
模塊初始 sys模塊 import sys sys.path #列印環境變數 sys.argv#列印該文件路徑 #註意:該文件名字不能跟導入模塊名字相同 os模塊 import os cmd_res = os.system("dir")#只執行system命令,不保存結果,返回一個值0代表執行成功, ...
模塊初始
sys模塊
import sys
sys.path #列印環境變數
sys.argv#列印該文件路徑
#註意:該文件名字不能跟導入模塊名字相同
os模塊
import os
cmd_res = os.system("dir")#只執行system命令,不保存結果,返回一個值0代表執行成功,1代表執行失敗
cmd_res = os.popen("dir).read()#執行system命令並且保存結果
os.mkdir("new_dir")#創建一個新的目錄
第三方庫模塊
用戶可以自己編寫自己所需要的模塊來進行調用
.pyc是什麼
當python程式運行時,編譯的結果則是保存在記憶體中的PyCodeObject中,PyCodeObject則是Python編譯器真正編譯成的結果,當Python程式結束運行時,Python解釋器則將PyCodeObject寫到pyc文件中。當python程式第二次運行時,首先程式會在硬碟中尋找pyc文件,如果找到則直接進去,否則就重覆上面的過程。因此Python其實是一門先編譯後解釋的語言。
Python的三元運算
b = a if xxx else c
相當於c++中b = xxx?a:c
Python的str與bytes之間的轉換
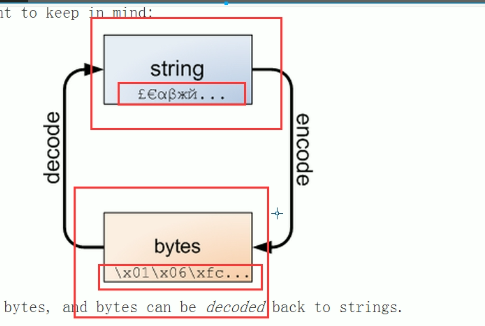
msg.encode(encoding = "utf-8")
msg,decode(encoding = "utf-8")
Python列表的學習
Python列表的格式
names = ["ZhangSan", "LiSi", "WangWu"]
Python的增
names.append("ZhaoLiu")加到後面
names.insert(1, "ls")把ls插到”LiSi”前面
Python的刪
names.remove("ZhanSan")
del names[0]
names. pop[0] 預設為最後一個
Python的改
names[0] = "ls"
Python的查
names.index("ZhangSan") 該字元串所在的下表
names[0] 取第一個列表中的元素
names[0:2] --》names[:2] 取names[0], names[1]包括左邊不包括右邊
names[-1]取最後一個元素
names[-2:]取最後兩個值
Python其他的函數
names.count("ZhangSan") 該字元串的數量
names.clear()清空列表
names.reverse()列表進行反轉
names.sort()列表排序
extend用法
names2 = [1, 2, 3]
names.extend(names2)
names = ["ZhangSan", "LiSi", "WangWu", 1, 2, 3]
Python的copy函數
淺拷貝
names = ["a", "b", "c", "d"]
names2 = names.copy()
names[1] = "B"
-->names = ["a", "B", "c", "d"]
--> names2 = ["a", "b", "c", "d"]
names = ["a", "b", "c", [1, 2 ,3], "d"]
names2 = names.copy()
names[3][0] = 10
-->names = ["a", "b", "c", [10, 2 ,3], "d"]
-->names = ["a", "b", "c", [10, 2 ,3], "d"]
由此可以看出copy為淺拷貝,只拷貝第一層,也就是說只拷貝了記憶體地址(引用)
深拷貝
import copy
names2 = copy.deepcopy(names)
列表的迴圈
names = ["a", "b", "c", "d"]
for i in names[0:-1:2]:
print(i)
-->['a', ' c']
for k, v in enumerate(names):
print(i, k)
-->0 a
1 b
2 c
3 d
Python元組的學習
元組跟列表差不多,只不過它一旦創建,便不能在進行修改,所以又叫只讀列表
寫法:names = ("a", "b", "c")
Python的字元串的一些操作
names = "my name is jason!"
names.capitalize() -->My Name Is Jason! 首字元大寫
names.count("a") -->2 a的個數
names.center(20, "-") -->--------My Name Is Jason!----------列印20個字元不夠用-來,字元串放中間
names.endswith("on!") -->True 字元串是否以什麼結尾
names2 = "my \tname is jason!"
names2.expandtabs(tabsize = 20) -->my name is jason!
names.find("names") -->4 查找第一個出現的字元串
names3 = "my name is{_name}, i am {_age}!"
names3 .format(_name= "Jason", _age= 24)
-->my name is Jason, i am 24!
names.isalnum() 是否是阿拉伯數字
names.isalpha() 是否是字元
names.isdecimal() 是否是十進位
names.isdigit() 是否是整數
names.isidentifier() 是否是合法字元
names.isnumeric() 是否是數字(只有數字,不能有.)
等等
Python的字典操作
python的數據類型key_value相當於lua中的table,c++中的map
字典的寫法
info_dic = {
"a":"廣州",
“b”:"香港",
“c”:“澳門”,
}
字典的特性
dict是無序的,每次輸出的結果都可能不一樣
key必須是唯一的
info_dic = {
"a":"廣州",
“b”:"香港",
“c”:“澳門”,
}
字典的增
a["e"] = "北京 "
字典的刪
del info_dic["a"]
info_dic.pop("a")
info_dic.popitem() 隨機刪除
字典的改
info_dic["a"] = "上海"
字典的查
info_dic["a"] 當不存在就會報錯
info_dic.get("a”) 不存在就會返回None
字典可以多級嵌套,也可以嵌套列表
字典的其他函數用法
info_dic.values() -->["a", "b", "c"]
info_dic.keys() -->["廣州", "香港", "澳門"]
info_dic.setdefault("d", "大連") 創建一個新的值,前提是字典中沒有這個key,假如有的話就不用變

