
本文目錄:1. prefork模式 1.1 概述 1.2 prefork工作機制 1.3 prefork相關指令2. worker模式 2.1 概述 2.2 worker工作機制3. event模式 3.1 概述 3.2 和worker工作模式的關係 3.3 event工作機制 3.3.1 非同步連接 ...
本文目錄:
1. prefork模式
1.1 概述
1.2 prefork工作機制
1.3 prefork相關指令
2. worker模式
2.1 概述
2.2 worker工作機制
3. event模式
3.1 概述
3.2 和worker工作模式的關係
3.3 event工作機制
3.3.1 非同步連接(Async connections)
3.3.2 Graceful進程終止和記分牌(ScoreBoard)的使用方式
3.3.3 不足之處Limitations
3.3.4 背景資料Background material
3.3.5 相關指令:AsyncRequestWorkerFactor
4. httpd三種MPM工作機制總結分析
4.1 web服務處理請求的過程
4.1.1 監聽線程和工作線程的交互
4.1.2 工作線程獲取數據的過程分析
4.2 prefork模式
4.3 worker模式
4.4 event模式
4.5 記分板
4.5.1 全局記分板
4.5.2 子進程記分板
4.5.3 線程記分板
4.6 graceful restart問題
本文專講httpd MPM。為了更完整、權威,我先把apache httpd 2.4關於prefork、worker和event的官方手冊大致翻譯了一遍,也就是本文的前3節。水平有限,難免翻譯的"鬼才看得懂",還請見諒。不過在此之後,我專門拿出一節(第4節)對3種MPM做總結分析,比較通俗易懂,在看翻譯有疑惑時,可以參照這一節對應的內容,我想我描述的應該比較清晰,也已經非常詳細了。本來還想把MPM相關的通用性指令翻譯一遍,但發現寫完前面4節,篇幅已經很大了,所以,偷個懶算了。
註:內容有些多,如有錯誤,盼請指出。
1. prefork模式
1.1 概述
這種MPM實現了一種非線程、預先fork好服務進程(即主httpd進程外的所有派生httpd進程)的web服務。每個服務進程都可以響應流入的請求、而父進程負責維護服務進程池中服務進程的數量。對於隔離每個請求以避免單個請求出問題時殃及池魚來說,prefork是最佳的MPM。
prefork有很強的自我調節能力,幾乎不用調整它的配置指令就可以很好地工作。最重要的指令是MaxRequestWorkers,要儘量將其設置大一些,以便能處理大量的併發請求,但不能設置的太大,因為要確保能剩餘足夠多的物理記憶體供其它進程使用。
1.2 prefork工作機制
一個單獨的控制進程(主httpd進程)負責產生用於監聽和處理連接的子進程,並控制這些子進程的存活周期。httpd主進程總是嘗試保留一些備用或空閑的服務進程,以便能夠隨時處理新流入的請求。這種方式下,客戶端在得到服務前就不用等待httpd fork一個新的子進程。
指令StartServers, MinSpareServers, MaxSpareServers和MaxRequestWorkers調節了父進程如何創建服務子進程。通常情況下,主httpd進程有很好的自我調節能力,絕大多數站點沒有必要去調整這些指令的預設值。對於要處理大於256個併發請求的站點來說,可能需要增大MaxRequestWorkers指令的值,但如果沒有足夠的記憶體,應該減小MaxRequestWorker指令的值以保證不使用swap分區而降低整體的性能。
在Unix系統中,父進程通常以root身份運行以便綁定特權80埠,而主httpd的子進程通常以一個低特權的用戶運行。User和Group指令可以設置子進程的身份許可權。運行子進程的用戶必須要對它所服務的內容有讀許可權,但對服務內容之外的其他資源應該儘可能少地擁有許可權。
MaxConnectionsPerChild指令用於控制殺死舊子進程和生成新子進程的頻率。
1.3 prefork相關指令
-
MaxSpareServers
預設為10。
該指令設置期望的最大空閑子進程數。空閑子進程指的是當前沒有在處理任何請求。如果空閑子進程數比該指令指定的數量還多,則父進程會殺掉多餘的子進程。
只有在非常繁忙的站點上才有必要調整該指令的值。強烈建議不要將該指令的值設置交大。如果嘗試設置該值小於或等於MinSpareServer的值,主httpd進程將自動調整該指令的值為MinSpareServers+1。 -
MinSpareServers
預設值為5。
該指令設置期望的最小空閑子進程數。空閑子進程指的是當前沒有在處理任何請求。如果空閑子進程數少於該指令指定的值,則父進程會新創建子進程補足缺少的空閑子進程。此時創建空閑子進程的方式:派生一個子進程,等一秒,派生兩個子進程,等一秒,派生4個子進程,依次下去最多到每秒32個子進程,並強制停止派生。
只有在非常繁忙的站點上才有必要調整該指令的值。強烈建議不要將該指令的值設置較大。
2. worker模式
2.1 概述
這種MPM實現了一種多進程、多線程混合的web服務。相比使用進程來處理請求,使用線程處理請求可以使用更少的系統資源處理更多的請求。但是,它也使用了多個進程(每個進程下有很多線程),以更多地獲得基於進程處理方式的穩定性。
該MPM最重要的指令是ThreadsPerChild和MaxRequestWorkers,前者控制了每個子進程展開的線程數量,後者控制了最大匯流排程數量。
2.2 worker工作機制
一個單獨的控制進程(父進程)負責產生子進程。每個子進程創建固定數量的服務線程,數量由ThreadsPerChild指令設置,同時還會額外創建一個監聽線程,負責監聽請求併在它們到達的時候將它們交給服務線程來處理。(即N個服務線程+1個監聽線程。)
apache http服務總是嘗試保留一些備用或空閑的服務線程池,以便可以隨時處理流入的請求。這種情況下,客戶端在它們的請求被處理前無需等待產生新線程。初始化時產生的進程數由指令StartServers指定。在操作期間,父進程會評估所有子進程中所有空閑線程的總數,還會新建或殺死子進程使得空閑進程總數在MinSpareThreads和MaxSpareThreads指定的邊界值內。由於進程的自我調節能力很好,很少需要修改該指令的預設值。能處理的最大客戶端併發數(如所有進程中的所有線程數)由MaxRequestWorkers指令決定。激活的最大子進程數計算方式為:MaxRequestWorkers/ThreadsPerChild。
有兩個指令可以硬限制激活的子進程數和每個子進程中的服務線程數,硬限制的數量只能通過完全關閉http server再啟動它來改變。ServerLimit指令硬限制激活的子進程數,它必須大於或等於MaxRequesetWorkers/ThreadsPerChild。ThreadLimit指令硬限制每個子進程中的服務線程數,必須大於或等於ThreadsPerChild的值。
除了激活的子進程之外,可能還有其他的正在被中斷的子進程,這種子進程中可能還至少有一個服務線程正在處理請求。所以,可能線上程總數達到了MaxRequestWorkers的數量時,仍存在正被中斷的子進程。可以通過下麵的方式禁止某個單獨的子進程終止行為:
- 設置MaxConnectionsPerChild值為0。
- 設置MaxSpareThreads的值等於MaxRequestWorkers的值。
一個典型的worker MPM進程-線程的配置大致如下:
ServerLimit 16
StartServers 2
MaxRequestWorkers 150
MinSpareThreads 25
MaxSpareThreads 75
ThreadsPerChild 25
在Unix系統中,父進程通常以root身份運行以便綁定特權80埠,而主httpd的子進程通常以一個低特權的用戶運行。User和Group指令可以設置子進程的身份許可權。運行子進程的用戶必須要對它所服務的內容有讀許可權,但對服務內容之外的其他資源應該儘可能少地擁有許可權。此外,除非使用了suexec,否則這兩個指令設置的許可權也會被CGI腳本繼承。
MaxConnectionsPerChild指令用於控制殺死舊子進程和生成新子進程的頻率。
3. event模式
3.1 概述
設計event MPM旨在將工作線程(worker thread)正在處理的請求轉移給監聽線程(listener threads),以釋放工作線程來接收新請求,從而能夠併發處理更多請求。
要使用event MPM,需要在編譯httpd的時候在configure的配置中加上"--with-mpm=event"。(當然,只要將它動態編譯,以後可以使用LoadModule動態切換。)
3.2 和worker工作模式的關係
event工作模式是基於進程、線程混合的worker模式的。一個單獨的控制進程(父進程)負責生成子進程,每個子進程創建由固定數量的服務線程,服務線程數由ThreadsPerChild指令設置,同時還創建一個監聽線程,負責監聽請求併在它們到達的時候將它們交給服務線程來處理。(即N個服務線程+1個監聽線程。)
運行時的配置指令和worker模式的指令完全相同,除了AsyncRequestWorkerFactor指令。
3.3 event工作機制
這種MPM嘗試修複http中的"長連接問題"。當客戶端完成了第一次請求後,可以繼續保持它的連接不被關閉,以便之後可以使用相同的套接字發送其他的請求,而且這樣可以節省多次創建TCP連接帶來的大量消耗。但是,傳統的apache httpd會保留那個負責處理請求的子進程或線程來等待客戶端隨後可能發送的請求,這不免帶來了它自身的缺陷:資源浪費且"占著茅坑不拉屎"。為瞭解決這種問題,event MPM在每個子進程中使用一個專門的監聽線程,不僅負責監聽套接字,還負責處理所有處於長連接狀態的套接字,這些套接字都是已經被所有handler和協議過濾器(通過過濾器,可以修改請求、待響應內容)處理完畢後的套接字,它們只剩下一件事沒完成:發送數據給客戶端。
這種新的架構方式,利用了非阻塞套接字(non-blocking sockets)和實現現代內核特性的APR(類似於Linux的epoll),而不再使用可能會導致"驚群問題"(thundering herd problem)的mpm-accept mutex(互斥鎖方式)。
註:驚群問題,從英文單詞來翻譯是"暴怒中的野獸問題",在電腦領域,它的意思是大量進程/線程都在等待同一個事件,當事件發生時,所有進程/線程都被喚醒,它們都想擁有這個資源,於是在討論一段時間後,除了那個獲得資源的進程/線程,其餘進程/線程又再次進入睡眠,當再次發生事件,又被全部喚醒、爭論、睡眠,一直重覆直到所有進程/線程都獲取了資源。這樣的結果是進程/線程抖動極度嚴重,每次上下文切換都消耗極大的資源,很容易導致伺服器崩潰。但如果每次只喚醒一個進程,則不會出現抖動問題),這可以避。
單個進程或線程塊可以處理的總連接數由AsyncRequestWorkerFactor指令控制。
3.3.1 非同步連接(Async connections)
非同步連接需要一個固定的專用的工作線程。mod_status模塊的status顯示頁中將展示一個新的非同步連接列,如下:(在配置了mod_status模塊時,可以使用apachectl fullstatus或在瀏覽器中www.example.com/server-status獲取,以下是某次用ab命令測試過程中的數據)
Slot PID Stopping Connections Threads Async connections
total accepting busy idle writing keep-alive closing
0 42480 no 27 yes 25 0 1 0 1
1 42481 no 26 yes 25 0 2 0 0
2 42482 no 27 yes 25 0 0 0 2
3 42564 no 28 no 25 0 1 0 2
4 42618 no 26 yes 25 0 1 0 1
5 42651 no 27 yes 25 0 1 0 1
6 42652 no 26 yes 25 0 2 0 0
7 42709 no 26 no 24 1 1 0 1
8 42710 no 26 no 25 0 2 0 0
9 42711 no 26 yes 24 1 2 0 0
10 42712 no 27 yes 25 0 2 0 0
11 42824 no 27 yes 25 0 1 0 1
12 42825 no 26 yes 25 0 0 0 1
13 42826 no 27 yes 25 0 2 0 0
14 42827 no 28 no 25 0 1 0 3
15 42828 no 26 no 25 0 1 0 1
Sum 16 0 426 398 2 20 0 14
它有以下幾個欄位:
-
Writing
當工作線程發送響應數據給客戶端時,可能會因為連接太慢而導致內核的TCP寫緩衝區(tcp write buffer,嚴格地說是tcp send buffer,但httpd手冊上寫的是write buffer,所以就使用它了,後文可能會隨機使用兩種描述,看心情)填滿的情況。通常這種情況下,該套接字的write()調用會返回EWOULDBLOCK或EAGAIN,只有經過一段空閑時間後才可以再次可寫。持有套接字的工作線程可以卸掉這種等待任務,並將該套接字交給監聽線程,之後按順序輪詢直到該套接字的事件升級(例如該套接字已經可寫)時,監聽線程會將該套接字分配給第一個空閑的工作線程。(這是在IO寫等待的情況下把套接字交給監聽線程) -
Keep-alive
相比worker MPM,event MPM對長連接的處理方式是它最本質的提高。當工作線程完成了對客戶端的響應(數據已經發送結束了),它可以將套接字卸給監聽線程,然後按順序輪詢等待來自操作系統的所有事件信息,例如"該套接字現在可讀"。如果該客戶端再次發起了新請求,監聽線程將把該套接字轉交給第一個空閑的工作線程。相反,如果到了KeepAliveTimeout指定的時長,該套接字將被監聽線程關閉。在這種方式下,工作線程不需要負責空閑的套接字,它可以被重新利用來處理其他請求。(這是在請求結束後把空閑的套接字交給監聽線程) -
Closing
某些時候,event MPM需要實現延遲關閉(lingering_close)的行為,換句話說,發一個之前的錯誤信息給仍在向httpd傳輸請求的客戶端。直接發送響應並立即關閉連接是錯誤的行為,因為客戶端(仍在嘗試發送剩餘的請求)在連接關閉後可以獲取一個新的已RST包,使得它無法讀取httpd的已經發送的錯誤響應信息。因此在這種情況下,httpd嘗試讀取剩餘的請求以使得客戶耗盡響應。延遲關閉的行為有時間限定,但相對來說它有足夠長的時間,因此工作線程可以將其卸給監聽線程。
註:關於lingering_close,在nginx中也有這個概念。它表示延遲關閉TCP連接。當客戶端或服務端發生錯誤時,一般情況下,我們期待的是把錯誤信息告訴客戶端,並關閉連接,且不要再建立連接。但直接關閉tcp連接會導致處理不當的問題。這要從關閉TCP連接的過程來解釋。
在執行close()系統調用關閉某個tcp連接時,內核會檢查tcp連接的read buffer中是否還有數據(對httpd來講,就是保持這個tcp連接的子進程/線程是否還有沒有處理的請求)。如果沒有,則等待tcp的write buffer中的數據(對httpd來講,即響應或轉發數據)向客戶端傳輸完畢,最後四次揮手關閉連接;如果有,則向客戶端發送一個RST包,以便關閉TCP連接,但只要發送了RST包,tcp的write buffer中的數據就會被丟棄。
於是就存在一種特殊情況,在發送close()系統調用想要關閉tcp連接之前,如果write buffer和read buffer中都有數據,在發送RST包之後,write buffer中的數據就丟棄了(其中就包括想要響應給客戶端的錯誤信息),也就是說客戶端收不到這裡面的響應數據。這種特殊的情況也不難理解,在write buffer中有數據是很正常的,因為傳輸響應數據給客戶端占用了子進程/線程大多數時間,在read buffer中有數據也很正常,例如客戶端還在源源不斷地發送請求,就會導致tcp的read buffer總是非空。
解決的辦法是讓服務端先不要發送RST包,且不要再往tcp write buffer中添加新數據(即關閉向writer buffer的寫操作)。這樣一來,子進程/線程只讀read buffer中的請求,但卻直接忽略請求不做任何處理,而客戶端請求總有發完的時候,只要不再發請求了,read buffer就可以讀完變成空buffer。於此同時,write buffer中的數據也在不斷地傳輸給客戶端,最終會讓客戶端收到write buffer尾部的錯誤信息數據。當然,nginx可以設置讀超時lingering_timeout,如果客戶端還是不斷地發請求,對服務端來說,我都不理你了,你還沒完沒了,那啥,只能對不起了。此外,nginx還可以設置一個寫超時lingering_time,在這個超時時間內,如果write buffer中的數據還是沒有傳輸完,也就是說客戶端最終還是沒有收到錯誤響應消息,還是對不起,因為可能網速太慢了,對伺服器來說,我不能在你身上等死。至於httpd有沒有設置讀超時和寫超時的指令,官方手冊上暫時沒找到,可能需要修改源碼吧。
在官方的nginx中,lingering_close預設值為ON,也就是會經過上面所說的一大堆過程來延遲關閉。但是在tengine中,預設為off,也就是會直接關閉tcp連接,但這樣會導致一些不合理的錯誤處理。
另外,套接字選項SO_LINGER和lingering_close並沒有半毛錢關係,SO_LINGER只是控制close()函數預設行為的。而lingering_close則描述了一種需要特殊處理的情況。
這3種提升方式對HTTP和HTTPS連接都適用。
3.3.2 Graceful進程終止和記分牌(ScoreBoard)的使用方式
早期event MPM有一些擴展能力的瓶頸,它會報這樣的錯:"scoreboard is full, not at MaxRequestWorkers"(記分牌已被占滿,但沒有達到允許的最大併發數量)。MaxRequestWorkers限制了任意時刻可以同時處理的請求數量,也限制了允許激活的進程數(MaxRequestWorkers/ThreadsPerChild)。於此同時,記分牌中記錄了所有正在運行的進程以及它們的工作線程的狀態信息。如果記分牌占滿了(所有的線程的狀態都不是idle),但是正在處理的請求數量卻沒有達到MaxRequestWorkers值,意味著有某些線程阻塞了本可以處理但卻排在隊列中的請求。線程的大多數時間被用在了Graceful的狀態,也就是說,它們為了讓TCP連接安全地終止,正在等待結束他們的工作,然後釋放記分牌中的槽位。有兩種很常見的情況:
-
在graceful restart時。父進程向所有子進程發送信號,通知它們完成它們的工作並終止,同時它重讀配置文件並派生新的子進程。如果舊的子進程仍然運行了一段時間,記分牌可能仍被它們占用,直到它們終止,記分牌中的槽位才被釋放。
-
當server需要以一種讓httpd殺子進程的方式來降低負載時(例如MaxSpareThreads的緣故)。這是一種非常嚴重的情況,因為當負載再次增高時,httpd將會重新生成新的進程。如果重覆出現這種情況,進程的數量會增多很多,最終導致正要嘗試被停止的進程和新創建的進程混合,使得進程管理的亂七八糟,記分牌中的信息也亂七八糟。
從httpd 2.4.24開始,event MPM可以足夠智能地處理graceful終止導致的問題。有以下一系列的提升:
- 允許記分牌中的槽位擴展到ServerLimit的數量。MaxRequestWorkers和ThreadsPerChild用於限制激活的進程數,於此同時,ServerLimit會考慮正在graceful關閉的進程,以便在需要的時候能提供更多的槽位。所以實現的方式是,使用ServerLimit的值來指導httpd關於在影響系統資源之前可以容忍多少總進程數。
- 強制正在graceful stop的進程關閉長連接狀態的連接。
- 在graceful stop期間,如果給定子進程中正在運行的工作線程數多於該子進程中已打開的連接數,終止這些多出的線程以便能更快地釋放資源。(在新建進程時可能需要這樣,因為當前線程數量會影響子進程的數量。)
- 如果記分牌已經滿了,阻止在降低負載殺進程時graceful stop進程,直到舊的子進程已經全部終止了才允許graceful stop(否則當負載再次增高時,情況會更糟,如前文所述)。
最後一點所描述的行為,完全可以通過mod_status中的連接狀態表中的"Slot"和"Stopping"列看出來。前者是槽位號,與PID對應,後者表示的是進程是否正在終止;
3.3.3 不足之處Limitations
對於那些已經聲明自己和event不相容的特定連接過濾器,上面所說的event的提升方式可能無法正確處理。這種情況下,event MPM將切回worker MPM,併為每個連接都保留一個工作線程(即再次將連接和線程綁定)。
一個類似的限制是,當前存在會調用輸出過濾器的請求,且這個輸出過濾器需要讀取或修改整個響應body。如果到客戶端的連接被阻塞了,但過濾器卻正在處理數據,正好過濾器產生的數據又非常大以致tcp寫緩衝區(tcp write buffer)無法裝下,那麼處理該請求的線程不會被釋放,httpd會一直等待直到待發送的數據已經全部發送給客戶端。
為瞭解決這個問題,我們考慮了下麵兩種途徑:提供一個靜態內容(例如一個CSS文件)和提供從FCGI/CGI或代理伺服器檢索的內容。前面的情況是可預見的,也就是說,直到到內容尾部,所有的內容對event MPM都是完全可見的:工作線程提供響應內容,並且可以向客戶端傳輸數據直到write()返回EWOULDLOCK或EAGAIN,然後將這種需要寫等待的套接字卸給監聽線程。這種情況下會等待發生在這個套接字上的事件,並且在等待到事件後找合適的時機將套接字重新分配給第一個空閑的工作線程以便將剩下的數據傳輸完。而後面一種情況(FCGI/CGI/代理內容),event MPM無法預測響應內容的結尾,這時工作線程在控制權返回給監聽線程前,它必須老老實實完成它的所有工作(包括將數據全部響應給客戶端)。
3.3.4 背景資料Background material
通過在操作系統中引入新型API(如下所列),使得事件驅動模型成為可能:
- epoll (Linux)
- kqueue (BSD)
- event ports (Solaris)
在新型API引入之前,只能使用的select和poll這兩種API。這些API在處理大量連接時速度很慢,在連接組(set of connections)的變化頻率較高時也會很慢。新型的API允許監控更多的連接,即使在連接組變化頻率較高時也能更好地工作。因此,這些新型的API使得event MPM成為可能:在有大量空閑連接時,這種模式比典型的httpd有更好的擴展能力。
這種MPM假定底層的apr_pollset的實現是線程安全的,這使得event MPM可以避免過高的鎖級別以及必須喚醒監聽線程以便轉交長連接狀態的套接字。當前僅支持KQueue和EPoll。
3.3.5 相關指令:AsyncRequestWorkerFactor
預設值為2。可設置為小數,例如1.5。
event MPM以非同步方式處理連接。非同步情況下,監聽線程會為每個連接請求分配一個很短時間的工作線程以建立非同步連接。但那些正在處理請求的工作線程則會保留對應的連接,這可能會導致一種場景:所有的工作線程都被連接綁定了,沒有空閑的工作線程來迎接新的請求以建立非同步連接。
event MPM會做以下兩件事來解決這個問題:
- 限制每個進程允許接受的連接數量,這依賴於空閑工作線程的數量。
- 如果某個進程中的所有工作線程都在忙,將關閉長連接狀態的連接,即使還沒有達到長連接的超時時間。這使得那個長連接的客戶端可以連接到其他進程,而這個進程中可能有空閑的線程。
該指令可以用來調整每個進程允許的連接數。只有噹噹前連接數(不包括正處於closing狀態的連接)小於下麵的表達式的值時,子進程才允許接收新連接。
ThreadsPerChild + (AsyncRequestWorkerFactor * number of idle workers)
評估所有進程可以接受的最大併發連接數:
(ThreadsPerChild + (AsyncRequestWorkerFactor * number of idle workers)) * ServerLimit
示例:
ThreadsPerChild = 10
ServerLimit = 4
AsyncRequestWorkerFactor = 2
MaxRequestWorkers = 40
idle_workers = 4 (為了方便,取所有進程中空閑線程的平均數)
max_connections = (ThreadsPerChild + (AsyncRequestWorkerFactor * idle_workers)) * ServerLimit
= (10 + (2 * 4)) * 4 = 72
當所有的工作線程都是空閑狀態時,可以使用下麵的表達式計算最大併發連接數:
(AsyncRequestWorkerFactor + 1) * MaxRequestWorkers
示例:
ThreadsPerChild = 10
ServerLimit = 4
MaxRequestWorkers = 40
AsyncRequestWorkerFactor = 2
如果所有進程的所有線程都是空閑時:
idle_workers = 10
我們可以用下麵兩種方法計算絕對最大允許的併發連接數:
max_connections = (ThreadsPerChild + (AsyncRequestWorkerFactor * idle_workers)) * ServerLimit
= (10 + (2 * 10)) * 4 = 120
max_connections = (AsyncRequestWorkerFactor + 1) * MaxRequestWorkers
= (2 + 1) * 40 = 120
調整AsyncRequestWorkerFactor需要基於各種httpd處理的流量情形,因此要改變它的預設值時需要做很多測試和數據收集(從mod_status獲取)
4. httpd三種MPM工作機制總結分析
到了httpd 2.4版本,prefork模式已經算比較弱勢了,特別是現在的event模式已經去掉了"該MPM正處於實驗階段"的標記。在完全支持event模式後,3種模式中無疑event模式性能最好,由於它也基於epoll,所以在併發處理能力上,和nginx的差距會縮小不少。
這樣說來,似乎都不需要再用prefork、worker了?但event畢竟從長期的"實驗階段"翻身不久,誰知道有沒有什麼"隱疾"呢?而且,據php官方說明,當php以模塊方式安裝到apache httpd中時,不建議httpd使用線程的工作方式,也就是說應該使用prefork模式。當然,使用php-fpm方式管理php-cgi時就無所謂了。
4.1 web服務處理請求的過程
在分析三種MPM之前,先以worker模式對httpd從監聽開始到處理請求的過程做個全局的分析。再此建議先閱讀套接字和TCP連接的過程。
首先是監聽過程。假設沒有使用套接字重用技術(預設情況下都沒有開啟),那麼每個子進程中的監聽線程都在爭搶監聽同一個監聽套接字。為了避免"饑餓問題",在某一個時刻,應該只能有一個監聽線程監聽在這個套接字上,而其他監聽線程需要被阻塞,那麼哪個監聽線程才有資格監聽在這個套接字上呢?
在說明這個問題之前,先說說httpd的監聽線程和工作線程的交互。
4.1.1 監聽線程和工作線程的交互
當監聽線程監聽到客戶端發起了TCP連接請求時,它將請求接進來,並創建連接套接字放入到套接字隊列中(註意,監聽線程創建的這個套接字是連接套接字,和監聽套接字不是同一個,監聽套接字是被監聽者通過select/poll或epoll來輪詢的,而連接套接字是提供給工作線程用來和客戶端通信的。還是那句話,如果不明白兩種套接字請先閱讀套接字和TCP連接的過程)。至此,監聽線程就完成了一個任務,準備去監聽下一個連接請求。而工作線程則在空閑時取出隊列中的第一個連接套接字,在得到連接套接字時它就和客戶端建立了聯繫,可以進行數據交互,於是開始處理客戶端發送的請求。
回到監聽資格的問題上。如果監聽線程發現這個子進程中已經沒有空閑的工作線程,那麼監聽線程就不應該去監聽新的連接請求,因為即使接進來了也無法立即處理。如何才能不去監聽呢?httpd通過accept互斥鎖(accept mutex)來實現,當它發現這個子進程中還可以接受新請求時,它就會持有accept互斥鎖,持有這個鎖時它就可以通過類似accept()函數去接受新請求、返回連接套接字並放入套接字隊列中,等待空閑的工作線程取走。於是可以得出結論:監聽線程除了select/poll/epoll監控套接字,還判斷子進程中空閑工作線程的數量(每當工作線程從忙轉為空閑,都會通知監聽線程)。
也就是說,accept mutex就是監聽者的監聽資格。如果多個子進程同時都有空閑工作線程,這些監聽者不就又開始爭搶了嗎?沒錯,這就是前面說的"驚群問題",在event模式下,監聽線程採用非阻塞IO的epoll來避免這個問題,而worker模式如何解決的我不清楚,假設通過一次喚醒一個監聽線程來解決,那麼結合上面所說的,監聽線程和工作線程的交互方式如下圖所示:
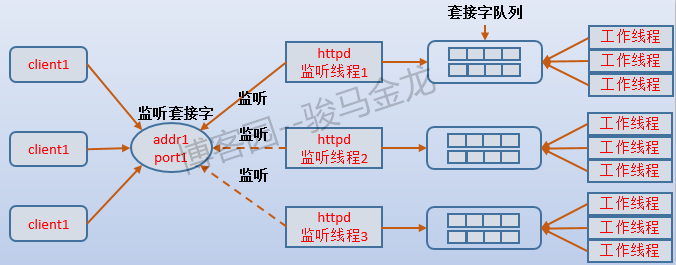
藉此可以想象得到,prefork模式下,一個子進程既要負責監聽又要負責工作,它的套接字隊列存在與否並不重要,而且子進程的最大數量決定了某一個時刻可以處理的最大請求數量。worker模式下,每個子進程的套接字隊列至少要大於或等於最大工作線程數,因為是否有空閑工作線程決定了監聽線程是否可以獲得accpet mutex,子進程能否接受新請求的yes/no狀態也取決於該子進程是否有idle worker。對於event模式則要特殊一點,因為event模式採用epoll監控非阻塞的監聽套接字,且它還維持了工作卸載給監聽線程的writing、keep-alive和closing三種狀態的連接,所以對監聽線程判斷空閑工作線程數量時,會因為接收到這3種狀態的連接時而導致一些"誤判"。這樣可能導致的情況是,工作線程全都是busy狀態,但子進程能否接受新請求的yes/no狀態卻為yes,連接數也大於工作線程數。
例如,下麵是某次event模式的部分記分板信息。
Slot PID Stopping Connections Threads Async connections
total accepting busy idle writing keep-alive closing
0 42480 no 25 yes 25 0 1 0 0
1 42481 no 26 yes 25 0 2 0 0
2 42482 no 27 yes 25 0 3 0 2
3 42564 no 27 yes 24 1 2 0 1
4 42618 no 28 yes 25 0 3 0 1
5 42651 no 28 yes 24 1 1 0 2
其中每個子進程最大工作線程數位25,但當busy=25時,卻仍顯示"accepting=yes,total>25",這正是非同步連接導致的。而prefork和worker都是同步連接,能否繼續接受新請求,嚴格受限於是否有空閑工作者。(同步、非同步連接和同步、非同步IO模型是不同的概念)
4.1.2 工作線程獲取數據的過程分析
一張圖說明。
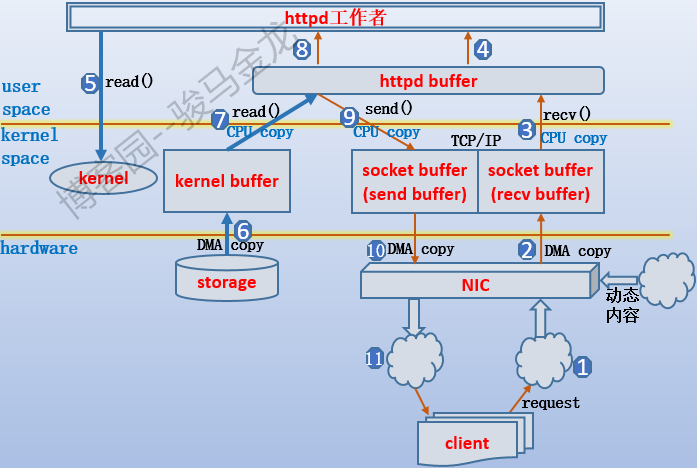
如果對IO過程熟悉,這張圖也很容易理解,如果不熟悉,這張圖就像天書,具體可參考網路數據傳輸的全過程的這一小節。下麵大致描述下這張圖的過程。需要說明,這張圖是工作者和客戶端的通信過程,和監聽者的監聽過程沒有關係,也就是說監聽者已經把連接套接字交給了工作者,假設是worker下的工作線程。
首先客戶端發送http請求,通過網卡將請求數據傳輸到TCP的recv buffer中,worker線程將請求數據從recv buffer中複製到它自己的httpd buffer,於是worker線程可以訪問、修改該請求數據,例如URL重寫、url翻譯轉換等。如果分析出這個http請求是某個靜態文件,則需要從硬體中載入對應文件,於是發起系統調用通知內核去載入,數據從磁碟中載入到內核的kernel buffer中,再從kernel buffer中複製到httpd buffer,於是worker線程開始準備構建響應數據,這個過程中worker線程可以修改httpd buffer中的數據,例如添加一個相應首部,構建完成後將數據複製到TCP的send buffer中,再複製到網卡中通過網路傳輸給客戶端。假如worker線程分析到這次請求的是動態內容,則需要將動態請求轉發給對應的伺服器,並最終從該伺服器中獲取到結果,這個結果很可能也是通過TCP連接進行傳輸的(假設動靜分離了),那麼數據就從網卡複製到recv buffer,再複製到httpd buffer,再構建響應。
4.2 prefork模式
這種模式是最簡單的模式,而且設置成這種模式後,連指令的值都基本可以採用預設值,因為httpd主進程有很強的自我調節能力。
prefork模式下,一個以root身份運行的主httpd進程(父進程)負責fork一堆以普通身份運行的子httpd進程。啟動httpd時,初始化創建的子進程數量由StartServers指令指定。對於prefork模式來說,預設值為5。
4 S root 69856 1 0 80 0 - 56536 poll_s 19:47 ? 00:00:00 /usr/sbin/httpd -DFOREGROUND
5 S apache 69857 69856 0 80 0 - 57057 inet_c 19:47 ? 00:00:00 /usr/sbin/httpd -DFOREGROUND
5 S apache 69858 69856 0 80 0 - 57057 inet_c 19:47 ? 00:00:00 /usr/sbin/httpd -DFOREGROUND
5 S apache 69859 69856 0 80 0 - 57057 inet_c 19:47 ? 00:00:00 /usr/sbin/httpd -DFOREGROUND
5 S apache 69860 69856 0 80 0 - 57057 inet_c 19:47 ? 00:00:00 /usr/sbin/httpd -DFOREGROUND
5 S apache 69861 69856 0 80 0 - 57057 inet_c 19:47 ? 00:00:00 /usr/sbin/httpd -DFOREGROUND
父進程只負責管理維護子進程,例如把超出空閑數量的子進程殺掉,空閑子進程數量不足時創建幾個新的子進程,殺掉出了故障的子進程等。子進程才是負責監聽和處理web請求的進程,當有請求到達,空閑的子進程會迎接該請求並和該客戶端建立連接。通過ServerLimit指令可以硬控制最大的子進程數量,預設值為256,這個值已經很高了,不用改。
為了保證新進來的請求能儘可能快地被處理,prefork的父進程會維護一個空閑子進程池,最大空閑子進程數量和最小空閑子進程數量分別由MaxSpareServers(預設值為10)和MinSpareServers(預設值為5)指定,但通常來說不需要去改變這兩個指令的預設值,除非在非常繁忙的站點上。此外,MaxRequestWorkers指令用於設置最大允許的併發連接數量,如果某一刻涌進了大量連接請求,超出該指令值的連接請求會暫時放入等待隊列中。
prefork的缺點就是用進程去處理請求,相比於線程,進程太過重量級,對於繁忙的站點來說,不斷處理新請求,就需要不斷地在進程之間進行切換,進程切換動作對cpu來說是沒有生產力的,切換太頻繁會浪費很多cpu資源。另一方面,httpd的各子進程之間不共用記憶體,在一定程度上性能也夠好。但它也有優點,基於進程的處理方式,穩定性和調節能力比較好。
另外,由於進程之間的地址空間是相互獨立的,多個子進程請求同一個文件時,各子進程都會使用一個獨立記憶體空間去存放這段數據,所以對記憶體的利用可能浪費比較嚴重。而如果採用線程,由於子進程中的線程可以共用存放這段數據的空間,所以只需使用少量記憶體即可。
4.3 worker模式
worker模式是對prefork模式的改進,在進程方面,它和prefork一樣,有root身份的父httpd進程,普通身份的子httpd進程。httpd啟動時,初始化創建的子進程數量由StartServers指令決定(worker模式下預設為3)。但不同的是,在每個子進程下還有一堆線程。這些線程包括工作線程(worker thread)和一個額外的監聽線程(listener thread)。
[root@xuexi ~]# pstree -p | grep http[d]
|-httpd(43510)-+-httpd(43512)-+-{httpd}(43516)
| | |-{httpd}(43520)
| | |-{httpd}(43521)
| | |-{httpd}(43523)
| | |-{httpd}(43524)
| | |-{httpd}(43525)
| | |...............
| |-httpd(43513)-+-{httpd}(43518)
| | |-{httpd}(43546)
| | |-{httpd}(43547)
| | |-{httpd}(43548)
| | |...............
| `-httpd(43514)-+-{httpd}(43522)
| |-{httpd}(43551)
| |-{httpd}(43553)
| |-{httpd}(43555)
| |-{httpd}(43556)
| |-{httpd}(43558)
| |...............
監聽線程負責輪詢(poll模式)監控開放的服務埠,接收請求並建立連接,然後將連接套接字放入套接字隊列中,當工作線程"閑"下來時,將套接字從套接字隊列中讀走並開始處理。每當工作線程閑下來,都會通知監聽線程它當前空閑,這樣一來,監聽線程就知道它所在子進程中是否還有空閑的工作線程,如果沒有空閑工作線程,即滿負荷狀態,則監聽線程暫時不會去接受新連接請求,因為即使接進來放到套接字隊列中,也沒有工作線程可以立即處理它們。
由於每個子進程中的監聽線程都在輪詢地監聽開放的埠,所以必須要讓每個監聽線程去獲取一種互斥鎖(mpm-accept mutex),只有非滿負荷的監聽線程才能去爭搶互斥鎖,也才能將連接請求搶到自己的地盤。
這同樣說明瞭,無論是prefork/worker/event或者其他網路模型,在某一刻總是只有一個子進程/線程在監聽這個埠,更嚴格地說是監聽已經bind好的套接字描述符。這個效率是不怎麼高的,所以現在的Linux內核中已經加入了埠重用選項SO_REUSEPORT,再加上地址重用選項SO_REUSEADDR,就可以讓bind將套接字描述符綁定在同一個地址:埠上,這意味著多實例、多進程、多線程可以同時監聽同一個套接字。舉個簡單的例子,預設情況下,同一臺主機上行如果要啟動兩個sshd服務程式,必須讓前後啟動的服務程式載入含有不同"ADDR:PORT"選項的配置文件,否則會報錯。而通過埠重用技術,就可以讓這兩個sshd同時監聽在同一個套接字上,當請求到達時,會通過round-robin均衡演算法進行輪詢。關於apache開啟以及配置埠重用的指令見ListenCoresBucketsRatio。關於地址重用和埠重用技術,見地址/埠重用技術。
回歸正題。當子進程中的工作線程處於滿負荷狀態時,監聽線程不會接收新的連接請求。當變為非滿負荷狀態,那麼空閑下來的那個工作線程必然是第一個空閑進程,它必須去通知監聽線程,讓監聽線程知道現在有空閑工作線程,可以讀取套接字隊列,於是監聽線程會去爭搶互斥鎖以監聽開放的埠。
和prefork一樣,父進程負責維護子進程的數量。而子進程負責維護該子進程下的線程數量。無論是子進程還是每個子進程下的線程以及空閑的線程數,都有數量限制。ThreadsPerChild指令用於設置每個子進程中的線程數量,MaxSpareThreads和MinSpareThreads指令分別設置每個子進程中最大和最小的空閑線程數,MaxRequestWorkers指定最大允許的併發連接數。
由於每個線程處理一個請求,所以在某一時刻,MaxRequestWorkers的值和此刻線程的數量決定了是否要新創建子進程,以及創建幾個子進程。例如某一個時刻線程數量為40,MaxRequestWorkers指令的值為400,那麼應該至少要提供10個子進程,少了就要新創建,這都是httpd主進程自動調節的。同理,子進程內的線程也一樣,少了就要創建。但顯然,不能無限制地創建子進程和線程,所以提供了兩個硬限制指令ServerLimit和ThreadLimit,表示即使自動調節時會創建新子進程或線程,但也不能分別超過這兩個指令指定的數量。
在理論上,worker比prefork更優,不僅因為它繼承了prefork的多進程穩定性和自我調節能力,更重要的是它使用線程來處理每個請求,且還提供了一個專門的監聽線程。由於進程中的線程可以共用所在進程的資源,且某個線程的阻塞不會影響進程內其它線程的運行,再一方面,線程共用了子進程的很多資源,它在上下文切換時只需保存、恢復它自己所負責的那一小部分上下文,比進程的切換要輕量的多。因此,線程的工作方式在處理web請求時,無疑比進程性能要好的多。
但是,那隻是理論上的。在Linux系統上,實現的線程僅僅只是輕量級的進程,而不是真正意義上的線程。線程沒有自己的記憶體地址空間,有時候一個線程的"崩潰"會導致整個進程"死掉"(例如對公共資源造成了破壞),而且,一個線程寫壞另一個線程的棧空間也是很正常的。也就是說,使用線程是不安全的,它的穩定性不如進程。所以,無論是worker還是event模式,都明確說明瞭要保證線程安全。
關於線程對進程的影響,舉個網上找來的例子,雖然不太合理,但描述它們的相互相互影響的方式很合適。
主進程是整輛火車,子進程是每一小節車廂,車廂里的每個乘客是各個線程。每節車廂都有自己公共的衛生間(進程內線程的公共資源:如堆記憶體),每個乘客也有自己的座位(線程自身的資源:棧空間)。如果某個乘客把自己的座椅搞壞了,那是他自己倒霉,不會影響其他乘客,也不會影響這一節車廂,更不會影響整輛火車。如果某個乘客把別的乘客的座椅搞壞了,比如他旁邊的,那麼那個人就倒霉,這樣也不會影響車廂。但如果某個乘客把公共衛生間搞壞了,這節車廂就整個一起"死",其他乘客只能陪葬。
即使如此,對於httpd來說,在大併發時,使用worker線程處理請求的方式,比使用prefork處理請求的方式性能要好的多。即使某個子進程死了,原本它的線程保持的連接也可以找新的子進程里的線程,只不過對這不幸的一小部分請求來說,它們有可能要重新排排隊。
4.4 event模式
event模式的優點在前面就已經說了。它是在worker模式上改進的,也是"主進程-->子進程-->工作線程+監聽線程"的方式。它改進的地方是使用了事件驅動IO復用模型(基於epoll),強化了監聽線程的工作能力。相比worker模式,它最直觀的提升是大大改善了處理長連接(keep alive)的方式,可以一個線程處理多個連接請求。
先說說httpd響應客戶端的過程。當httpd進程/線程處理完請求後,就需要構建響應並把相關數據傳輸給客戶端。從開始響應的那一刻開始,內核將數據從內核緩衝區(kernel buffer)源源不斷地複製到用戶空間的httpd的緩衝區(app buffer),於此同時,httpd進程/線程在app buffer有數據時立即將其中的數據複製到TCP的send buffer中,然後通過網路傳輸給客戶端,直到所有數據都傳輸完,這次響應才算真正結束。
再說說長連接。當某個請求已經響應結束了,相應的TCP連接也應該立即斷開(套接字也被關閉)。如果啟用了長連接功能,那麼在響應結束後,和發起這個請求的客戶端的TCP連接會繼續保持著而不會立即斷開,這時的TCP連接稱為"長連接狀態"。當長連接的客戶端再次發起請求時,就可以繼續使用這個TCP連接進行通信,也就是說不用再重新建立TCP連接。沒有開啟長連接時,每次建立TCP連接和斷開


