
而這就是我們最初設定的願景。 加速高質量的交付,提升開發者的價值。我們技術團隊所做的每一個步驟、每一個過程都是疊加的、遞增的,日拱一卒,功不唐捐。 ...
鄭昀 創建於2017/6/29 最後更新於2017/6/30
關鍵詞:大數據,Spark,SparkSQL,HBase,HDFS,工作流,任務,Flow,Job,監控報警
提綱:
-
為什麼要大數據協作?
-
什麼是願景?
-
我們的DataCube
-
工作流什麼樣?
DataCube 是數據中心劉奎組推出的大數據協作平臺。從2016年3月29日我提出數據中心的大一統平臺建設目標至今,已經過去了整整一年零三個月時間。其實在很久以前,基於 Hadoop 集群的單一離線計算任務的上傳和管理工作,針對 Mesos 集群、HBase、HDFS 的監控報警,劉奎、王銀卡、崔建偉、陳少明、李少傑等人已經開發就緒。但真正要把數據倉庫計算方方面面搬進來,仍然等了一年時間,因為在底層,運維工程師們還構建了一個 DataFlash 集群,情況比較複雜。
DataCube,中文名字是魔盒。
當初,我說魔盒主要是圍繞著這四個核心概念構建一個體系:
-
資源
-
數據
-
流程
-
操作
什麼體系?
-
資源,能看見。
-
流程,能流轉。
-
數據,能共用。
-
操作,有記錄。
出了問題,隨時能通過圖形化界面排查。
不需要知道的,都隱藏在黑暗之中,被封裝為黑箱。
流程驅動數據,再驅動操作,形成閉環。
在2016年年初,我還對於運維自動化平臺 SimpleWay 也提出了我的願景:
在我的想象中,到了 2016年Q3 所見到的是:
線上配置同步到CMDB且可視化:我能在 SimpleWay 上看到任意一臺 Nginx、Redis、MySQL、ElasticSearch、ZooKeeper等的物理信息和配置;
資源的調撥和歷史可視化:我能在 SimpleWay 上看到任意一臺物理機什麼時候採購的、什麼時候上架的、在哪個機櫃、上面都有什麼應用、跑了什麼虛擬機、承載了什麼容器等等;
資源申請、運維操作的流程化:SA、Dev、QA 對資源的申請,或變更配置,工作流的流轉以及操作登記備案。
其實,對未來的這些願景大同小異,都體現了窩窩和雲縱的研發哲學:Don't make me think.
0x00,為什麼要大數據協作?
2016年的時候,數據中心雖然有自助式報表、即席查詢、資料庫變更訂閱中心、元數據管理、實時數據大屏等管理工具,即使2017年進一步演變出來了數屏、數據開放實驗室,但仍不成體系。
什麼叫不成體系?
數據,不能共用。
流程,不能流轉。
資源,無法看見。
操作,沒有記錄。
各個模塊各自為戰。最令我無法忍受的是,Hadoop 集群的離線計算和實時計算線下部署和線上發佈還以手工操作為主。
所以,我著重強調用“流程貫穿”提升研發的生產效率。
0x01,什麼是願景?
我曾經說過,在內部討論技術平臺和體系的時候,不要束縛自己的想象力,不要說因為我現在是這樣,所以我按此演進,只能是那樣。
NO!
一定要切換到朴素無華的腦力和心態(是的,我喜歡用朴素無華這個詞),進入使用者場景,想象怎麼才是用起來最舒服的狀態,或者你所見過的最應當如此、最順其自然的流程。
我說,我要如此。
可能,最後真的能如此。
舉一個例子:
研發中心的協作平臺,申請伺服器資源是這個樣子:
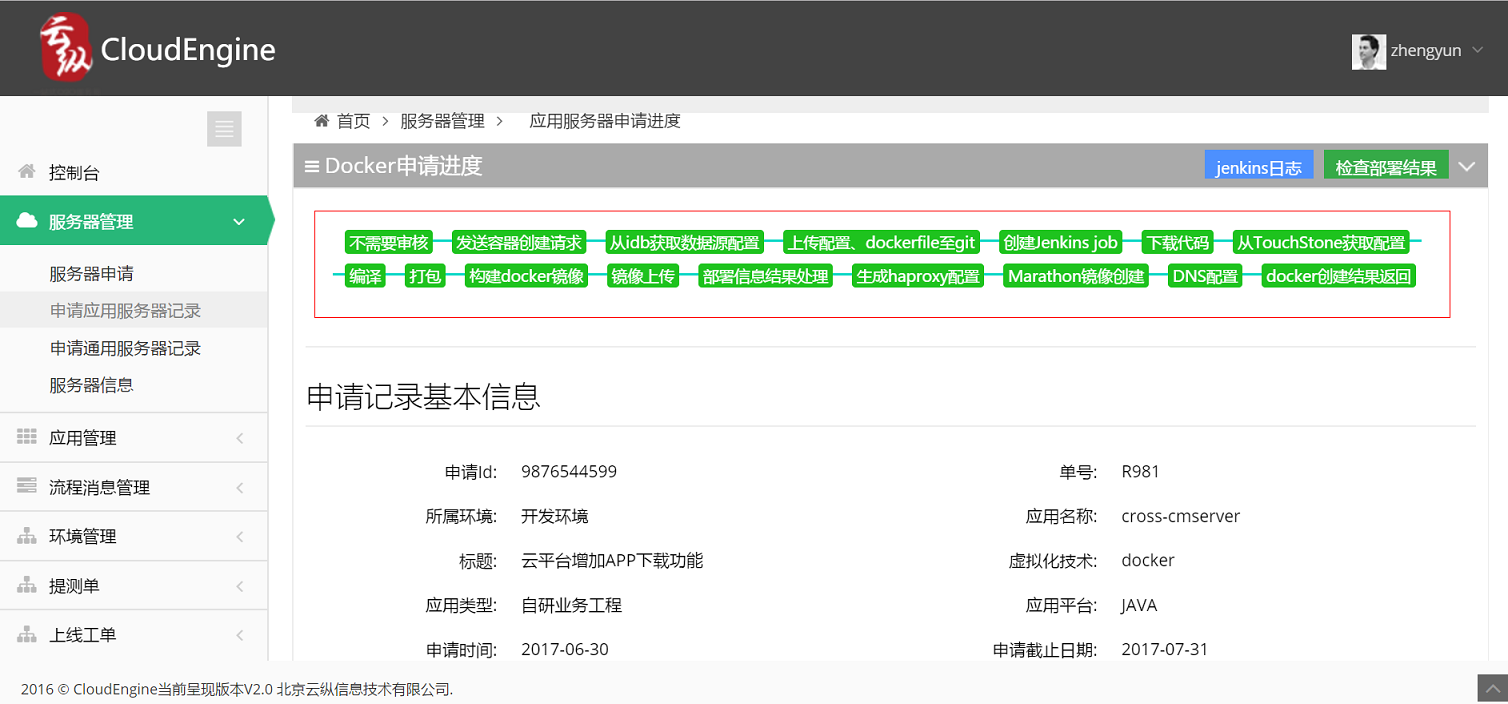
圖1 我們這樣申請測試資源
那時候我們期望如此。
後來夢想成真。
0x02,我們的DataCube
那麼現如今,魔盒能做到什麼呢?
先來一張靚照:
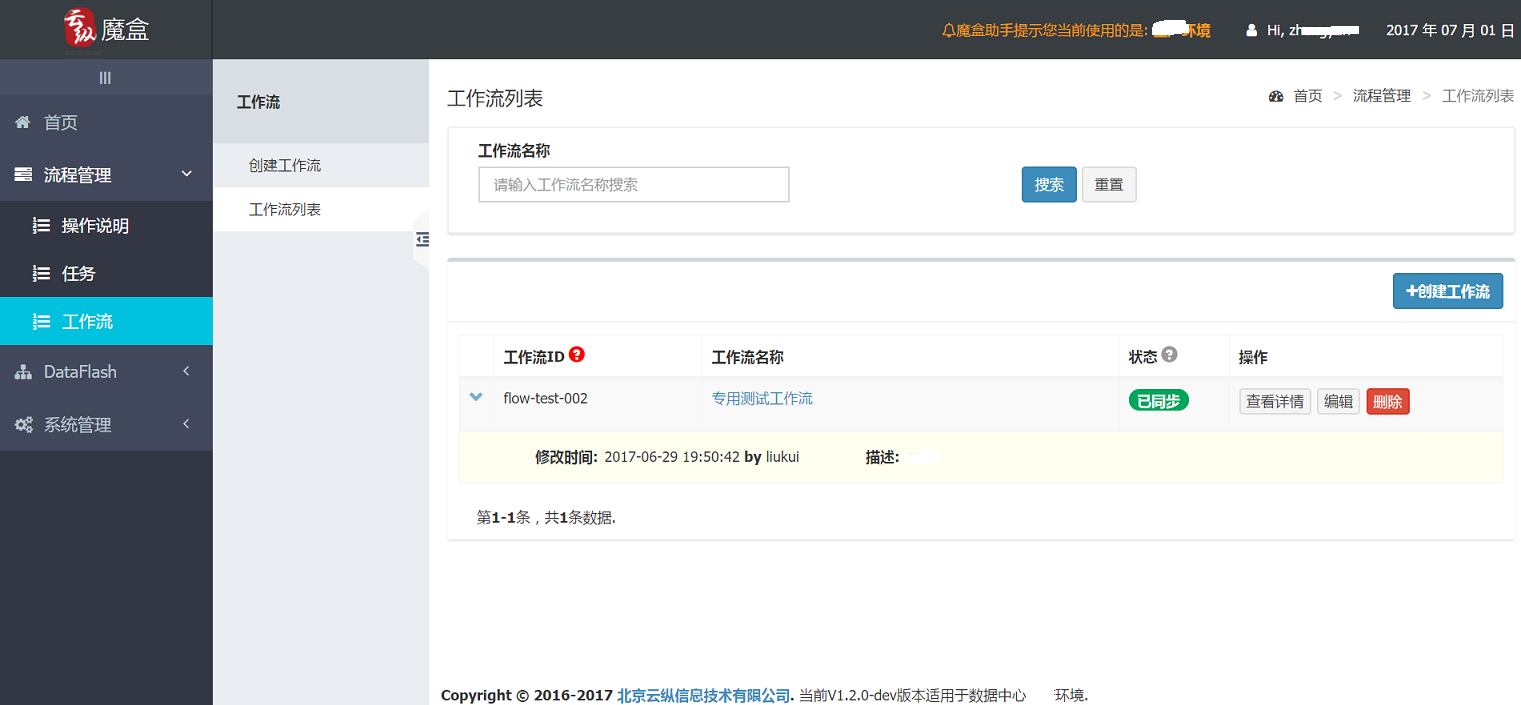
圖2-0 DataCube靚照
生產環境的它有這些功能:
-
DashBoard
-
流程管理:
-
任務:
-
任務列表
-
任務詳情
-
任務更新
-
任務刪除
-
創建任務(Spark任務,SparkSQL任務)
-
工作流:
-
工作流列表
-
工作流詳情
-
工作流編輯
-
工作流刪除
-
創建工作流
-
配置流程
-
展示流程拓撲圖
-
設定調度計劃
-
DataFlash:主要是監控報警
-
集群概覽
-
DataFlash實時監測
-
近一周報警走勢
-
今日報警分類圖
-
今日報警日誌列表
-
Mesos
-
概覽
-
實例列表
-
監控指標
-
報警規則(設置)
-
HBase
-
概覽
-
實例列表
-
監控指標
-
報警規則(設置)
-
HDFS
-
概覽
-
實例列表
-
監控指標
-
報警規則(設置)
-
系統管理:
-
公共資源配置
對 DataFlash 集群(Mesos/HBase/HDFS)的監控報警,暫且不提。大概齊長下麵這個樣子:
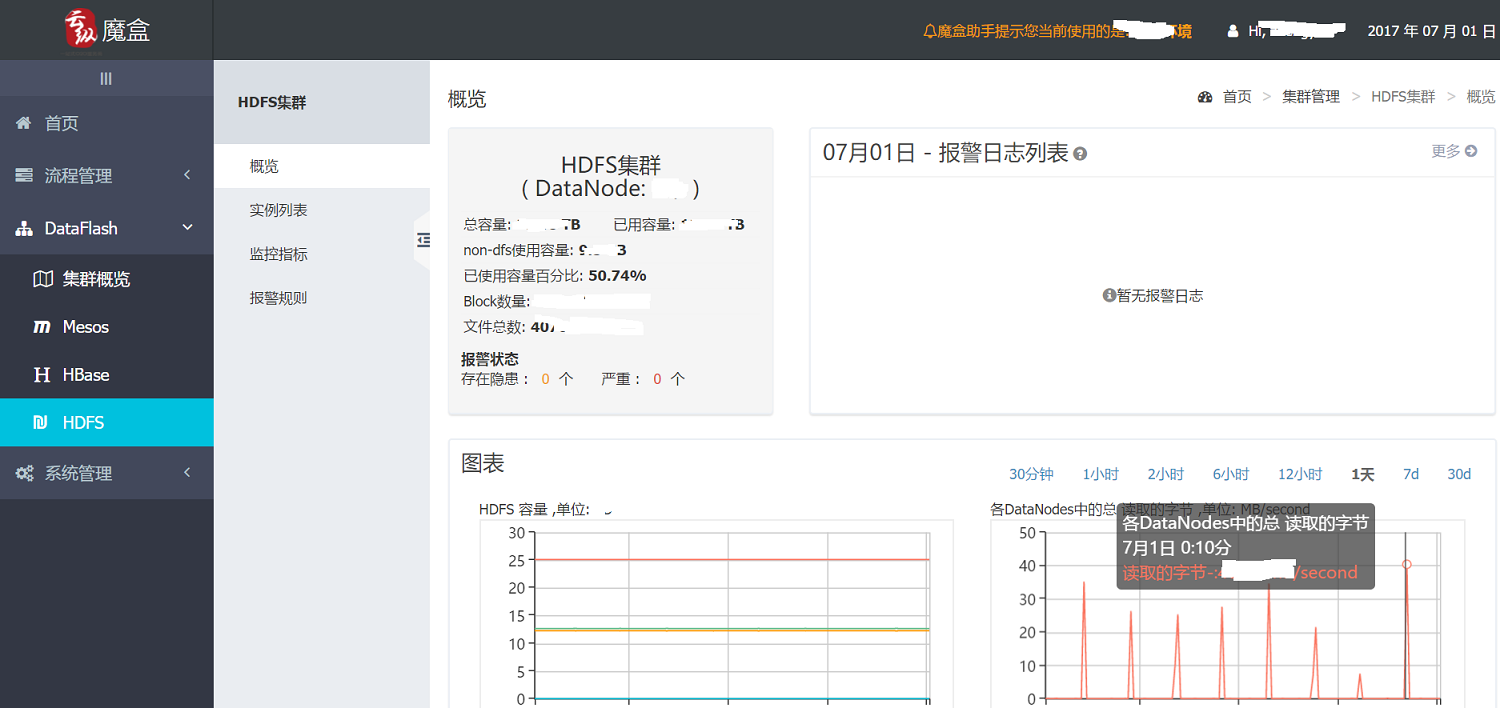
圖2-1 針對DataFlash集群的監控報警體系
我們講一下最新的工作流。
0x03,工作流什麼樣?
我作為一名數據倉庫工程師,首先創建一個離線計算任務:
圖3 創建任務
我可以創建一個 Spark任務 或 一個 SparkSQL 任務。
我不需要上傳 jar 包。
指定 git 倉庫地址即可,以及任務入口類名,還可以設置動態參數。
系統可以幫你構建和上傳,不需要你操心。
提交任務之後,可以進入任務詳情,親手構建和發佈上線。
圖4 任務詳情
這裡的“發佈上線”指的是,從測試環境推送到生產環境。當然了,生產環境需要對這次推送確認。
有了任務,還需要有工作流。
我們的工作流往往很複雜。
譬如這樣的:
圖5 工作流詳情頁上半部分
工作流中的任務可以依賴於其他任務或工作流。
我們在工作流身上設置時間調度規則。也可以選擇立即執行。
可以在工作流詳情頁的下半部分看到執行詳情:
圖6 工作流詳情頁下半部分
點擊上圖中的工作流名稱,可以看到本次執行的拓撲圖,下圖中的紅色代表執行失敗:
圖7 工作流執行詳情
還可以一路點擊進去看到底錯在哪裡了:
圖8 工作流執行-任務詳情
還是解決不了問題的話,就點擊查看日誌,不再贅述。
總之,我們可以通過魔盒的圖形化界面,解決85%~90%的大數據日常調度、管理和部署工作。
而這就是我們最初設定的願景。
加速高質量的交付,提升開發者的價值。我們技術團隊所做的每一個步驟、每一個過程都是疊加的、遞增的,日拱一卒,功不唐捐。
下一步需要做什麼?
實時計算還沒有納入其中。繼續努力。
-EOF-
關註我的訂閱號:

註:頭圖來自於bing.com

