
本文旨在提供最基本的,可以用於在生產環境進行Hadoop、HDFS分散式環境的搭建,對自己是個總結和整理,也能方便新人學習使用。 一、基礎環境 在Linux上安裝Hadoop之前,需要先安裝兩個程式: 1.1 安裝說明 1. JDK 1.6或更高版本(本文所提到的安裝的是jdk1.7); 2. SS ...
本文旨在提供最基本的,可以用於在生產環境進行Hadoop、HDFS分散式環境的搭建,對自己是個總結和整理,也能方便新人學習使用。 一、基礎環境 在Linux上安裝Hadoop之前,需要先安裝兩個程式: 1.1 安裝說明 1. JDK 1.6或更高版本(本文所提到的安裝的是jdk1.7); 2. SSH(安全外殼協議),推薦安裝OpenSSH。 下麵簡述一下安裝這兩個程式的原因: 1. Hadoop是用Java開發的,Hadoop的編譯及MapReduce的運行都需要使用JDK。 2. Hadoop需要通過SSH來啟動salve列表中各台主機的守護進程,因此SSH也是必須安裝的,即使是安裝偽分散式版本(因為Hadoop並沒有區分集群式和偽分散式)。對於偽分散式,Hadoop會採用與集群相同的處理方式,即依次序啟動文件conf/slaves中記載的主機上的進程,只不過偽分散式中salve為localhost(即為自身),所以對於偽分散式Hadoop,SSH一樣是必須的。 1.1 JDK的安裝與配置 1、上傳壓縮包 我這裡使用的是WinScp工具 上傳jdk-7u76-linux-x64.tar.gz壓縮包
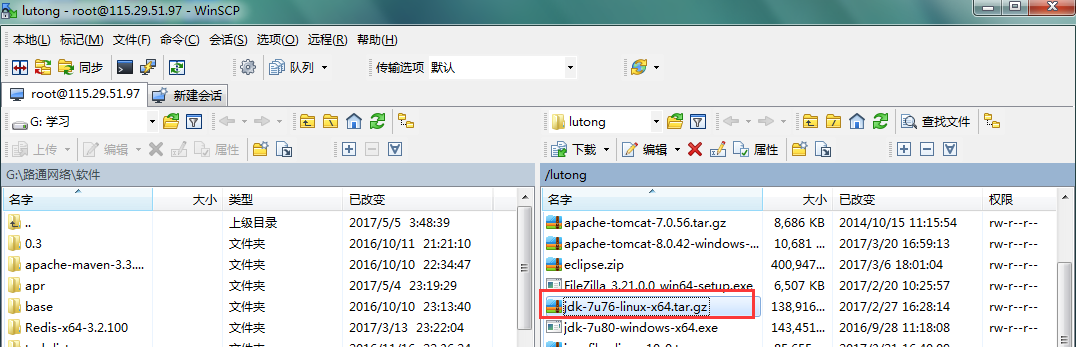 2、解壓壓縮包
tar -zxvf jdk-7u76-linux-x64.tar.gz
3、將解壓的目錄移動到/usr/local目錄下
mv /lutong/jdk1.7.0_76/ /usr/local/
2、解壓壓縮包
tar -zxvf jdk-7u76-linux-x64.tar.gz
3、將解壓的目錄移動到/usr/local目錄下
mv /lutong/jdk1.7.0_76/ /usr/local/
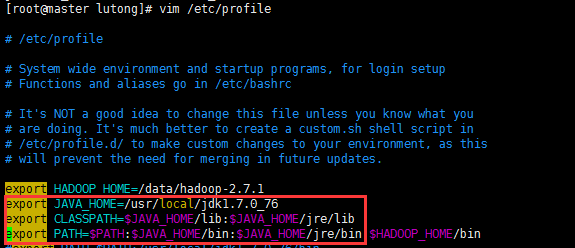
 4、配置環境變數
vim /etc/profile
4、配置環境變數
vim /etc/profile
 5、重新載入/etc/profile,使配置生效
source /etc/profile
6、查看配置是否生效
echo $PATH
java -version
5、重新載入/etc/profile,使配置生效
source /etc/profile
6、查看配置是否生效
echo $PATH
java -version
 出現如上信息表示已經配置好了。
出現如上信息表示已經配置好了。
二、Host配置
由於我搭建Hadoop集群包含三台機器,所以需要修改調整各台機器的hosts文件配置,命令如下: vim /etc/hosts 如果沒有足夠的許可權,可以切換用戶為root。 三台機器的內容統一增加以下host配置: 可以通過hostname來修改伺服器名稱為master、slave1、slave2 hostname master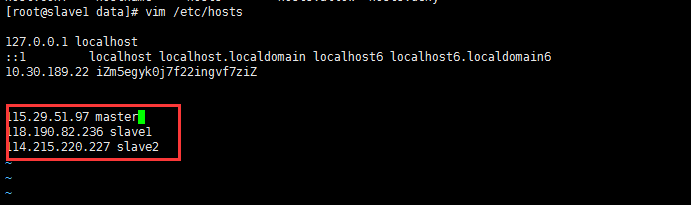
三、Hadoop的安裝與配置
3.1 創建文件目錄 為了便於管理,給Master的hdfs的NameNode、DataNode及臨時文件,在用戶目錄下創建目錄: /data/hdfs/name /data/hdfs/data /data/hdfs/tmp 然後將這些目錄通過scp命令拷貝到Slave1和Slave2的相同目錄下。 首先到Apache官網(http://www.apache.org/dyn/closer.cgi/hadoop/common/)下載Hadoop,從中選擇推薦的下載鏡像(http://mirrors.hust.edu.cn/apache/hadoop/common/),我選擇hadoop-2.6.0的版本,並使用以下命令下載到Master機器的 /data目錄: wget http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.7.1/hadoop-2.7.1.tar.gz 然後使用以下命令將hadoop-2.7.1.tar.gz 解壓縮到/data目錄 tar -zxvf hadoop-2.7.1.tar.gz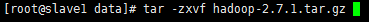 3.3 配置環境變數
回到/data目錄,配置hadoop環境變數,命令如下:
vim /etc/profile
在/etc/profile添加如下內容
3.3 配置環境變數
回到/data目錄,配置hadoop環境變數,命令如下:
vim /etc/profile
在/etc/profile添加如下內容
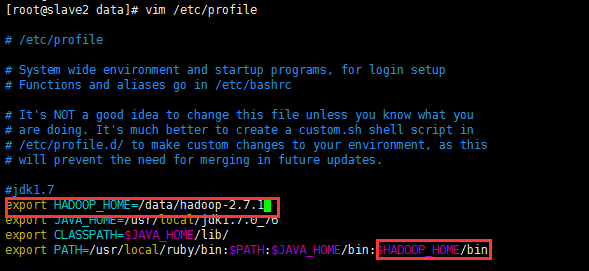 立刻讓hadoop環境變數生效,執行如下命令:
source /etc/profile
再使用hadoop命令,發現可以有提示了,則表示配置生效了。
立刻讓hadoop環境變數生效,執行如下命令:
source /etc/profile
再使用hadoop命令,發現可以有提示了,則表示配置生效了。
 3.4 Hadoop的配置
進入hadoop-2.7.1的配置目錄:
cd /data/hadoop-2.7.1/etc/hadoop
依次修改core-site.xml、hdfs-site.xml、mapred-site.xml及yarn-site.xml文件。
3.4 Hadoop的配置
進入hadoop-2.7.1的配置目錄:
cd /data/hadoop-2.7.1/etc/hadoop
依次修改core-site.xml、hdfs-site.xml、mapred-site.xml及yarn-site.xml文件。
 3.4.1 修改core-site.xml
vim core-site.xml
3.4.1 修改core-site.xml
vim core-site.xml
 3.4.2 修改vim hdfs-site.xml
vim hdfs-site.xml
3.4.2 修改vim hdfs-site.xml
vim hdfs-site.xml
 3.4.3 修改vim mapred-site.xml
vim mapred-site.xml
3.4.3 修改vim mapred-site.xml
vim mapred-site.xml
 3.4.4 修改vim yarn-site.xml
vim yarn-site.xml
3.4.4 修改vim yarn-site.xml
vim yarn-site.xml
 由於我們已經配置了JAVA_HOME的環境變數,所以hadoop-env.sh與yarn-env.sh這兩個文件不用修改,因為裡面的配置是:
export JAVA_HOME=${JAVA_HOME}
最後,將整個hadoop-2.7.1文件夾及其子文件夾使用scp複製到slave1和slave2的相同目錄中:
scp -r /data/hadoop-2.7.1 root@slave1:/data
scp -r /data/hadoop-2.7.1 root@slave2:/data
由於我們已經配置了JAVA_HOME的環境變數,所以hadoop-env.sh與yarn-env.sh這兩個文件不用修改,因為裡面的配置是:
export JAVA_HOME=${JAVA_HOME}
最後,將整個hadoop-2.7.1文件夾及其子文件夾使用scp複製到slave1和slave2的相同目錄中:
scp -r /data/hadoop-2.7.1 root@slave1:/data
scp -r /data/hadoop-2.7.1 root@slave2:/data
五、運行Hadoop
5.1 格式化NameNode
執行命令: hadoop namenode -format 執行過程如下圖:
最後的執行結果如下圖:
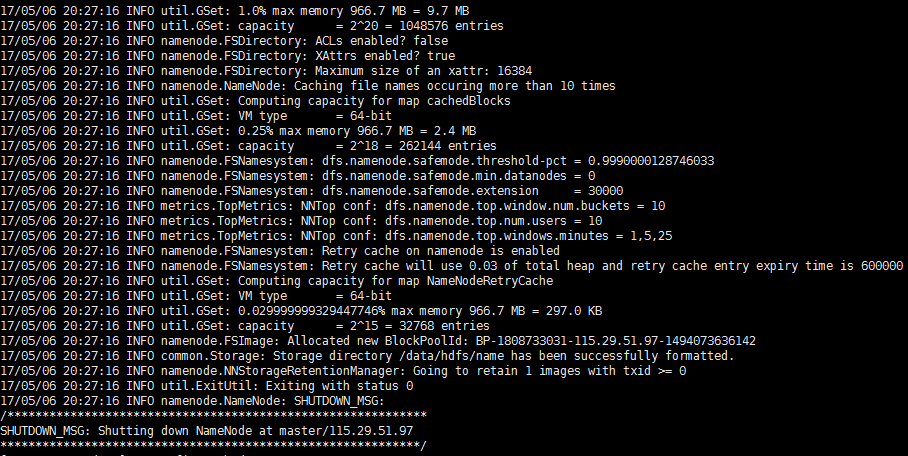
5.2 啟動NameNode
執行命令如下: /data/hadoop-2.7.1/sbin/hadoop-daemon.sh start namenode 

在Master上執行jps命令,得到如下結果:


master

slave1

slave2

說明ResourceManager運行正常。
在兩台Slave上執行jps,也會看到NodeManager運行正常,如下圖:
六、測試hadoop
6.1 測試HDFS
最後測試下親手搭建的Hadoop集群是否執行正常,測試的命令如下圖所示:

6.2 測試YARN
可以訪問YARN的管理界面,驗證YARN,如下圖所示: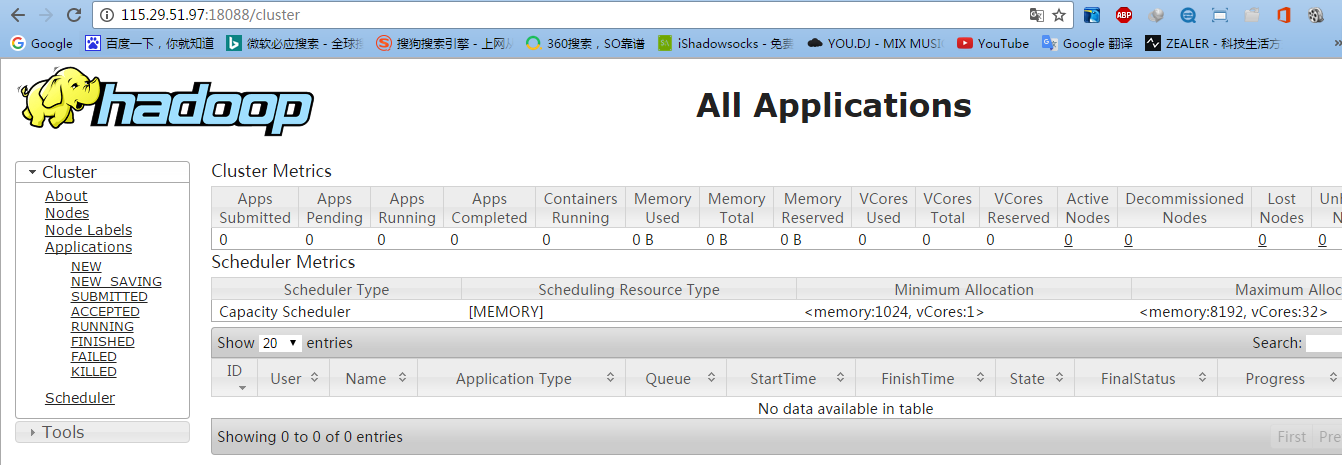
6.3 測試mapreduce
不想編寫mapreduce代碼。幸好Hadoop安裝包里提供了現成的例子,在Hadoop的share/hadoop/mapreduce目錄下。運行例子: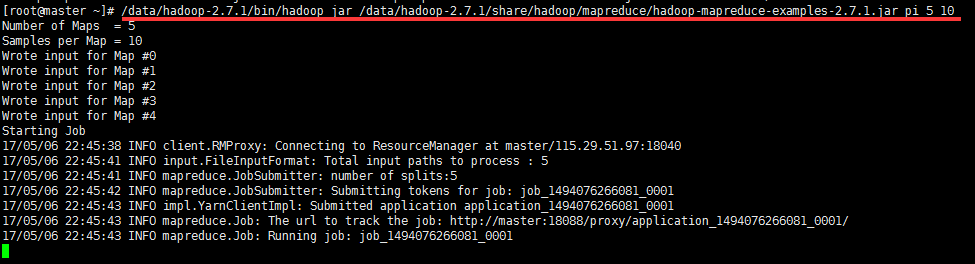
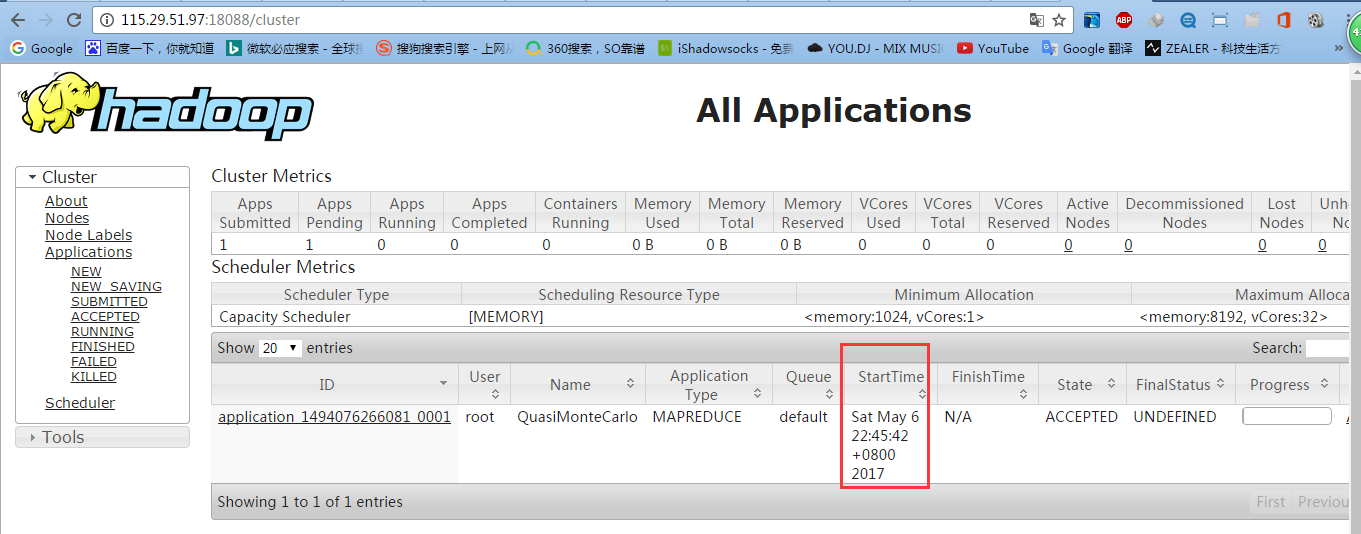
七、配置運行Hadoop中遇見的問題
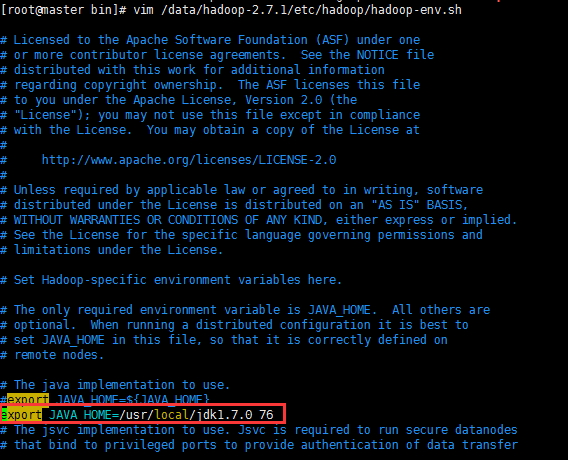
7.1 JAVA_HOME未設置? 啟動的時候報:
則需要/data/hadoop-2.7.1/etc/hadoop/hadoop-env.sh,添加JAVA_HOME路徑
7.2 ncompatible clusterIDs
由於配置Hadoop集群不是一蹴而就的,所以往往伴隨著配置——>運行——>。。。——>配置——>運行的過程,所以DataNode啟動不了時,往往會在查看日誌後,發現以下問題:
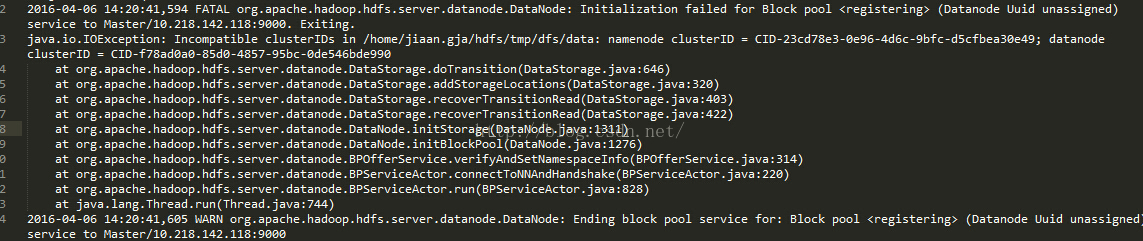
此問題是由於每次啟動Hadoop集群時,會有不同的集群ID,所以需要清理啟動失敗節點上data目錄(比如我創建的/home/jiaan.gja/hdfs/data)中的數據。
7.3 NativeCodeLoader的警告
在測試Hadoop時,細心的人可能看到截圖中的警告信息:


