
分散式系統中主要的問題就是如何保持節點狀態的一致性,不論發生任何failure,只要集群中大部分的節點可以正常工作,則這些節點具有相同的狀態,保持一致,在client看來相當於一臺機器。 一致性問題本質就是replicated state machines,即所有結點都從同一個state出發,都經過 ...
分散式系統中主要的問題就是如何保持節點狀態的一致性,不論發生任何failure,只要集群中大部分的節點可以正常工作,則這些節點具有相同的狀態,保持一致,在client看來相當於一臺機器。
一致性問題本質就是replicated state machines,即所有結點都從同一個state出發,都經過同樣的一些操作序列(log),最後到達同樣的state。其中保證各個節點執行相同的操作序列就是raft演算法所要實現的。在raft演算法中有一個Leader的角色,client與之進行交互,並且Leader協調Follower,保障所有的Follower具有相同的操作序列,最後提交這些操作,使狀態機達成一個新的一致的stat。
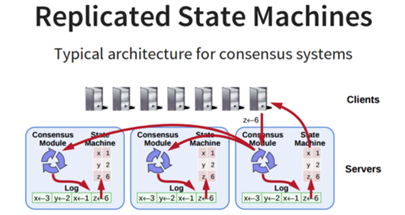
整個raft演算法分為Leader選舉,日誌分發,日誌壓縮(快照),集群成員變更。其中的Leader選舉是演算法的核心部分。演算法保證任何時候最多只有一個Leader,但是可能沒有Leader(比如正在選舉過程中或者集群成員多數不可用時)。在Leader確立之後,就可以進行日誌分發,演算法保證日誌會被安全的分發到集群中並且應用到狀態機的日誌和自己相同。快照是為了減少日誌量,去除中間過程。集群成員變更是為了在不停服務的情況下安全使用新的集群配置。
Raft在非拜占庭錯誤情況下,包括網路延遲、分區、丟包、冗餘和亂序等錯誤都可以保證正確,不會返回錯誤結果,這就是安全性保證。實際上就是保證所有成員狀態機都以同樣的順序,執行同樣的命令。下麵分析幾種典型的場景下,raft是如何保證安全性的。
1. Leader選舉之後,如果Follower與Leader日誌有衝突該如何處理?
Raft規定Follower中的衝突日誌會被Leader中的日誌覆蓋,使得Follower中的日誌總是與Leader的日誌保持一致。Leader必須找到Follower日誌中最後兩者達成一致的地方,然後刪除從那個點之後的所有日誌條目,發送自己的日誌給Follower。所有的這些操作都在進行日誌複製RPC的一致性檢查時完成: Leader針對每一個Follower維護了一個 nextIndex,表示下一個需要發送給Follower的日誌條目的index。當一個Leader剛獲得權力的時候,他初始化所有的 nextIndex 值為自己的最後一條日誌的index加1。Leader每次發送日誌複製RPC的時候會包含兩個值:prevLogIndex和prevLogTerm,分別對應緊隨新日誌條目之前日誌的索引值(index)和任期號(term),即prevLogIndex = newIndex - 1,如果Follower在它的日誌中找不到包含Leader發送過來的index和term的條目,那麼他就會拒絕接收新的日誌條目。也就是此時Follower的日誌和Leader不一致,日誌複製RPC 時的一致性檢查就會失敗。在被Follower拒絕之後,Leader就會減小 nextIndex 值併進行重試。最終 nextIndex 會在某個位置使得Leader和Follower的日誌達成一致。當這種情況發生,日誌複製 RPC 就會成功,這時就會把Follower衝突的日誌條目全部刪除並且加上Leader的日誌。一旦日誌複製 RPC 成功,那麼Follower的日誌就會和Leader保持一致,並且在接下來的任期里一直繼續保持。通過上述步驟,Raft演算法保證了日誌是順序複製的。就是說,假如有一條舊的日誌還未複製給FollowerA,那麼更新的日誌就不能複製。日誌的順序複製,很大程度上簡化了Raft演算法。比如查看各成員日誌的新舊,只要比較最後一條日誌即可。
2. 如果在一個Follower宕機的時候Leader提交了若幹的日誌條目,然後這個Follower上線後可能會被選舉為Leader並且覆蓋這些日誌條目,如此就會產生不一致。
Raft通過對Leader的選舉進行限制,來保證所新選出的任何Leader對於給定的任期號,都擁有了之前任期的所有被提交的日誌條目,限制規則為:candidate發送出去的投票請求消息必須帶上其最後一條日誌條目的Index與Term;接收者需要判斷該Index與Term至少與本地日誌的最後一條日誌條目一樣新,否則不給投票。因為 前一個Leader提交日誌條目的條件是日誌複製給集群中的多數成員,Candidate選舉為Leader的條件也是需要多數成員的投票。那麼這兩個大多數中成員必定有一個交叉,即有一個成員具有該日誌,並且投票給了新Leader,也就意味著新Leader的日誌至少不比該成員舊,那麼新Leader也具有該日誌。這樣就得到證明瞭,後續的Leader一定具有前面Leader提交的日誌。
3. 即使保證上述選舉規則,也不能保證一致性,也就是說會出現Leader提交了前面任期的日誌條目之後,該條目還有可能被後來的Leader覆蓋而產生不一致。如下圖所示:

- (a) S1是Leader,並且部分地複製了index-2;
- (b) S1宕機,S5得到S3、S4、S5的投票當選為新的Leader(S2不會選擇S5,因為S2的日誌較S5新),並且在index-2寫入到一個新的條目,此時是term=3(註:之所以是term=3,是因為在term-2的選舉中,S3、S4、S5至少有一個參與投票,也就是至少有一個知道term-2,雖然他們沒有term-2的日誌);
- (c) S5宕機,S1恢復並被選舉為Leader,並且開始繼續複製日誌(也就是將來自term-2的index-2複製給了S3),此時term-2,index-2已經複製給了多數的伺服器,但是還沒有提交;
- (d) S1再次宕機,並且S5恢復又被選舉為Leader(通過S2、S3、S4投票,因為S2、S3、S4的term=4<5,且日誌條目(為term=2,index=2)並沒有S5的日誌條目新,所以可以選舉成功),然後覆蓋Follower中的index-2為來自term-3的index-2;(註:此時出現了,term-2中的index-2已經複製到三台伺服器,還是被覆蓋掉);
- (e) 然而,如果S1在宕機之前已經將其當前任期(term-4)的條目都複製出去,然後該條目被提交(那麼S5將不能贏得選舉,因為S1、S2、S3的日誌term=4比S5都新)。此時所有在前的條目都會被很好地提交。
如果上述情況(c)中,term=2,index=2的日誌條目被覆制到大多數後,如果此時當選的S1提交了該日誌條目,則後續產生的term=3,index=2會覆蓋它,此時就可能會在同一個index位置先後提交一個不同的日誌,這就違反了狀態機安全性,產生不一致。也就是說當一個新Leader當選時,由於所有成員的日誌進度不同,很可能需要繼續複製前面term的日誌條目,就算複製到多數伺服器並且提交,還是可能被覆蓋,因為前面term對應的日誌條目較舊,容易使的沒有這些條目的其他伺服器當選Leader,此時就會覆蓋這些日誌條目。
為了消除上述場景就規定Leader可以複製前面任期的日誌,但是不會主動提交前面任期的日誌。而是通過提交當前任期的日誌,而間接地提交前面任期的日誌。
4.配置變更的時候,需要保證任何時候只能有一個Leader,直接從舊的配置轉化到新配置的方案是不安全的,如下圖所示:
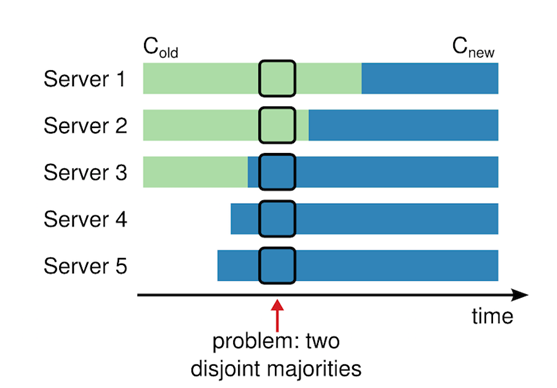
轉換過程中,server1,server2通過舊配置選出一個Leader(三臺中的兩台支持),server3,server4,server5通過新配置選出一個Leader(五臺中的三台支持),這樣在同一個term中就有兩台Leader,造成不一致,為了保證安全性,配置更改必須使用兩階段方法。在 Raft 中,集群先切換到一個過渡配置,我們稱之為共同一致;一旦共同一致已經被提交了,那麼系統就切換到新的配置上。

過渡配置保證不會在old與new兩個配置上同時產生Leader :
過渡配置是指由 old配置和 new複合成的一個新配置(old+new)。
Leader會將該過渡配置日誌先應用到本地,然後複製給集群中的所有成員。所有收到配置的成員,會直接將配置應用到本地。
處於過渡配置的成員,在Leader選舉與提交日誌時規則發生了變化,要求分別得到old與new兩個配置下的多數成員同意才行。比如:
old:1、2、3
new:2、3、4、5、6 (刪除機器1,增加機器4、5、6)
old+new:1、2、3、4、5、6(機器是old+new所有機器)
那麼處於過渡配置的成員在Leader選舉與提交日誌時,需要得到 old(1、2、3)三個成員中的多數支持,以及new(2、3、4、5、6)五個成員中的多數支持(而不是old+new中六個成員的多數)。
那麼上述過度配置如何保證不同時間段只產生一個Leader:
1)從old -> old+new配置提交之前
此時還未產生new配置,因此不可能在new配置下產生Leader。
那麼是否可能在old與old+new下分別產生Leader哪? old下要產生Leader需要old中的多數投票,old+new下要產生Leader也需要old中的多數投票,而要在old與old+new下分別產生Leader,則old中至少有一個成員同時投票給old與old+new中的Leader。根據投票規則,在一個term下只能投票一次,因此就不可能在old與old+new配置下在同一個term上分別產生Leader。
而在不同term下產生則不違反規則,因為新的term下產生的Leader,發送心跳給舊Leader,舊Leader就會馬上變成Follower。
2)old+new提交之後
只要old+new這個配置提交,則意味著該配置已經複製給了old中的多數成員,那麼在old配置中就不可能再產生一個Leader出來了。只能在old+new與new配置下產生。而在old+new與new中也不可能在同一個term下分別選舉出Leader,這個證明與old與old+new配置是一樣的。
若每次增加或者刪除一個成員不需要過渡配置:
就是說,每次配置變更只能增加或者刪除一個成員。若滿足則可以直接從old配置轉換到new配置。
證明:舊配置有N個成員,新配置有N+1個成員,在切換過程中不會在舊配置與新配置下分別產生Leader。
1)若舊配置下選舉出Leader,那麼需要N/2+1個成員投票。
2)新配置下,從成員數是N+1去掉以及投票的N/2+1個成員只剩下N/2個成員。
3)而新配置下要選舉出Leader需要(N+1)/2+1=N/2+3/2個成員投票,但是只剩下N/2個成員可以投票,因此新配置下不可能再選舉出Leader。
4)反過來也一樣。
參考: http://www.blogjava.net/jinfeng_wang/archive/2017/02/03/432287.html
http://blog.csdn.net/hfty290/article/details/75331948

