
最近寫完mysql flashback,突然發現還有有這種使用場景:有些情況下,可能會統計在某個時間段內,MySQL修改了多少數據量?發生了多少事務?主要是哪些表格發生變動?變動的數量是怎麼樣的? 但是卻不需要行記錄的修改內容,只需要瞭解 行數據的 變動情況。故也整理了下。 昨晚寫的腳本,因為個人p ...
最近寫完mysql flashback,突然發現還有有這種使用場景:有些情況下,可能會統計在某個時間段內,MySQL修改了多少數據量?發生了多少事務?主要是哪些表格發生變動?變動的數量是怎麼樣的? 但是卻不需要行記錄的修改內容,只需要瞭解 行數據的 變動情況。故也整理了下。 昨晚寫的腳本,因為個人python能力有限,本來想這不發這文,後來想想,沒準會有哪位園友給出優化建議。
如果轉載,請註明博文來源: www.cnblogs.com/xinysu/ ,版權歸 博客園 蘇家小蘿蔔 所有。望各位支持!
1 實現內容
有些情況下,可能會統計在某個時間段內,MySQL修改了多少數據量?發生了多少事務?主要是哪些表格發生變動?變動的數量是怎麼樣的? 但是卻不需要行記錄的修改內容,只需要瞭解 行數據的 變動情況。 這些情況部分可以通過監控來大致瞭解,但是也可以基於binlog來全盤分析,binlog的格式是row模式。 在寫flashback的時候,順帶把這個也寫了個腳步,使用python編寫,都差不多原理,只是這個簡單些,介於個人python弱的不行,性能可能還有很大的提升空間,也希望園友能協助優化下。 先貼python腳步的分析結果圖如下,分為4個部分:事務耗時情況、事務影響行數情況、DML行數情況以及操作最頻繁表格情況。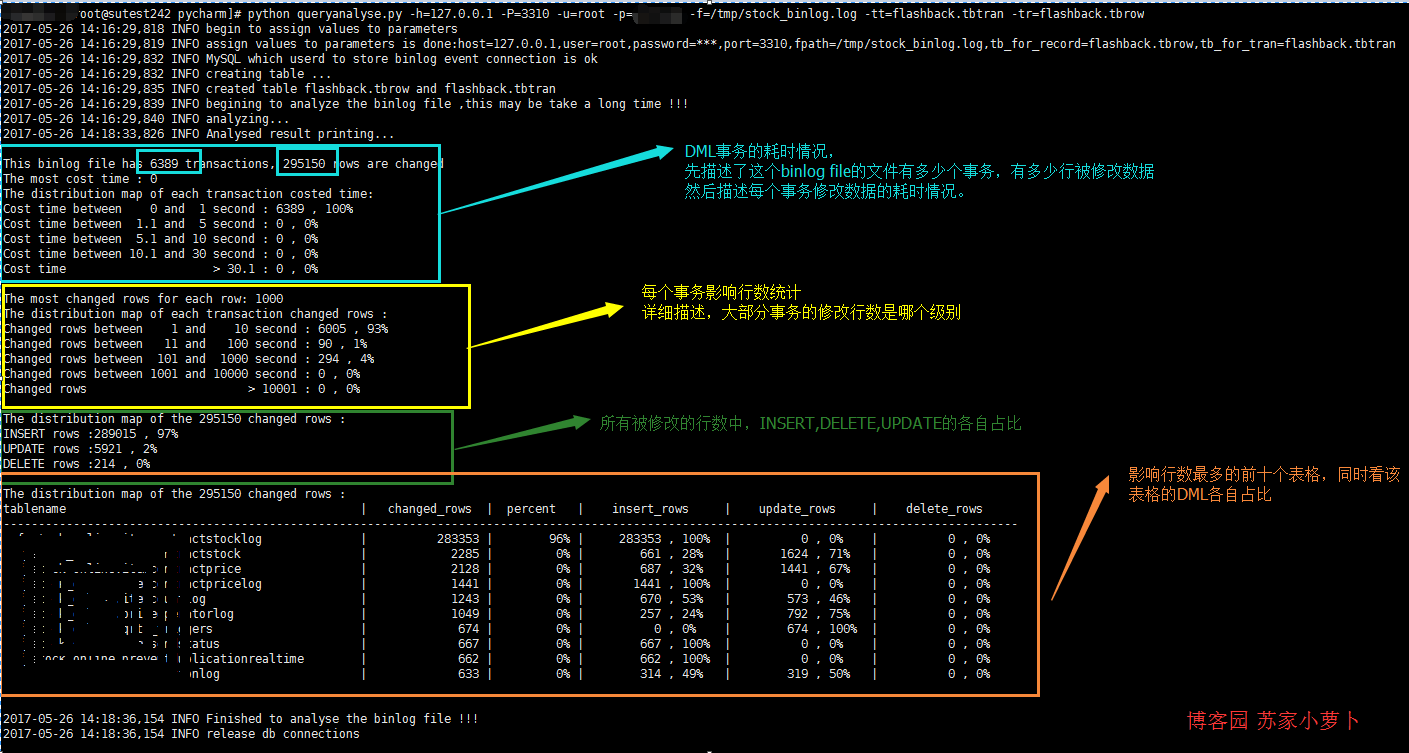
2 腳本簡單描述
腳本依賴的模塊中,pymysql需要自行安裝。 創建類queryanalyse,其中有5個函數定義:_get_db、create_tab、rowrecord、binlogdesc跟closeconn。2.1 _get_db
該函數用來解析輸入參數值,參數值一共有7個,都是必須填寫的。分別為host,user,password,port,table name for transaction,table name for records,對應的簡寫如下: ALL options need to assign: -h : host, the database host,which database will store the results after analysis -u : user, the db user -p : password, the db user's password -P : port, the db port -f : file path, the binlog file -tr : table name for record , the table name to store the row record -tt : table name for transaction, the table name to store transactions 比如,執行腳本:python queryanalyse.py -h=127.0.0.1 -P=3310 -u=root -p=password -f=/tmp/stock_binlog.log -tt=flashback.tbtran -tr=flashback.tbrow,該函數負責處理各個選項的參數值情況,並存儲。2.2 create_tab
創建兩個表格,分別用來存儲 binlog file文件的分析結果。一個用來存儲事務的執行開始時間跟結束時間,由選項 -tt來賦值表名;一個是用來存儲每一行記錄的修改情況,由選項 -tr來賦值表名。 事務表記錄內容:事務的開始時間及事務的結束時間。 行記錄表的內容:庫名,表名,DML類型以及事務對應事務表的編號。root@localhost:mysql3310.sock 14:42:29 [flashback]>show create table tbrow \G *************************** 1. row *************************** Table: tbrow Create Table: CREATE TABLE `tbrow` ( `auto_id` int(10) unsigned NOT NULL AUTO_INCREMENT, `sqltype` int(11) NOT NULL COMMENT '1 is insert,2 is update,3 is delete', `tran_num` int(11) NOT NULL COMMENT 'the transaction number', `dbname` varchar(50) NOT NULL, `tbname` varchar(50) NOT NULL, PRIMARY KEY (`auto_id`), KEY `sqltype` (`sqltype`), KEY `dbname` (`dbname`), KEY `tbname` (`tbname`) ) ENGINE=InnoDB AUTO_INCREMENT=295151 DEFAULT CHARSET=utf8 1 row in set (0.00 sec) root@localhost:mysql3310.sock 14:42:31 [flashback]>SHOW CREATE TABLE TBTRAN \G *************************** 1. row *************************** Table: TBTRAN Create Table: CREATE TABLE `tbtran` ( `auto_id` int(10) unsigned NOT NULL AUTO_INCREMENT, `begin_time` datetime NOT NULL, `end_time` datetime NOT NULL, PRIMARY KEY (`auto_id`) ) ENGINE=InnoDB AUTO_INCREMENT=6390 DEFAULT CHARSET=utf8 1 row in set (0.00 sec)
2.3 rowrecord
重點函數,分析binlog文件內容。這裡有幾個規律:- 每個事務的結束點,是以 'Xid = ' 來查找
- 事務的開始時間,是事務內的第一個 'Table_map' 行裡邊的時間
- 事務的結束時間,是以 'Xid = '所在行的 裡邊的時間
- 每個行數據是屬於哪個表格,是以 'Table_map'來查找
- DML的類型是按照 行記錄開頭的情況是否為:'### INSERT INTO' 、'### UPDATE' 、'### DELETE FROM'
- 註意,單個事務可以包含多個表格多種DML多行數據修改的情況。
2.4 binlogdesc
描述分析結果,簡單4個SQL分析。- 分析修改行數據的 事務耗時情況
- 分析修改行數據的 事務影響行數情況
- 分析DML分佈情況
- 分析 最多DML操作的表格 ,取前十個分析
2.5 closeconn
關閉資料庫連接。3 使用說明
首先,確保python安裝了pymysql模塊,把python腳本拷貝到文件 queryanalyse.py。 然後,把要分析的binlog文件先用 mysqlbinlog 指令分析存儲,具體binlog的文件說明,可以查看之前的博文:關於binary log那些事——認真碼了好長一篇。mysqlbinlog的指令使用方法,可以詳細查看文檔:https://dev.mysql.com/doc/refman/5.7/en/mysqlbinlog.html 。 比較常用通過指定開始時間跟結束時間來分析 binlog文件。 mysqlbinlog --start-datetime='2017-04-23 00:00:03' --stop-datetime='2017-04-23 00:30:00' --base64-output=decode-rows -v /data/mysql/logs/mysql-bin.007335 > /tmp/binlog_test.log 分析後,可以把這個 binlog_test.log文件拷貝到其他空閑伺服器執行分析,只需要有個空閑的DB來存儲分析記錄即可。 假設這個時候,拷貝 binlog_test.log到測試伺服器上,測試伺服器上的資料庫可以用來存儲分析內容,則可以執行python腳本了,註意要進入到python腳本的目錄中,或者指定python腳本路徑。 python queryanalyse.py -h=127.0.0.1 -P=3310 -u=root -p=password -f= /tmp/binlog_test.log -tt=flashback.tbtran -tr=flashback.tbrow 沒了,就等待輸出吧。 性能是硬傷,在虛擬機上測試,大概500M的binlog文件需要分析2-3min,有待提高!4 python腳本
1 import pymysql 2 from pymysql.cursors import DictCursor 3 import re 4 import os 5 import sys 6 import datetime 7 import time 8 import logging 9 import importlib 10 importlib.reload(logging) 11 logging.basicConfig(level=logging.DEBUG,format='%(asctime)s %(levelname)s %(message)s ') 12 13 14 usage=''' usage: python [script's path] [option] 15 ALL options need to assign: 16 17 -h : host, the database host,which database will store the results after analysis 18 -u : user, the db user 19 -p : password, the db user's password 20 -P : port, the db port 21 -f : file path, the binlog file 22 -tr : table name for record , the table name to store the row record 23 -tt : table name for transaction, the table name to store transactions 24 Example: python queryanalyse.py -h=127.0.0.1 -P=3310 -u=root -p=password -f=/tmp/stock_binlog.log -tt=flashback.tbtran -tr=flashback.tbrow 25 26 ''' 27 28 class queryanalyse: 29 def __init__(self): 30 #初始化 31 self.host='' 32 self.user='' 33 self.password='' 34 self.port='3306' 35 self.fpath='' 36 self.tbrow='' 37 self.tbtran='' 38 39 self._get_db() 40 logging.info('assign values to parameters is done:host={},user={},password=***,port={},fpath={},tb_for_record={},tb_for_tran={}'.format(self.host,self.user,self.port,self.fpath,self.tbrow,self.tbtran)) 41 42 self.mysqlconn = pymysql.connect(host=self.host, user=self.user, password=self.password, port=self.port,charset='utf8') 43 self.cur = self.mysqlconn.cursor(cursor=DictCursor) 44 logging.info('MySQL which userd to store binlog event connection is ok') 45 46 self.begin_time='' 47 self.end_time='' 48 self.db_name='' 49 self.tb_name='' 50 51 def _get_db(self): 52 #解析用戶輸入的選項參數值,這裡對password的處理是明文輸入,可以自行處理成是input格式, 53 #由於可以拷貝binlog文件到非線上環境分析,所以password這塊,沒有特殊處理 54 logging.info('begin to assign values to parameters') 55 if len(sys.argv) == 1: 56 print(usage) 57 sys.exit(1) 58 elif sys.argv[1] == '--help': 59 print(usage) 60 sys.exit() 61 elif len(sys.argv) > 2: 62 for i in sys.argv[1:]: 63 _argv = i.split('=') 64 if _argv[0] == '-h': 65 self.host = _argv[1] 66 elif _argv[0] == '-u': 67 self.user = _argv[1] 68 elif _argv[0] == '-P': 69 self.port = int(_argv[1]) 70 elif _argv[0] == '-f': 71 self.fpath = _argv[1] 72 elif _argv[0] == '-tr': 73 self.tbrow = _argv[1] 74 elif _argv[0] == '-tt': 75 self.tbtran = _argv[1] 76 elif _argv[0] == '-p': 77 self.password = _argv[1] 78 else: 79 print(usage) 80 81 def create_tab(self): 82 #創建兩個表格:一個用戶存儲事務情況,一個用戶存儲每一行數據修改的情況 83 #註意,一個事務可以存儲多行數據修改的情況 84 logging.info('creating table ...') 85 create_tb_sql ='''CREATE TABLE IF NOT EXISTS {} ( 86 `auto_id` int(10) unsigned NOT NULL AUTO_INCREMENT, 87 `begin_time` datetime NOT NULL, 88 `end_time` datetime NOT NULL, 89 PRIMARY KEY (`auto_id`) 90 ) ENGINE=InnoDB DEFAULT CHARSET=utf8; 91 CREATE TABLE IF NOT EXISTS {} ( 92 `auto_id` int(10) unsigned NOT NULL AUTO_INCREMENT, 93 `sqltype` int(11) NOT NULL COMMENT '1 is insert,2 is update,3 is delete', 94 `tran_num` int(11) NOT NULL COMMENT 'the transaction number', 95 `dbname` varchar(50) NOT NULL, 96 `tbname` varchar(50) NOT NULL, 97 PRIMARY KEY (`auto_id`), 98 KEY `sqltype` (`sqltype`), 99 KEY `dbname` (`dbname`), 100 KEY `tbname` (`tbname`) 101 ) ENGINE=InnoDB DEFAULT CHARSET=utf8; 102 truncate table {}; 103 truncate table {}; 104 '''.format(self.tbtran,self.tbrow,self.tbtran,self.tbrow) 105 106 self.cur.execute(create_tb_sql) 107 logging.info('created table {} and {}'.format(self.tbrow,self.tbtran)) 108 109 def rowrecord(self): 110 #處理每一行binlog 111 #事務的結束採用 'Xid =' 來劃分 112 #分析結果,按照一個事務為單位存儲提交一次到db 113 try: 114 tran_num=1 #事務數 115 record_sql='' #行記錄的insert sql 116 tran_sql='' #事務的insert sql 117 118 self.create_tab() 119 120 with open(self.fpath,'r') as binlog_file: 121 logging.info('begining to analyze the binlog file ,this may be take a long time !!!') 122 logging.info('analyzing...') 123 124 for bline in binlog_file: 125 126 if bline.find('Table_map:') != -1: 127 l = bline.index('server') 128 n = bline.index('Table_map') 129 begin_time = bline[:l:].rstrip(' ').replace('#', '20') 130 131 if record_sql=='': 132 self.begin_time = begin_time[0:4] + '-' + begin_time[4:6] + '-' + begin_time[6:] 133 134 self.db_name = bline[n::].split(' ')[1].replace('`', '').split('.')[0] 135 self.tb_name = bline[n::].split(' ')[1].replace('`', '').split('.')[1] 136 bline='' 137 138 elif bline.startswith('### INSERT INTO'): 139 record_sql=record_sql+"insert into {}(sqltype,tran_num,dbname,tbname) VALUES (1,{},'{}','{}');".format(self.tbrow,tran_num,self.db_name,self.tb_name) 140 141 elif bline.startswith('### UPDATE'): 142 record_sql=record_sql+"insert into {}(sqltype,tran_num,dbname,tbname) VALUES (2,{},'{}','{}');".format(self.tbrow,tran_num,self.db_name,self.tb_name) 143 144 elif bline.startswith('### DELETE FROM'): 145 record_sql=record_sql+"insert into {}(sqltype,tran_num,dbname,tbname) VALUES (3,{},'{}','{}');".format(self.tbrow,tran_num,self.db_name,self.tb_name) 146 147 elif bline.find('Xid =') != -1: 148 149 l = bline.index('server') 150 end_time = bline[:l:].rstrip(' ').replace('#', '20') 151 self.end_time = end_time[0:4] + '-' + end_time[4:6] + '-' + end_time[6:] 152 tran_sql=record_sql+"insert into {}(begin_time,end_time) VALUES ('{}','{}')".format(self.tbtran,self.begin_time,self.end_time) 153 154 self.cur.execute(tran_sql) 155 self.mysqlconn.commit() 156 record_sql = '' 157 tran_num += 1 158 159 except Exception: 160 return 'funtion rowrecord error' 161 162 def binlogdesc(self): 163 sql='' 164 t_num=0 165 r_num=0 166 logging.info('Analysed result printing...\n') 167 #分析總的事務數跟行修改數量 168 sql="select 'tbtran' name,count(*) nums from {} union all select 'tbrow' name,count(*) nums from {};".format(self.tbtran,self.tbrow) 169 self.cur.execute(sql) 170 rows=self.cur.fetchall() 171 for row in rows: 172 if row['name']=='tbtran': 173 t_num = row['nums'] 174 else: 175 r_num = row['nums'] 176 print('This binlog file has {} transactions, {} rows are changed '.format(t_num,r_num)) 177 178 # 計算 最耗時 的單個事務 179 # 分析每個事務的耗時情況,分為5個時間段來描述 180 # 這裡正常應該是 以毫秒來分析的,但是binlog中,只精確時間到second 181 sql='''select 182 count(case when cost_sec between 0 and 1 then 1 end ) cos_1, 183 count(case when cost_sec between 1.1 and 5 then 1 end ) cos_5, 184 count(case when cost_sec between 5.1 and 10 then 1 end ) cos_10, 185 count(case when cost_sec between 10.1 and 30 then 1 end ) cos_30, 186 count(case when cost_sec >30.1 then 1 end ) cos_more, 187 max(cost_sec) cos_max 188 from 189 ( 190 select 191 auto_id,timestampdiff(second,begin_time,end_time) cost_sec 192 from {} 193 ) a;'''.format(self.tbtran) 194 self.cur.execute(sql) 195 rows=self.cur.fetchall() 196 197 for row in rows: 198 print('The most cost time : {} '.format(row['cos_max'])) 199 print('The distribution map of each transaction costed time: ') 200 print('Cost time between 0 and 1 second : {} , {}%'.format(row['cos_1'],int(row['cos_1']*100/t_num))) 201 print('Cost time between 1.1 and 5 second : {} , {}%'.format(row['cos_5'], int(row['cos_5'] * 100 / t_num))) 202 print('Cost time between 5.1 and 10 second : {} , {}%'.format(row['cos_10'], int(row['cos_10'] * 100 / t_num))) 203 print('Cost time between 10.1 and 30 second : {} , {}%'.format(row['cos_30'], int(row['cos_30'] * 100 / t_num))) 204 print('Cost time > 30.1 : {} , {}%\n'.format(row['cos_more'], int(row['cos_more'] * 100 / t_num))) 205 206 # 計算 單個事務影響行數最多 的行數量 207 # 分析每個事務 影響行數 情況,分為5個梯度來描述 208 sql='''select 209 count(case when nums between 0 and 10 then 1 end ) row_1, 210 count(case when nums between 11 and 100 then 1 end ) row_2, 211 count(case when nums between 101 and 1000 then 1 end ) row_3, 212 count(case when nums between 1001 and 10000 then 1 end ) row_4, 213 count(case when nums >10001 then 1 end ) row_5, 214 max(nums) row_max 215 from 216 ( 217 select 218 count(*) nums 219 from {} group by tran_num 220 ) a;'''.format(self.tbrow) 221 self.cur.execute(sql) 222 rows=self.cur.fetchall() 223 224 for row in rows: 225 print('The most changed rows for each row: {} '.format(row['row_max'])) 226 print('The distribution map of each transaction changed rows : ') 227 print('Changed rows between 1 and 10 second : {} , {}%'.format(row['row_1'],int(row['row_1']*100/t_num))) 228 print('Changed rows between 11 and 100 second : {} , {}%'.format(row['row_2'], int(row['row_2'] * 100 / t_num))) 229 print('Changed rows between 101 and 1000 second : {} , {}%'.format(row['row_3'], int(row['row_3'] * 100 / t_num))) 230 print('Changed rows between 1001 and 10000 second : {} , {}%'.format(row['row_4'], int(row['row_4'] * 100 / t_num))) 231 print('Changed rows > 10001 : {} , {}%\n'.format(row['row_5'], int(row['row_5'] * 100 / t_num))) 232 233 # 分析 各個行數 DML的類型情況 234 # 描述 delete,insert,update的分佈情況 235 sql='select sqltype ,count(*) nums from {} group by sqltype ;'.format(self.tbrow) 236 self.cur.execute(sql) 237 rows=self.cur.fetchall() 238 239 print('The distribution map of the {} changed rows : '.format(r_num)) 240 for row in rows: 241 242 if row['sqltype']==1: 243 print('INSERT rows :{} , {}% '.format(row['nums'],int(row['nums']*100/r_num))) 244 if row['sqltype']==2: 245 print('UPDATE rows :{} , {}% '.format(row['nums'],int(row['nums']*100/r_num))) 246 if row['sqltype']==3: 247 print('DELETE rows :{} , {}%\n '.format(row['nums'],int(row['nums']*100/r_num))) 248 249 # 描述 影響行數 最多的表格 250 # 可以分析是哪些表格頻繁操作,這裡顯示前10個table name 251 sql = '''select 252 dbname,tbname , 253 count(*) ALL_rows, 254 count(*)*100/{} per, 255 count(case when sqltype=1 then 1 end) INSERT_rows, 256 count(case when sqltype=2 then 1 end) UPDATE_rows, 257 count(case when sqltype=3 then 1 end) DELETE_rows 258 from {} 259 group by dbname,tbname 260 order by ALL_rows desc 261 limit 10;'''.format(r_num,self.tbrow) 262 self.cur.execute(sql) 263 rows = self.cur.fetchall() 264 265 print('The distribution map of the {} changed rows : '.format(r_num)) 266 print('tablename'.ljust(50), 267 '|','changed_rows'.center(15), 268 '|','percent'.center(10), 269 '|','insert_rows'.center(18), 270 '|','update_rows'.center(18), 271 '|','delete_rows'.center(18) 272 ) 273 print('-------------------------------------------------------------------------------------------------------------------------------------------------') 274 for row in rows:


