
在我們很多情況下的開發,為了方便或者通用性的考慮,都首先考慮SQL Server資料庫進行開發,但有時候客戶的生產環境是Oracle或者其他資料庫,那麼我們就需要把對應的數據結構和數據腳本轉換為對應的資料庫,數據結構一般來說,語法都遵循了SQL92的標準,或者我們根據不同的PowerDesigner... ...
在我們很多情況下的開發,為了方便或者通用性的考慮,都首先考慮SQL Server資料庫進行開發,但有時候客戶的生產環境是Oracle或者其他資料庫,那麼我們就需要把對應的數據結構和數據腳本轉換為對應的資料庫,數據結構一般來說,語法都遵循了SQL92的標準,或者我們根據不同的PowerDesigner文件進行生成對應的結構腳本即可,但是實際數據的腳本我們就需要進行一定的處理,以及文本的替換處理了,本文結合Notepad++的文本正則表達式替換,實現一些如日期較為特殊的數據腳本調整,把它從SQL Server轉換為Oracle的處理過程,本文就是針對這些整體的資料庫處理進行介紹。
1、資料庫設計文件及資料庫結構腳本
我們一般在做資料庫設計的時候,都會使用PowerDesigner這樣的資料庫建模工具進行設計,預設把它設計為SQL Server的資料庫設計模型,如下所示。
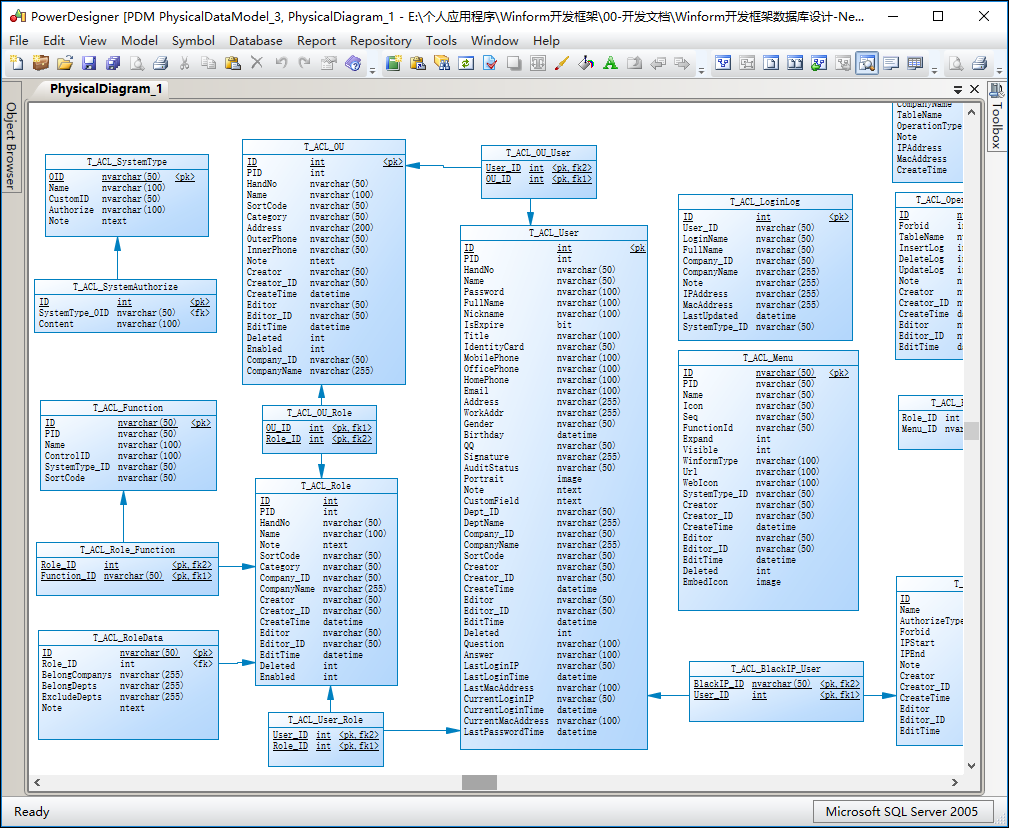
當然我們如果需要其他資料庫,那麼把它轉換為對應的資料庫,然後進行一定的資料庫類型調整,以及欄位的大小寫轉換即可。
根據這種方式我們調整後的各種資料庫設計文件如下所示。
不同的資料庫的設計模型有所差異,那麼我們進行一些核對,主要是資料庫類型的核對即可,如備註欄位的大文本應該設置為CLOB,二進位的應該調整為BLOB等。
例如對於Oracle的資料庫設計(從SQL Server轉換過來的),同時也需要把它的欄位名轉換為大寫才好,在PowerDesigner裡面可以執行自定義函數進行處理。
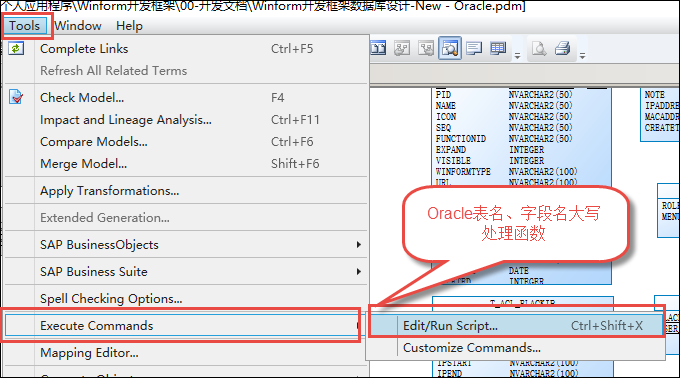
其中在對話框選擇打開對應的大寫欄位表名的腳本,如下操作。
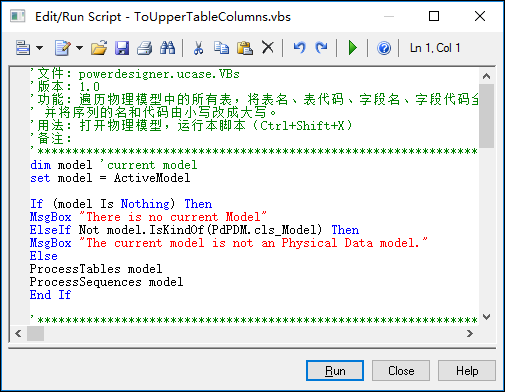
為了大家方便使用,我把它貼出來,供使用。
'文件:powerdesigner.ucase.VBs '版本:1.0 '功能:遍歷物理模型中的所有表,將表名、表代碼、欄位名、欄位代碼全部由小寫改成大寫; ' 並將序列的名和代碼由小寫改成大寫。 '用法:打開物理模型,運行本腳本(Ctrl+Shift+X) '備註: '***************************************************************************** dim model 'current model set model = ActiveModel If (model Is Nothing) Then MsgBox "There is no current Model" ElseIf Not model.IsKindOf(PdPDM.cls_Model) Then MsgBox "The current model is not an Physical Data model." Else ProcessTables model ProcessSequences model End If '***************************************************************************** '函數:ProcessSequences '功能:遞歸遍歷所有的序列 '***************************************************************************** sub ProcessSequences(folder) '處理模型中的序列:小寫改大寫 dim sequence for each sequence in folder.sequences sequence.name = UCase(sequence.name) sequence.code = UCase(sequence.code) next end sub '***************************************************************************** '函數:ProcessTables '功能:遞歸遍歷所有的表 '***************************************************************************** sub ProcessTables(folder) '處理模型中的表 dim table for each table in folder.tables if not table.IsShortCut then ProcessTable table end if next '對子目錄進行遞歸 dim subFolder for each subFolder in folder.Packages ProcessTables subFolder next end sub '***************************************************************************** '函數:ProcessTable '功能:遍歷指定table的所有欄位,將欄位名由小寫改成大寫, ' 欄位代碼由小寫改成大寫 ' 表名由小寫改成大寫 '***************************************************************************** sub ProcessTable(table) dim col for each col in table.Columns '將欄位名由小寫改成大寫 col.code = UCase(col.code) col.name = UCase(col.name) next table.name = UCase(table.name) table.code = UCase(table.code) end sub
這樣處理後,我們在PowerDesigner裡面的表名及欄位就可以正常轉換為大寫了,從而可以獲得對應表的數據結構腳本,如果需要多個表,那麼可以批量生成資料庫結構腳本。
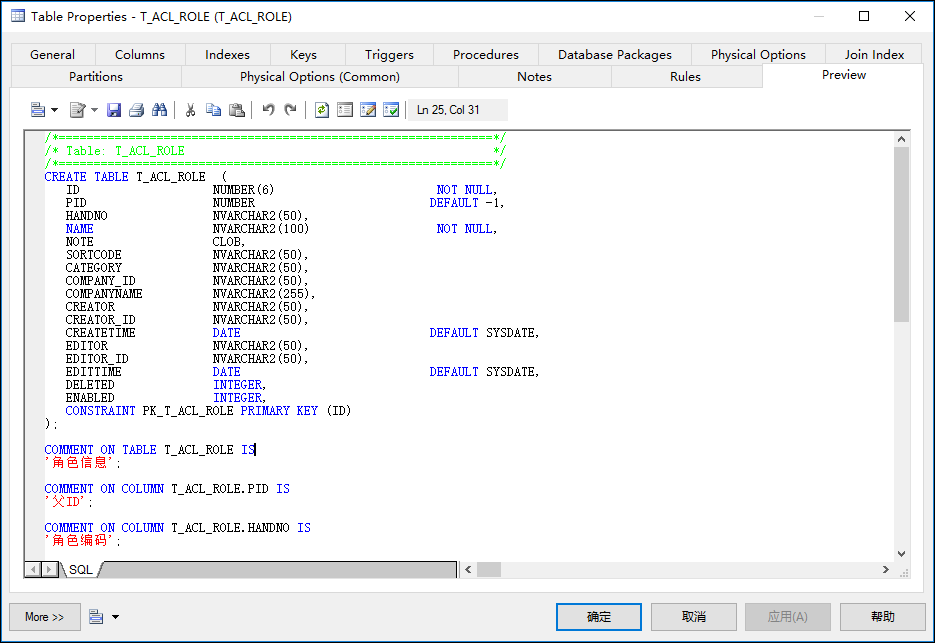
2、資料庫表數據腳本的生成
上面的資料庫表結構的腳本生成,只是我們資料庫遷移腳本的一部分操作,有時候我們實際的框架或者業務系統裡面,都往往有一些基礎數據需要寫入的,那麼就需要我們構建對應的數據腳本了。
在資料庫腳本導出的,我們可以使用很多工具,如SQL Server本身的工具就可以導出數據的SQL腳本,同時我們也可以利用其它資料庫管理工具,如Toad For SQLServer或者Navicat Premium等資料庫管理工具實現數據的導出腳本操作。
然後在生成腳本的過程中,設置輸出的高級選項中的“要編寫腳本的數據的類型”為【僅限數據】即可,如下所示。
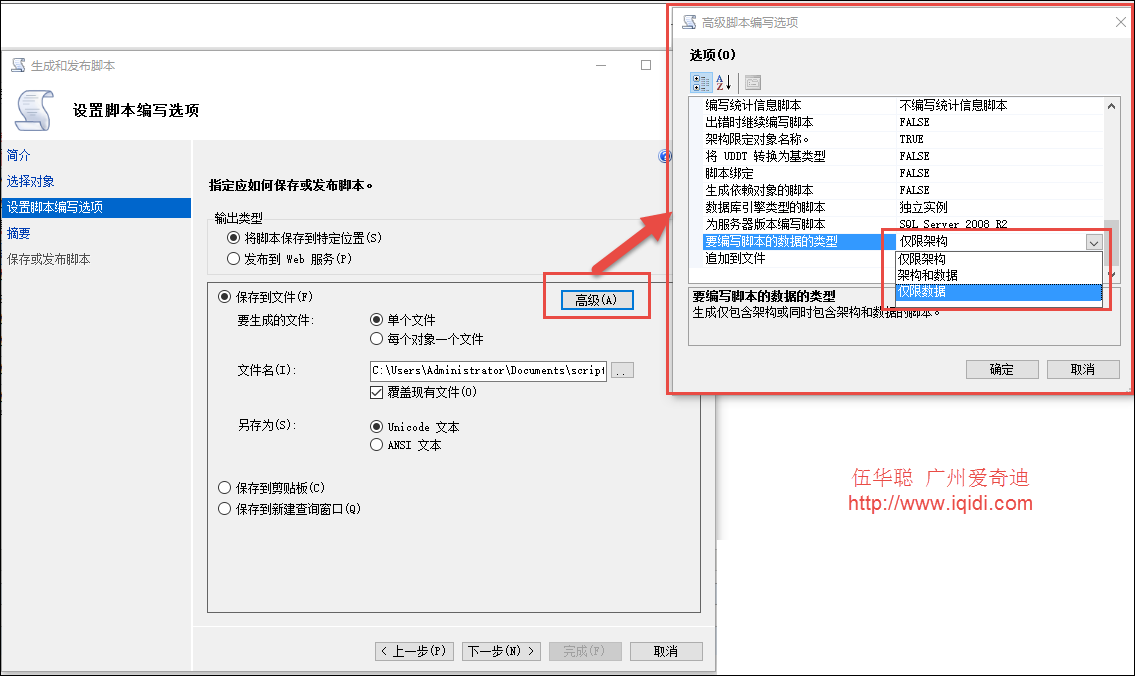
不過預設採用SQLServer生成出來的數據腳本,對日期類型轉換真不是很好,如下結果所示。
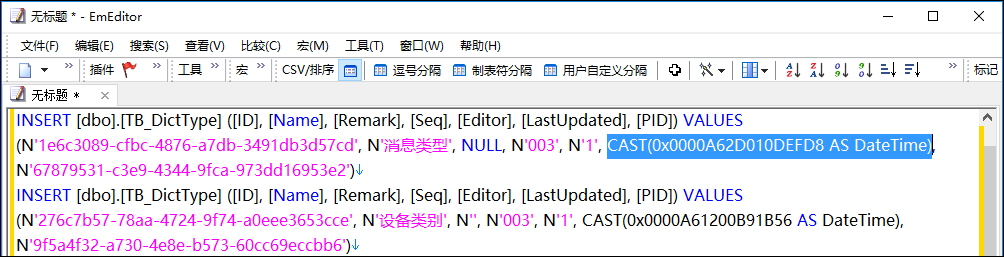
因此我使用更加直觀顯示的Navicat Premium 工具來處理資料庫的數據腳本。使用Navicat Premium生成的腳本如下所示(僅僅日期類型有所不同)。
獲得生成的數據腳本如下所示。
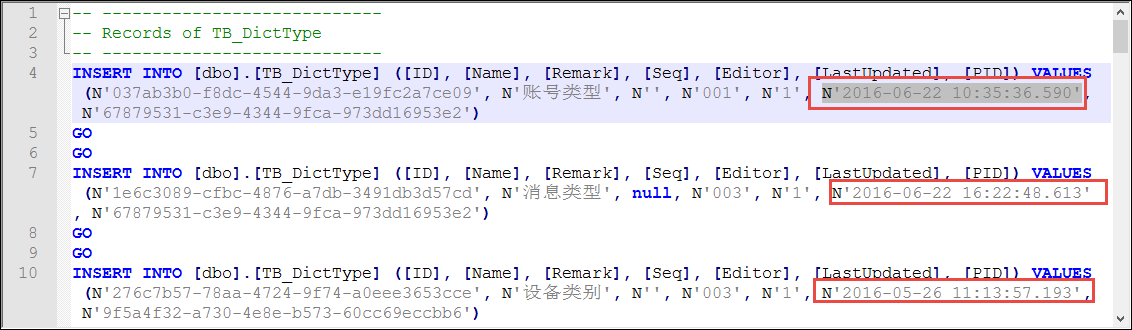
剩下的工作就是我們對這些數據腳本進行進一步的處理操作了。
3、數據表的數據腳本的替換處理
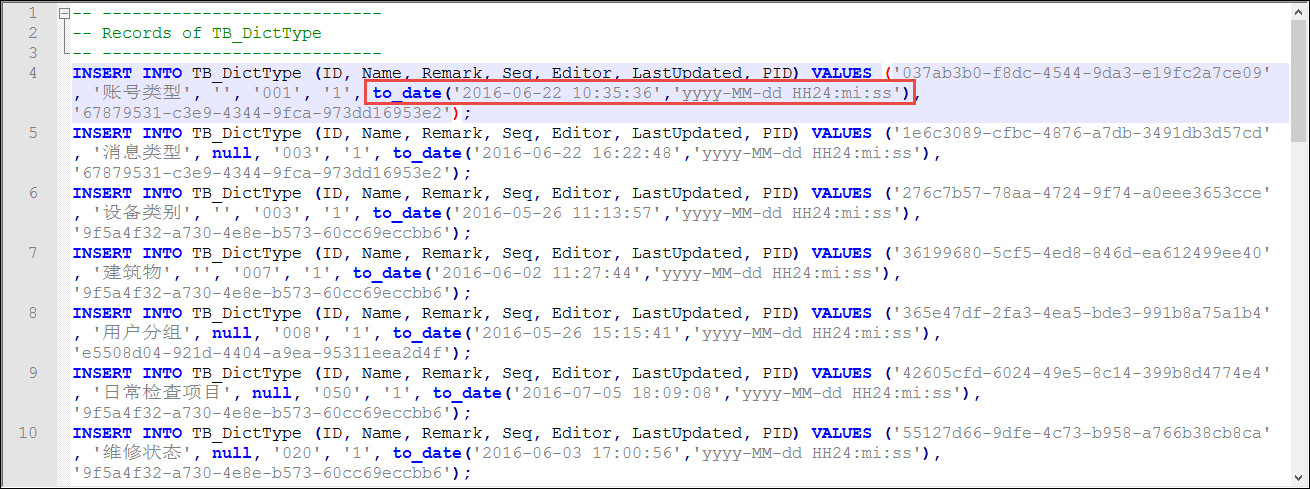
上面介紹了通過工具來獲得正確的數據腳本,我們使用了Navicat Premium或者 Toad For SQLServer都能夠獲得類似下麵格式的時間腳本。
N'2016-06-22 10:35:36.590'
這樣我們為了處理為Oracle的日期數據,那麼需要轉換為
to_date('2016-06-22 10:35:36','yyyy-MM-dd HH24:mi:ss')
這樣的格式
那麼我們對上面的腳本,進行一定規則的處理,如替換:[dbo]. [ ] N'為' 等常規文本處理後,還需要再進行正則表達式規則的處理才可以,例如我們的日期替換的正則表達式如下:
'(\d{4}-\d{2}-\d{2}\s*\d{2}:\d{2}:\d{2})\.\d{3}'
to_date\('\1','yyyy-MM-dd HH24:mi:ss'\)
如下所示。
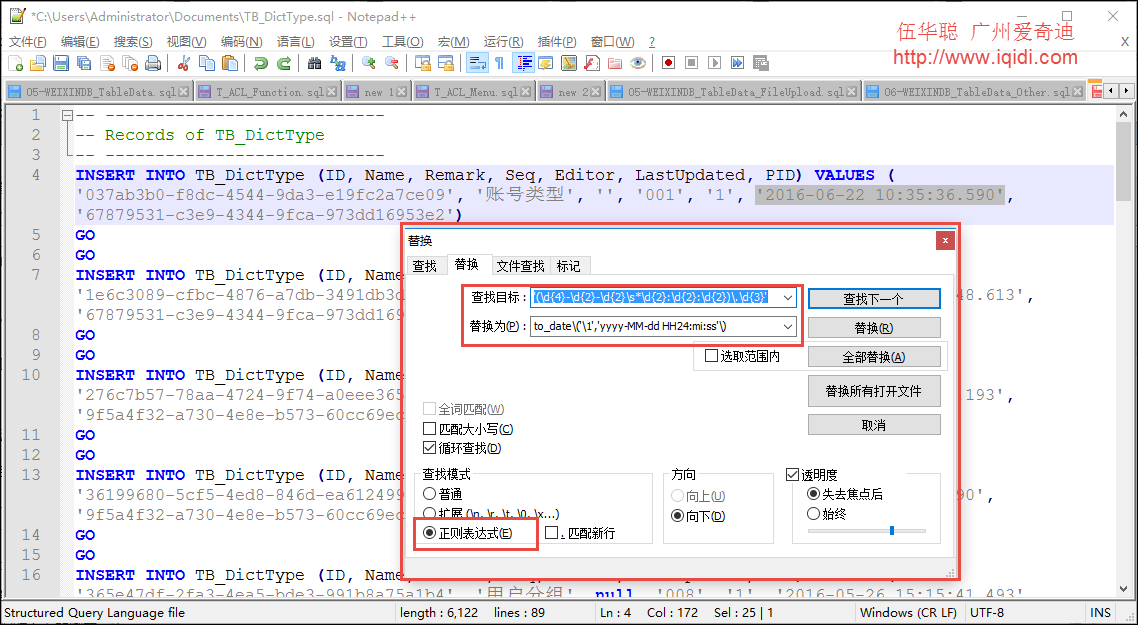
最後使用正則表達式替換後的資料庫腳本如下所示。
4、數據腳本在PL-SQL Developer工具上執行操作
上面介紹如何實現了表數據的腳本生成,有了這些腳本,我們需要使用Oracle的資料庫管理工具 PL-SQL Developer工具進行數據導入,才能最終完成整個過程。這個操作也是有所講究的。
例如我們創建各類不同的資料庫腳本,那麼只需要按照順序加入或者選擇加入執行資料庫腳本即可。
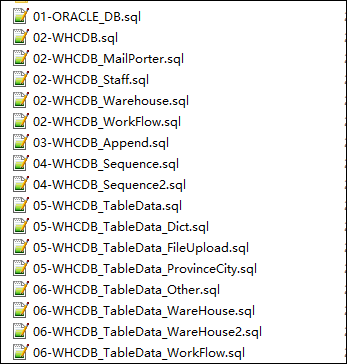
那麼執行這些SQL,該如何操作呢,是不是直接拖動到PL-SQL上就可以了?
當然不是,否則長一點的資料庫腳本,就可能導致非常遲緩的執行效率。
一般可以通過兩種方式,一種是使用命令行的方式。

這種方式執行速度非常快,比起直接在PL-SQL的SQL視窗上執行更有效率。
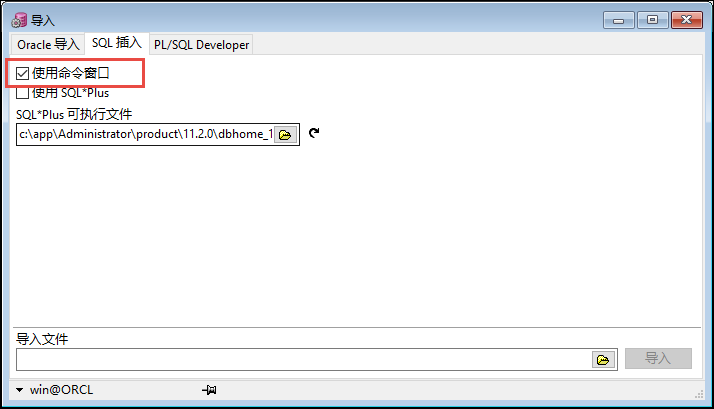
另外一種方式,就是可以利用PL-SQL裡面的另外一個地方進行執行資料庫腳本,如下所示。
在【 工具】【導入表】的操作裡面,彈出一個對話框,也是執行腳本高效的操作之一。
上面介紹的這些方式,就是在資料庫沒有的情況下,根據資料庫腳本構建對應的數據對象和數據的。


