
概覽 首先我們來認識一下HDFS, HDFS(Hadoop Distributed File System )Hadoop分散式文件系統。它其實是將一個大文件分成若幹塊保存在不同伺服器的多個節點中。通過聯網讓用戶感覺像是在本地一樣查看文件,為了降低文件丟失造成的錯誤,它會為每個小文件複製多個副本(默 ...
概覽
首先我們來認識一下HDFS, HDFS(Hadoop Distributed File System )Hadoop分散式文件系統。它其實是將一個大文件分成若幹塊保存在不同伺服器的多個節點中。通過聯網讓用戶感覺像是在本地一樣查看文件,為了降低文件丟失造成的錯誤,它會為每個小文件複製多個副本(預設為三個),以此來實現多機器上的多用戶分享文件和存儲空間。
HDFS特點:
① 保存多個副本,且提供容錯機制,副本丟失或宕機自動恢復。預設存3份。
② 運行在廉價的機器上。
③ 適合大數據的處理。因為小文件也占用一個塊,小文件越多(1000個1k文件)塊越 多,NameNode壓力越大。
如:將一個大文件分成三塊A、B、C的存儲方式
PS:數據複製原則:
除了最後一個塊之外的文件中的所有塊都是相同的大小。
HDFS的放置策略:
是將一個副本放在本地機架中的一個節點上,另一個位於不同(遠程)機架中的節點上,而最後一個位於不同節點上遠程機架。
涉及到的屬性:
塊大小:Hadoop1版本里預設為64M,Hadoop2版本里預設為128M
複製因數:每個文件加上其文件副本的份數
HDFS的基本結構

如上圖所示,HDFS基本結構分NameNode、SecondaryNameNode、DataNode這幾個。
NameNode:是Master節點,有點類似Linux里的根目錄。管理數據塊映射;處理客戶端的讀寫請求;配置副本策略;管理HDFS的名稱空間;
SecondaryNameNode:保存著NameNode的部分信息(不是全部信息NameNode宕掉之後恢複數據用),是NameNode的冷備份;合併fsimage和edits然後再發給namenode。(防止edits過大的一種解決方案)
DataNode:負責存儲client發來的數據塊block;執行數據塊的讀寫操作。是NameNode的小弟。
熱備份:b是a的熱備份,如果a壞掉。那麼b馬上運行代替a的工作。
冷備份:b是a的冷備份,如果a壞掉。那麼b不能馬上代替a工作。但是b上存儲a的一些信息,減少a壞掉之後的損失。
fsimage:元數據鏡像文件(文件系統的目錄樹。)
edits:元數據的操作日誌(針對文件系統做的修改操作記錄)
namenode記憶體中存儲的是=fsimage+edits。
NameNode詳解
作用:
Namenode起一個統領的作用,用戶通過namenode來實現對其他數據的訪問和操作,類似於root根目錄的感覺。
Namenode包含:目錄與數據塊之間的關係(靠fsimage和edits來實現),數據塊和節點之間的關係
fsimage文件與edits文件是Namenode結點上的核心文件。
Namenode中僅僅存儲目錄樹信息,而關於BLOCK的位置信息則是從各個Datanode上傳到Namenode上的。
Namenode的目錄樹信息就是物理的存儲在fsimage這個文件中的,當Namenode啟動的時候會首先讀取fsimage這個文件,將目錄樹信息裝載到記憶體中。
而edits存儲的是日誌信息,在Namenode啟動後所有對目錄結構的增加,刪除,修改等操作都會記錄到edits文件中,並不會同步的記錄在fsimage中。
而當Namenode結點關閉的時候,也不會將fsimage與edits文件進行合併,這個合併的過程實際上是發生在Namenode啟動的過程中。
也就是說,當Namenode啟動的時候,首先裝載fsimage文件,然後在應用edits文件,最後還會將最新的目錄樹信息更新到新的fsimage文件中,然後啟用新的edits文件。
整個流程是沒有問題的,但是有個小瑕疵,就是如果Namenode在啟動後發生的改變過多,會導致edits文件變得非常大,大得程度與Namenode的更新頻率有關係。
那麼在下一次Namenode啟動的過程中,讀取了fsimage文件後,會應用這個無比大的edits文件,導致啟動時間變長,並且不可控,可能需要啟動幾個小時也說不定。
Namenode的edits文件過大的問題,也就是SecondeNamenode要解決的主要問題。
SecondNamenode會按照一定規則被喚醒,然後進行fsimage文件與edits文件的合併,防止edits文件過大,導致Namenode啟動時間過長。
DataNode詳解
DataNode在HDFS中真正存儲數據。
首先解釋塊(block)的概念:
- DataNode在存儲數據的時候是按照block為單位讀寫數據的。block是hdfs讀寫數據的基本單位。
- 假設文件大小是100GB,從位元組位置0開始,每128MB位元組劃分為一個block,依此類推,可以劃分出很多的block。每個block就是128MB大小。
- block本質上是一個 邏輯概念,意味著block裡面不會真正的存儲數據,只是劃分文件的。
- block里也會存副本,副本優點是安全,缺點是占空間
SecondaryNode
執行過程:從NameNode上 下載元數據信息(fsimage,edits),然後把二者合併,生成新的fsimage,在本地保存,並將其推送到NameNode,同時重置NameNode的edits.
工作原理(轉自“大牛筆記”的博客,由於實現是清晰,受益很大,在此不做改動)
寫操作:

有一個文件FileA,100M大小。Client將FileA寫入到HDFS上。
HDFS按預設配置。
HDFS分佈在三個機架上Rack1,Rack2,Rack3。
a. Client將FileA按64M分塊。分成兩塊,block1和Block2;
b. Client向nameNode發送寫數據請求,如圖藍色虛線①------>。
c. NameNode節點,記錄block信息。並返回可用的DataNode,如粉色虛線②--------->。
Block1: host2,host1,host3
Block2: host7,host8,host4
原理:
NameNode具有RackAware機架感知功能,這個可以配置。
若client為DataNode節點,那存儲block時,規則為:副本1,同client的節點上;副本2,不同機架節點上;副本3,同第二個副本機架的另一個節點上;其他副本隨機挑選。
若client不為DataNode節點,那存儲block時,規則為:副本1,隨機選擇一個節點上;副本2,不同副本1,機架上;副本3,同副本2相同的另一個節點上;其他副本隨機挑選。
d. client向DataNode發送block1;發送過程是以流式寫入。
流式寫入過程,
1>將64M的block1按64k的package劃分;
2>然後將第一個package發送給host2;
3>host2接收完後,將第一個package發送給host1,同時client想host2發送第二個package;
4>host1接收完第一個package後,發送給host3,同時接收host2發來的第二個package。
5>以此類推,如圖紅線實線所示,直到將block1發送完畢。
6>host2,host1,host3向NameNode,host2向Client發送通知,說“消息發送完了”。如圖粉紅顏色實線所示。
7>client收到host2發來的消息後,向namenode發送消息,說我寫完了。這樣就真完成了。如圖黃色粗實線
8>發送完block1後,再向host7,host8,host4發送block2,如圖藍色實線所示。
9>發送完block2後,host7,host8,host4向NameNode,host7向Client發送通知,如圖淺綠色實線所示。
10>client向NameNode發送消息,說我寫完了,如圖黃色粗實線。。。這樣就完畢了。
分析,通過寫過程,我們可以瞭解到:
①寫1T文件,我們需要3T的存儲,3T的網路流量貸款。
②在執行讀或寫的過程中,NameNode和DataNode通過HeartBeat進行保存通信,確定DataNode活著。如果發現DataNode死掉了,就將死掉的DataNode上的數據,放到其他節點去。讀取時,要讀其他節點去。
③掛掉一個節點,沒關係,還有其他節點可以備份;甚至,掛掉某一個機架,也沒關係;其他機架上,也有備份。
讀操作:
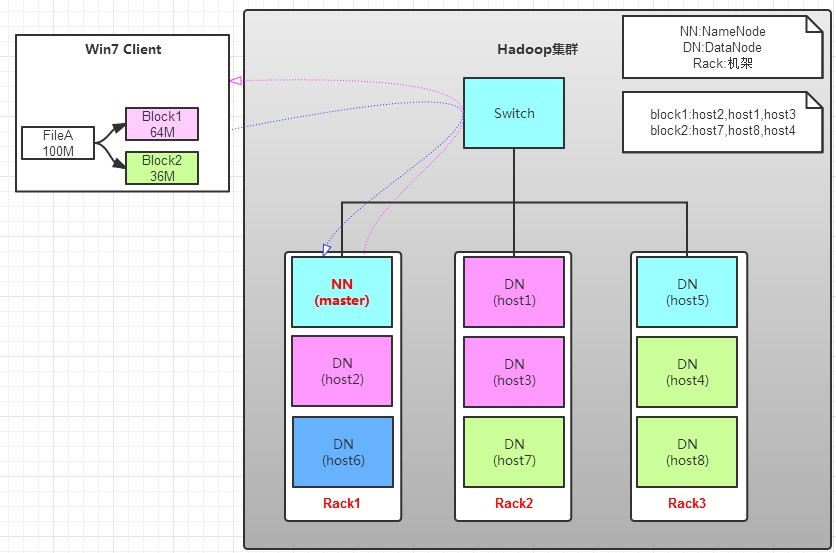
讀操作就簡單一些了,如圖所示,client要從datanode上,讀取FileA。而FileA由block1和block2組成。
那麼,讀操作流程為:
a. client向namenode發送讀請求。
b. namenode查看Metadata信息,返回fileA的block的位置。
block1:host2,host1,host3
block2:host7,host8,host4
c. block的位置是有先後順序的,先讀block1,再讀block2。而且block1去host2上讀取;然後block2,去host7上讀取;
上面例子中,client位於機架外,那麼如果client位於機架內某個DataNode上,例如,client是host6。那麼讀取的時候,遵循的規律是:
優選讀取本機架上的數據。
運算和存儲在同一個伺服器中,每一個伺服器都可以是本地伺服器
補充
元數據
元數據被定義為:描述數據的數據,對數據及信息資源的描述性信息。(類似於Linux中的i節點)
以 “blk_”開頭的文件就是 存儲數據的block。這裡的命名是有規律的,除了block文件外,還有後 綴是“meta”的文件 ,這是block的源數據文件,存放一些元數據信息。
數據複製
NameNode做出關於塊複製的所有決定。它周期性地從集群中的每個DataNode接收到一個心跳和一個阻塞報告。收到心跳意味著DataNode正常運行。Blockreport包含DataNode上所有塊的列表。
參考文獻:
http://www.cnblogs.com/laov/p/3434917.html
https://www.ibm.com/developerworks/cn/opensource/os-cn-hadoop-name-node/
http://www.cnblogs.com/linuxprobe/p/5594431.html


