
本文目錄:1. 背景2. 連接的具體過程分析 2.1 socket()函數 2.2 bind()函數 2.3 listen()函數和connect()函數 2.3.1 深入分析listen() 2.3.2 syn flood的影響 2.4 accept()函數 2.5 send()和recv()函數 ...
本文目錄:
1. 背景
2. 連接的具體過程分析
2.1 socket()函數
2.2 bind()函數
2.3 listen()函數和connect()函數
2.3.1 深入分析listen()
2.3.2 syn flood的影響
2.4 accept()函數
2.5 send()和recv()函數
2.6 close()、shutdown()函數
3. 地址/埠重用技術
本文主要說明的是TCP連接過程中,各個階段對套接字的操作,希望能對沒有網路編程基礎的人理解套接字是什麼、扮演的角色有所幫助。如發現錯誤,敬請指出
1. 背景
1.完整的套接字格式{protocol,src_addr,src_port,dest_addr,dest_port}。
這常被稱為套接字的五元組。其中protocol指定了是TCP還是UDP連接,其餘的分別指定了源地址、源埠、目標地址、目標埠。但是這些內容是怎麼來的呢?
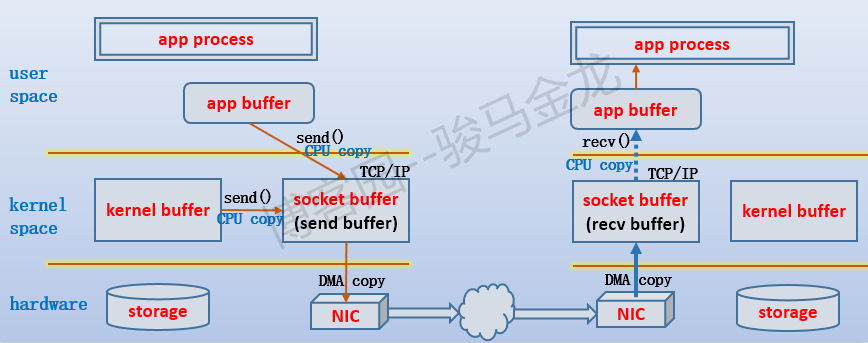
2.TCP協議棧維護著兩個socket緩衝區:send buffer和recv buffer。
要通過TCP連接發送出去的數據都先拷貝到send buffer,可能是從用戶空間進程的app buffer拷入的,也可能是從內核的kernel buffer拷入的,拷入的過程是通過send()函數完成的,由於也可以使用write()函數寫入數據,所以也把這個過程稱為寫數據,相應的send buffer也就有了別稱write buffer。不過send()函數比write()函數更有效率。
最終數據是通過網卡流出去的,所以send buffer中的數據需要拷貝到網卡中。由於一端是記憶體,一端是網卡設備,可以直接使用DMA的方式進行拷貝,無需CPU的參與。也就是說,send buffer中的數據通過DMA的方式拷貝到網卡中並通過網路傳輸給TCP連接的另一端:接收端。
當通過TCP連接接收數據時,數據肯定是先通過網卡流入的,然後同樣通過DMA的方式拷貝到recv buffer中,再通過recv()函數將數據從recv buffer拷入到用戶空間進程的app buffer中。
大致過程如下圖:
3.兩種套接字:監聽套接字和已連接套接字。
監聽套接字是在服務進程讀取配置文件時,從配置文件中解析出要監聽的地址、埠,然後通過socket()函數創建的,然後再通過bind()函數將這個監聽套接字綁定到對應的地址和埠上。隨後,進程/線程就可以通過listen()函數來監聽這個埠(嚴格地說是監控這個監聽套接字)。
已連接套接字是在監聽到TCP連接請求並三次握手後,通過accept()函數返回的套接字,後續進程/線程就可以通過這個已連接套接字和客戶端進行TCP通信。
為了區分socket()函數和accept()函數返回的兩個套接字描述符,有些人使用listenfd和connfd分別表示監聽套接字和已連接套接字,挺形象的,下文偶爾也這麼使用。
下麵就來說明各種函數的作用,分析這些函數,也是在連接、斷開連接的過程。
2. 連接的具體過程分析
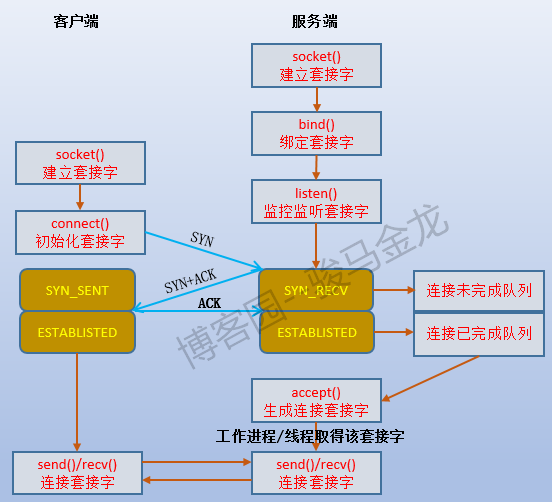
如下圖:
2.1 socket()函數
socket()函數的作用就是生成一個用於通信的套接字文件描述符sockfd(socket() creates an endpoint for communication and returns a descriptor)。這個套接字描述符可以作為稍後bind()函數的綁定對象。
2.2 bind()函數
服務程式通過分析配置文件,從中解析出想要監聽的地址和埠,再加上可以通過socket()函數生成的套接字sockfd,就可以使用bind()函數將這個套接字綁定到要監聽的地址和埠組合"addr:port"上。綁定了埠的套接字可以作為listen()函數的監聽對象。
綁定了地址和埠的套接字就有了源地址和源埠(對伺服器自身來說是源),再加上通過配置文件中指定的協議類型,五元組中就有了其中3個元組。即:
{protocal,src_addr,src_port}
但是,常見到有些服務程式可以配置監聽多個地址、埠實現多實例。這實際上就是通過多次socket()+bind()系統調用生成並綁定多個套接字實現的。
2.3 listen()函數和connect()函數
顧名思義,listen()函數就是監聽已經通過bind()綁定了addr+port的套接字的。監聽之後,套接字就從CLOSE狀態轉變為LISTEN狀態,於是這個套接字就可以對外提供TCP連接的視窗了。
而connect()函數則用於向某個已監聽的套接字發起連接請求,也就是發起TCP的三次握手過程。從這裡可以看出,連接請求方(如客戶端)才會使用connect()函數,當然,在發起connect()之前,連接發起方也需要生成一個sockfd,且使用的很可能是綁定了隨機埠的套接字。既然connect()函數是向某個套接字發起連接的,自然在使用connect()函數時需要帶上連接的目的地,即目標地址和目標埠,這正是服務端的監聽套接字上綁定的地址和埠。同時,它還要帶上自己的地址和埠,對於服務端來說,這就是連接請求的源地址和源埠。於是,TCP連接的兩端的套接字都已經成了五元組的完整格式。
2.3.1 深入分析listen()
再來細說listen()函數。如果監聽了多個地址+埠,即需要監聽多個套接字,那麼此刻負責監聽的進程/線程會採用select()、poll()的方式去輪詢這些套接字(當然,也可以使用epoll()模式),其實只監控一個套接字時,也是使用這些模式去輪詢的,只不過select()或poll()所感興趣的套接字描述符只有一個而已。
不管使用select()還是poll()模式(至於epoll的不同監控方式就無需多言了),在進程/線程(監聽者)監聽的過程中,它阻塞在select()或poll()上。直到有數據(SYN信息)寫入到它所監聽的sockfd中(即recv buffer),監聽者被喚醒並將SYN數據拷貝到用戶空間中自己管理的app buffer中進行一番處理,併發送SYN+ACK,這個數據同樣需要從app buffer中拷入send buffer(使用send()函數)中,再拷入網卡傳送出去。這時會在連接未完成隊列中為這個連接創建一個新項目,並設置為SYN_RECV狀態。然後再次使用select()/poll()方式監控著套接字listenfd,直到再次有數據寫入這個listenfd中監聽者才被喚醒,如果這次寫入的數據是ACK信息,則將數據拷入到app buffer中進行一番處理後,把連接未完成隊列中對應的項目移入連接已完成隊列,並設置為ESTABLISHED狀態,如果這次接收的不是ACK,則肯定是SYN,也就是新的連接請求,於是和上面的處理過程一樣,放入連接未完成隊列。這就是監聽者處理整個TCP連接的迴圈過程。
也就是說,listen()函數還維護了兩個隊列:連接未完成隊列和連接已完成隊列。當監聽者接收到某個客戶端發來的SYN並回覆了SYN+ACK之後,就會在未完成連接隊列的尾部創建一個關於這個客戶端的條目,並設置它的狀態為SYN_RECV。顯然,這個條目中必須包含客戶端的地址和埠相關信息(可能是hash過的,我不太確定)。當服務端再此收到這個客戶端發送的ACK信息之後,監聽者線程通過分析數據就知道這個消息是回覆給未完成連接隊列中的哪一項的,於是將這一項移入到已完成連接隊列,並設置它的狀態為ESTABLISHED。
當未完成連接隊列滿了,監聽者被阻塞不再接收新的連接請求,並通過select()/poll()等待兩個隊列觸發可寫事件。當已完成連接隊列滿了,則監聽者也不會接收新的連接請求,同時,正準備移入到已完成連接隊列的動作被阻塞。在Linux 2.2以前,listen()函數有一個backlog的參數,用於設置這兩個隊列的最大總長度,從Linux 2.2開始,這個參數只表示已完成隊列的最大長度,而/proc/sys/net/ipv4/tcp_max_syn_backlog則用於設置未完成隊列的最大長度。/proc/sys/net/core/somaxconn則是硬限制已完成隊列的最大長度,預設為128,如果backlog大於somaxconn,則backlog會被截斷為等於該值。
下麵的Send-Q列就是backlog列,也即未完成連接最大隊列數。Recv-Q則表示當前未完成連接隊列中的條目數。可見man netstat的解釋。
[root@xuexi ~]# ss -tnl
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 128 *:80 *:*
LISTEN 0 128 *:22 *:*
LISTEN 0 100 127.0.0.1:25 *:*
LISTEN 0 128 :::22 :::*
LISTEN 0 100 ::1:25 :::*
2.3.2 syn flood的影響
此外,如果監聽者發送SYN+ACK後,遲遲收不到客戶端返回的ACK消息,監聽者將被select()/poll()設置的超時時間喚醒,並對該客戶端重新發送SYN+ACK消息,防止這個消息遺失在茫茫網路中。但是,這一重發就出問題了,如果客戶端調用connect()時偽造源地址,那麼監聽者回覆的SYN+ACK消息是一定到不了對方的主機的,也就是說,監聽者會遲遲收不到ACK消息,於是重新發送SYN+ACK。但無論是監聽者因為select()/poll()設置的超時時間一次次地被喚醒,還是一次次地將數據拷入send buffer,這期間都是需要CPU參與的,而且send buffer中的SYN+ACK還要再拷入網卡(這次是DMA拷貝,不需要CPU)。如果,這個客戶端是個攻擊者,源源不斷地發送了數以千、萬計的SYN,監聽者幾乎直接就崩潰了,網卡也會被阻塞的很嚴重。這就是所謂的syn flood攻擊。
解決syn flood的方法有多種,例如,縮小listen()維護的兩個隊列的最大長度,減少重發syn+ack的次數,增大重發的時間間隔,減少收到ack的等待超時時間,使用syncookie等,但直接修改tcp選項的任何一種方法都不能很好兼顧性能和效率。所以在連接到達監聽者線程之前對數據包進行過濾是極其重要的手段。
2.4 accept()函數
accpet()函數的作用是讀取已完成連接隊列中的第一項(讀完就從隊列中移除),並對此項生成一個用於後續連接的套接字描述符,假設使用connfd來表示。有了新的連接套接字,工作進程/線程(稱其為工作者)就可以通過這個連接套接字和客戶端進行數據傳輸,而前文所說的監聽套接字(sockfd)則仍然被監聽者監聽。
例如,prefork模式的httpd,每個子進程既是監聽者,又是工作者,每個客戶端發起連接請求時,子進程在監聽時將它接收進來,並釋放對監聽套接字的監聽,使得其他子進程可以去監聽這個套接字。多個來回後,終於是通過accpet()函數生成了新的連接套接字,於是這個子進程就可以通過這個套接字專心地和客戶端建立交互,當然,中途可能會因為各種io等待而多次被阻塞或睡眠。這種效率真的很低,僅僅考慮從子進程收到SYN消息開始到最後生成新的連接套接字這幾個階段,這個子進程一次又一次地被阻塞。當然,可以將監聽套接字設置為非阻塞IO模式,只是即使是非阻塞模式,它也要不斷地去檢查狀態。
再考慮worker/event處理模式,每個子進程中都使用了一個專門的監聽線程和N個工作線程。監聽線程專門負責監聽並建立新的連接套接字描述符,放入apache的套接字隊列中。這樣監聽者和工作者就分開了,在監聽的過程中,工作者可以仍然可以自由地工作。如果只從監聽這一個角度來說,worker/event模式比prefork模式性能高的不是一點半點。
當監聽者發起accept()系統調用的時候,如果已完成連接隊列中沒有任何數據,那麼監聽者會被阻塞。當然,可將套接字設置為非阻塞模式,這時accept()在得不到數據時會返回EWOULDBLOCK或EAGAIN的錯誤。可以使用select()或poll()或epoll來等待已完成連接隊列的可讀事件。還可以將套接字設置為信號驅動IO模式,讓已完成連接隊列中新加入的數據通知監聽者將數據複製到app buffer中並使用accept()進行處理。
常聽到同步連接和非同步連接的概念,它們到底是怎麼區分的?同步連接的意思是,從監聽者監聽到某個客戶端發送的SYN數據開始,它必須一直等待直到建立連接套接字、並和客戶端數據交互結束,在和這個客戶端的連接關閉之前,中間不會接收任何其他客戶端的連接請求。通常以同步連接的方式處理時,監聽者和工作者是同一個進程,例如httpd的prefork模型。而非同步連接則可以在建立連接和數據交互的任何一個階段接收、處理其他連接請求。通常,監聽者和工作者不是同一個進程時使用非同步連接的方式,例如httpd的event模型,儘管worker模型中監聽者和工作者分開了,但是仍採用同步連接,監聽者將連接請求接入並創建了連接套接字後,立即交給工作線程,工作線程處理的過程中一直只服務於該客戶端直到連接斷開,而event模式的非同步也僅僅是在工作線程處理特殊的連接(如處於長連接狀態的連接)時,可以將它交給監聽線程保管而已,對於正常的連接,它仍等價於同步連接的方式。通俗而不嚴謹地說,同步連接是一個進程/線程處理一個連接,非同步連接是一個進程/線程處理多個連接。
2.5 send()和recv()函數
send()函數是將數據從app buffer複製到send buffer中(當然,也可能直接從內核的kernel buffer中複製),recv()函數則是將recv buffer中的數據複製到app buffer中。當然,使用write()和read()函數替代它們並沒有什麼不可以,只是send()/recv()的針對性更強而已。
這兩個函數都涉及到了socket buffer,但是在調用send()或recv()時,複製的源buffer中是否有數據、複製的目標buffer中是否已滿而導致不可寫是需要考慮的問題。不管哪一方,只要不滿足條件,調用send()/recv()時進程/線程會被阻塞(假設套接字設置為阻塞式IO模型)。當然,可以將套接字設置為非阻塞IO模型,這時在buffer不滿足條件時調用send()/recv()函數,調用函數的進程/線程將返回錯誤狀態信息EWOULDBLOCK或EAGAIN。buffer中是否有數據、是否已滿而導致不可寫,其實可以使用select()/poll()/epoll去監控對應的文件描述符(對應socket buffer則監控該socket描述符),當滿足條件時,再去調用send()/recv()就可以正常操作了。還可以將套接字設置為信號驅動IO或非同步IO模型,這樣數據準備好、複製好之前就不用再做無用功去調用send()/recv()了。
2.6 close()、shutdown()函數
通用的close()函數可以關閉一個文件描述符,當然也包括面向連接的網路套接字描述符。當調用close()時,將會嘗試發送send buffer中的所有數據。但是close()函數只是將這個套接字引用計數減1,就像rm一樣,刪除一個文件時只是移除一個硬鏈接數,只有這個套接字的所有引用計數都被刪除,套接字描述符才會真的被關閉,才會開始後續的四次揮手中。對於父子進程共用套接字的併發服務程式,調用close()關閉子進程的套接字並不會真的關閉套接字,因為父進程的套接字還處於打開狀態,如果父進程一直不調用close()函數,那麼這個套接字將一直處於打開狀態,見一直進入不了四次揮手過程。
而shutdown()函數專門用於關閉網路套接字的連接,和close()對引用計數減一不同的是,它直接掐斷套接字的所有連接,從而引發四次揮手的過程。可以指定3種關閉方式:
1.關閉寫。此時將無法向send buffer中再寫數據,send buffer中已有的數據會一直發送直到完畢。
2.關閉讀。此時將無法從recv buffer中再讀數據,recv buffer中已有的數據只能被丟棄。
3.關閉讀和寫。此時無法讀、無法寫,send buffer中已有的數據會發送直到完畢,但recv buffer中已有的數據將被丟棄。
無論是shutdown()還是close(),每次調用它們,在真正進入四次揮手的過程中,它們都會發送一個FIN。
3. 地址/埠重用技術
正常情況下,一個addr+port只能被一個套接字綁定,換句話說,addr+port不能被重用,不同套接字只能綁定到不同的addr+port上。舉個例子,如果想要開啟兩個sshd實例,先後啟動的sshd實例配置文件中,必須不能配置同樣的addr+port。同理,配置web虛擬主機時,除非是基於功能變數名稱,否則兩個虛擬主機必須不能配置同一個addr+port,而基於功能變數名稱的虛擬主機能綁定同一個addr+port的原因是http的請求報文中包含主機名信息,實際上在這類連接請求到達的時候,仍是通過同一個套接字進行監聽的,只不過監聽到之後,httpd的工作進程/線程可以將這個連接分配到對應的主機上。
既然上面說的是正常情況下,當然就有非正常情況,也就是地址重用和埠重用技術,組合起來就是套接字重用。在現在的Linux內核中,已經有支持地址重用的socket選項SO_REUSEADDR和支持埠重用的socket選項SO_REUSEPORT。設置了埠重用選項後,再去綁定套接字,就不會再有錯誤了。而且,一個實例綁定了兩個addr+port之後(可以綁定多個,此處以兩個為例),就可以同一時刻使用兩個監聽進程/線程分別去監聽它們,客戶端發來的連接也就可以通過round-robin的均衡演算法輪流地被接待。
對於監聽進程/線程來說,每次重用的套接字被稱為監聽桶(listener bucket),即每個監聽套接字都是一個監聽桶。
以httpd的worker或event模型為例,假設目前有3個子進程,每個子進程中都有一個監聽線程和N個工作線程。
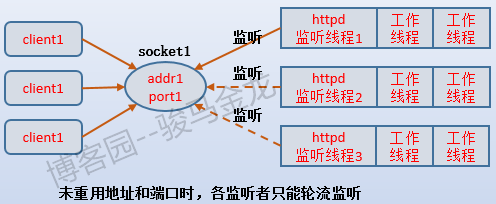
那麼,在沒有地址重用的情況下,各個監聽線程是爭搶式監聽的。在某一時刻,這個監聽套接字上只能有一個監聽線程在監聽(通過獲取互斥鎖mutex方式獲取監聽資格),當這個監聽線程接收到請求後,讓出監聽的資格,於是其他監聽線程去搶這個監聽資格,並只有一個線程可以搶的到。如下圖:
當使用了地址重用和埠重用技術,就可以為同一個addr+port綁定多個套接字。例如下圖中是多使用一個監聽桶時,有兩個套接字,於是有兩個監聽線程可以同時進行監聽,當某個監聽線程接收到請求後,讓出資格,讓其他監聽線程去爭搶資格。
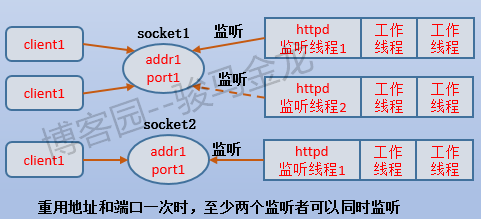
如果再多綁定一個套接字,那麼這三個監聽線程都不用讓出監聽資格,可以無限監聽。如下圖。
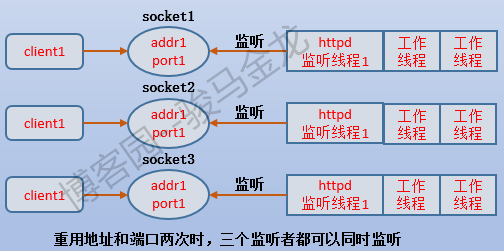
似乎感覺上去,性能很好,不僅減輕了監聽資格(互斥鎖)的爭搶,避免"饑餓問題",還能更高效地監聽,並因為可以負載均衡,從而可以減輕監聽線程的壓力。但實際上,每個監聽線程的監聽過程都是需要消耗CPU的,如果只有一核CPU,即使重用了也體現不出重用的優勢,反而因為切換監聽線程而降低性能。因此,要使用埠重用,必須考慮是否已將各監聽進程/線程隔離在各自的cpu中,也就是說是否重用、重用幾次都需考慮cpu的核數以及是否將進程與cpu相互綁定。
暫時就先寫這麼多了。


