
本節介紹正則表達式相關的Java API,討論在Java中利用正則表達式實現文本的切分、驗證、查找和替換,對於替換,我們演示一個簡單的模板引擎 ...
上節介紹了正則表達式的語法,本節介紹相關的Java API。
正則表達式相關的類位於包java.util.regex下,有兩個主要的類,一個是Pattern,另一個是Matcher。Pattern表示正則表達式對象,它與要處理的具體字元串無關。Matcher表示一個匹配,它將正則表達式應用於一個具體字元串,通過它對字元串進行處理。
字元串類String也是一個重要的類,我們在29節專門介紹過String,其中提到,它有一些方法,接受的參數不是普通的字元串,而是正則表達式。此外,正則表達式在Java中是需要先以字元串形式表示的。
下麵,我們先來介紹如何表示正則表達式,然後探討如何利用它實現一些常見的文本處理任務,包括切分、驗證、查找、和替換。
表示正則表達式
轉義符 '\'
正則表達式由元字元和普通字元組成,字元'\'是一個元字元,要在正則表達式中表示'\'本身,需要使用它轉義,即'\\'。
在Java中,沒有什麼特殊的語法能直接表示正則表達式,需要用字元串表示,而在字元串中,'\'也是一個元字元,為了在字元串中表示正則表達式的'\',就需要使用兩個'\',即'\\',而要匹配'\'本身,就需要四個'\',即'\\\\',比如說,如下表達式:
<(\w+)>(.*)</\1>
對應的字元串表示就是:
"<(\\w+)>(.*)</\\1>"
一個簡單規則是,正則表達式中的任何一個'\',在字元串中,需要替換為兩個'\'。
Pattern對象
字元串表示的正則表達式可以被編譯為一個Pattern對象,比如:
String regex = "<(\\w+)>(.*)</\\1>";
Pattern pattern = Pattern.compile(regex);
Pattern是正則表達式的面向對象表示,所謂編譯,簡單理解就是將字元串表示為了一個內部結構,這個結構是一個有窮自動機,關於有窮自動機的理論比較深入,我們就不探討了。
編譯有一定的成本,而且Pattern對象只與正則表達式有關,與要處理的具體文本無關,它可以安全地被多線程共用,所以,在使用同一個正則表達式處理多個文本時,應該儘量重用同一個Pattern對象,避免重覆編譯。
匹配模式
Pattern的compile方法接受一個額外參數,可以指定匹配模式:
public static Pattern compile(String regex, int flags)
上節,我們介紹過三種匹配模式:單行模式(點號模式)、多行模式和大小寫無關模式,它們對應的常量分別為:Pattern.DOTALL,Pattern.MULTILINE和Pattern.CASE_INSENSITIVE,多個模式可以一起使用,通過'|'連起來即可,如下所示:
Pattern.compile(regex, Pattern.CASE_INSENSITIVE | Pattern.DOTALL)
還有一個模式Pattern.LITERAL,在此模式下,正則表達式字元串中的元字元將失去特殊含義,被看做普通字元。Pattern有一個靜態方法:
public static String quote(String s)
quote()的目的是類似的,它將s中的字元都看作普通字元。我們在上節介紹過\Q和\E,\Q和\E之間的字元會被視為普通字元。quote()基本上就是在字元串s的前後加了\Q和\E,比如,如果s為"\\d{6}",則quote()的返回值就是"\\Q\\d{6}\\E"。
切分
簡單情況
文本處理的一個常見需求是根據分隔符切分字元串,比如在處理CSV文件時,按逗號分隔每個欄位,這個需求聽上去很容易滿足,因為String類有如下方法:
public String[] split(String regex)
比如:
String str = "abc,def,hello"; String[] fields = str.split(","); System.out.println("field num: "+fields.length); System.out.println(Arrays.toString(fields));
輸出為:
field num: 3
[abc, def, hello]
不過,有一些重要的細節,我們需要註意。
轉義元字元
split將參數regex看做正則表達式,而不是普通的字元,如果分隔符是元字元,比如. $ | ( ) [ { ^ ? * + \,就需要轉義,比如按點號'.'分隔,就需要寫為:
String[] fields = str.split("\\.");
如果分隔符是用戶指定的,程式事先不知道,可以通過Pattern.quote()將其看做普通字元串。
將多個字元用作分隔符
既然是正則表達式,分隔符就不一定是一個字元,比如,可以將一個或多個空白字元或點號作為分隔符,如下所示:
String str = "abc def hello.\n world";
String[] fields = str.split("[\\s.]+");
fields內容為:
[abc, def, hello, world]
空白字元串
需要說明的是,尾部的空白字元串不會包含在返回的結果數組中,但頭部和中間的空白字元串會被包含在內,比如:
String str = ",abc,,def,,"; String[] fields = str.split(","); System.out.println("field num: "+fields.length); System.out.println(Arrays.toString(fields));
輸出為:
field num: 4
[, abc, , def]
找不到分隔符
如果字元串中找不到匹配regex的分隔符,返回數組長度為1,元素為原字元串。
切分數目限制
split方法接受一個額外的參數limit,用於限定切分的數目:
public String[] split(String regex, int limit)
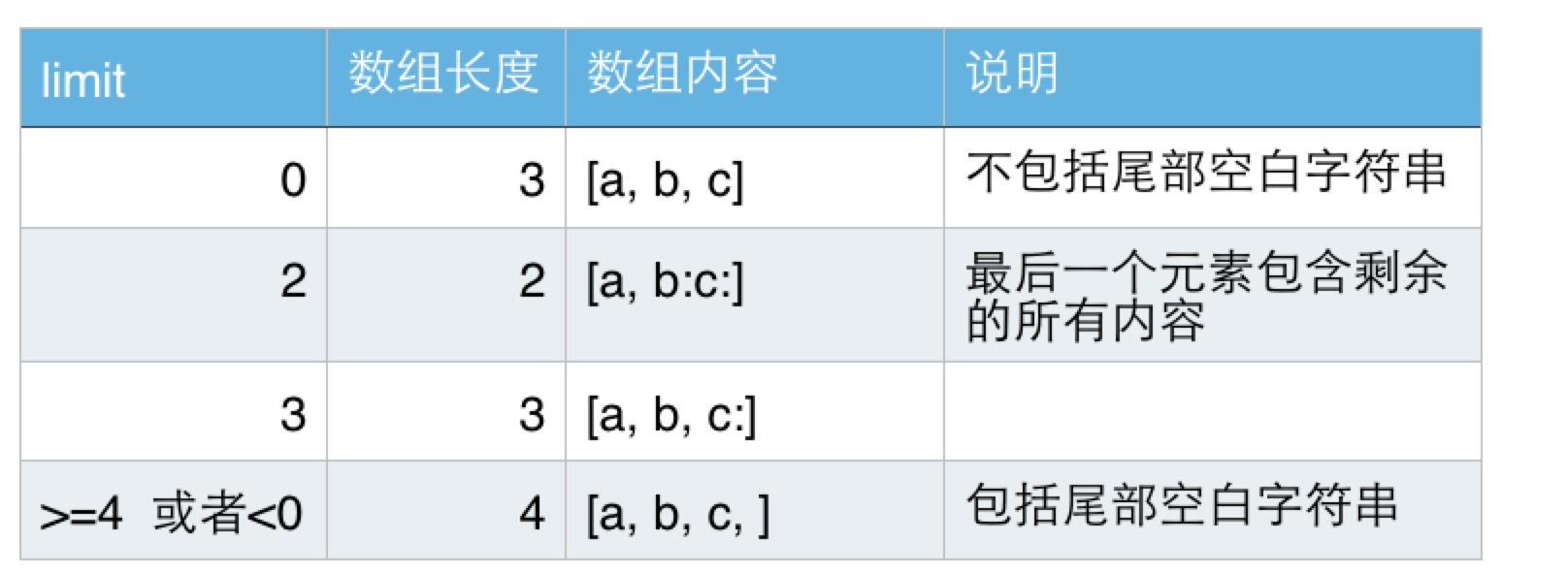
不帶limit參數的split,其limit相當於0。關於limit的含義,我們通過一個例子說明下,比如字元串是"a:b:c:",分隔符是":",在limit為不同值的情況下,其返回數組如下表所示:
Pattern的split方法
Pattern也有兩個split方法,與String方法的定義類似:
public String[] split(CharSequence input) public String[] split(CharSequence input, int limit)
與String方法的區別是:
- Pattern接受的參數是CharSequence,更為通用,我們知道String, StringBuilder, StringBuffer, CharBuffer等都實現了該介面;
- 如果regex長度大於1或包含元字元,String的split方法會先將regex編譯為Pattern對象,再調用Pattern的split方法,這時,為避免重覆編譯,應該優先採用Pattern的方法;
- 如果regex就是一個字元且不是元字元,String的split方法會採用更為簡單高效的實現,所以,這時,應該優先採用String的split方法。
驗證
驗證就是檢驗輸入文本是否完整匹配預定義的正則表達式,經常用於檢驗用戶的輸入是否合法。
String有如下方法:
public boolean matches(String regex)
比如:
String regex = "\\d{8}";
String str = "12345678";
System.out.println(str.matches(regex));
檢查輸入是否是8位數字,輸出為true。
String的matches實際調用的是Pattern的如下方法:
public static boolean matches(String regex, CharSequence input)
這是一個靜態方法,它的代碼為:
public static boolean matches(String regex, CharSequence input) { Pattern p = Pattern.compile(regex); Matcher m = p.matcher(input); return m.matches(); }
就是先調用compile編譯regex為Pattern對象,再調用Pattern的matcher方法生成一個匹配對象Matcher,Matcher的matches()返回是否完整匹配。
查找
查找就是在文本中尋找匹配正則表達式的子字元串,看個例子:
public static void find(){ String regex = "\\d{4}-\\d{2}-\\d{2}"; Pattern pattern = Pattern.compile(regex); String str = "today is 2017-06-02, yesterday is 2017-06-01"; Matcher matcher = pattern.matcher(str); while(matcher.find()){ System.out.println("find "+matcher.group() +" position: "+matcher.start()+"-"+matcher.end()); } }
代碼尋找所有類似"2017-06-02"這種格式的日期,輸出為:
find 2017-06-02 position: 9-19
find 2017-06-01 position: 34-44
Matcher的內部記錄有一個位置,起始為0,find()方法從這個位置查找匹配正則表達式的子字元串,找到後,返回true,並更新這個內部位置,匹配到的子字元串信息可以通過如下方法獲取:
//匹配到的完整子字元串 public String group() //子字元串在整個字元串中的起始位置 public int start() //子字元串在整個字元串中的結束位置加1 public int end()
group()其實調用的是group(0),表示獲取匹配的第0個分組的內容。我們在上節介紹過捕獲分組的概念,分組0是一個特殊分組,表示匹配的整個子字元串。除了分組0,Matcher還有如下方法,獲取分組的更多信息:
//分組個數 public int groupCount() //分組編號為group的內容 public String group(int group) //分組命名為name的內容 public String group(String name) //分組編號為group的起始位置 public int start(int group) //分組編號為group的結束位置加1 public int end(int group)
比如:
public static void findGroup() { String regex = "(\\d{4})-(\\d{2})-(\\d{2})"; Pattern pattern = Pattern.compile(regex); String str = "today is 2017-06-02, yesterday is 2017-06-01"; Matcher matcher = pattern.matcher(str); while (matcher.find()) { System.out.println("year:" + matcher.group(1) + ",month:" + matcher.group(2) + ",day:" + matcher.group(3)); } }
輸出為:
year:2017,month:06,day:02
year:2017,month:06,day:01
替換
replaceAll和replaceFirst
查找到子字元串後,一個常見的後續操作是替換。String有多個替換方法:
public String replace(char oldChar, char newChar) public String replace(CharSequence target, CharSequence replacement) public String replaceAll(String regex, String replacement) public String replaceFirst(String regex, String replacement)
第一個replace方法操作的是單個字元,第二個是CharSequence,它們都是將參數看做普通字元。而replaceAll和replaceFirst則將參數regex看做正則表達式,它們的區別是,replaceAll替換所有找到的子字元串,而replaceFirst則只替換第一個找到的,看個簡單的例子,將字元串中的多個連續空白字元替換為一個:
String regex = "\\s+"; String str = "hello world good"; System.out.println(str.replaceAll(regex, " "));
輸出為:
hello world good
在replaceAll和replaceFirst中,參數replacement也不是被看做普通的字元串,可以使用美元符號加數字的形式,比如$1,引用捕獲分組,我們看個例子:
String regex = "(\\d{4})-(\\d{2})-(\\d{2})";
String str = "today is 2017-06-02.";
System.out.println(str.replaceFirst(regex, "$1/$2/$3"));
輸出為:
today is 2017/06/02.
這個例子將找到的日期字元串的格式進行了轉換。所以,字元'$'在replacement中是元字元,如果需要替換為字元'$'本身,需要使用轉義,看個例子:
String regex = "#"; String str = "#this is a test"; System.out.println(str.replaceAll(regex, "\\$"));
如果替換字元串是用戶提供的,為避免元字元的的干擾,可以使用Matcher的如下靜態方法將其視為普通字元串:
public static String quoteReplacement(String s)
String的replaceAll和replaceFirst調用的其實是Pattern和Matcher中的方法,比如,replaceAll的代碼為:
public String replaceAll(String regex, String replacement) { return Pattern.compile(regex).matcher(this).replaceAll(replacement); }
邊查找邊替換
replaceAll和replaceFirst都定義在Matcher中,除了一次性的替換操作外,Matcher還定義了邊查找、邊替換的方法:
public Matcher appendReplacement(StringBuffer sb, String replacement) public StringBuffer appendTail(StringBuffer sb)
這兩個方法用於和find()一起使用,我們先看個例子:
public static void replaceCat() { Pattern p = Pattern.compile("cat"); Matcher m = p.matcher("one cat, two cat, three cat"); StringBuffer sb = new StringBuffer(); int foundNum = 0; while (m.find()) { m.appendReplacement(sb, "dog"); foundNum++; if (foundNum == 2) { break; } } m.appendTail(sb); System.out.println(sb.toString()); }
在這個例子中,我們將前兩個"cat"替換為了"dog",其他"cat"不變,輸出為:
one dog, two dog, three cat
StringBuffer類型的變數sb存放最終的替換結果,Matcher內部除了有一個查找位置,還有一個append位置,初始為0,當找到一個匹配的子字元串後,appendReplacement()做了三件事情:
- 將append位置到當前匹配之前的子字元串append到sb中,在第一次操作中,為"one ",第二次為", two ";
- 將替換字元串append到sb中;
- 更新append位置為當前匹配之後的位置。
appendTail將append位置之後所有的字元append到sb中。
模板引擎
利用Matcher的這幾個方法,我們可以實現一個簡單的模板引擎,模板是一個字元串,中間有一些變數,以{name}表示,如下例所示:
String template = "Hi {name}, your code is {code}.";
這裡,模板字元串中有兩個變數,一個是name,另一個是code。變數的實際值通過Map提供,變數名稱對應Map中的鍵,模板引擎的任務就是接受模板和Map作為參數,返回替換變數後的字元串,示例實現為:
private static Pattern templatePattern = Pattern.compile("\\{(\\w+)\\}"); public static String templateEngine(String template, Map<String, Object> params) { StringBuffer sb = new StringBuffer(); Matcher matcher = templatePattern.matcher(template); while (matcher.find()) { String key = matcher.group(1); Object value = params.get(key); matcher.appendReplacement(sb, value != null ? Matcher.quoteReplacement(value.toString()) : ""); } matcher.appendTail(sb); return sb.toString(); }
代碼尋找所有的模板變數,正則表達式為:
\{(\w+)\}
'{'是元字元,所以要轉義,\w+表示變數名,為便於引用,加了括弧,可以通過分組1引用變數名。
使用該模板引擎的示例代碼為:
public static void templateDemo() { String template = "Hi {name}, your code is {code}."; Map<String, Object> params = new HashMap<String, Object>(); params.put("name", "老馬"); params.put("code", 6789); System.out.println(templateEngine(template, params)); }
輸出為:
Hi 老馬, your code is 6789.
小結
本節介紹了正則表達式相關的主要Java API,討論瞭如何在Java中表示正則表達式,如何利用它實現文本的切分、驗證、查找和替換,對於替換,我們演示了一個簡單的模板引擎。
下一節,我們繼續探討正則表達式,討論和分析一些常見的正則表達式。
(與其他章節一樣,本節所有代碼位於 https://github.com/swiftma/program-logic,位於包shuo.laoma.regex.c89下)
----------------
未完待續,查看最新文章,敬請關註微信公眾號“老馬說編程”(掃描下方二維碼),從入門到高級,深入淺出,老馬和你一起探索Java編程及電腦技術的本質。用心原創,保留所有版權。



