
本文由 網易雲 發佈。 上一篇文章介紹瞭如何搭建Hadoop偽分散式集群,本篇將向大家介紹下Hadoop分散式集群的搭建。內容淺顯,但能夠為新手們提供 一個參考,讓像我一樣的小白們對Hadoop的環境能夠有一定的瞭解。 本文由 網易雲 發佈。 上一篇文章介紹瞭如何搭建Hadoop偽分散式集群,本篇將 ...
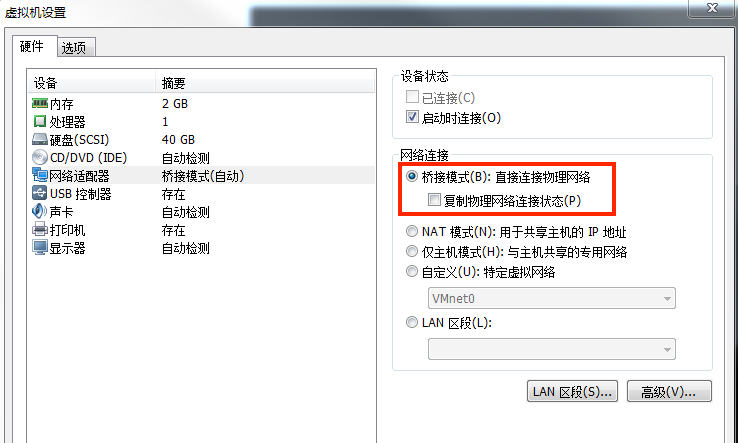
本文由 網易雲 發佈。 上一篇文章介紹瞭如何搭建Hadoop偽分散式集群,本篇將向大家介紹下Hadoop分散式集群的搭建。內容淺顯,但能夠為新手們提供 一個參考,讓像我一樣的小白們對Hadoop的環境能夠有一定的瞭解。 環境: 系統環境:CentOS7.3.1611 64位 Java版本:OpenJDK 1.8.0 使用兩個節點作為集群環境:一個作為Master節點,另一個作為Slave節點 集群搭建流程: Hadoop集群的安裝配置主要流程如下: (1)選定一臺機器作為Master; (2)在Master節點上配置hadoop用戶、Java環境及安裝SSH server; (3)在 Master 節點上安裝 Hadoop,完成配置; (4)其餘機器作為Slave節點,同理,在 Slave 節點上配置 hadoop 用戶、Java環境、安裝 SSH Server; (5)將 Master 節點上的Hadoop安裝目錄內容複製到其他 Slave 節點上; (6)在 Master 節點上開啟 Hadoop; 以上步驟中,配置hadoop用戶、Java環境,安裝SSH server,安裝Hadoop的步驟在《Hadoop單機/偽分散式集群搭建(新手向)》 一文中做了比較詳細的介紹,大家可以參照此文中的步驟來:http://ks.netease.com/blog?id=8333。 集群所有的節點都需要位於同一個區域網,因此在完成上述步驟的前4步驟後,先進行以下的網路配置,實現節點間的互連。 網路配置 本文使用的是VMware虛擬機安裝的系統,所以只需要更改網路連接方式為橋接(Bridge)模式,便能實現節點互連。如圖:
 配置完成後可以在各個節點上查看節點的ip,Linux中查看節點IP地址的命令為:ifconfig,如下圖所示,Master節點的ip為10.240.193.67:
配置完成後可以在各個節點上查看節點的ip,Linux中查看節點IP地址的命令為:ifconfig,如下圖所示,Master節點的ip為10.240.193.67:
 網路配置完成後,便可進行hadoop分散式集群的配置了。
為了能夠方便的區分Master和Slave,我們可以修改節點的主機名用以區分。在CentOS7中,我們在Master節點上執行以下命令來修改 主機名:
sudo vim /etc/hostname
將主機名修改為Master:
網路配置完成後,便可進行hadoop分散式集群的配置了。
為了能夠方便的區分Master和Slave,我們可以修改節點的主機名用以區分。在CentOS7中,我們在Master節點上執行以下命令來修改 主機名:
sudo vim /etc/hostname
將主機名修改為Master:
 同理,修改Slave節點的主機名為Slave。
然後,在Master和Slave節點上都執行如下命令修改IP映射,添加所有節點的IP映射:
sudo vim /etc/hosts
本文中使用的兩個節點的名稱與對應IP關係如下:
同理,修改Slave節點的主機名為Slave。
然後,在Master和Slave節點上都執行如下命令修改IP映射,添加所有節點的IP映射:
sudo vim /etc/hosts
本文中使用的兩個節點的名稱與對應IP關係如下:
 修改完成後需要重啟節點,使得以上配置生效。可以在各個節點上ping其他節點的主機名,若能ping通說明配置成功。
SSH無密碼登陸節點
分散式集群搭建需要Master節點能夠無密碼SSH登陸至各個Slave節點上。因此,我們需要生成Master節點的公鑰,並將Master公鑰 在Slave節點中加入授權。步驟如下:
(1)首先生成Master節點的公鑰,執行如下命令:
cd ~/.ssh --若無該目錄,先執行ssh localhost
rm ./id_rsa* --若已生成過公鑰,則刪除原有的公鑰
ssh-keygen -t rsa --一路回車
(2)Master節點需能無密碼SSH登陸本機,在Master節點上執行命令:
cat ./id_rsa.pub >> ./authorized_keys
chmod 600 ./authorized_keys
若不執行修改許可權,會出現以下問題,仍無法實現無密碼SSH登陸本機。
修改完成後需要重啟節點,使得以上配置生效。可以在各個節點上ping其他節點的主機名,若能ping通說明配置成功。
SSH無密碼登陸節點
分散式集群搭建需要Master節點能夠無密碼SSH登陸至各個Slave節點上。因此,我們需要生成Master節點的公鑰,並將Master公鑰 在Slave節點中加入授權。步驟如下:
(1)首先生成Master節點的公鑰,執行如下命令:
cd ~/.ssh --若無該目錄,先執行ssh localhost
rm ./id_rsa* --若已生成過公鑰,則刪除原有的公鑰
ssh-keygen -t rsa --一路回車
(2)Master節點需能無密碼SSH登陸本機,在Master節點上執行命令:
cat ./id_rsa.pub >> ./authorized_keys
chmod 600 ./authorized_keys
若不執行修改許可權,會出現以下問題,仍無法實現無密碼SSH登陸本機。
 完成後,執行ssh Master驗證是否可以無密碼SSH登陸本機,首次登陸需要輸入yes,輸入exit即可退出登陸。
上述scp命令遠程將Master節點的公鑰拷貝至了Slave節點的/home/hadoop目錄下,執行過程中會要求輸入Slave節點hadoop用戶的密 碼,輸入完成後會顯示傳輸的進度:
完成後,執行ssh Master驗證是否可以無密碼SSH登陸本機,首次登陸需要輸入yes,輸入exit即可退出登陸。
上述scp命令遠程將Master節點的公鑰拷貝至了Slave節點的/home/hadoop目錄下,執行過程中會要求輸入Slave節點hadoop用戶的密 碼,輸入完成後會顯示傳輸的進度:
 (4)在Slave節點上,將Master節點的ssh公鑰加入授權,執行命令:
ssh localhost --執行該命令是為了生成~/.ssh目錄,或者mkdir ~/.ssh創建
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys
(5)至此,已經完成 了Master節點無密碼SSH登陸到Slave節點的配置。在Master節點上輸入命令:ssh Slave 進行驗證,登陸成功如下 圖:
(4)在Slave節點上,將Master節點的ssh公鑰加入授權,執行命令:
ssh localhost --執行該命令是為了生成~/.ssh目錄,或者mkdir ~/.ssh創建
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys
(5)至此,已經完成 了Master節點無密碼SSH登陸到Slave節點的配置。在Master節點上輸入命令:ssh Slave 進行驗證,登陸成功如下 圖:
 配置hadoop分散式環境
配置hadoop分散式環境需要修改hadoop中的五個配置文件,分別為:slaves、core-site.xml、hdfs-site.xml、mapred-site.xml、 yarn-site.xml。具體的配置項及作用可以參考官網的說明,這裡對正常啟動分散式集群所必須的配置項進行配置。
1、slaves
將作為DataNode節點的主機名寫入文件。該文件預設為localhost,因此偽分佈配置時,節點是NameNode的同時也是 DataNode。localhost可以刪除有可以保留。本文Master僅作為NameNode節點,Slave作為DataNode節點,因此刪除localhost。
配置hadoop分散式環境
配置hadoop分散式環境需要修改hadoop中的五個配置文件,分別為:slaves、core-site.xml、hdfs-site.xml、mapred-site.xml、 yarn-site.xml。具體的配置項及作用可以參考官網的說明,這裡對正常啟動分散式集群所必須的配置項進行配置。
1、slaves
將作為DataNode節點的主機名寫入文件。該文件預設為localhost,因此偽分佈配置時,節點是NameNode的同時也是 DataNode。localhost可以刪除有可以保留。本文Master僅作為NameNode節點,Slave作為DataNode節點,因此刪除localhost。
 2、core-site.xml
2、core-site.xml
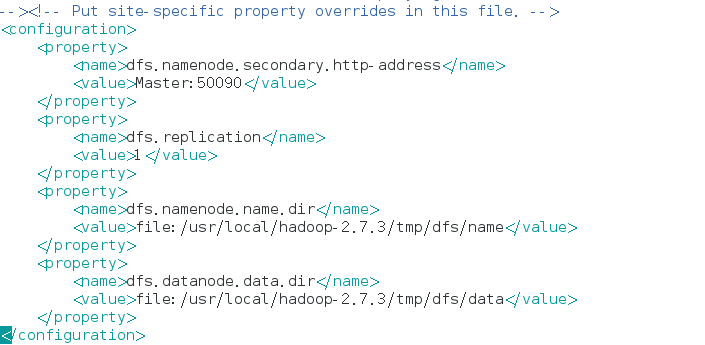
 3、hdfs-site.xml
由於只有一個Slave節點,所有dfs.replication的值設為1。
3、hdfs-site.xml
由於只有一個Slave節點,所有dfs.replication的值設為1。
 4、mapred-site.xml
預設文件名為mapred-site.xml.template,重命名為mapred-site.xml後,修改配置。
4、mapred-site.xml
預設文件名為mapred-site.xml.template,重命名為mapred-site.xml後,修改配置。
 5、yarn-site.xml
5、yarn-site.xml
 配置完成後,將Master上的hadoop文件夾複製到Slave節點上相同路徑下(/usr/local/),並修改文件夾的owner為hadoop。
接著便可啟動分散式hadoop集群了,啟動集群前需要先關閉集群中每個節點的防火牆,否則會引起DataNode啟動了,但Live datanode為0。
啟動分散式集群
首次啟動需要先在Master節點執行NameNode的格式化,命令:
hdfs namenode -format
然後啟動hadoop,hadoop的啟動與關閉需要在Master節點上進行。
啟動hadoop,執行hadoop/sbin中的啟動腳本
cd /usr/local/hadoop/sbin
./start-dfs.sh
./start-yarn.sh
./mr-jobhistory-daemon.sh start historyserver
配置完成後,將Master上的hadoop文件夾複製到Slave節點上相同路徑下(/usr/local/),並修改文件夾的owner為hadoop。
接著便可啟動分散式hadoop集群了,啟動集群前需要先關閉集群中每個節點的防火牆,否則會引起DataNode啟動了,但Live datanode為0。
啟動分散式集群
首次啟動需要先在Master節點執行NameNode的格式化,命令:
hdfs namenode -format
然後啟動hadoop,hadoop的啟動與關閉需要在Master節點上進行。
啟動hadoop,執行hadoop/sbin中的啟動腳本
cd /usr/local/hadoop/sbin
./start-dfs.sh
./start-yarn.sh
./mr-jobhistory-daemon.sh start historyserver
 在Slave節點中可以看到NodeManager和DataNode進程,如圖。
在Slave節點中可以看到NodeManager和DataNode進程,如圖。
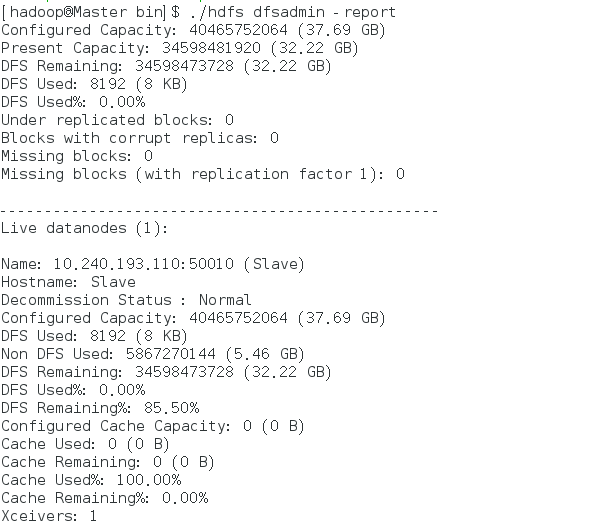
 任一進程缺少都表示啟動出錯。同時,我們還需要在Master節點通過命令hdfs dfsadmin -report查看DataNode是否正常啟動,如果 Live datanode為0,則說明啟動失敗。由於我們只配置了一個DataNode,所以顯示Live datanode為1,如圖。
任一進程缺少都表示啟動出錯。同時,我們還需要在Master節點通過命令hdfs dfsadmin -report查看DataNode是否正常啟動,如果 Live datanode為0,則說明啟動失敗。由於我們只配置了一個DataNode,所以顯示Live datanode為1,如圖。
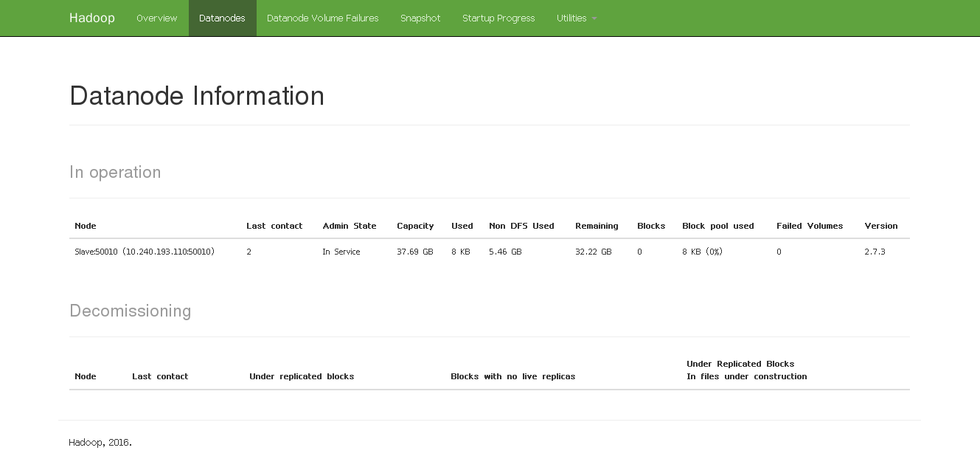
 我們還可以通過web頁面查看DataNode和NameNode的狀態:http://master:50070。
我們還可以通過web頁面查看DataNode和NameNode的狀態:http://master:50070。
 接著我們便可以執行分散式實例了,我們啟動了mr-jobhistory服務,可以通過Web頁http://master:8088/cluster,點擊Tracking UI 中的history查看任務運行信息。
關閉hadoop集群
在Master節點上執行腳本:
stop-yarn.sh
Stop-dfs.sh
Mr-jobhistory-daemon.sh stop historyserver
接著我們便可以執行分散式實例了,我們啟動了mr-jobhistory服務,可以通過Web頁http://master:8088/cluster,點擊Tracking UI 中的history查看任務運行信息。
關閉hadoop集群
在Master節點上執行腳本:
stop-yarn.sh
Stop-dfs.sh
Mr-jobhistory-daemon.sh stop historyserver
網易有數
企業級大數據可視化分析平臺。面向業務人員的自助式敏捷分析平臺,採用PPT模式的報告製作,更加易學易用,具備強大的探索分析功能,真正幫助用戶洞察數據發現價值。
點擊這裡---免費試用。
瞭解 網易雲 :
網易雲官網:https://www.163yun.com/
新用戶大禮包:https://www.163yun.com/gift
網易雲社區:https://sq.163yun.com/


