
如果轉載,請註明博文來源: www.cnblogs.com/xinysu/ ,版權歸 博客園 蘇家小蘿蔔 所有。望各位支持! 1 行記錄如何存儲 這裡引入兩個概念:堆跟聚集索引表。本部分參考MSDN。 1.1 堆表 堆表,沒有聚集索引的表格,可以創建一個或者多個非聚集索引。沒有按照某個規則進行存儲, ...
如果轉載,請註明博文來源: www.cnblogs.com/xinysu/ ,版權歸 博客園 蘇家小蘿蔔 所有。望各位支持!
1 行記錄如何存儲
這裡引入兩個概念:堆跟聚集索引表。本部分參考MSDN。1.1 堆表
堆表,沒有聚集索引的表格,可以創建一個或者多個非聚集索引。沒有按照某個規則進行存儲,一般來說,按照行記錄入表的順序,但是由於性能要求,可能會在不同區域移動入庫數據。像一堆沙子一樣,沒有明確的組織順序。 堆的 sys.partitions 中具有一行,對於堆使用的每個分區,都有 index_id = 0。預設情況下,一個堆有一個分區。 當堆有多個分區時,每個分區有一個堆結構,其中包含該特定分區的數據。例如,如果一個堆有四個分區,則有四個堆結構,每個分區有一個堆結構。 根據堆中的數據類型,每個堆結構將有一個或多個分配單元來存儲和管理特定分區的數據。每個堆中每個分區至少有一個 IN_ROW_DATA 分配單元。如果堆包含大型對象 (LOB) 列,則該堆的每個分區還將有一個 LOB_DATA 分配單元。如果堆包含超過 8,060 位元組的行大小限制的變數長度列,則它的每個分區中還會有一個 ROW_OVERFLOW_DATA 分配單元。 sys.system_internals_allocation_units系統視圖中的列 first_iam_page 指向 IAM 頁鏈中的第一個 IAM 頁,該 IAM 頁鏈可管理分配給特定分區中的堆的空間。 SQL Server 使用 IAM 頁在堆之間移動。堆內的數據頁和行沒有任何特定的順序,也不鏈接在一起。數據頁之間唯一的邏輯連接是記錄在 IAM 頁內的信息。.png)
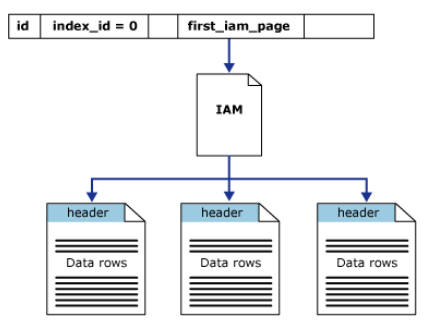
擁有聚集索引的表格,稱為聚集索引表,每個表格按照其聚集索引的排序規則進行存儲,但是這裡註意一點,在一個頁面中,並非 行記錄 按照 其聚集索引排序規則,而是 行偏移量 按照其排序規則存儲。
1.2 聚集索引表格
在 SQL Server 中,索引是按 B 樹結構進行組織的。 索引 B 樹中的每一頁稱為一個索引節點。 B 樹的頂端節點稱為根節點。 索引中的底層節點稱為葉節點。 根節點與葉節點之間的任何索引級別統稱為中間級。 在聚集索引中,葉節點包含基礎表的數據頁。 根節點和中間級節點包含存有索引行的索引頁。 每個索引行包含一個鍵值和一個指針,該指針指向 B 樹上的某一中間級頁或葉級索引中的某個數據行。 每級索引中的頁均被鏈接在雙向鏈接列表中。 聚集索引在 sys.partitions 中有一行,其中,索引使用的每個分區的 index_id = 1。 預設情況下,聚集索引有單個分區。 當聚集索引有多個分區時,每個分區都有一個包含該特定分區相關數據的 B 樹結構。 例如,如果聚集索引有四個分區,就有四個 B 樹結構,每個分區中有一個 B 樹結構。 根據聚集索引中的數據類型,每個聚集索引結構將有一個或多個分配單元,將在這些單元中存儲和管理特定分區的相關數據。 每個聚集索引的每個分區中至少有一個 IN_ROW_DATA 分配單元。 如果聚集索引包含大型對象 (LOB) 列,則它的每個分區中還會有一個 LOB_DATA 分配單元。 如果聚集索引包含的變數長度列超過 8,060 位元組的行大小限制,則它的每個分區中還會有一個 ROW_OVERFLOW_DATA 分配單元。 數據鏈內的頁和行將按聚集索引鍵值進行排序。 所有插入操作都在所插入行中的鍵值與現有行中的排序順序相匹配時執行。 下圖顯式了聚集索引單個分區中的結構。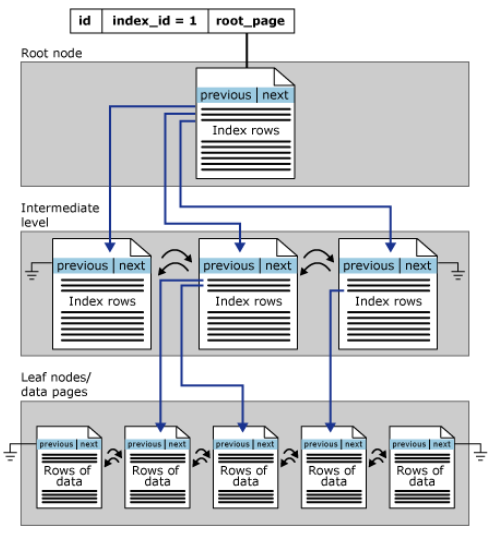 由此,可以看出,堆表不存在特定的存儲順序,一般按照INSERT的順序存儲,但是有時因為性能需求,也會四處存放數據;而聚集索引表的數據行按照聚集鍵的排序情況存儲,葉子節點即為行記錄。
由此,可以看出,堆表不存在特定的存儲順序,一般按照INSERT的順序存儲,但是有時因為性能需求,也會四處存放數據;而聚集索引表的數據行按照聚集鍵的排序情況存儲,葉子節點即為行記錄。
2 非聚集索引結構
無論是堆表還是聚集索引表格,都可以創建非聚集索引。非聚集索引頁也是B-TREE結構,但是,有幾點不同:非聚集索引不影響基礎表的存儲順序,其葉子節點是有索引頁組成而非數據頁組成。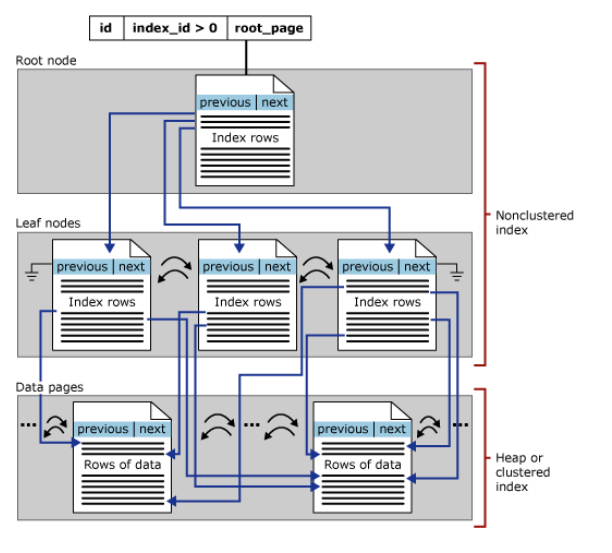 當需要通過非聚集索引尋找行記錄時,先是在非聚集索引所在的B-TREE樹查找,找到相應的葉子節點後,在根據該鍵值上的相應 行定位器 去查找其所指向的 行記錄位置。
那麼,行定位器是怎麼樣的呢?
這個還需要去分析 非聚集索引的鍵值內容,才可以清晰瞭解,詳見下文的分析案例。
當需要通過非聚集索引尋找行記錄時,先是在非聚集索引所在的B-TREE樹查找,找到相應的葉子節點後,在根據該鍵值上的相應 行定位器 去查找其所指向的 行記錄位置。
那麼,行定位器是怎麼樣的呢?
這個還需要去分析 非聚集索引的鍵值內容,才可以清晰瞭解,詳見下文的分析案例。
3 非聚集索引鍵值內容
創建3個表格:堆表、聚集索引非唯一表及聚集索引唯一表,並且創建非聚集索引,同時INSERT 部分數據。 --創建堆表 create table tb_heap(id int ,name varchar(100),age int) --創建聚集索引(非唯一)表 create table tb_clu_no_unique(id int identity(1,1) ,name varchar(100),age int) create CLUSTERED index ix_clu_id on tb_clu_no_unique(id) --創建聚集索引且鍵值唯一表 create table tb_pk(id int primary key identity(1,1) ,name varchar(100),age int) --創建非聚集索引 create index ix_tb_pk_name on tb_pk(name) create index ix_tb_heap_name on tb_heap(name) create index ix_tb_clu_no_unique_name on tb_clu_no_unique(name) --造數據 insert into tb_pk(name,age) select name,cast(rand()*100 as int) from master.dbo.spt_values where name is not null insert into tb_clu_no_unique(name,age) select name,age from tb_pk insert into tb_heap(id,name,age) select id,name,age from tb_pk3.1 堆表上的非聚集索引
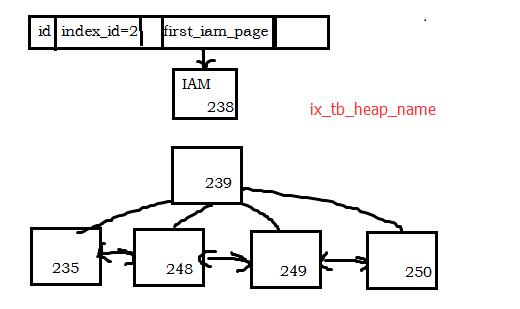
#會話視窗查看ind,需要打開 3604跟蹤 dbcc traceon(3604) dbcc ind('dbpage','tb_heap',2).png)
 可以得出這些結論:
可以得出這些結論:
- pageid=238是IAM頁,判斷依據是:IAMFID=NULL;
- tb_heap上的非聚集索引ix_tb_heap_name的B tree結構有2層,判斷依據是:IndexLevel最大值為1;
- B-tree樹中,根頁為 pageid=239,葉子節點的最左節點葉是 235
.png)
 選取pageid=235,來分析非聚集索引頁上的結構。
dbcc traceon(3604)
dbcc page('dbpage',1,235,3)
查看 ` 消息` ,可以看到,這個是索引頁,目前上面存儲260行索引鍵值,該頁空閑空間12個位元組,空閑空間從第7660位元組開始。
選取pageid=235,來分析非聚集索引頁上的結構。
dbcc traceon(3604)
dbcc page('dbpage',1,235,3)
查看 ` 消息` ,可以看到,這個是索引頁,目前上面存儲260行索引鍵值,該頁空閑空間12個位元組,空閑空間從第7660位元組開始。
.png)
 查看 `結果` ,如下:
查看 `結果` ,如下:
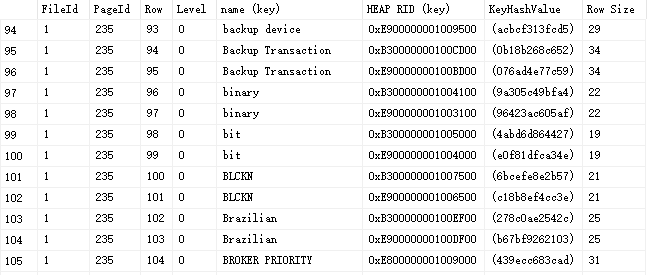 可以看到在這個頁面上,每一行的行記錄情況,可以看到 非聚集索引的鍵值有2部分:name 跟 HEAD RID,name因為是非聚集索引的列,所以理應存儲,RID是什麼呢?
RID除了可以從dbcc page中查詢,也可以通過偽列查詢:%%physloc%%。
select *,%%physloc%% as RID from tb_heap
可以看到在這個頁面上,每一行的行記錄情況,可以看到 非聚集索引的鍵值有2部分:name 跟 HEAD RID,name因為是非聚集索引的列,所以理應存儲,RID是什麼呢?
RID除了可以從dbcc page中查詢,也可以通過偽列查詢:%%physloc%%。
select *,%%physloc%% as RID from tb_heap
.png)
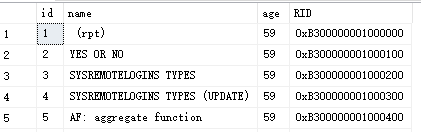 RID實際上是用來 唯一標識 堆表中的每一行數據,占8個位元組,按以下格式標識行:{ file id }:{ page id }:{ slot id},文件號:數據頁號:槽位,從存儲的角度唯一表示了一行數據。
但是從dbcc的結果看,這是一個16進位的數值,該如何轉化呢?
轉換規則:分為8個位元組->前4bytes為page id->中間2bytes為file id->最後2bytes為slot id->反序排列->取10進位
用
RID實際上是用來 唯一標識 堆表中的每一行數據,占8個位元組,按以下格式標識行:{ file id }:{ page id }:{ slot id},文件號:數據頁號:槽位,從存儲的角度唯一表示了一行數據。
但是從dbcc的結果看,這是一個16進位的數值,該如何轉化呢?
轉換規則:分為8個位元組->前4bytes為page id->中間2bytes為file id->最後2bytes為slot id->反序排列->取10進位
用 中的RID來實驗下如何反解析。
--1 分為8個位元組
E9 00 00 00 01 00 95 00
--2 前4bytes為page id
E9 00 00 00
--3 中間2bytes為file id
01 00
--4 最後2bytes為slot id
95 00
--5 反序排列並取10進位
pageid,反序後為 00 00 00 E9,十進位為16*14+9=233
fileid,反序後為 00 01,十進位為 1
slotid,反序後為 00 95,十進位為 149
則可以推算出,name='backup device'中,有一行行數據存儲在 第一個文件中的第233頁面的149槽位
dbcc page('dbpage',1,233,3)
中的RID來實驗下如何反解析。
--1 分為8個位元組
E9 00 00 00 01 00 95 00
--2 前4bytes為page id
E9 00 00 00
--3 中間2bytes為file id
01 00
--4 最後2bytes為slot id
95 00
--5 反序排列並取10進位
pageid,反序後為 00 00 00 E9,十進位為16*14+9=233
fileid,反序後為 00 01,十進位為 1
slotid,反序後為 00 95,十進位為 149
則可以推算出,name='backup device'中,有一行行數據存儲在 第一個文件中的第233頁面的149槽位
dbcc page('dbpage',1,233,3)
.png)
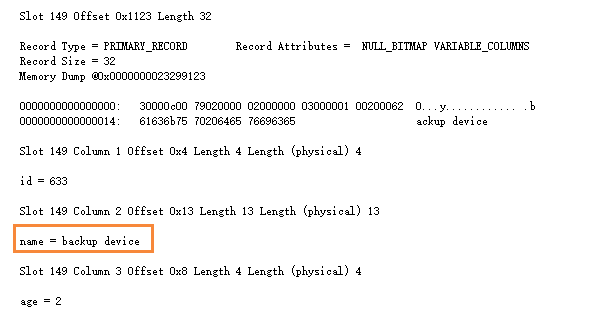
由此,可以推出:在堆表中,非聚集索引的鍵值包含兩部分:索引列 以及 RID,RID用於查找索引鍵值對應的行記錄。
3.2 聚集索引表(唯一)的非聚集索引
#會話視窗查看ind,需要打開 3604跟蹤 dbcc traceon(3604) dbcc ind('dbpage','tb_pk',2).png)
 根據2.1的推論,一樣可以得出這些結論:
根據2.1的推論,一樣可以得出這些結論:
- pageid=121是IAM頁,判斷依據是:IAMFID=NULL;
- tb_pk上的非聚集索引ix_tb_pk_name的B tree結構有2層,判斷依據是:IndexLevel最大值為1;
- B-tree樹中,根頁為 pageid=126,葉子節點的最左節點葉是 120。
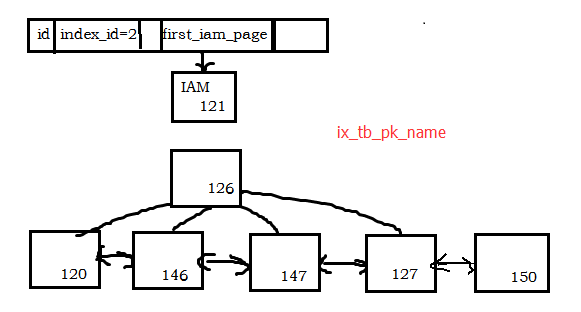
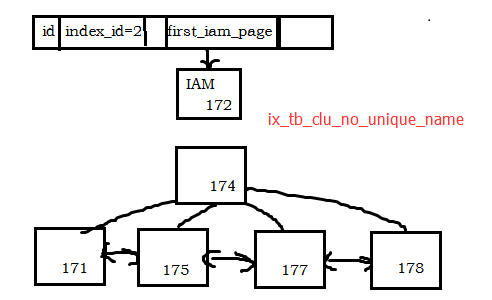
依據IndexLevel、NextPagePid及PrevPagePid,可以畫出 ix_tb_pk_name 的數據結構如下:
.png) 選取pageid=120,來分析非聚集索引頁上的結構。
dbcc traceon(3604)
dbcc page('dbpage',1,120,3)
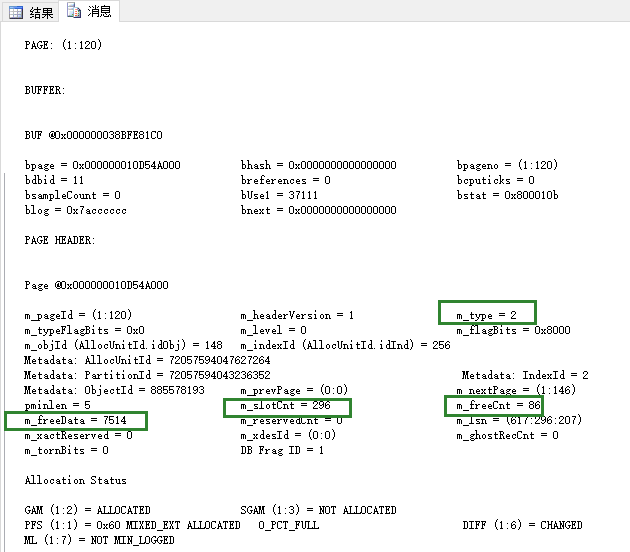
查看 ` 消息` ,可以看到,這個是索引頁,目前上面存儲296行索引鍵值,該頁空閑空間86個位元組,空閑空間從第7514位元組開始。
選取pageid=120,來分析非聚集索引頁上的結構。
dbcc traceon(3604)
dbcc page('dbpage',1,120,3)
查看 ` 消息` ,可以看到,這個是索引頁,目前上面存儲296行索引鍵值,該頁空閑空間86個位元組,空閑空間從第7514位元組開始。
 查看 ` 結果` ,可發現,在 聚集索引且唯一的表格裡邊,非聚集索引有2部分:鍵值列+主鍵列。這個相對比較好理解,因為在建立了聚集唯一索引的表格裡邊,其聚集索引鍵值可以唯一標識每一行的行記錄,所以,在非聚集索引上,只需要包含這兩部分。
查看 ` 結果` ,可發現,在 聚集索引且唯一的表格裡邊,非聚集索引有2部分:鍵值列+主鍵列。這個相對比較好理解,因為在建立了聚集唯一索引的表格裡邊,其聚集索引鍵值可以唯一標識每一行的行記錄,所以,在非聚集索引上,只需要包含這兩部分。

3.3 聚集索引表(非唯一)的非聚集索引
#會話視窗查看ind,需要打開 3604跟蹤 dbcc traceon(3604) dbcc ind('dbpage','tb_clu_no_unique',2).png)
 根據2.1的推論,一樣可以得出這些結論:
根據2.1的推論,一樣可以得出這些結論:
- pageid=172是IAM頁,判斷依據是:IAMFID=NULL;
- tb_pk上的非聚集索引tb_clu_no_unique的B tree結構有2層,判斷依據是:IndexLevel最大值為1;
- B-tree樹中,根頁為 pageid=174,葉子節點的最左節點葉是 171
.png)
 選取pageid=171,來分析非聚集索引頁上的結構。
dbcc traceon(3604)
dbcc page('dbpage',1,171,3)
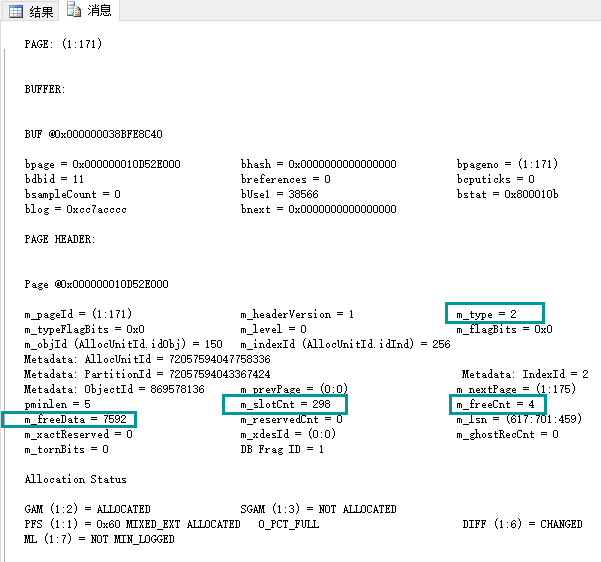
查看 ` 消息` ,可以看到,這個是索引頁,目前上面存儲298行索引鍵值,該頁空閑空間4個位元組,空閑空間從第7592位元組開始。
選取pageid=171,來分析非聚集索引頁上的結構。
dbcc traceon(3604)
dbcc page('dbpage',1,171,3)
查看 ` 消息` ,可以看到,這個是索引頁,目前上面存儲298行索引鍵值,該頁空閑空間4個位元組,空閑空間從第7592位元組開始。
.png)
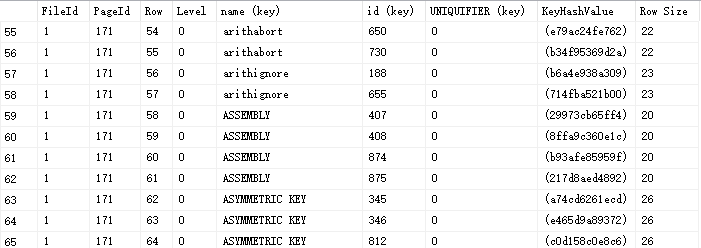
 查看 ` 結果` ,註意列後面括弧'(key)',這個表明為鍵值對組成部分,這裡,發現有之前沒有看到的鍵值列 UNIQUIFIER列。
查看 ` 結果` ,註意列後面括弧'(key)',這個表明為鍵值對組成部分,這裡,發現有之前沒有看到的鍵值列 UNIQUIFIER列。
.png) 那麼,UNIQUIFIER列,這一列是用來做什麼的呢?
這裡,為了更好的理解UNIQUIFIER列,需要新建一個新表,INSERT少量重覆聚集索引鍵值的行記錄。
create table tb_clu_no_unique_2(id int ,name varchar(100),age int)
create CLUSTERED index ix_clu_i_2 on tb_clu_no_unique_2(id)
CREATE INDEX IX_tb_clu_no_unique_2_NAME ON tb_clu_no_unique_2(NAME)
INSERT INTO tb_clu_no_unique_2(ID,NAME,AGE) SELECT 1,'A',3;
INSERT INTO tb_clu_no_unique_2(ID,NAME,AGE) SELECT 1,'B',3;
INSERT INTO tb_clu_no_unique_2(ID,NAME,AGE) SELECT 2,'C',3;
INSERT INTO tb_clu_no_unique_2(ID,NAME,AGE) SELECT 2,'D',3;
INSERT INTO tb_clu_no_unique_2(ID,NAME,AGE) SELECT 2,'E',3;
DBCC TRACEON(3604)
DBCC IND('dbpage','tb_clu_no_unique_2',2)
DBCC PAGE('dbpage',1,306,3)
那麼,UNIQUIFIER列,這一列是用來做什麼的呢?
這裡,為了更好的理解UNIQUIFIER列,需要新建一個新表,INSERT少量重覆聚集索引鍵值的行記錄。
create table tb_clu_no_unique_2(id int ,name varchar(100),age int)
create CLUSTERED index ix_clu_i_2 on tb_clu_no_unique_2(id)
CREATE INDEX IX_tb_clu_no_unique_2_NAME ON tb_clu_no_unique_2(NAME)
INSERT INTO tb_clu_no_unique_2(ID,NAME,AGE) SELECT 1,'A',3;
INSERT INTO tb_clu_no_unique_2(ID,NAME,AGE) SELECT 1,'B',3;
INSERT INTO tb_clu_no_unique_2(ID,NAME,AGE) SELECT 2,'C',3;
INSERT INTO tb_clu_no_unique_2(ID,NAME,AGE) SELECT 2,'D',3;
INSERT INTO tb_clu_no_unique_2(ID,NAME,AGE) SELECT 2,'E',3;
DBCC TRACEON(3604)
DBCC IND('dbpage','tb_clu_no_unique_2',2)
DBCC PAGE('dbpage',1,306,3)
.png)
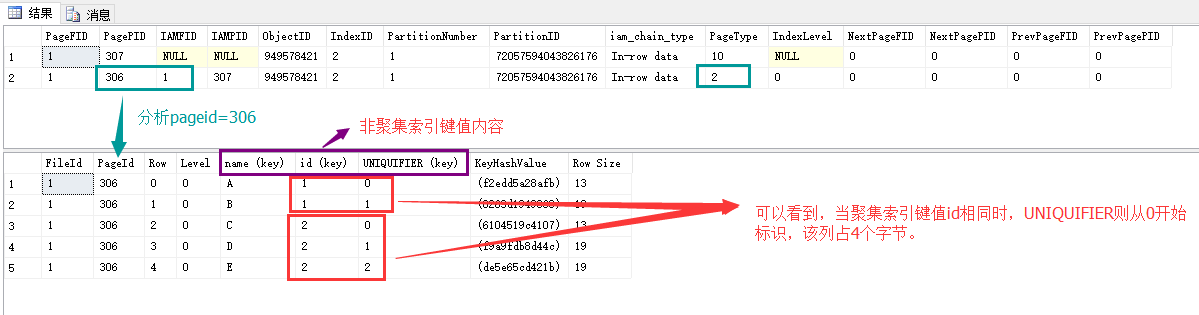 可發現,在 聚集索引且非唯一的表格裡邊,非聚集索引有3部分:鍵值列+主鍵列+UNIQUIFIER列。建立了聚集非唯一索引,表的存儲順序按照聚集索引順序,但是僅靠聚集索引無法唯一標識每一行的行記錄,所以,需要添加 UNIQUIFIER列來唯一標識。
總結:
可發現,在 聚集索引且非唯一的表格裡邊,非聚集索引有3部分:鍵值列+主鍵列+UNIQUIFIER列。建立了聚集非唯一索引,表的存儲順序按照聚集索引順序,但是僅靠聚集索引無法唯一標識每一行的行記錄,所以,需要添加 UNIQUIFIER列來唯一標識。
總結:
- 堆表 的 非聚集索引 鍵值內容:索引列+RID
- 聚集且唯一索引表 的非聚集索引 鍵值內容:索引列+主鍵列
- 聚集且非唯一索引表 的非聚集索引 鍵值內容:索引列+主鍵列+UNIQUIFIER列


