
Delete、Drop 和 Truncate delete、truncate 僅僅刪除表裡面的數據,drop會把表的結構也刪除 delete 是 DML 語句,操作完成後,可以回滾,truncate 和 drop 是 DDL 語句,刪除之後立即生效,不能回滾 執行效率:drop > truncate ...
Delete、Drop 和 Truncate
- delete、truncate 僅僅刪除表裡面的數據,drop會把表的結構也刪除
- delete 是 DML 語句,操作完成後,可以回滾,truncate 和 drop 是 DDL 語句,刪除之後立即生效,不能回滾
- 執行效率:drop > truncate > delete
MyISAM 與 InnoDB
- InnoDB 支持事務,MyISAM 不支持
- InnoDB 支持外鍵,MyISAM 不支持
- InnoDB 是聚集索引,數據文件是和索引綁定一起的
- MyISAM 是非聚簇索引,索引和數據文件是分離的,索引保存的是數據的指針
- InnoDB 不保存表的具體行數,執行 select count(*) from table 時需要全表掃描
- MyISAM 用一個變數保存整個表的行數,執行上述語句時只需要讀出改變數即可,速度很快
- InnoDB 支持表、行(預設)級鎖,MyISAM 支持表級鎖
Join 語句
left join、right join、inner join 的區別:
left join(左連接):
- 返回包括左表中的所有記錄和右表中聯結欄位相等的記錄
- 左表是驅動表,右表是被驅動表
right join(右連接):
- 返回包括右表中的所有記錄和左表中聯結欄位相等的記錄
- 右表是驅動表,左表是被驅動表
innner join(等值連接):
- 只返回兩個表中聯結欄位相等的行
- 數據量比較小的表作為驅動表,大表作為被驅動表
join 查詢在有索引條件下:
- 驅動表有索引不會使用到索引
- 被驅動表建立索引會使用到索引、
所以在以小表驅動大表的情況下,給大表建立索引會大大提高查詢效率
Join 原理:
Simple Nested-Loop:
- 驅動表中的每一條記錄與被驅動表中的記錄進行比較判斷(笛卡爾積)
- 對於兩表聯結來說,驅動表只會被訪問一遍,但驅動表卻要被訪問到好多遍
Index Nested-Loop:
- 基於索引進行連接的演算法
- 他要求被動表驅動表上有索引,可以通過索引來加速查詢
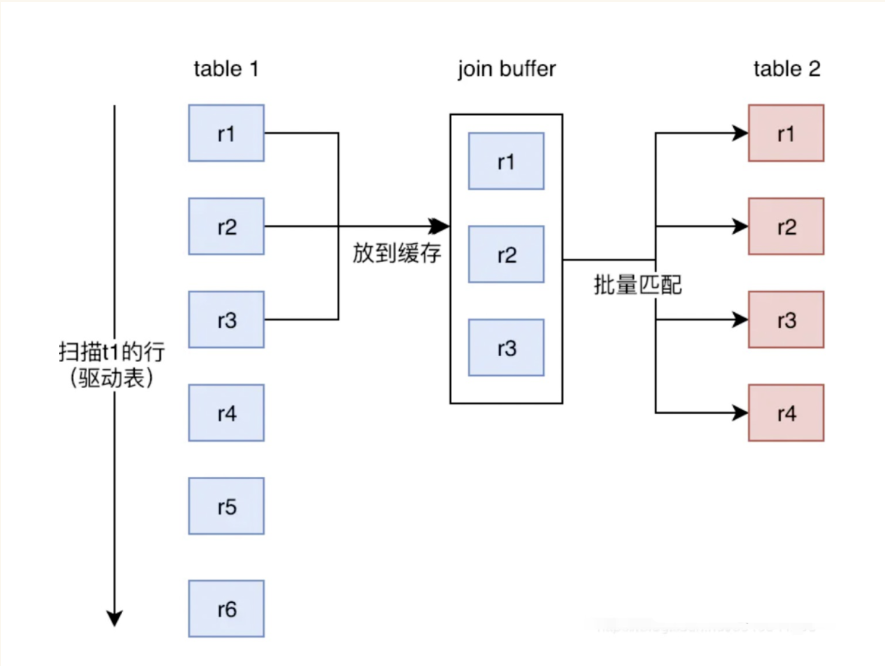
Block Nested-Loop:
- 它使用 Join Buffer 來減少內部迴圈讀取表的次數
- Join Buffer 用以緩存聯接需要的列
選擇 Join 演算法優先順序:
- Index Nested-LoopJoin > Block Nested-Loop Join > Simple Nested-Loop Join
當不使用 Index Nested-Loop Join 的時候,預設使用 Block Nested-Loop Join
分頁查詢優化
select * from table
where
type = 2
and level = 9
order by id asc
limit 190289,10;
延遲關聯:
通過 where 條件提取出主鍵,再將該表與原數據表關聯,通過主鍵 id 提取數據行,而不是通過原來的二級索引提取數據行
select a.* from table a, ( select id from table where type = 2 and level =9 order by id asc limit 190289,10 ) b where a.id = b.id;書簽方式:
找到 limit 第一個參數對應的主鍵值, 在根據這個主鍵值再去過濾並 limit
select * from table where id > ( select * from table where type = 2 and level = 9 order by id asc limit 190289, 1 ) limit 10;


