
在ElasticSearch 2.4版本中,文檔存儲的介質分為記憶體和硬碟:記憶體速度快,但是容量有限;硬碟速度較慢,但是容量很大。同時,ElasticSearch進程自身的運行也需要記憶體空間,必須保證ElasticSearch進程有充足的運行時記憶體。為了使ElasticSearch引擎達到最佳性能,必... ...
這是ElasticSearch 2.4 版本系列的第八篇:
- ElasticSearch入門 第一篇:Windows下安裝ElasticSearch
- ElasticSearch入門 第二篇:集群配置
- ElasticSearch入門 第三篇:索引
- ElasticSearch入門 第四篇:使用C#添加和更新文檔
- ElasticSearch入門 第五篇:使用C#查詢文檔
- ElasticSearch入門 第六篇:複合數據類型——數組,對象和嵌套
- ElasticSearch入門 第七篇:分析器
- ElasticSearch入門 第八篇:存儲
- ElasticSearch入門 第九篇:實現正則表達式查詢的思路
在ElasticSearch 2.4版本中,文檔存儲的介質分為記憶體和硬碟:記憶體速度快,但是容量有限;硬碟速度較慢,但是容量很大。同時,ElasticSearch進程自身的運行也需要記憶體空間,必須保證ElasticSearch進程有充足的運行時記憶體。為了使ElasticSearch引擎達到最佳性能,必須合理分配有限的記憶體和硬碟資源。
一,倒排索引(Inverted Index)
ElasticSearch引擎把文檔數據寫入到倒排索引(Inverted Index)的數據結構中,倒排索引建立的是分詞(Term)和文檔(Document)之間的映射關係,在倒排索引中,數據是面向詞(Term)而不是面向文檔的。
舉個例子,文檔和詞條之間的關係如下圖:
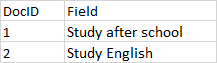
欄位值被分析之後,存儲在倒排索引中,倒排索引存儲的是分詞(Term)和文檔(Doc)之間的關係,簡化版的倒排索引如下圖:

從圖中可以看出,倒排索引有一個詞條的列表,每個分詞在列表中是唯一的,記錄著詞條出現的次數,以及包含詞條的文檔。實際上,ElasticSearch引擎創建的倒排索引比這個複雜得多。
1,段是倒排索引的組成部分
倒排索引是由段(Segment)組成的,段存儲在硬碟(Disk)文件中。索引段不是實時更新的,這意味著,段在寫入硬碟之後,就不再被更新。在刪除文檔時,ElasticSearch引擎把已刪除的文檔的信息存儲在一個單獨的文件中,在搜索數據時,ElasticSearch引擎首先從段中執行查詢,再從查詢結果中過濾被刪除的文檔,這意味著,段中存儲著被刪除的文檔,這使得段中含有”正常文檔“的密度降低。多個段可以通過段合併(Segment Merge)操作把“已刪除”的文檔將從段中物理刪除,把未刪除的文檔合併到一個新段中,新段中沒有”已刪除文檔“,因此,段合併操作能夠提高索引的查找速度,但是,段合併是IO密集型操作,需要消耗大量的硬碟IO。
在ElasticSearch中,大多數查詢都需要從硬碟文件(索引的段數據存儲在硬碟文件中)中獲取數據,因此,在全局配置文件elasticsearch.yml 中,把結點的路徑(Path)配置為性能較高的硬碟,能夠提高查詢性能。預設情況下,ElasticSearch使用基於安裝目錄的相對路徑來配置結點的路徑,安裝目錄由屬性path.home顯示,在home path下,ElasticSearch自動創建config,data,logs和plugins目錄,一般情況下不需要對結點路徑單獨配置。結點的文件路徑配置項:
- path.data:設置ElasticSearch結點的索引數據保存的目錄,多個數據文件使用逗號隔開,例如,path.data: /path/to/data1,/path/to/data2;
- path.work:設置ElasticSearch的臨時文件保存的目錄;
2,分詞和原始文本的存儲
映射參數index決定ElasticSearch引擎是否對文本欄位執行分析操作,也就是說分析操作把文本分割成一個一個的分詞,也就是標記流(Token Stream),把分詞編入索引,使分詞能夠被搜索到:
- 當index為analyzed時,該欄位是分析欄位,ElasticSearch引擎對該欄位執行分析操作,把文本分割成分詞流,存儲在倒排索引中,使其支持全文搜索;
- 當index為not_analyzed時,該欄位不會被分析,ElasticSearch引擎把原始文本作為單個分詞存儲在倒排索引中,不支持全文搜索,但是支持詞條級別的搜索;也就是說,欄位的原始文本不經過分析而存儲在倒排索引中,把原始文本編入索引,在搜索的過程中,查詢條件必須全部匹配整個原始文本;
- 當index為no時,該欄位不會被存儲到倒排索引中,不會被搜索到;
欄位的原始值是否被存儲到倒排索引,是由映射參數store決定的,預設值是false,也就是,原始值不存儲到倒排索引中。
映射參數index和store的區別在於:
- store用於獲取(Retrieve)欄位的原始值,不支持查詢,可以使用投影參數fields,對stroe屬性為true的欄位進行過濾,只獲取(Retrieve)特定的欄位,減少網路負載;
- index用於查詢(Search)欄位,當index為analyzed時,對欄位的分詞執行全文查詢;當index為not_analyzed時,欄位的原始值作為一個分詞,只能對欄位的原始文本執行詞條查詢;
3,單個分詞的最大長度
如果設置欄位的index屬性為not_analyzed,原始文本將作為單個分詞,其最大長度跟UTF8 編碼有關,預設的最大長度是32766Bytes,如果欄位的文本超過該限制,那麼ElasticSearch將跳過(Skip)該文檔,併在Response中拋出異常消息:
operation[607]: index returned 400 _index: ebrite _type: events _id: 76860 _version: 0 error: Type: illegal_argument_exception Reason: "Document contains at least one immense term in field="event_raw" (whose UTF8 encoding is longer than the max length 32766), all of which were skipped. Please correct the analyzer to not produce such terms. The prefix of the first immense term is: '[112, 114,... 115]...', original message: bytes can be at most 32766 in length; got 35100" CausedBy:Type: max_bytes_length_exceeded_exception Reason: "bytes can be at most 32766 in length; got 35100"
可以在欄位中設置ignore_above屬性,該屬性值指的是字元數量,而不是位元組數量;由於一個UTF8字元最多占用3個位元組,因此,可以設置
“ignore_above”:10000
這樣,超過30000位元組之後的字元將會被分析器忽略,單個分詞(Term)的最大長度是30000Bytes。
The value for
ignore_aboveis the character count, but Lucene counts bytes. If you use UTF-8 text with many non-ASCII characters, you may want to set the limit to32766 / 3 = 10922since UTF-8 characters may occupy at most 3 bytes.
二,列式存儲(doc_values)
預設情況下,大多數欄位被索引之後,能夠被搜索到。倒排索引是由一個有序的詞條列表構成的,每一個詞條在列表中都是唯一存在的,通過這種數據存儲模式,你可以很快查找到包含某一個詞條的文檔列表。但是,排序和聚合操作採用相反的數據訪問模式,這兩種操作不是查找詞條以發現文檔,而是查找文檔,以發現欄位中包含的詞條。ElasticSearch使用列式存儲實現排序和聚合查詢。
文檔值(doc_values)是存儲在硬碟上的數據結構,在索引時(index time)根據文檔的原始值創建,文檔值是一個列式存儲風格的數據結構,非常適合執行存儲和聚合操作,除了字元類型的分析欄位之外,其他欄位類型都支持文檔值存儲。預設情況下,欄位的文檔值存儲是啟用的,除了字元類型的分析欄位之外。如果不需要對欄位執行排序或聚合操作,可以禁用欄位的文檔值,以節省硬碟空間。
"mappings": { "my_type": { "properties": { "status_code": { "type": "string", "index": "not_analyzed" }, "session_id": { "type": "string", "index": "not_analyzed", "doc_values": false } } } }
三,順排索引(fielddata)
字元類型的分析欄位,不支持文檔值(doc_values),但是,支持fielddata數據結構,fielddata數據結構存儲在JVM的堆記憶體中。相比文檔值(數據存儲在硬碟上),fielddata欄位(數據存儲在記憶體中)的查詢性能更高。預設情況下,ElasticSearch引擎在第一次對欄位執行聚合或排序查詢時((query-time)),創建fielddata數據結構;在後續的查詢請求中,ElasticSearch引擎使用fielddata數據結構以提高聚合和排序的查詢性能。
在ElasticSearch中,倒排索引的各個段(segment)的數據存儲在硬碟文件上,從整個倒排索引的段中讀取欄位數據之後,ElasticSearch引擎首先反轉詞條和文檔之間的關係,創建文檔和詞條之間的關係,即創建順排索引,然後把順排索引存儲在JVM的堆記憶體中。把倒排索引載入到fielddata結構是一個非常消耗硬碟IO資源的過程,因此,數據一旦被載入到記憶體,最好保持在記憶體中,直到索引段(segment)的生命周期結束。預設情況下,倒排索引的每個段(segment),都會創建相應的fielddata結構,以存儲字元類型的分析欄位值,但是,需要註意的是,分配的JVM堆記憶體是有限的,Fileddata把數據存儲在記憶體中,會占用過多的JVM堆記憶體,甚至耗盡JVM賴以正常運行的記憶體空間,反而會降低ElasticSearch引擎的查詢性能。
1,format屬性
fielddata會消耗大量的JVM記憶體,因此,儘量為JVM設置大的記憶體,不要為不必要的欄位啟用fielddata存儲。通過format參數控制是否啟用欄位的fielddata特性,字元類型的分析欄位,fielddata的預設值是paged_bytes,這就意味著,預設情況下,字元類型的分析欄位啟用fielddata存儲。一旦禁用fielddata存儲,那麼字元類型的分析欄位將不再支持排序和聚合查詢。
"mappings": { "my_type": { "properties": { "text": { "type": "string", "fielddata": { "format": "disabled" } } } } }
2,載入屬性(loading)
loading屬性控制fielddata載入到記憶體的時機,可能的值是lazy,eager和eager_global_ordinals,預設值是lazy。
- lazy:fielddata只在需要時載入到記憶體,預設情況下,在第一次搜索時,fielddata被載入到記憶體中;但是,如果查詢一個非常大的索引段(Segment),lazy載入方式會產生較大的時間延遲。
- eager:在倒排索引的段可用之前,其數據就被載入到記憶體,eager載入方式能夠減少查詢的時間延遲,但是,有些數據可能非常冷,以至於沒有請求來查詢這些數據,但是冷數據依然被載入到記憶體中,占用緊缺的記憶體資源。
- eager_global_ordinals:按照global ordinals積極把fielddata載入到記憶體。
四,JVM進程使用的記憶體和堆記憶體
1,配置ElasticSearch使用的記憶體
ElasticSearch使用JAVA_OPTS環境變數(Environment Variable)啟動JVM進程,在JAVA_OPTS中,最重要的配置是:-Xmx參數控制分配給JVM進程的最大記憶體,-Xms參數控制分配給JVM進程的最小記憶體。通常情況下,使用預設的配置就能滿足工程需要。
ES_HEAP_SIZE 環境變數控制分配給JVM進程的堆記憶體(Heap Memory)大小,順排索引(fielddata)的數據存儲在堆記憶體(Heap Memory)中。
2,記憶體鎖定
大多數應用程式嘗試使用儘可能多的記憶體,並儘可能把未使用的記憶體換出,但是,記憶體換出會影響ElasticSearch引擎的查詢性能,推薦啟用記憶體鎖定,禁用ElasticSearch記憶體的換進換出。
在全局配置文檔 elasticsearch.yml中,設置 bootstrap.memory_lock為ture,這將鎖定ElasticSearch進程的記憶體地址空間,阻止ElasticSearch記憶體被OS換出(Swap out)。
參考文檔:
Elasticsearch Reference [2.4] » Mapping » Mapping parameters


