
在hadoop生態越來越完善的背景下,集群多用戶租用的場景變得越來越普遍,多用戶任務下的資源調度就顯得十分關鍵了。比如,一個公司擁有一個幾十個節點的hadoop集群,a項目組要進行一個計算任務,b項目組要計算一個任務,集群到底先執行哪個任務?如果你需要提交1000個任務呢?這些任務又是如何執行的? ...
在hadoop生態越來越完善的背景下,集群多用戶租用的場景變得越來越普遍,多用戶任務下的資源調度就顯得十分關鍵了。比如,一個公司擁有一個幾十個節點的hadoop集群,a項目組要進行一個計算任務,b項目組要計算一個任務,集群到底先執行哪個任務?如果你需要提交1000個任務呢?這些任務又是如何執行的?
為瞭解決上面的問題,就需要在hadoop集群中引入資源管理和任務調度的框架。這就是——Yarn。
YARN的發展
Yarn在第一代的時候,框架跟hdfs差不多。一個主節點jobtracker,用來分配任務和監控任務運行情況;多個從節點tasktracker,用來執行真正的計算。

這種方式還是有一定的弊端的:
- tasktracker出現故障,會導致整個任務計算失敗。
- jobtracker壓力過大,既要負責全局的任務分配,還需要時刻與tasktracker溝通。
因此,就出現了第二代的YARN。

這種模式主要的特點,就是兩個地方:
jobtracker被分離為兩個角色,一個是resourcemanager,簡稱RM,僅僅負責任務的調度和應用的管理;一個是applicationmaster,簡稱AM,每個應用任務都會創建一個AM,用於申請任務需要的資源並且監控任務運行狀況。
YARN資源調度流程
YARN的資源調度可以看官網提供的圖片:
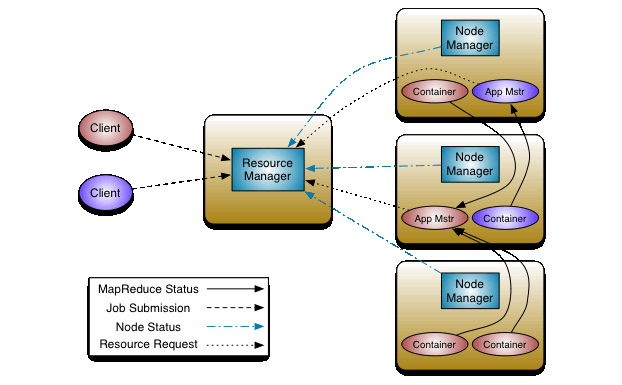
流程大致如下:
- client客戶端向yarn集群(resourcemanager)提交任務
- resourcemanager選擇一個node創建appmaster
- appmaster根據任務向rm申請資源
- rm返回資源申請的結果
- appmaster去對應的node上創建任務需要的資源(container形式,包括記憶體和CPU)
- appmaster負責與nodemanager進行溝通,監控任務運行
- 最後任務運行成功,彙總結果。
其中Resourcemanager裡面一個很重要的東西,就是調度器Scheduler,調度規則可以使用官方提供的,也可以自定義。
官方大概提供了三種模式:
- FIFO,最簡單的先進先出,按照用戶提交任務的順序執行。這種方式最簡單,但是也一大堆問題,比如任務可能獨占資源,導致其他任務餓死等。
- Capacity,採用隊列的概念,任務提交到隊列,隊列可以設置資源的占比,並且支持層級隊列、訪問控制、用戶限制、預定等等高級的玩法。
- Fair share,基於用戶或者應用去平分資源,靈活分配。
capacity和fair share都是採用隊列的模式,隊列內部基本上還是FIFO。並且同級的隊列任務,如果一個隊列是空閑的,那麼另一個隊列任務可以使用資源;如果這個隊列又提交了任務,則會搶占或者等待資源釋放,直到資源到達預定的分配比例。
總的來說,YARN的資源調度還是比較完善的。


