
上周拿到了我的第一個工作任務,統計一個按天分區每天都有百億條數據條的hive表中account欄位的非重用戶數(大概兩千萬)。後來又更改為按id欄位分別統計每個id的用戶數。 按照我資料庫老師的教導,我很輕易的跳出來了count(distinct account)這個句子。然後寫上了一行查詢,等待了 ...
上周拿到了我的第一個工作任務,統計一個按天分區每天都有百億條數據條的hive表中account欄位的非重用戶數(大概兩千萬)。後來又更改為按id欄位分別統計每個id的用戶數。
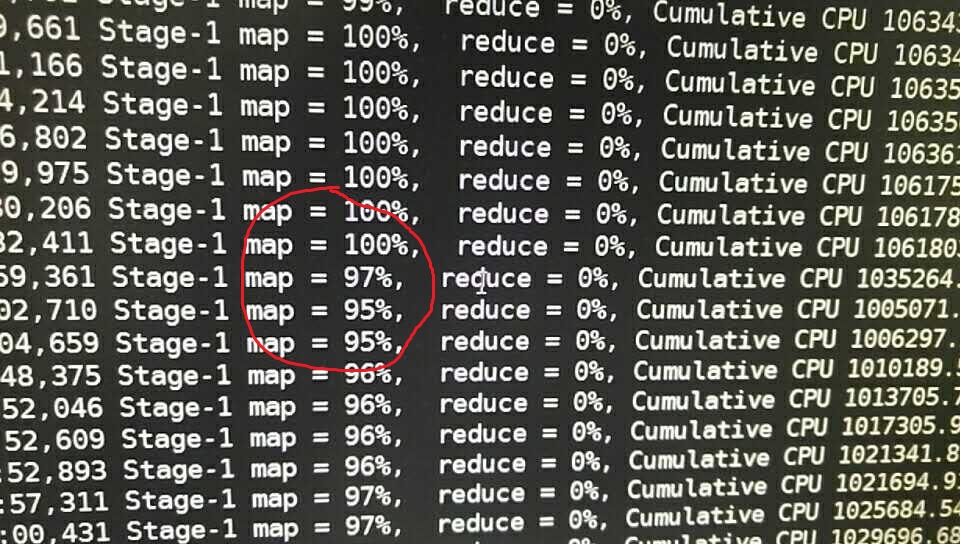
按照我資料庫老師的教導,我很輕易的跳出來了count(distinct account)這個句子。然後寫上了一行查詢,等待了四個小時,然後map反著跑
 就知道沒這麼容易的任務。。
就知道沒這麼容易的任務。。
然後想起來Hive SQL 基於的mapreduce是並行計算,百億的數據可不是平時測試時的mysql里的幾百條數據。
這麼想來應該是map和reduce的記憶體不夠,
set mapreduce.map.memory.mb=48192; set mapreduce.reduce.memory.mb=48192;
執行語句
select count(distinct account) from...where...
繼續mapreduce,三個小時後報錯error in shuffle in fetcher#3. shuffle過程又出問題了。
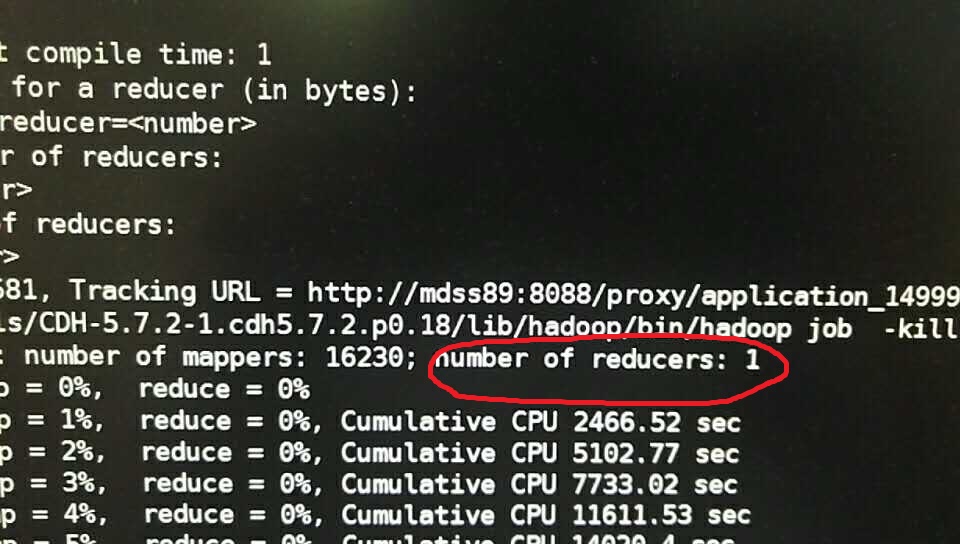
找呀找,reducer只有1? 那還怎麼並行?果斷
set mapred.reduce.tasks=1000;
又進行查詢,發現reducer 還是1。 只能求助於萬能的Internet了。
原來因為加入distinct,map階段不能用combine消重,數據輸出為(key,value)形式然後在reduce階段進行消重。
重點是,Hive在處理COUNT這種“全聚合(full aggregates)”計算時,它會忽略用戶指定的Reduce Task數,而強制使用1。
示意圖如下

解決辦法:轉換為子查詢,轉化為兩個mapreduce任務 先select distinct的欄位,然後在count(),這樣去重就會分發到不同的reduce塊,count依舊是一個reduce但是只需要計數即可。
select count(*) from (select distinct account form tablename where...)t;
這樣大概半小時可以得到結果。
後來需求改變為對這個表按account的類型(欄位名為id)統計每個類型的account非重覆數。
如果按照上述方法,在查詢條件添加 where id=..,這樣每個查詢都需要半小時,效率很低。
優化方法:利用gourp by 按id,account分組,存入一個臨時表 只需要對臨時表進行統計即可
insert overwrite table temp select id,account,count(1) as num from tablename group by id,account;
這樣temp表裡的數據直接就是非重數據,並且按id升序排序,按id篩選 count(*)即可。 sum(num)也可統計總數。
參考:http://blog.csdn.net/xiewenbo/article/details/29559075


