
本文出處:http://www.cnblogs.com/wy123/p/6908377.html NTILE函數可以按照指定的排序規則,對數據按照指定的組數(M個對象,按照某種排序分N個組)進行分組,可以展現出某一條數據被分配在哪個組中. 不僅可以單單利用這個特性,還可以藉助該特實現更加有意思的功能 ...
本文出處:http://www.cnblogs.com/wy123/p/6908377.html
NTILE函數可以按照指定的排序規則,對數據按照指定的組數(M個對象,按照某種排序分N個組)進行分組,可以展現出某一條數據被分配在哪個組中.
不僅可以單單利用這個特性,還可以藉助該特實現更加有意思的功能.
NTILE的基本使用
NTILE的作用是對數據進行整體上的分組,比如有60個學生,按照成績分成“上中下”三個級別,可以看出那些人位於哪個級別,用NTILE函數就可以實現。
比如這裡的簡單的示例,有六個學生,按照成績,分成三組,可以看到,每個人位於哪一組中(或者說哪個人位於哪個層次)
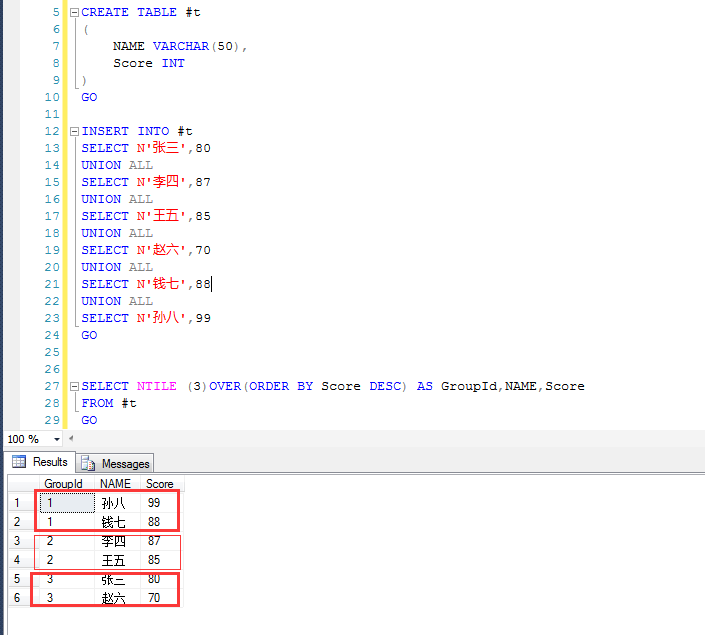
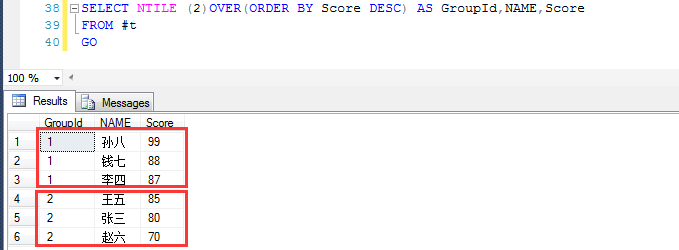
當然也可以分成兩組,分組和排序方式由NTILE (N)OVER(ORDER BY *** ASC | DESC) 決定
在NTILE的分組功能上擴展
當然這個應用還可以擴展,藉助其擴展功能,可以完成很多個性化的需求。
最近遇到一個需求,要處理一批歷史數據,目的是根據其Id,經過一系列的邏輯運算(存儲過程實現),計算生成這個Id的某些屬性,
正常情況下是迴圈表中的每一行數據,分別傳入存儲過程進行處理。
/*
DECLARE @id INT = 0
DECLARE @achived bit = 1
while @achived>0
begin
select top 1 @id = id from business_table order by id
insert into deal_result
exec deal_procrdure @id
delete from t where business_table = @id
if exists (select 1 from t)
set @achived = 1
else
set @achived = 0
end
*/
但是考慮到business_table的數據量太大,單個Session運算起來可能要花費太久的時間,
因此要考慮使用多個Session,每個Session分別計算一部分數據,這樣就可以加快數據的生成效率。
比如有1000W行數據,使用10個Session,每個Session計算100W行,這樣比一個Session計算1000W行數據,理論上要快10倍
那麼這裡就涉及到一個分組的問題,鑒於數據的特點,其Id是唯一的但不連續的,
比如要分成10組,如何通過Id的範圍,確保每組的數據量基本上相同?
一開始是採用比較笨的方法,利用top,比如前100W行數據,可以這樣
select max(id) from
(
select top 100W from t
)t
通過這樣,如果最大的id為Id1,那麼前100W行的數據範圍為0~Id1。
對於第二個100W行的數據,可以計算前200W行的max(id)
select max(id) from
(
select top 200W from t
)t
如果最大的id為Id2,那麼第二個100W行的數據範圍為Id1~Id2。
然後依次類推,是有點笨……
類似需求可以通過上面提到的NTILE分析函數實現
先上個實例代碼,模擬上文提到的Business_table Id唯一但是不連續的情況
DECLARE @i INT = 0 WHILE @i<200000 BEGIN INSERT INTO TestNtile VALUES (@i,NEWID()) set @i=@i+1 END GO --隨機刪除部分數據,模擬Id不是連續的 ;WITH del AS ( select top 100 * from TestNtile order by NEWID() ) DELETE FROM del GO --通過NTILE分成十個組,取每個組的最大值 SELECT GroupId,MAX(Id) AS Id FROM ( select NTILE (10)over(order by Id) as GroupId,Id from TestNtile )t GROUP BY GroupId GO
原理正如備註中的寫的,利用NTILE函數,對數據整體上分成10組,取每個組的最大值,就可以確定每個組的Id的區間範圍了。
參考下圖,將測試數據分成10組,分別取得每個組的最大Id值,就可以確定每個組的Id的範圍了。
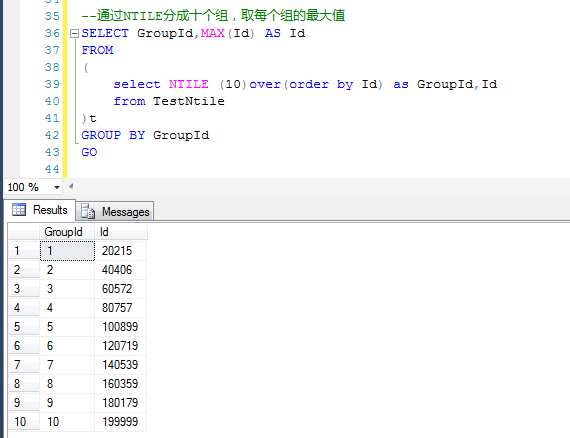
這樣就很容易確定,第一組的Id的範圍是0~20215,第二組的範圍是20216~40406,第三組的範圍是40406~60572……
計算出來範圍之後,可以通過啟動多個Session來迴圈計算,或者是交給多線程,讓每個線程處理某個範圍內的Id
很基礎的問題,就不總結了。

