
解鎖 SQL Server 2022的時間序列數據功能 SQL Server2022在處理時間序列數據時,SQL Server 提供了一些優化和功能,比如 DATE_BUCKET 函數、視窗函數(如 FIRST_VALUE 和 LAST_VALUE)以及其他時間日期函數,以便更高效地處理時間序列數據 ...
解鎖 SQL Server 2022的時間序列數據功能
SQL Server2022在處理時間序列數據時,SQL Server 提供了一些優化和功能,比如 DATE_BUCKET 函數、視窗函數(如 FIRST_VALUE 和 LAST_VALUE)以及其他時間日期函數,以便更高效地處理時間序列數據。
GENERATE_SERIES函數
SQL Server 2022 引入了一個新的函數 GENERATE_SERIES,它用於生成一個整數序列。
這個函數非常有用,可以在查詢中生成一系列連續的數值,而無需創建臨時表或迴圈。
GENERATE_SERIES ( start, stop [, step ] ) start:序列的起始值。 stop:序列的終止值。 step:每次遞增或遞減的步長(可選)。如果省略,預設為1。
使用場景包括快速生成一系列數據用於測試或填充表或者結合日期函數生成一系列日期值。
示例
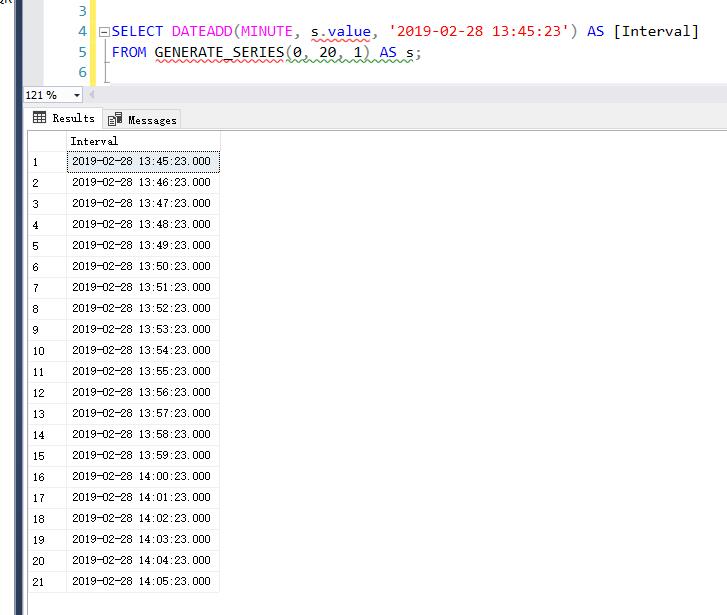
生成的結果集將包含 20 行,每行顯示從 '2019-02-28 13:45:23' 開始,按分鐘遞增的時間。
SELECT DATEADD(MINUTE, s.value, '2019-02-28 13:45:23') AS [Interval] FROM GENERATE_SERIES(0, 20, 1) AS s;
對於每一個 s.value,DATEADD 函數將基準日期時間增加相應的分鐘數。
DATE_BUCKET函數
SQL Server 2022 引入了一個新的函數 DATE_BUCKET,用於將日期時間值按指定的時間間隔分組(即分桶)。
這個函數在時間序列分析、數據聚合和分段分析等場景中非常有用。
DATE_BUCKET ( bucket_width, datepart, startdate, date ) bucket_width:時間間隔的大小,可以是整數。 datepart:時間間隔的類型,例如 year, month, day, hour, minute, second 等。 startdate:起始日期,用於定義時間間隔的起點。 date:需要分組的日期時間值。
使用 DATE_BUCKET 函數時,指定的時間間隔單位(如 YEAR、QUARTER、MONTH、WEEK 等)以及起始日期(origin)決定了日期時間值被分配到哪個存儲桶。這種方式有助於理解時間間隔的計算是如何基於起始日期來進行的。
示例
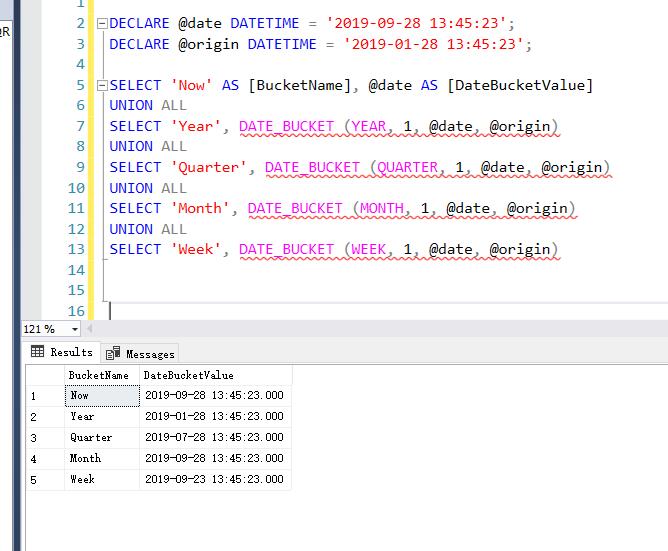
DECLARE @date DATETIME = '2019-09-28 13:45:23'; DECLARE @origin DATETIME = '2019-01-28 13:45:23'; SELECT 'Now' AS [BucketName], @date AS [DateBucketValue] UNION ALL SELECT 'Year', DATE_BUCKET (YEAR, 1, @date, @origin) UNION ALL SELECT 'Quarter', DATE_BUCKET (QUARTER, 1, @date, @origin) UNION ALL SELECT 'Month', DATE_BUCKET (MONTH, 1, @date, @origin) UNION ALL SELECT 'Week', DATE_BUCKET (WEEK, 1, @date, @origin) --假如日期時間值如下: Now: 2019-09-28 13:45:23 --按年分組: DATE_BUCKET(YEAR, 1, @date, @origin) 從 2019-01-28 13:45:23 開始的年度存儲桶,2019-09-28 落入 2019-01-28 至 2020-01-28 的存儲桶中。 結果:2019-01-28 13:45:23 --按季度分組: DATE_BUCKET(QUARTER, 1, @date, @origin) 從 2019-01-28 13:45:23 開始的季度存儲桶,每個季度 3 個月。 2019-09-28 落入第三個季度存儲桶(即從 2019-07-28 13:45:23 到 2019-10-28 13:45:23)。 結果:2019-07-28 13:45:23 --按月分組: DATE_BUCKET(MONTH, 1, @date, @origin) 從 2019-01-28 13:45:23 開始的月度存儲桶,每個月一個存儲桶。 2019-09-28 落入第九個存儲桶(即從 2019-09-28 13:45:23 到 2019-10-28 13:45:23)。 結果:2019-09-28 13:45:23 --按周分組: DATE_BUCKET(WEEK, 1, @date, @origin) 從 2019-01-28 13:45:23 開始的每周存儲桶。 2019-09-28 落入從 2019-09-23 13:45:23 到 2019-09-30 13:45:23 的存儲桶。 結果:2019-09-23 13:45:23
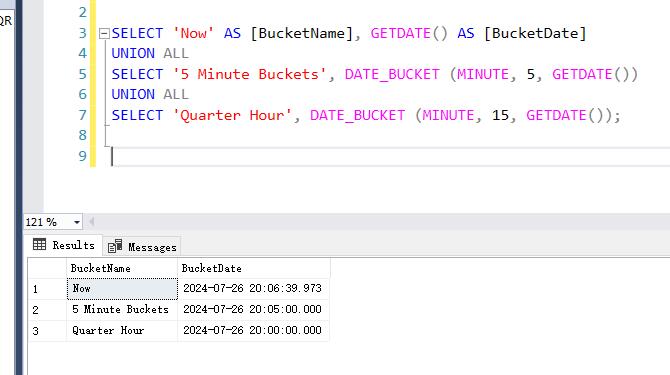
SELECT 'Now' AS [BucketName], GETDATE() AS [BucketDate] UNION ALL SELECT '5 Minute Buckets', DATE_BUCKET (MINUTE, 5, GETDATE()) UNION ALL SELECT 'Quarter Hour', DATE_BUCKET (MINUTE, 15, GETDATE()); Now: BucketName: Now BucketDate: 2024-07-26 16:14:11.030 這是當前時間,即 GETDATE() 返回的系統當前時間。 5 Minute Buckets: BucketName: 5 Minute Buckets BucketDate: 2024-07-26 16:10:00.000 這是將當前時間按 5 分鐘間隔進行分組的結果。DATE_BUCKET(MINUTE, 5, GETDATE()) 返回當前時間所在的 5 分鐘區間的起始時間。在這個例子中,16:14:11 落在 16:10:00 到 16:15:00 之間,因此返回 16:10:00。 Quarter Hour: BucketName: Quarter Hour BucketDate: 2024-07-26 16:00:00.000 這是將當前時間按 15 分鐘間隔進行分組的結果。DATE_BUCKET(MINUTE, 15, GETDATE()) 返回當前時間所在的 15 分鐘區間的起始時間。在這個例子中,16:14:11 落在 16:00:00 到 16:15:00 之間,因此返回 16:00:00。
更多實際場景示例
按自定義起始日期分組
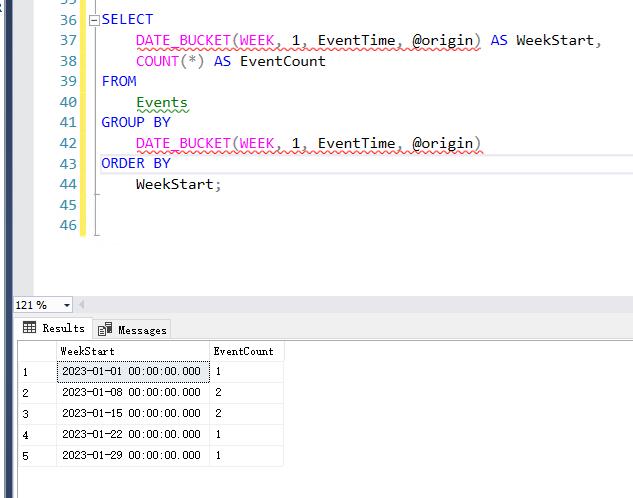
假設我們有一系列事件時間 EventTime,希望從'2023-01-01'日期開始,每周進行分組統計事件數量。
--創建表 Events: USE [testdb] GO CREATE TABLE Events ( EventID INT PRIMARY KEY, EventTime DATETIME ); INSERT INTO Events (EventID, EventTime) VALUES (1, '2023-01-02 14:30:00'), (2, '2023-01-08 09:15:00'), (3, '2023-01-09 17:45:00'), (4, '2023-01-15 12:00:00'), (5, '2023-01-16 08:00:00'), (6, '2023-01-22 19:30:00'), (7, '2023-01-29 11:00:00'); --從'2023-01-01'起始日期開始,每周進行分組統計事件數量。 DECLARE @origin DATETIME = '2023-01-01'; SELECT DATE_BUCKET(WEEK, 1, EventTime, @origin) AS WeekStart, COUNT(*) AS EventCount FROM Events GROUP BY DATE_BUCKET(WEEK, 1, EventTime, @origin) ORDER BY WeekStart;
按自定義時間間隔分組
假設我們有一個感測器數據表 SensorReadings
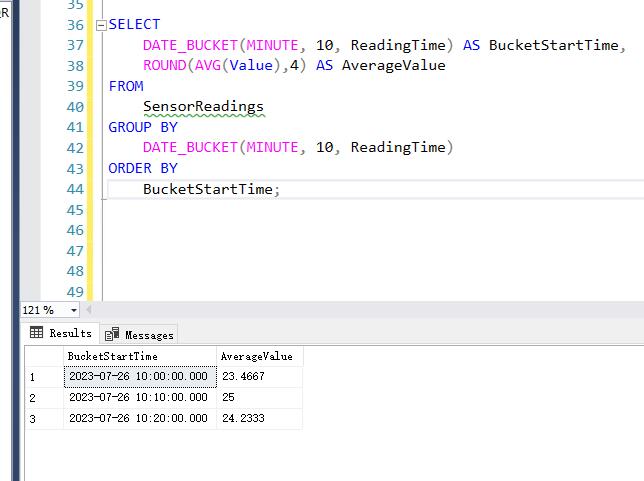
USE [testdb] GO CREATE TABLE SensorReadings ( ReadingID INT PRIMARY KEY, --唯一標識 ReadingTime DATETIME, --讀數的時間 Value FLOAT --讀數的值 ); INSERT INTO SensorReadings (ReadingID, ReadingTime, Value) VALUES (1, '2023-07-26 10:03:00', 23.5), (2, '2023-07-26 10:05:00', 24.1), (3, '2023-07-26 10:09:00', 22.8), (4, '2023-07-26 10:15:00', 25.0), (5, '2023-07-26 10:20:00', 23.9), (6, '2023-07-26 10:27:00', 24.3), (7, '2023-07-26 10:29:00', 24.5); --我們希望按 10 分鐘的間隔將數據分組,並計算每個間隔的平均讀數值。 SELECT DATE_BUCKET(MINUTE, 10, ReadingTime) AS BucketStartTime, ROUND(AVG(Value),4) AS AverageValue FROM SensorReadings GROUP BY DATE_BUCKET(MINUTE, 10, ReadingTime) ORDER BY BucketStartTime;
如果是傳統方法需要使用公用表表達式CTE才能完成這個需求
--查詢:按 10 分鐘間隔分組並計算平均值 WITH TimeIntervals AS ( SELECT ReadingID, ReadingTime, Value, --將分鐘數歸約到最近的 10 分鐘的整數倍, 從2010年到現在有多少個10分鐘區間 DATEADD(MINUTE, (DATEDIFF(MINUTE, '2000-01-01', ReadingTime) / 10) * 10, '2010-01-01') AS BucketStartTime FROM SensorReadings ) SELECT BucketStartTime, ROUND(AVG(Value), 4) AS AverageValue FROM TimeIntervals GROUP BY BucketStartTime ORDER BY BucketStartTime;
WITH TimeIntervals AS (...)公共表表達式(CTE)用於計算每條記錄的 BucketStartTime。
DATEDIFF(MINUTE, '2000-01-01', ReadingTime) / 10 計算 ReadingTime 到基準時間 '2000-01-01' 的分鐘數,然後除以 10,得到當前時間點所在的 10 分鐘區間的索引。
DATEADD(MINUTE, ..., '2000-01-01') 將該索引轉換回具體的時間點,即區間的起始時間。
查詢主部分:
選擇 BucketStartTime 和相應區間內讀數值的平均值。
使用 GROUP BY 按 BucketStartTime 分組,並計算每個分組的平均值。
ORDER BY 用於按照時間順序排列結果。
FIRST_VALUE 和 LAST_VALUE 視窗函數
在 之前版本的SQL Server 中,FIRST_VALUE 和 LAST_VALUE 是視窗函數,用於在一個分區或視窗中返回第一個或最後一個值。
SQL Server 2022 引入了新的選項 IGNORE NULLS 和 RESPECT NULLS 來處理空值(NULL)的方式,從而增強了這些函數的功能。
基本語法
FIRST_VALUE 返回指定視窗或分區中按指定順序的第一個值。 FIRST_VALUE ( [scalar_expression ] ) OVER ( [ partition_by_clause ] order_by_clause [ rows_range_clause ] ) LAST_VALUE 返回指定視窗或分區中按指定順序的最後一個值。 LAST_VALUE ( [scalar_expression ] ) OVER ( [ partition_by_clause ] order_by_clause [ rows_range_clause ] ) 新功能:IGNORE NULLS 和 RESPECT NULLS IGNORE NULLS: 忽略分區或視窗中的 NULL 值。 RESPECT NULLS: 預設行為,包含分區或視窗中的 NULL 值。
示例
假設我們有一個表 MachineTelemetry,包含以下數據:
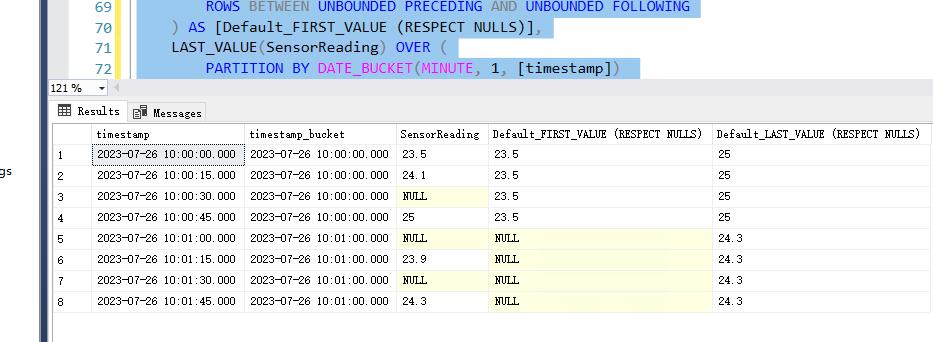
CREATE TABLE MachineTelemetry ( [timestamp] DATETIME, SensorReading FLOAT ); INSERT INTO MachineTelemetry ([timestamp], SensorReading) VALUES ('2023-07-26 10:00:00', 23.5), ('2023-07-26 10:00:15', 24.1), ('2023-07-26 10:00:30', NULL), ('2023-07-26 10:00:45', 25.0), ('2023-07-26 10:01:00', NULL), ('2023-07-26 10:01:15', 23.9), ('2023-07-26 10:01:30', NULL), ('2023-07-26 10:01:45', 24.3);
預設行為(包含 NULL 值)
--使用 FIRST_VALUE 和 LAST_VALUE 進行差距分析 --預設行為(包含 NULL 值) SELECT [timestamp], DATE_BUCKET(MINUTE, 1, [timestamp]) AS [timestamp_bucket], SensorReading, FIRST_VALUE(SensorReading) OVER ( PARTITION BY DATE_BUCKET(MINUTE, 1, [timestamp]) ORDER BY [timestamp] ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING ) AS [Default_FIRST_VALUE (RESPECT NULLS)], LAST_VALUE(SensorReading) OVER ( PARTITION BY DATE_BUCKET(MINUTE, 1, [timestamp]) ORDER BY [timestamp] ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING ) AS [Default_LAST_VALUE (RESPECT NULLS)] FROM MachineTelemetry ORDER BY [timestamp];
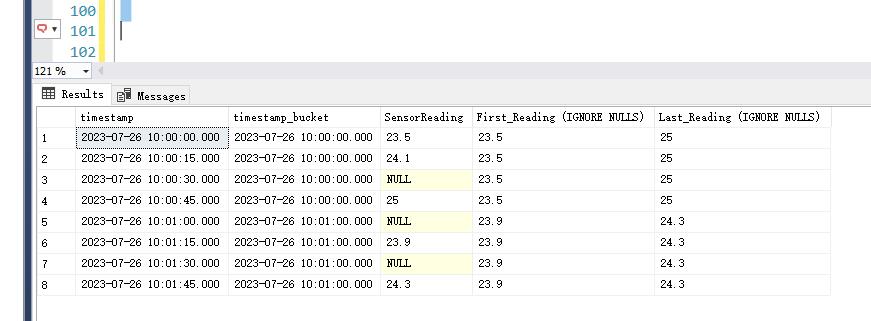
忽略 NULL 值
--忽略 NULL 值 SELECT [timestamp], DATE_BUCKET(MINUTE, 1, [timestamp]) AS [timestamp_bucket], SensorReading, FIRST_VALUE(SensorReading) IGNORE NULLS OVER ( PARTITION BY DATE_BUCKET(MINUTE, 1, [timestamp]) ORDER BY [timestamp] ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING ) AS [First_Reading (IGNORE NULLS)], LAST_VALUE(SensorReading) IGNORE NULLS OVER ( PARTITION BY DATE_BUCKET(MINUTE, 1, [timestamp]) ORDER BY [timestamp] ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING ) AS [Last_Reading (IGNORE NULLS)] FROM MachineTelemetry ORDER BY [timestamp];
總結
實際上,對於時間序列我們一般使用專業的時間序列資料庫,例如InfluxDB 。
它使用 TSM(Time-Structured Merge Tree)作為存儲引擎稱,這是 LSM 樹的一種變體,專門優化用於時間序列數據的寫入和查詢性能。
另外,SQL Server 的時間序列功能是使用行存儲引擎(Row Store)作為其存儲引擎,這意味著數據是按行進行存儲和處理的。
在大部分場景下麵,如果性能不是要求非常高,其實SQL Server 存儲時間序列數據性能是完全足夠的,而且額外使用InfluxDB資料庫需要維護多一個技術棧,對運維要求更加高。
特別是現在追求資料庫一體化的趨勢背景下,無論是時間序列數據,向量數據,地理數據,json數據都最好在一個資料庫里全部滿足,減輕運維負擔,復用技術棧,減少重覆建設成本是比較好的解決方案。
參考文章
https://sqlbits.com/sessions/event2024/Time_Series_with_SQL_Server_2022
https://www.microsoft.com/en-us/sql-server/blog/2023/01/12/working-with-time-series-data-in-sql-server-2022-and-azure-sql/
https://www.mssqltips.com/sqlservertip/6232/load-time-series-data-with-sql-server/
本文版權歸作者所有,未經作者同意不得轉載。


