
前言 ConcurrentLinkedQueue是基於鏈接節點的無界線程安全隊列。此隊列按照FIFO(先進先出)原則對元素進行排序。隊列的頭部是隊列中存在時間最長的元素,而隊列的尾部則是最近添加的元素。新的元素總是被插入到隊列的尾部,而隊列的獲取操作(例如poll或peek)則是從隊列頭部開始。 與 ...
前言
ConcurrentLinkedQueue是基於鏈接節點的無界線程安全隊列。此隊列按照FIFO(先進先出)原則對元素進行排序。隊列的頭部是隊列中存在時間最長的元素,而隊列的尾部則是最近添加的元素。新的元素總是被插入到隊列的尾部,而隊列的獲取操作(例如poll或peek)則是從隊列頭部開始。
與傳統的LinkedList不同,ConcurrentLinkedQueue使用了一種高效的非阻塞演算法,被稱為無鎖編程(Lock-Free programming),它通過原子變數和CAS(Compare-And-Swap)操作來保證線程安全,而不是通過傳統的鎖機制。這使得它在高併發場景下具有出色的性能表現。
可以看做一個線程安全的LinkedList,是一個線程安全的無界隊列,但LinkedList是一個雙向鏈表,而ConcurrentLinkedQueue是單向鏈表。
ConcurrentLinkedQueue線程安全在於設置head、tail以及next指針時都用的cas操作,而且node里的item和next變數都是用volatile修飾,保證了多線程下變數的可見性。而ConcurrentLinkedQueue的所有讀操作都是無鎖的,所以可能讀會存在不一致性。
應用場景
如果對隊列加鎖的成本較高則適合使用無鎖的 ConcurrentLinkedQueue 來替代。適合在對性能要求相對較高,同時有多個線程對隊列進行讀寫的場景。
ConcurrentLinkedQueue通過無鎖來做到了更高的併發量,是個高性能的隊列,但是使用場景相對不如阻塞隊列常見,畢竟取數據也要不停的去迴圈,不如阻塞的設計,但是在併發量特別大的情況下,是個不錯的選擇,性能上好很多,而且這個隊列的設計也是特別費力,尤其的使用的改良演算法和對哨兵的處理。
主要方法
ConcurrentLinkedQueue提供了豐富的方法來操作隊列,包括:
offer(E e):將指定的元素插入此隊列的尾部。add(E e):將指定的元素插入此隊列的尾部(與offer方法功能相同,但在失敗時拋出異常)。poll():獲取並移除此隊列的頭部,如果此隊列為空,則返回null。peek():獲取但不移除此隊列的頭部,如果此隊列為空,則返回null。size():返回此隊列中的元素數量。需要註意的是,由於併發的原因,這個方法返回的結果可能並不准確。如果需要在併發環境下獲取準確的元素數量,建議使用java.util.concurrent.atomic包中的原子變數進行計數。isEmpty():檢查此隊列是否為空。與size()方法類似,由於併發的原因,這個方法返回的結果也可能不准確。
需要註意的是,在併發環境下使用size()和isEmpty()方法時需要特別小心,因為它們的結果可能並不准確。如果需要精確的元素數量或空隊列檢測,建議使用額外的同步機制或原子變數來實現。
底層源碼
類的內部類
private static class Node<E> {
// 元素
volatile E item;
// next域
volatile Node<E> next;
/**
* Constructs a new node. Uses relaxed write because item can
* only be seen after publication via casNext.
*/
// 構造函數
Node(E item) {
// 設置item的值
UNSAFE.putObject(this, itemOffset, item);
}
// 比較並替換item值
boolean casItem(E cmp, E val) {
return UNSAFE.compareAndSwapObject(this, itemOffset, cmp, val);
}
void lazySetNext(Node<E> val) {
// 設置next域的值,並不會保證修改對其他線程立即可見
UNSAFE.putOrderedObject(this, nextOffset, val);
}
// 比較並替換next域的值
boolean casNext(Node<E> cmp, Node<E> val) {
return UNSAFE.compareAndSwapObject(this, nextOffset, cmp, val);
}
// Unsafe mechanics
// 反射機制
private static final sun.misc.Unsafe UNSAFE;
// item域的偏移量
private static final long itemOffset;
// next域的偏移量
private static final long nextOffset;
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> k = Node.class;
itemOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("item"));
nextOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("next"));
} catch (Exception e) {
throw new Error(e);
}
}
}
說明: Node類表示鏈表結點,用於存放元素,包含item域和next域,item域表示元素,next域表示下一個結點,其利用反射機制和CAS機制來更新item域和next域,保證原子性。
類的屬性
public class ConcurrentLinkedQueue<E> extends AbstractQueue<E>
implements Queue<E>, java.io.Serializable {
// 版本序列號
private static final long serialVersionUID = 196745693267521676L;
// 反射機制
private static final sun.misc.Unsafe UNSAFE;
// head域的偏移量
private static final long headOffset;
// tail域的偏移量
private static final long tailOffset;
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> k = ConcurrentLinkedQueue.class;
headOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("head"));
tailOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("tail"));
} catch (Exception e) {
throw new Error(e);
}
}
// 頭節點
private transient volatile Node<E> head;
// 尾結點
private transient volatile Node<E> tail;
}
說明: 屬性中包含了head域和tail域,表示鏈表的頭節點和尾結點,同時,ConcurrentLinkedQueue也使用了反射機制和CAS機制來更新頭節點和尾結點,保證原子性。
類的構造函數
- ConcurrentLinkedQueue()
public ConcurrentLinkedQueue() {
// 初始化頭節點與尾結點
head = tail = new Node<E>(null);
}
說明: 該構造函數用於創建一個最初為空的 ConcurrentLinkedQueue,頭節點與尾結點指向同一個結點,該結點的item域為null,next域也為null。
- ConcurrentLinkedQueue(Collection<? extends E>)
public ConcurrentLinkedQueue(Collection<? extends E> c) {
Node<E> h = null, t = null;
for (E e : c) { // 遍歷c集合
// 保證元素不為空
checkNotNull(e);
// 新生一個結點
Node<E> newNode = new Node<E>(e);
if (h == null) // 頭節點為null
// 賦值頭節點與尾結點
h = t = newNode;
else {
// 直接頭節點的next域
t.lazySetNext(newNode);
// 重新賦值頭節點
t = newNode;
}
}
if (h == null) // 頭節點為null
// 新生頭節點與尾結點
h = t = new Node<E>(null);
// 賦值頭節點
head = h;
// 賦值尾結點
tail = t;
}
說明: 該構造函數用於創建一個最初包含給定 collection 元素的 ConcurrentLinkedQueue,按照此 collection 迭代器的遍歷順序來添加元素。
核心函數分析
offer函數
public boolean offer(E e) {
// 檢查e是不是null,是的話拋出NullPointerException異常。
checkNotNull(e);
// 創建新的節點
final Node<E> newNode = new Node<E>(e);
// 將“新的節點”添加到鏈表的末尾。
for (Node<E> t = tail, p = t;;) {//這個for迴圈是個死迴圈,增加了兩個指針p,t。
Node<E> q = p.next;
// 情況1:q為空,p就是尾節點,新節點插入
if (q == null) {
// CAS操作:如果“p的下一個節點為null”(即p為尾節點),則設置p的下一個節點為newNode。
// 如果該CAS操作成功的話,則比較“p和t”(若p不等於t,則設置newNode為新的尾節點),然後返回true。
// 如果該CAS操作失敗,這意味著“其它線程對尾節點進行了修改”,則重新迴圈。
if (p.casNext(null, newNode)) {
if (p != t) // hop two nodes at a time
casTail(t, newNode); // Failure is OK.
return true;
}
}
// 情況2:p和q相等
else if (p == q)
p = (t != (t = tail)) ? t : head;
// 情況3:其它\\
//這裡是移動p指針,意思就是此時如果p不是最後一個元素則把p指針指向tail,否則指向q,也就是指向p.next元素。
else
p = (p != t && t != (t = tail)) ? t : q;
}
}
說明: offer函數用於將指定元素插入此隊列的尾部。下麵模擬offer函數的操作,隊列狀態的變化(假設單線程添加元素,連續添加10、20兩個元素)。
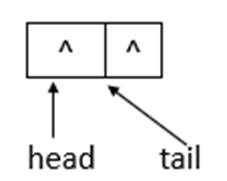
若ConcurrentLinkedQueue的初始狀態如上圖所示,即隊列為空。單線程添加元素,此時,添加元素10,則狀態如下所示
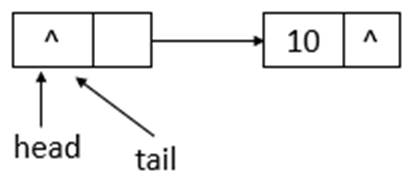
如上圖所示,添加元素10後,tail沒有變化,還是指向之前的結點,繼續添加元素20,則狀態如下所示
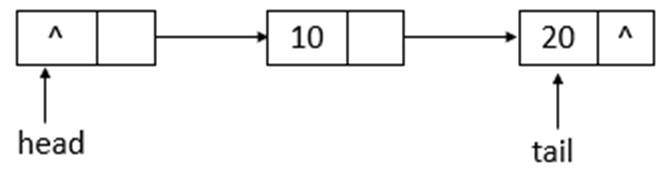
如上圖所示,添加元素20後,tail指向了最新添加的結點。
poll函數
public E poll() {
restartFromHead:
for (;;) { // 無限迴圈
for (Node<E> h = head, p = h, q;;) { // 保存頭節點
// item項
E item = p.item;
if (item != null && p.casItem(item, null)) { // item不為null並且比較並替換item成功
// Successful CAS is the linearization point
// for item to be removed from this queue.
if (p != h) // p不等於h // hop two nodes at a time
// 更新頭節點
updateHead(h, ((q = p.next) != null) ? q : p);
// 返回item
return item;
}
else if ((q = p.next) == null) { // q結點為null
// 更新頭節點
updateHead(h, p);
return null;
}
else if (p == q) // p等於q
// 繼續迴圈
continue restartFromHead;
else
// p賦值為q
p = q;
}
}
}
說明: 此函數用於獲取並移除此隊列的頭,如果此隊列為空,則返回null。下麵模擬poll函數的操作,隊列狀態的變化(假設單線程操作,狀態為之前offer10、20後的狀態,poll兩次)。
隊列初始狀態如上圖所示,在poll操作後,隊列的狀態如下圖所示
如上圖可知,poll操作後,head改變了,並且head所指向的結點的item變為了null。再進行一次poll操作,隊列的狀態如下圖所示。
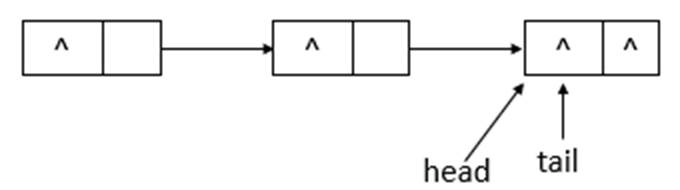
如上圖可知,poll操作後,head結點沒有變化,只是指示的結點的item域變成了null。
remove函數
public boolean remove(Object o) {
// 元素為null,返回
if (o == null) return false;
Node<E> pred = null;
for (Node<E> p = first(); p != null; p = succ(p)) { // 獲取第一個存活的結點
// 第一個存活結點的item值
E item = p.item;
if (item != null &&
o.equals(item) &&
p.casItem(item, null)) { // 找到item相等的結點,並且將該結點的item設置為null
// p的後繼結點
Node<E> next = succ(p);
if (pred != null && next != null) // pred不為null並且next不為null
// 比較並替換next域
pred.casNext(p, next);
return true;
}
// pred賦值為p
pred = p;
}
return false;
}
說明: 此函數用於從隊列中移除指定元素的單個實例(如果存在)。其中,會調用到first函數和succ函數,first函數的源碼如下
Node<E> first() {
restartFromHead:
for (;;) { // 無限迴圈,確保成功
for (Node<E> h = head, p = h, q;;) {
// p結點的item域是否為null
boolean hasItem = (p.item != null);
if (hasItem || (q = p.next) == null) { // item不為null或者next域為null
// 更新頭節點
updateHead(h, p);
// 返回結點
return hasItem ? p : null;
}
else if (p == q) // p等於q
// 繼續從頭節點開始
continue restartFromHead;
else
// p賦值為q
p = q;
}
}
}
說明: first函數用於找到鏈表中第一個存活的結點。succ函數源碼如下
final Node<E> succ(Node<E> p) {
// p結點的next域
Node<E> next = p.next;
// 如果next域為自身,則返回頭節點,否則,返回next
return (p == next) ? head : next;
}
說明: succ用於獲取結點的下一個結點。如果結點的next域指向自身,則返回head頭節點,否則,返回next結點。下麵模擬remove函數的操作,隊列狀態的變化(假設單線程操作,狀態為之前offer10、20後的狀態,執行remove(10)、remove(20)操作)。
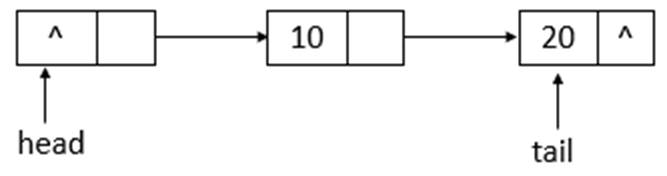
如上圖所示,為ConcurrentLinkedQueue的初始狀態,remove(10)後的狀態如下圖所示
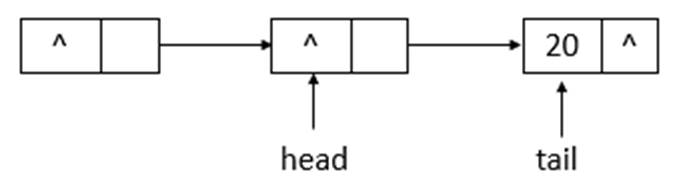
如上圖所示,當執行remove(10)後,head指向了head結點之前指向的結點的下一個結點,並且head結點的item域置為null。繼續執行remove(20),狀態如下圖所示
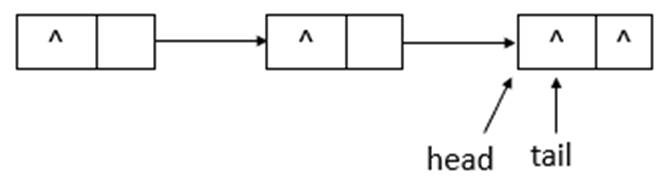
如上圖所示,執行remove(20)後,head與tail指向同一個結點,item域為null。
size函數
public int size() {
// 計數
int count = 0;
for (Node<E> p = first(); p != null; p = succ(p)) // 從第一個存活的結點開始往後遍歷
if (p.item != null) // 結點的item域不為null
// Collection.size() spec says to max out
if (++count == Integer.MAX_VALUE) // 增加計數,若達到最大值,則跳出迴圈
break;
// 返回大小
return count;
}
說明: 此函數用於返回ConcurrenLinkedQueue的大小,從第一個存活的結點(first)開始,往後遍歷鏈表,當結點的item域不為null時,增加計數,之後返回大小。
HOPS(延遲更新的策略)的設計
通過上面對offer和poll方法的分析,我們發現tail和head是延遲更新的,兩者更新觸發時機為:
-
tail更新觸發時機:當tail指向的節點的下一個節點不為null的時候,會執行定位隊列真正的隊尾節點的操作,找到隊尾節點後完成插入之後才會通過casTail進行tail更新;當tail指向的節點的下一個節點為null的時候,只插入節點不更新tail。
-
head更新觸發時機:當head指向的節點的item域為null的時候,會執行定位隊列真正的隊頭節點的操作,找到隊頭節點後完成刪除之後才會通過updateHead進行head更新;當head指向的節點的item域不為null的時候,只刪除節點不更新head。
從上面更新時的狀態圖可以看出,head和tail的更新是“跳著的”即中間總是間隔了一個。那麼這樣設計的意圖是什麼呢?
如果讓tail永遠作為隊列的隊尾節點,實現的代碼量會更少,而且邏輯更易懂。但是,這樣做有一個缺點,如果大量的入隊操作,每次都要執行CAS進行tail的更新,彙總起來對性能也會是大大的損耗。如果能減少CAS更新的操作,無疑可以大大提升入隊的操作效率,所以doug lea大師每間隔1次(tail和隊尾節點的距離為1)進行才利用CAS更新tail。對head的更新也是同樣的道理,雖然,這樣設計會多出在迴圈中定位隊尾節點,但總體來說讀的操作效率要遠遠高於寫的性能,因此,多出來的在迴圈中定位尾節點的操作的性能損耗相對而言是很小的。
關於作者
來自一線程式員Seven的探索與實踐,持續學習迭代中~
本文已收錄於我的個人博客:https://www.seven97.top
公眾號:seven97,歡迎關註~
本文來自線上網站:seven的菜鳥成長之路,作者:seven,轉載請註明原文鏈接:www.seven97.top


