
聚簇索引並不是一種單獨的索引類型,而是一種數據存儲方式。當表有聚簇索引的時候,它的數據行實際存放在索引的葉子頁(leaf page)中。術語“聚簇”表示數據行和相鄰的健值緊湊地存儲在一起。因為無法同時把數據行存放在兩個不同的地方,所以一個表只能有一個聚簇索引。 聚簇索引的存放如下圖: 由上圖註意到, ...
聚簇索引並不是一種單獨的索引類型,而是一種數據存儲方式。當表有聚簇索引的時候,它的數據行實際存放在索引的葉子頁(leaf page)中。術語“聚簇”表示數據行和相鄰的健值緊湊地存儲在一起。因為無法同時把數據行存放在兩個不同的地方,所以一個表只能有一個聚簇索引。
聚簇索引的存放如下圖:
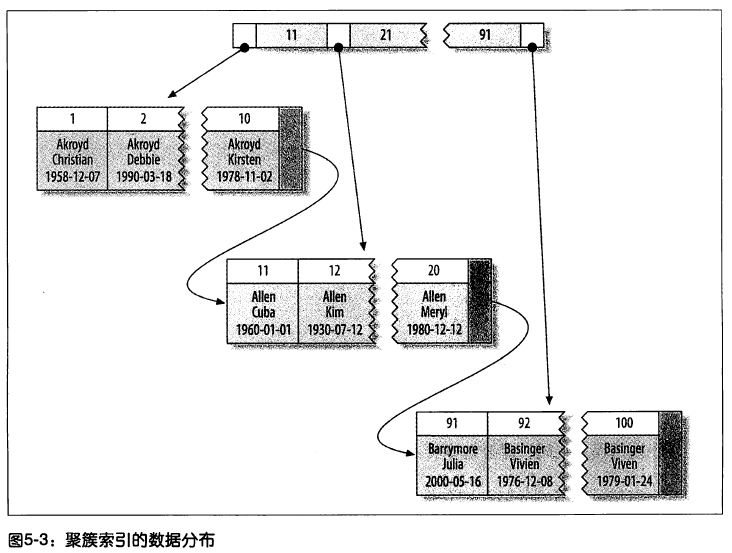
由上圖註意到,葉子頁包含了行的全部數據,但是節點頁只包含了索引列。在這張圖中,索引列包含的是整數值。
聚簇索引預設是主鍵,如果表中沒有定義主鍵,InnoDB 會選擇一個唯一的非空索引代替。如果沒有這樣的索引,InnoDB 會隱式定義一個主鍵來作為聚簇索引。InnoDB 只聚集在同一個頁面中的記錄。包含相鄰健值的頁面可能相距甚遠。
聚簇索引優點:
- 可以把相關數據保存在一起。例如實現電子郵箱時,可以根據用戶 ID 來聚集數據,這樣只需要從磁碟讀取少數的數據頁就能獲取某個用戶的全部郵件。如果沒有使用聚簇索引,則每封郵件都可能導致一次磁碟 I/O。
- 數據訪問更快。聚簇索引將索引和數據保存在同一個 B-Tree 中,因此從聚簇索引中獲取數據通常比在非聚簇索引中查找要快。
- 使用覆蓋索引掃描的查詢可以直接使用頁節點中的主鍵值。
聚簇索引缺點:
- 聚簇數據最大限度地提高了 I/O 密集型應用的性能,但如果數據全部都放在記憶體中,則訪問的順序就沒那麼重要了。聚簇索引也就沒掃描優勢了。
- 插入速度嚴重依賴於插入順序。按照主鍵的順序插入是載入數據到 InnoDB 表中速度最快的方式。但如果不是按照主鍵順序載入數據,那麼載入完成後最好使用 OPTIMIZE TABLE 命令重新組織一下表。
- 更新聚簇索引列的代價很高,因為會強制 InnoDB 將每個被更新的行移動到新的位置。
- 基於聚簇索引的表在插入新行,或者主鍵被更新導致需要移動行的時候,可能面臨“頁分裂(page split)”的問題。當行的主鍵值要求必須將這一行插入到某個已滿的頁時,存儲引擎會將該頁分裂成兩個頁面來容納該行,這就是一次頁分裂的操作。頁分裂會導致表占用更多的磁碟空間。
- 聚簇索引可能導致全表掃描變慢,尤其是行比較稀疏,或者由於頁分裂導致數據存儲不連續的時候。
- 二級索引(非聚簇索引)可能比想象的要更大,因為在二級索引的葉子節點包含了引用行的主鍵列。
- 二級索引訪問需要兩次索引查找,而不是一次。
為什麼二級索引需要兩次索引查找?因為二級索引的葉子節點保存的不是指向行的物理位置的指針,而是行的主鍵值。這就意味著通過二級索引查找行,存儲引擎需要找到二級索引的葉子節點獲得對應的主鍵值,然後根據這個值去聚簇索引中查找到對應的行。這裡做了重覆的操作:兩次 B-Tree 查找而不是一次。
InnoDB 和 MyISAM 的數據分佈對比
聚簇索引和非聚簇索引的數據分佈有區別,以及對應的主鍵索引和二級索引的數據分佈也有區別。使用以下的表來做測試:
1 CREATE TABLE layout_test( 2 col1 int NOT NULL, 3 col2 int NOT NULL, 4 PRIMARY KEY(col1), 5 KEY(col2) 6 );
假設該表的主鍵取值為1 ~ 10 000,按照隨機順序插入並使用 OPTIMIZE TABLE 命令做了優化。換句話說,數據在磁碟上的存儲方式已經是最優,但行的順序是隨機的。列 col2 的值是從 1 ~ 100 之間隨機賦值,所以有很多重覆值。
MyISAM 的數據分佈。MyISAM 的數據分佈非常簡單,它按照數據插入的順序存儲在磁碟上,如圖所示:
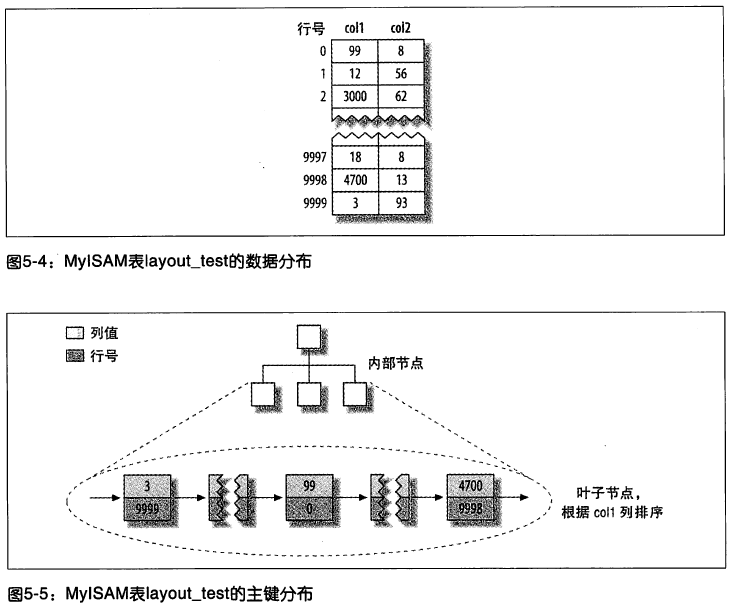
由上圖 5-4 可以看出,行的旁邊顯示了行號,從 0 開始遞增。因為行是定長的,所以 MyISAM 可以從表的開頭跳過所需的位元組找到需要的行(MyISAM 並不總是使用圖 5-4 中的“行號”,而是根據定長還是變長的行使用不同策略)。
這種分佈方式很容易創建索引。下麵顯示的一系列圖,隱藏了頁的物理細節,只顯示索引中的“節點”,索引中的每個葉子節點包含“行號”。圖 5-5 顯示了表的主鍵。
col2 的索引如下圖所示:
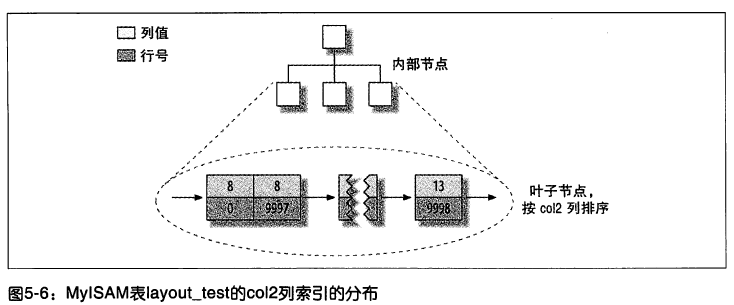
如上圖 5-6 可以看出 col2 列的索引和其它索引沒有什麼區別。事實上,MyISAM 中主鍵索引和其他索引在結構上沒有什麼不同。主鍵索引就是一個名為 PRIMARY 的唯一非空索引。
InnoDB 的數據分佈。因為 InnoDB 支持聚簇索引,所以使用非常不同的方式存儲同樣的數據。InnoDB 以如圖 5-7 所示的方式存儲數據。

由上圖可以看出,InnoDB 的聚簇索引的每一個葉子節點都包含了主鍵值、事務ID、用於事務和 MVCC 的回滾指針以及所有的剩餘列(在這個例子中是 col2)。如果主鍵是一個列首碼索引,InnoDB 也會包含完整的主鍵列和剩下的其他列。
還有一點和 MyISAM 的不同是,InnoDB 的二級索引和聚簇索引很不相同。InnoDB 二級索引的葉子節點中存儲的不是“行指針”,而是主鍵值,並以此作為指向行的“指針”。
這樣的策略減少了當出現行移動或者數據頁分裂時二級索引的維護工作。使用主鍵值當作指針會讓二級索引占用更多的空間,換來的好處是,InnoDB 在移動行時無須更新二級索引中的這個“指針”。
圖 5-8 可以看出表的 col2 索引,每一個葉子節點都包含了索引列(這裡是 col2),緊接著是主鍵值(col1)。
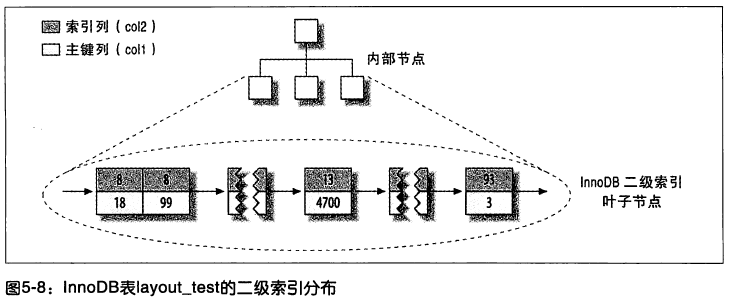
圖 5-9 是描述 InnoDB 和 MyISAM 如何存放表的抽象圖,可以很容易的看出 InnoDB 和 MyISAM 保存數據和索引的區別。
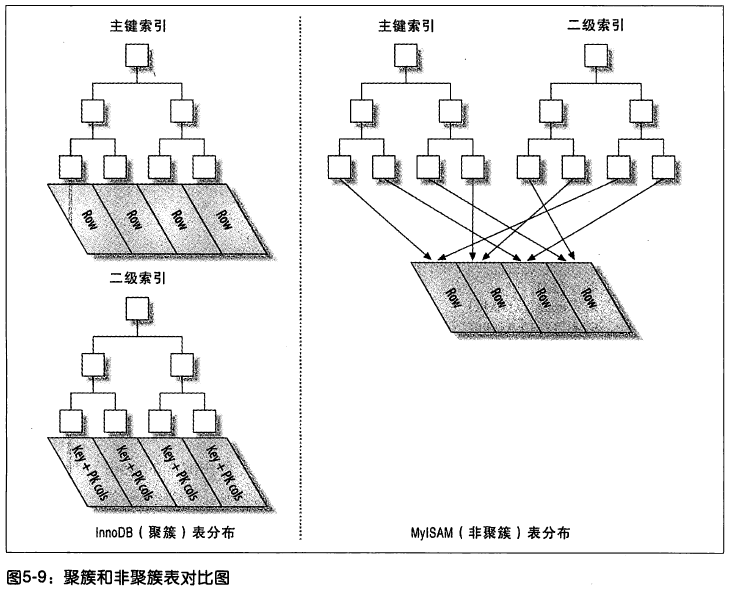
在 InnoDB 表中按主鍵順序插入行
最好避免使用隨機的(不連續且值的分佈範圍非常大)的列做聚簇索引(可以使用 int 型的自增 ID),特別是 I/O 密集型的應用。例如:使用 UUID 來作為聚簇索引則會很糟糕:它使得聚簇索引的插入變得完全隨機,這是最壞的情況,使得數據沒有任何聚集特性。
下麵我們用兩張表來做基準測試。第一個表使用整數 ID 插入 userinfo 表:
1 CREATE TABLE `userinfo`( 2 `id` int unsigend NOT NULL AUTO_INCREMENT, 3 `name` varchar(64) NOT NULL DEFAULT '', 4 `email` varchar(64) NOT NULL DEFAULT '', 5 `password` varchar(64) NOT NULL DEFAULT '', 6 `dob` date DEFAULT NULL, 7 `address` varchar(255) NOT NULL DEFAULT '', 8 `city` varchar(64) NOT NULL DEFAULT '', 9 `state_id` tinyint unsigend NOT NULL DEFAULT '0', 10 `country_id` smallint unsigend NOT NULL DEFAULT '0', 11 PRIMARY KEY (id), 12 UNIQUE KEY email (email), 13 KEY country_id (country_id), 14 KEY state_id (state_id), 15 KEY state_id_2 (state_id,city,address) 16 ) ENGINE = InnoDB
第二個例子是 userinfo_uuid 表,除了主鍵改為 UUID,其餘和前面的 userinfo 表完全相同。
1 CREATE TABLE `userinfo`( 2 `uuid` varchar(36) NOT NULL, 3 ... 4 );
現在已經創建好了兩個測試表了,接下來我們依次插入100萬條記錄。然後繼續依次插入300萬條記錄,使索引的大小超過伺服器的記憶體容量。結果如下圖:
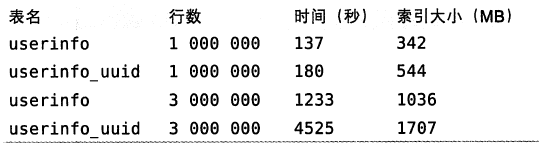
註意到向 UUID 插入行不僅花費的時間更長,而且索引占用的空間也更大。這一方面是由於主鍵欄位更長;另一方面是由於頁分裂和碎片導致的。
圖 5-10 是往第一個表插入數據時,索引發生的變化。
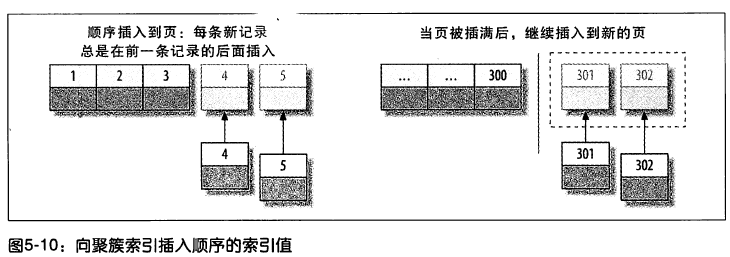
如圖 5-10 可以看出,因為主鍵的值是順序的,所以 InnoDB 把每一條記錄都存儲在上一條記錄的後面。當達到頁的最大填充因數時(InnoDB 預設的最大填充因數是頁大小的 15/16,留出部分空間用於以後修改),下一條記錄就會寫入新的頁中。一旦數據按照這種順序的方式載入,主鍵頁就會近似於被順序的記錄填滿(二級索引頁可能是不一樣的)。
圖 5-11 是往 UUID 表插入數據時,索引發生的變化。
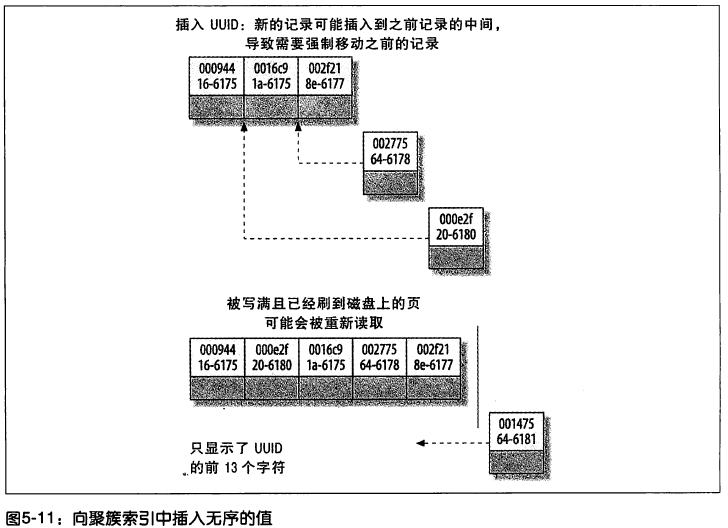
由圖 5-11 可知,因為新行的主鍵值不一定比之前插入的大,所以 InnoDB 無法簡單地總是把新行插入到索引的最後,而是需要給新行尋找合適的位置 —— 通常是已有數據的中間位置 —— 並且分配空間。這會增加很多的額外工作,並導致數據分佈不夠優化。下麵是總結的一些缺點:
- 寫入的目標頁可能已經刷到磁碟上並從緩存中移除,或者是還沒有被載入到緩存中,InnoDB 在插入之前不得不先找到並從磁碟讀取目標頁到記憶體中。這將導致大量的隨機 I/O。
- 因為寫入是亂序的,InnoDB不得不頻繁的做頁分裂操作,以便為新的行分配空間。頁分裂會導致移動大量數據,一次插入最少需要修改三個頁而不是一個頁。
- 由於頻繁的頁分裂,頁會變得稀疏並被不規則地填充,所以最終數據會有碎片。
把這些隨機值載入到聚簇索引之後,也許需要做一次 OPTIMIZE TABLE 來重建表並優化頁的填充。
從這個案例可以看出,使用 InnoDB 時應該儘可能地按主鍵順序插入數據,並且儘可能地使用單調增加的聚簇健的值來插入新行。
參考資料:
高性能MySQL(第3版)


