
轉載請註明出處:http://www.cnblogs.com/qm-article/p/8903893.html 一、介紹 在介紹該源碼之前,先來瞭解一下鏈表,接觸過數據結構的都知道,有種結構叫鏈表,當然鏈表也分多種,如常見的單鏈表、雙鏈表等,單鏈表結構如下圖所示(圖來自百度) 有一個頭結點指著下一 ...
轉載請註明出處:http://www.cnblogs.com/qm-article/p/8903893.html
一、介紹
在介紹該源碼之前,先來瞭解一下鏈表,接觸過數據結構的都知道,有種結構叫鏈表,當然鏈表也分多種,如常見的單鏈表、雙鏈表等,單鏈表結構如下圖所示(圖來自百度)
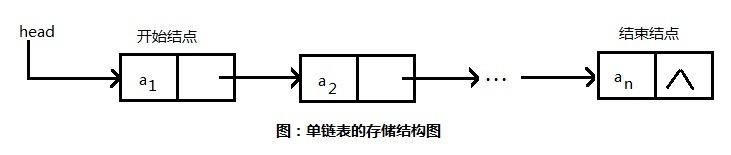
有一個頭結點指著下一個節點的位置,a1節點又存儲著a2節點的記憶體位置....,這樣就構成了一個單鏈表形式,下麵看一下雙鏈表的結構
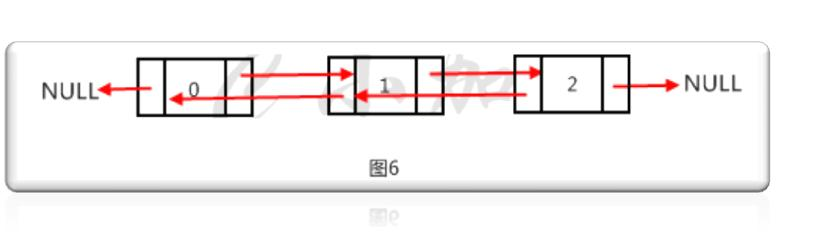
相比於單鏈表結構,雙鏈表的每個節點多存儲了一個數據,就是它的前一個節點的記憶體地址,鏈表和數組的區別如下
1、鏈表的記憶體不一定是連續的,而數組的記憶體地址一定是連續的
2、鏈表的增刪操作快,數組的查詢操作快。
3、數組一旦開闢了記憶體地址,基本上大小是固定的,而鏈表的大小卻不固定。
而這篇博文所介紹的java類就是一個鏈表式結構,而且是一個雙向鏈表,下麵呢,就圍繞著它的使用來進行分析,說起一個數據結構的操作,無非就是增刪改查,接下來來看下該類的源碼設計
二、鏈表設計
如果不先看源碼,讓我們自己來設計一個功能相對簡單的雙向鏈表,那思路該如何,學過面向對象的應該很快就知道,要設計鏈表,而鏈表又是由每個節點構成,那麼就設計一個內部節點類,讓它來表示每個節點,屬性呢,按照常規操作,那肯定有該節點值,該節點的前一個節點,該節點的下一個節點,再配上該類的構造函數,如下麵的代碼
1 private static class Node{//為了簡單,這裡沒使用泛型,僅以int型代表該節點值得類型 2 int val; 3 Node pre; 4 Node next; 5 public Node(int val, Node pre, Node next) { 6 super(); 7 this.val = val; 8 this.pre = pre; 9 this.next = next; 10 } 11 12 }
很簡單,一個內部類設計完成,考慮完每個節點後,那接下來肯定是考慮整個鏈,那肯定要寫一個類,該類含有內部類Node,至於屬性,因為這是雙鏈表,那肯定有頭結點,尾節點,還有鏈表的長度所以很容易就得到下麵這段代碼
1 public class LinkedList { 2 private Node first;//頭結點 3 private Node last;//尾節點 4 private Node size;//鏈表長度 5 6 7 private static class Node{ 8 int val; 9 Node pre; 10 Node next; 11 public Node(int val, Node pre, Node next) { 12 super(); 13 this.val = val; 14 this.pre = pre; 15 this.next = next; 16 } 17 18 } 19 }
既然我們設計出來這個類,那肯定是要用它,用一個數據結構,就像前面說的,就是增刪改查。
2.1、增加
這裡只是簡單的介紹下,增加過程。對於增加節點,可以大致分為這幾類
1、在原頭結點前增加節點
2、在原尾節點前增加節點
3、在頭結點和尾節點之間增加節點
其中的2和3,相信諸位都見得多,那對於1怎麼進行處理呢,繼續看下去
1、若我們是第一次增加,此時頭結點和尾節點都是null,那麼很簡單,直接用增加的節點去同時賦給頭結點和尾節點
2、若不是第一次增加,我們要把結點添加到頭結點之前,首先呢,肯定要獲取頭結點,具體邏輯如下。
1 public void addHeadNode(Node node){ 2 //將頭結點引用賦給臨時節點,避免直接操作first變數 3 Node temp = first; 4 if(temp == null){//表示第一次添加 5 first = node;// 1 6 last = node;//頭結點都為null,那last節點肯定也為null,所以同時賦值給尾節點 7 }else{ 8 temp.pre = node;//將原頭結點的pre指針指向添加節點 9 node.next = temp;//將添加節點的next指針執行原頭結點, 10 first = node;//將添加節點賦給頭結點 ,2 11 } 12 size++;//鏈表長度+1; 13 }
對於以上代碼,標記1和2的兩行代碼其實可以合併的。這裡為了好判別,就區分開來了
那對於類型2,原理和類型1差不多,不做過多解釋,代碼,如下
1 public void addLastNode(Node node){ 2 Node temp = last;//臨時節點 3 if(temp == null){//第一次添加 4 first = node; 5 last = node; 6 }else{ 7 temp.next = node;//將原尾節點next指針執行添加節點 8 node.pre = temp;//將添加節點的pre指針執行原尾節點 9 last = node;//將添加節點設為尾節點 10 } 11 size++;//鏈表長度+1 12 }
對於類型三,相比1和2,要稍微複雜一點,不過其實也差不多,將該種類型擬作類型2,無非就是後面多了節點,語言好像描述不太清楚,大家清楚那個意思就行,如下麵這個邏輯
有鏈表a->b->c->d,(額!這個是雙向鏈表,表達式沒體現出來),閑雜要在b和c直接插入節點e,那麼肯定是用一個臨時變數來替換c節點,如f=b.next,以此來保證該節點不被丟失,千萬不能直接b.next=e,這樣會丟失c後面的節點。之後就基本和類型2一樣,最後再做一個e.next = f,f,pre = e,保證節點的通暢性。代碼如下
1 //preNode代表要在該節點後插入node節點 2 public void add(Node preNode,Node node){ 3 //這裡不作校驗,(本來是要做些preNode是不是不·存在或啥的校驗) 4 Node nextNode = preNode.next; 5 //下麵這兩行代碼是用來preNode和node節點的連通性 6 preNode.next = node; 7 node.pre = preNode; 8 9 //這兩行代碼是保證node節點和nextNode節點的連通性 10 node.next = nextNode; 11 nextNode.pre = node; 12 13 size++; 14 }
2.2、刪除
那對於鏈表的刪除操作呢,也可以類似增加一樣,把它分成三類
1、刪除原有的頭結點,並返回刪除節點值。
2、刪除原有的尾節點,並返回刪除節點值。
3、刪除頭結點和尾節點之間的某一個節點值。
原理和增加類似,不過多敘述,直接上代碼
1 //刪除頭結點 2 public int deleteFirstNode(){ 3 Node temp = first; 4 int oldVal = temp.val; 5 Node next = temp.next; 6 if(temp == null){//說明該鏈表沒有節點 7 throw new RuntimeException("the class do not have head node"); 8 } 9 first = next; 10 first.pre = null; 11 if(next == null){//若條件滿足,則表示鏈表只有一個節點,即first==last為true; 12 last = null; 13 }else{ 14 temp = null; 15 } 16 size--; 17 return oldVal; 18 } 19 20 //刪除尾節點 21 public int deleteLastNode(){ 22 Node temp = last; 23 int oldVal = last.val; 24 Node pre = temp.pre; 25 if(temp == null){//說明該鏈表沒有節點 26 throw new RuntimeException("the class do not have last node"); 27 } 28 last = pre;//把原尾節點的前一個節點作為尾節點 29 if(pre == null){//只有一個節點 30 first = null; 31 }else{ 32 temp = null; 33 } 34 size--; 35 return oldVal; 36 } 37 38 //刪除頭結點和尾節點之間的某個節點,pre為node節點的前一個節點 39 //這裡也不考慮一些特殊情況,也就是刪除節點一定在兩節點之間 40 public int delete(Node pre,Node node){ 41 int oldVal = node.val; 42 Node next = node.next; 43 //構建node前後節點之間的連通性 44 pre.next = next; 45 next.pre = pre; 46 47 node = null; 48 return oldVal; 49 }
2.3、修改
這個操作,很簡單,找到該節點,將該節點值設為新值即可,尋找過程不像數組那樣可以直接定位下標,這個尋找過程要做鏈表的遍歷操作,代碼如下
1 //true代表設值成功,false為設值失敗 2 public boolean set(int oldVal,int newVal){ 3 Node temp = first; 4 while(temp != null){ 5 if(temp.val == oldVal){ 6 temp.val = newVal; 7 return true; 8 } 9 temp = temp.next; 10 } 11 return false; 12 }
2.4、查找
查找和修改類似,只是少了設值這一操作,代碼如下
1 //返回查找的節點 2 public Node find(int val){ 3 Node temp = first; 4 while(temp != null){ 5 if(temp.val == val){ 6 return temp; 7 } 8 temp = temp.next; 9 } 10 return null; 11 }
其實細心的可以發現,要是相同值怎麼辦,說實話,在這裡只會查找到距離頭結點最近的節點,若是用了泛型,則可以對泛型里的類型重寫hash和equals方法來儘量保證唯一性。
--------------------------------------------------------------------------------------------------------------------分界線-------------------------------------------------------------------------------------------------------------------------------------------------------------
上面敘述了一大堆關於自己實現雙向鏈表的操作,那下麵來看看jdk源碼怎麼實現的。
三、源碼分析
關於源碼分析,對於和前面設計類似的原理,避免啰里啰嗦,就一筆帶過
3.1、增加
關於LinkedList的增加方法,有多個增加
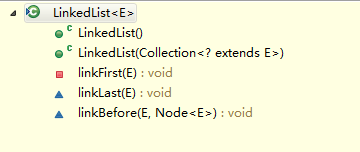

如左圖,第一個和第二個是該類的構造函數,後面三個方法的作用域是private、protected、protected,作用分別為,
1、在頭結點前增加節點
代碼也很比較簡潔,和之前設計的代碼類似,不過多敘述,原理類似,至於modCount的作用,請翻閱之前的一篇博客集合之ArrayList的源碼分析
1 private void linkFirst(E e) { 2 final Node<E> f = first; 3 final Node<E> newNode = new Node<>(null, e, f); 4 first = newNode; 5 if (f == null) 6 last = newNode; 7 else 8 f.prev = newNode; 9 size++; 10 modCount++; 11 }
2、在尾節點後增加節點
1 void linkLast(E e) { 2 final Node<E> l = last; 3 final Node<E> newNode = new Node<>(l, e, null); 4 last = newNode; 5 if (l == null) 6 first = newNode; 7 else 8 l.next = newNode; 9 size++; 10 modCount++; 11 }
3、在頭結點和尾節點之間添加節點
1 void linkBefore(E e, Node<E> succ) { 2 // assert succ != null; 3 final Node<E> pred = succ.prev; 4 final Node<E> newNode = new Node<>(pred, e, succ); 5 succ.prev = newNode; 6 if (pred == null) 7 first = newNode; 8 else 9 pred.next = newNode; 10 size++; 11 modCount++; 12 }
至於右圖,是該類暴露給其他類中使用的。但最後都調用了上述三個方法之一來完成增加操作
經常使用的add(E)方法是預設添加在尾節點後的,
對於add(int,E)方法要註意一下,按照我們正常猜想,先是直接遍歷該鏈表,找到某個節點,在該節點之後插入新節點,但是!!!,這裡並不是這樣的,它是類似數組那樣直接在某個位置插入,別慌,先來貼下代碼
1 public void add(int index, E element) { 2 checkPositionIndex(index);//檢查index的正確性 3 4 if (index == size)//即在尾節點後插入 5 linkLast(element); 6 else 7 linkBefore(element, node(index));//註意這裡的node(int)方法 8 } 9 10 11 Node<E> node(int index) { 12 // assert isElementIndex(index); 13 14 if (index < (size >> 1)) { 15 Node<E> x = first; 16 for (int i = 0; i < index; i++) 17 x = x.next; 18 return x; 19 } else { 20 Node<E> x = last; 21 for (int i = size - 1; i > index; i--) 22 x = x.prev; 23 return x; 24 } 25 }
可以看到node方法里的操作,相比之前直接從頭結點遍歷鏈表的效率要高一點,有點類似折半查找,找到對應的節點,之後操作類似
3.2、刪除
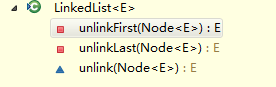

和增加方法一樣,左圖的三個刪除方法是核心,右邊的刪除是暴露給其他方法中使用的,原理和前面說的類似,其中右圖最後兩個方法是怕有兩個相同的obj,所以分了下類,從頭結點開始找,和從尾節點開始找,找到了即刪除。
其中remove()預設的也是移除頭節點
3.3、修改

該類只有這一個方法,
其中也是先利用node方法查找index對應的節點,然後設值。並返回
3.4、查詢
其中get(int)也是利用了node方法來查找對應的node節點
3.5、小結
對於LinkedList的其他方法,這裡不作介紹,我們平時用該類也是圍繞著增刪改查來用,所以這裡只介紹這四類。
4、和ArrayList的比較
一、它們的數據結構不一樣,ArrayList的結構是數組,LinkedList的結構是鏈表,所有它們的記憶體地址排序不一樣,一個是連續的,一個非連續
二、理論上,ArrayList的長度最大為Integer.MAX_VALUE,而鏈表的長度理論上無上限
三、ArrayList的增刪慢,查詢快,LinkedList的增刪快,查詢慢,兩者恰好相反
四、兩者都可以添加null元素,且都可以添加相同元素
五、兩者都有線程安全性問題
5、最後
對於該類,我認為只需要瞭解它內部的增刪改查原理,它的數據結構,它和ArrayList的區別即可。
若有不足或錯誤之處,還望諸位指正

