作,更加易學易用,具備強大的探索分析功能,真正幫助用戶洞察數據發現價值。
點擊這裡---免費試用。
瞭解 網易雲 :
網易雲官網:https://www.163yun.com/
新用戶大禮包:https://www.163yun.com/gift
網易雲社區:https://sq.163yun.com/


