
一、 用grep在文件中搜索文本 grep能夠接受正則表達式,生成各種格式的輸出。除此之外,它還有大量有趣的選項。 1、 搜索包含特定模式的文本行: 2、 從stdin中讀取: 3、 單個grep命令可以對多個文件進行搜索: 4、 --color選項在輸出行中著重標記出匹配到的單詞: 5、 grep ...
一、 用grep在文件中搜索文本
grep能夠接受正則表達式,生成各種格式的輸出。除此之外,它還有大量有趣的選項。
1、 搜索包含特定模式的文本行:
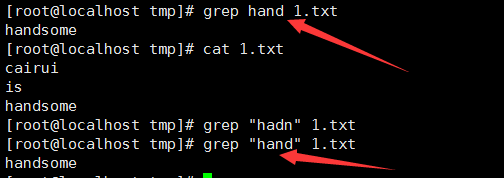
2、 從stdin中讀取:

3、 單個grep命令可以對多個文件進行搜索:

4、 --color選項在輸出行中著重標記出匹配到的單詞:

5、 grep中使用正則表達式時使用(grep -E或者egrep)

6、 只輸出文件中匹配到的文本部分,可以使用-o:

7、 要顯示除匹配行外的所有行用-v選項:

8、 統計文件或文本中包含匹配字元串的行數,-c(在單行出現多個匹配,只匹配一次):
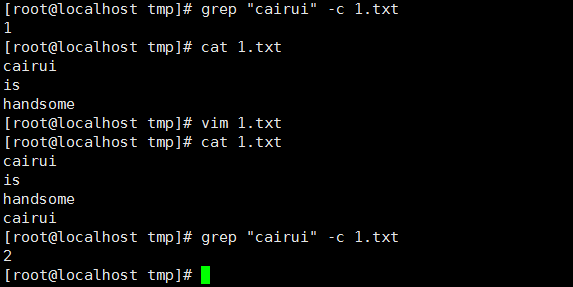
9、 列印出包含匹配字元串的行號,-n:

10、 搜索多個文件並找出匹配文本位於哪一個文件,-l(-L與之作用相反):
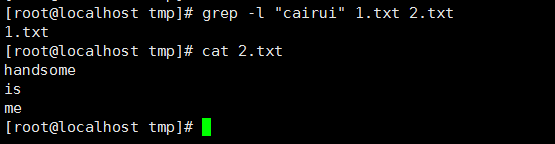
11、 遞歸搜素文件,-r(-R與之作用相同):

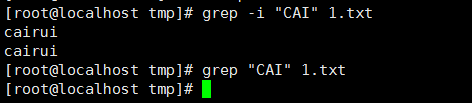
12、 忽略樣式中的大小寫,-i:
13、 用grep匹配多個樣式,-e:

14、 在grep搜索中指定(--include)或排除(--exclude)文件:
目錄中遞歸搜索所有的.c和.cpp文件

在搜索中排除所有的README文件

如果需要排除目錄,使用--exclude-dir選項
15、 grep靜默輸出,-q:
不輸出任何內容,如果成功匹配返回0,如果失敗返回非0值。
16、 列印出匹配文本之前或之後的行:
[root@localhost tmp]# seq 10 1 2 3 4 5 6 7 8 9 10 [root@localhost tmp]# seq 10 | grep 5 -A 3 #列印匹配的後指定行數 5 6 7 8 [root@localhost tmp]# seq 10 | grep 5 -B 3 #列印匹配前指定行數 2 3 4 5 [root@localhost tmp]# seq 10 | grep 5 -C 3 #列印匹配前後指定行數 2 3 4 5 6 7 8
二、 使用sed進行文本替換
sed是流編輯器(stream editor)的縮寫。sed一個用法為文本替換。
[root@cairui ~]# sed --help Usage: sed [OPTION]... {script-only-if-no-other-script} [input-file]... -n, --quiet, --silent suppress automatic printing of pattern space #取消自動列印模式空間 -e script, --expression=script add the script to the commands to be executed #添加“腳本”到程式的運行列表 -f script-file, --file=script-file add the contents of script-file to the commands to be executed #添加“腳本文件”到程式的運行列表 --follow-symlinks follow symlinks when processing in place; hard links will still be broken. -i[SUFFIX], --in-place[=SUFFIX] edit files in place (makes backup if extension supplied). The default operation mode is to break symbolic and hard links. This can be changed with --follow-symlinks and --copy. -c, --copy use copy instead of rename when shuffling files in -i mode. While this will avoid breaking links (symbolic or hard), the resulting editing operation is not atomic. This is rarely the desired mode; --follow-symlinks is usually enough, and it is both faster and more secure. -l N, --line-length=N specify the desired line-wrap length for the `l' command --posix disable all GNU extensions. -r, --regexp-extended use extended regular expressions in the script. -s, --separate consider files as separate rather than as a single continuous long stream. -u, --unbuffered load minimal amounts of data from the input files and flush the output buffers more often --help display this help and exit --version output version information and exit If no -e, --expression, -f, or --file option is given, then the first non-option argument is taken as the sed script to interpret. All remaining arguments are names of input files; if no input files are specified, then the standard input is read. GNU sed home page: <http://www.gnu.org/software/sed/>. General help using GNU software: <http://www.gnu.org/gethelp/>. E-mail bug reports to: <[email protected]>. Be sure to include the word ``sed'' somewhere in the ``Subject:'' field.
1、 sed可以替換給定文本的字元串:



該使用從stdin中讀取輸入,不影響原本的內容
2、預設情況下sed命令列印替換後的文本,如果想連原文本一起修改加-i命令,-i:
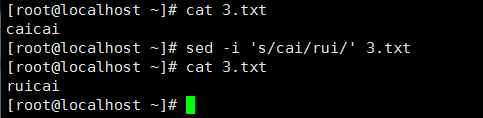
3、 之前的sed都是替換第一個匹配到的內容,想要全部替換就要在末尾加g:
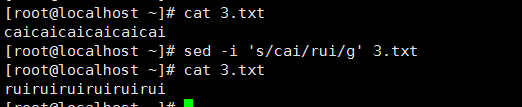
從第N個匹配開始替換

sed中的/為定界符,使用任何其他符號都可以替代

4、 移除空白行
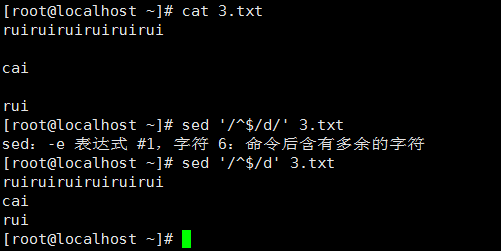
三、 使用awk進行高級文本處理
awk是一款設計用於數據流的工具。它對列和行進行操作。awk有很多內建的功能,比如數組、函數等,和C有很多相同之處。awk最大的優勢是靈活性。
[root@cairui ~]# awk --help Usage: awk [POSIX or GNU style options] -f progfile [--] file ... Usage: awk [POSIX or GNU style options] [--] 'program' file ... POSIX options: GNU long options: -f progfile --file=progfile -F fs --field-separator=fs -v var=val --assign=var=val -m[fr] val -O --optimize -W compat --compat -W copyleft --copyleft -W copyright --copyright -W dump-variables[=file] --dump-variables[=file] -W exec=file --exec=file -W gen-po --gen-po -W help --help -W lint[=fatal] --lint[=fatal] -W lint-old --lint-old -W non-decimal-data --non-decimal-data -W profile[=file] --profile[=file] -W posix --posix -W re-interval --re-interval -W source=program-text --source=program-text -W traditional --traditional -W usage --usage -W use-lc-numeric --use-lc-numeric -W version --version To report bugs, see node `Bugs' in `gawk.info', which is section `Reporting Problems and Bugs' in the printed version. gawk is a pattern scanning and processing language. By default it reads standard input and writes standard output. Examples: gawk '{ sum += $1 }; END { print sum }' file gawk -F: '{ print $1 }' /etc/passwd
awk腳本的結構基本如下所示:
awk ' BEGIN{ print "start" } pattern { commands } END { print "end" }' file
awk腳本通常由3部分組成。BEGIN,END和帶模式匹配選項的常見語句塊。這3個部分都是可選的。
1、工作原理
(1)執行BEGIN { commands }語句塊中的語句。
(2)從文件或stdin中讀取一行,然後執行pattern { commands }。重覆這個過程,直到文件全部被讀取完畢。
(3)當讀至輸入流末尾時,執行END { commands }語句塊。
其中最重要的部分就是pattern語句塊中的通用命令。這個語句塊同樣是可選的。如果不提供該語句塊,則預設執行{ print },即列印所讀取到的每一行。awk對於每一行,都會執行這個語句塊。這就像一個用來讀取行的while迴圈,在迴圈中提供了相應的語句。



