
上次向大家分享了論文圖譜項目Awesome-Graphs的介紹文章,這次我們就拿圖計算系統的奠基文章Pregel開篇,沿著論文圖譜的主線,對圖計算系統的論文內容進行解讀。 ...
Pregel論文:《Pregel: A System for Large-Scale Graph Processing》
上次向大家分享了論文圖譜項目Awesome-Graphs的介紹文章《論文圖譜當如是:Awesome-Graphs用200篇圖系統論文打個樣》,這次我們就拿圖計算系統的奠基文章Pregel開篇,沿著論文圖譜的主線,對圖計算系統的論文內容進行解讀,下篇預報Differential dataflow。
對圖計算技術感興趣的同學可以多做瞭解,也非常歡迎大家關註和參與論文圖譜的開源項目:
- Awesome-Graphs:https://github.com/TuGraph-family/Awesome-Graphs
- OSGraph:https://github.com/TuGraph-family/OSGraph
提前感謝給項目點Star的小伙伴,接下來我們直接進入正文!
摘要
使用Pregel計算模型編寫的程式,包含一系列的迭代。在每個迭代中,圖的點可以接收上一個迭代發送的消息,也可以給其他的點發送消息,同時可以更新自身和出邊的狀態,甚至可以修改圖的拓撲結構。這種以點為中心的計算方式可以靈活的表示大量的圖演算法。
1. 介紹
大規模圖處理面臨的挑戰:
- 圖演算法的記憶體訪問局部性較差。
- 單個點上的計算量較少。
- 執行過程中並行度改變帶來的問題。
- 分散式計算過程的機器故障問題。
大規模圖演算法的常見實現方式:
- 為特定的圖定製的分散式實現【通用型差】
- 基於現有的分散式計算平臺【如MR,性能、易用性不足】
- 使用單機圖演算法庫【如BGL、LEDA、NetworkX、JDSL、GraphBase、FGL,限制了圖的規模】
- 使用已有的圖計算系統【如Parallel BGL、CGMgraph,缺少容錯機制】
Pregel計算系統的設計靈感來源於Valiant的BSP模型:
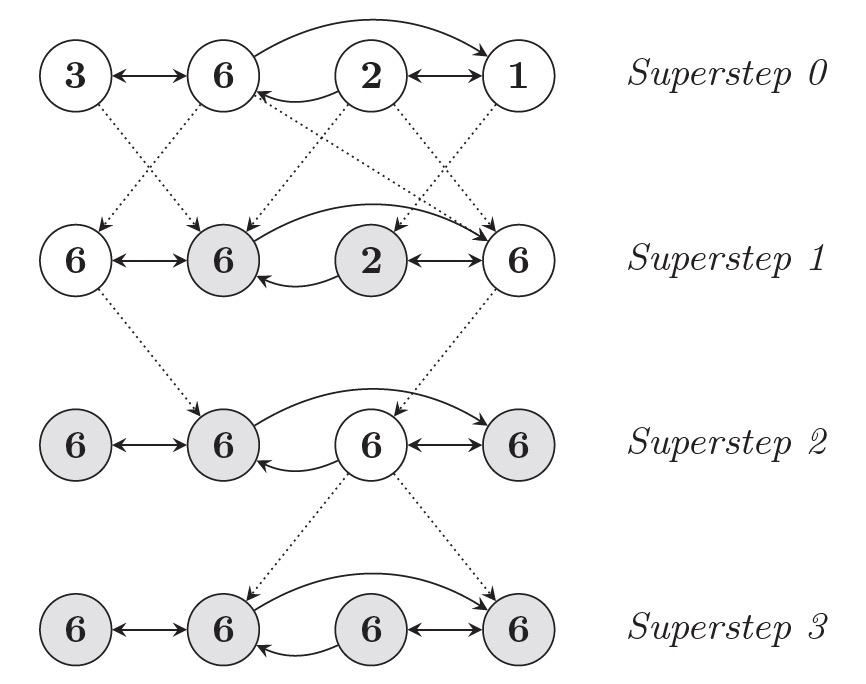
- 計算是由一系列的迭代組成,這些迭代被稱為超步(Superstep)。
- 每次超步框架都會並行地在點上執行用戶的UDF,描述了點V在超步S的行為。
- UDF內可以讀取S-1超步發送給點V的消息,並將新的消息發送給S+1超步的點。
- UDF內可以修改點V以及其出邊的狀態。
- 通常消息是沿著點的出邊方向進行發送的,但也可以發送給指定ID對應的點。
2. 模型
輸入
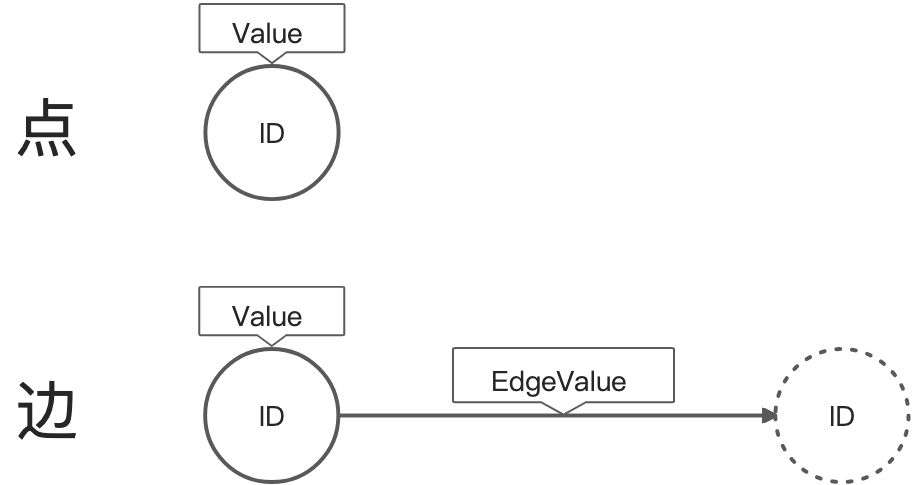
Pregel計算模型的輸入是一個有向圖:
- 點使用string類型的ID進行區分,並有一個可修改的用戶自定義類型value。
- 有向邊與源點關聯,包含可修改的用戶自定義類型value和目標點ID。
計算
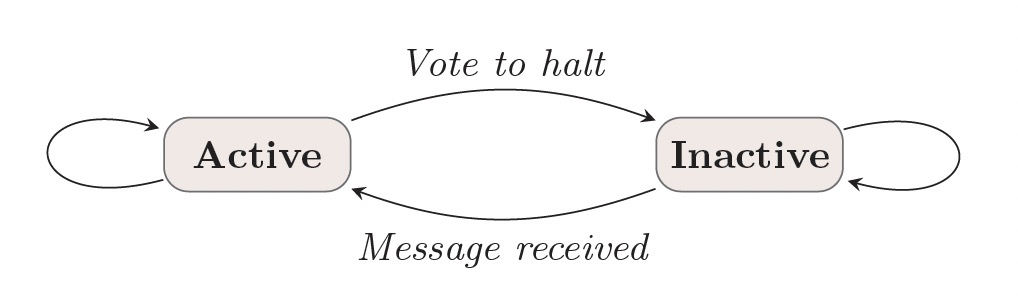
Pregel計算模型運行一系列超步直到計算結束,超步之間通過全部同步點(Barrier)進行分割。每個超步中點上的計算都是並行的,當所有的點都是inactive狀態且沒有消息傳遞時,計算終止。
輸出
Pregel計算模型的輸出是所有點輸出值的集合,通常是和輸入圖同構的有向圖。但這不是絕對的,因為計算過程中可以對點/邊進行新增和刪除操作。
討論
Pregel使用消息傳遞模型,而非遠程讀取或者其他類似共用記憶體的方案:
- 消息傳遞具備足夠的表達能力,而不必非要使用遠程讀取的方式。
- 遠程讀取的延遲很高,使用非同步+批量的消息傳遞方式,可以降低這個延遲。(蘊含push語義)
使用鏈式MR實現圖演算法的性能問題:
- Pregel將點/邊保存在執行計算的機器上,僅使用網路傳遞信息。MR的實現方式需要將圖狀態從一個stage轉換到另一個stage,提高了通信和序列化的開銷。
- 一連串的MR作業的協調增加了圖計算任務的複雜度,而使用Pregel的超步可以避免該問題。
3. API
template <typename VertexValue, typename EdgeValue, typename MessageValue>
class Vertex {
public:
virtual void Compute(MessageIterator* msgs) = 0;
const string& vertex_id() const;
int64 superstep() const;
const VertexValue& GetValue();
VertexValue* MutableValue();
OutEdgeIterator GetOutEdgeIterator();
void SendMessageTo(const string& dest_vertex, const MessageValue& message);
void VoteToHalt();
};
- Vertex:Pregel程式繼承於Vertex類,模版參數對應點值、邊值和消息的類型。
- Compute:每次超步在每個點上執行的UDF。
- GetValue:獲取點的值。
- MutableValue:修改點的值。
- GetOutEdgeIterator:獲取出邊的迭代器,可以對出邊的值進行讀取和修改。
- 點的值和出邊是跨超步持久化的。
3.1 消息傳遞
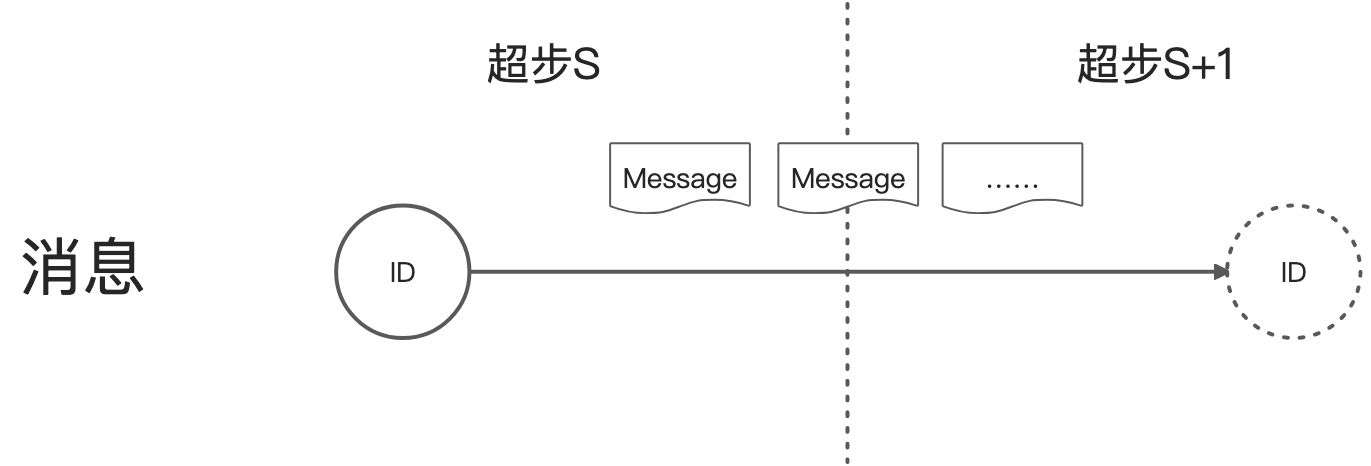
- 點可以發送任意多的消息。
- 所有在超步S發送給點V的消息,可以在超步S+1時使用迭代器獲取。
- 消息順序不做保證,但能保證一點會被傳輸且不會去重。
- 接收消息的點不一定是鄰居點,即消息不一定沿著出邊發送。
3.2 連接器(Combiner)
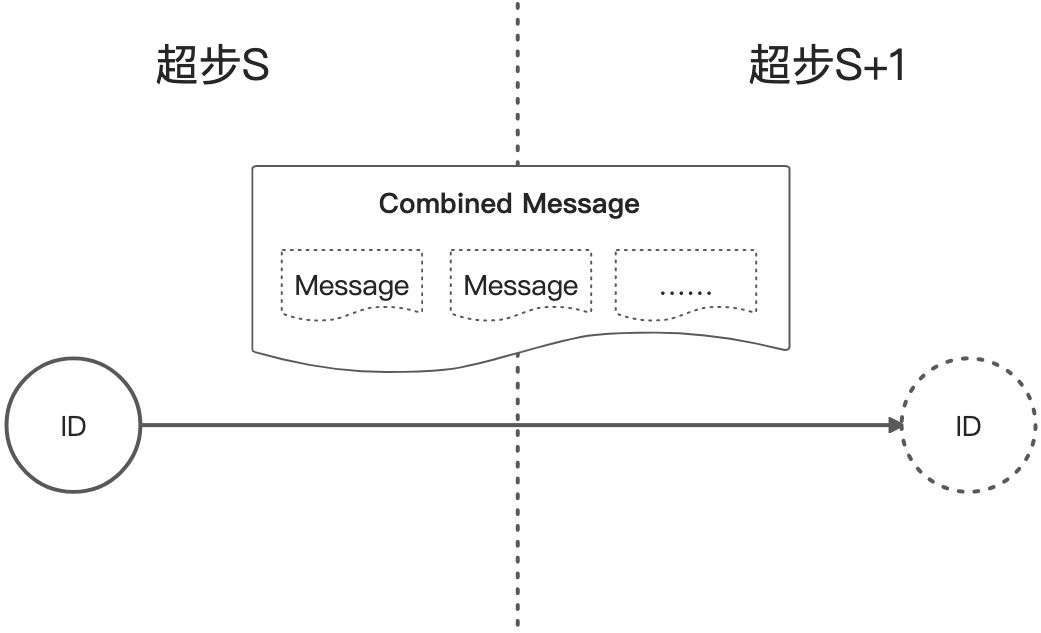
當給點發送消息,尤其是目標點在其他的機器上時,會產生一定的開銷,通過用戶層面自定義Combiner可以降低這樣的開銷。比如發送給同一個點的消息的合併邏輯是求和,那麼系統在發送消息給目標點之前就預先求和,將多個消息合併為一個消息,降低網路的和記憶體的開銷。
3.3 聚合器(Aggregator)
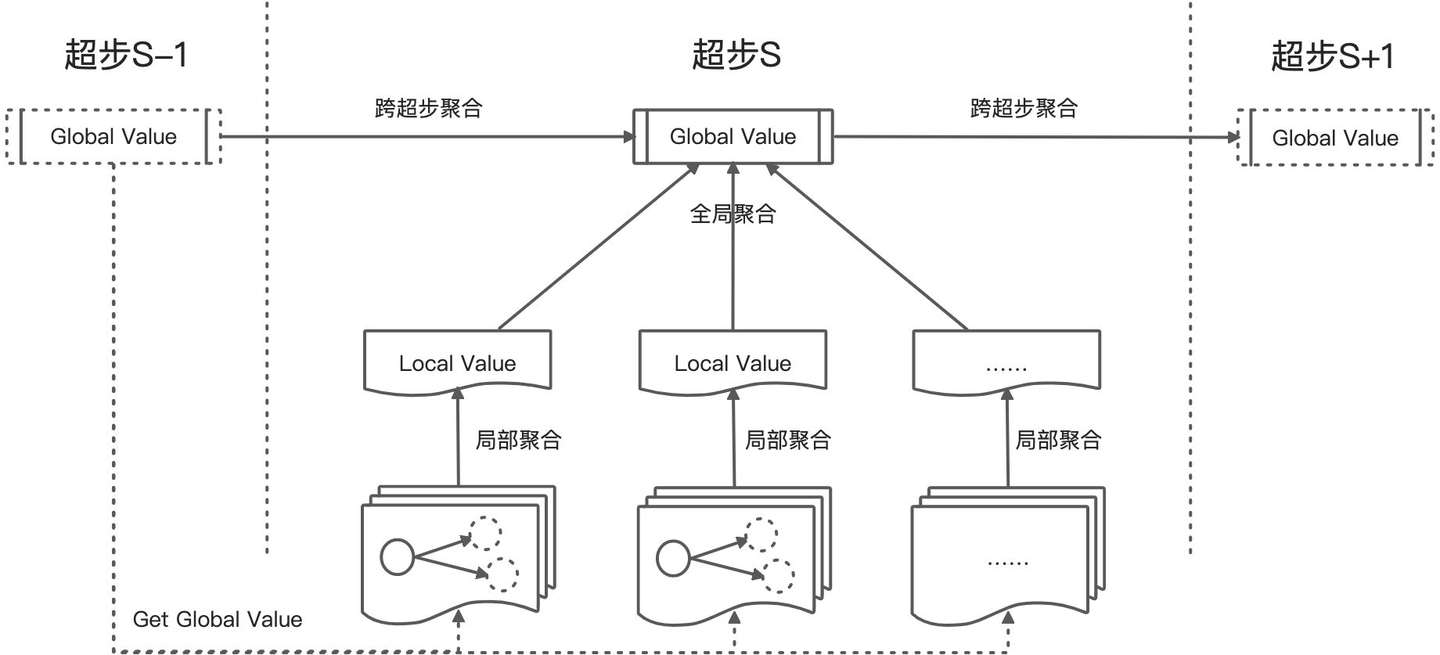
Pregel的聚合器提供了一種全局通信的機制:
- 每個超步S中的點都可以提供一個值。
- 系統使用reduce運算元將所有的值規約為一個全局值,如max、min、sum。
- 這個全局值對超步S+1中的所有點可見。
- 聚合器可以提供跨超步的聚合能力。
使用場景:
- 統計特征:對點的出度求和可以計算圖的邊數。
- 全局協調:超步中等待所有的點滿足一定條件再繼續計算;演算法中選舉一個點作為特殊角色。
- 跨超步聚合:根據超步中對邊的新增/刪除自動維護全局邊數量;Δ-stepping最短路徑演算法。
3.4 修改拓撲
修改衝突解決策略:
- 刪除邊優先於刪除點。
- 刪除操作優先於新增操作。
- 新增點優先於新增邊。
- 用戶自定義衝突策略。
- 最後執行compute函數。
3.5 輸入輸出
- 構圖與圖計算分離。
- 自定義Reader/Writer。
4. 實現
4.1 基本架構
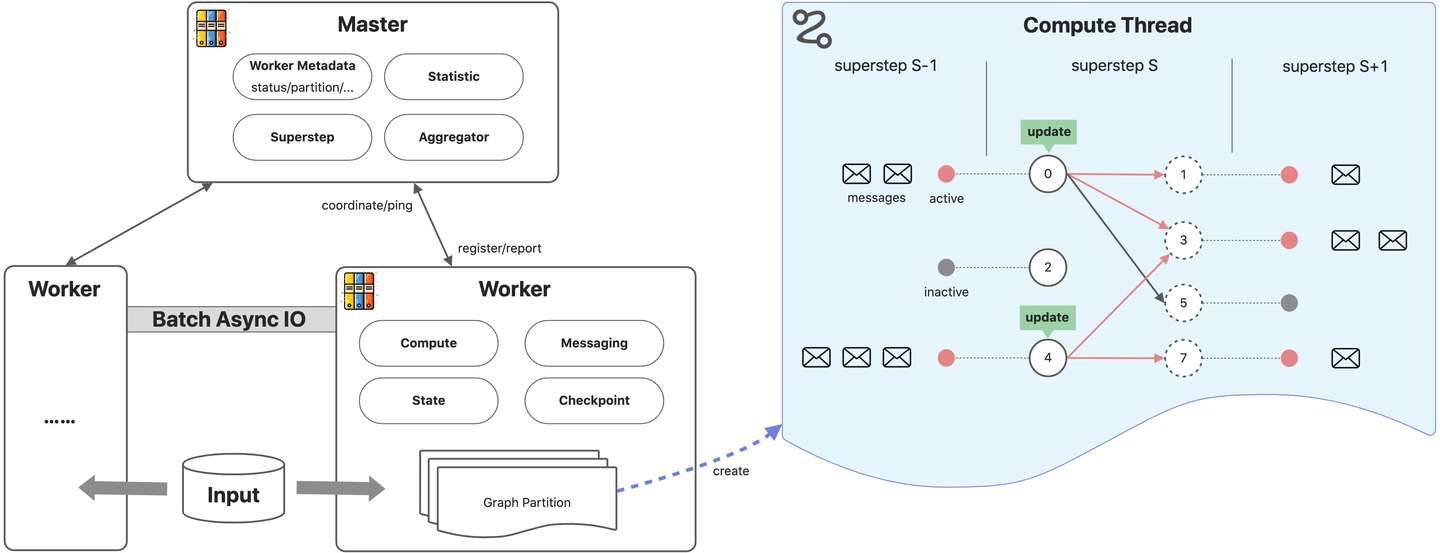
Pregel程式執行流程:
- 用戶程式被拷貝到master和worker節點上。master用於協調worker節點,worker節點通過名字服務向master註冊信息。
- master決定圖的分區,預設hash(點ID)%分區數。worker負責維護圖分區的狀態、執行compute函數、收發其他worker的消息。
- master為worker分配用戶輸入,輸入的劃分和圖切分是獨立的。如果輸入和圖分片剛好在一個worker上則立即更新對應數據結構,否則shuffle到其他worker。輸入載入完成後,點被初始化為active狀態。
- master指導worker執行超步,worker為每個分區啟動一個線程,在active狀態的點上執行compute函數,接收上個超步傳遞的消息。worker執行結束後,會向master彙報下次超步active的點數。
- 超步會不斷的執行,直到沒有active的點以及消息為止。計算結束後,master通知worker保存圖分片上的計算結果。
4.2 錯誤容忍
容錯機制通過checkpoint方式實現:
- 超步開始之前,master通知woker將圖狀態保存到持久化存儲。
- 圖狀態包含:點值、邊值、輸入消息,以及master上的aggregator的值。
- master通過ping消息檢測worker的狀態,一旦失聯worker計算終止,master將worker標記為failed狀態。
- master將失敗的worker上對應的分區分配到其他存活的worker,其他worker從checkpoint載入圖狀態。
- checkpoint可能比出錯時的上次超步領先多個超步(不一定每次超步都會checkpoint)。
- Confined Recovery會將發出的消息持久化,以節省恢復時的計算資源,但要求計算是確定的。
4.3 Worker實現
- worker維護了圖分片上每個點的狀態,狀態包含:當前點值、出邊列表(邊值+目標點)、輸入消息隊列、active標記。
- 考慮性能,點active標記和輸入消息隊列獨立存儲。
- 點/邊的值只有一份,點active標記和輸入消息隊列有兩份(當前超步和下一超步)。
- 發送給其他worker點上的消息先buffer再非同步發送,發給本地的點的消息直接存放到目標點的輸入消息隊列。
- 消息被加入到輸出隊列或者到達輸入隊列時,會執行combiner函數。後一種情況並不會節省網路開銷,但是會節省用於消息存儲的空間(compute內蘊含combine語義)。
4.4 Master實現
- 協調worker,在worker註冊到master分配id。保存worker的id、存活狀態、地址信息、分區信息等。
- master的操作包括輸入、輸出、計算、保存/恢復checkpoint。
- 維護計算過程中的統計數據和圖的狀態數據,如圖大小、出度分佈、active點數、超步的耗時和消息傳輸量、aggregator值等。
4.5 聚合器
- worker先進行分片的部分聚合。
- 全局聚合使用tree方式規約,而不是pipeline方式,提高CPU並行效率。
- 全局聚合值在下個超步被髮送給所有worker。
5. 應用
5.1 PageRank
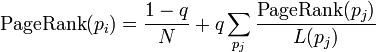
class PageRankVertex : public Vertex<double, void, double> {
public:
virtual void Compute(MessageIterator* msgs) {
if (superstep() >= 1) {
double sum = 0;
for (; !msgs->Done(); msgs->Next())
sum += msgs->Value();
*MutableValue() = 0.15 / NumVertices() + 0.85 * sum;
}
if (superstep() < 30) {
const int64 n = GetOutEdgeIterator().size();
SendMessageToAllNeighbors(GetValue() / n);
} else {
VoteToHalt();
}
}
};
5.2 最短路徑
class ShortestPathVertex: public Vertex<int, int, int> {
void Compute(MessageIterator* msgs) {
int mindist = IsSource(vertex_id()) ? 0 : INF;
for (; !msgs->Done(); msgs->Next())
mindist = min(mindist, msgs->Value());
if (mindist < GetValue()) {
*MutableValue() = mindist;
OutEdgeIterator iter = GetOutEdgeIterator();
for (; !iter.Done(); iter.Next())
SendMessageTo(iter.Target(), mindist + iter.GetValue());
}
VoteToHalt();
}
};
class MinIntCombiner : public Combiner<int> {
virtual void Combine(MessageIterator* msgs) {
int mindist = INF;
for (; !msgs->Done(); msgs->Next())
mindist = min(mindist, msgs->Value());
Output("combined_source", mindist);
}
};
5.3 二分圖匹配
計算流程:
- 階段0:左邊集合中那些還未被匹配的頂點會發送消息給它的每個鄰居請求匹配,然後會無條件的VoteToHalt。如果它沒有發送消息(可能是因為它已經找到了匹配,或者沒有出邊),或者是所有的消息接收者都已經被匹配,該頂點就不會再變為active狀態。
- 階段1:右邊集合中那些還未被匹配的頂點隨機選擇它接收到的消息中的其中一個,併發送消息表示接受該請求,然後給其他請求者發送拒絕消息。然後,它也無條件的VoteToHalt。
- 階段2:左邊集合中那些還未被匹配的頂點選擇它所收到右邊集合發送過來的接受請求中的其中一個,併發送一個確認消息。左邊集合中那些已經匹配好的頂點永遠都不會執行這個階段,因為它們不會在階段0發送消息。
- 階段3:右邊集合中還未被匹配的頂點最多會收到一個確認消息。它會通知匹配頂點,然後無條件的VoteToHalt,它的工作已經完成。
- 重覆以上過程,直到所有的節點匹配完成。
5.4 半聚類
【演算法實現要補充一下資料】
6. 實驗
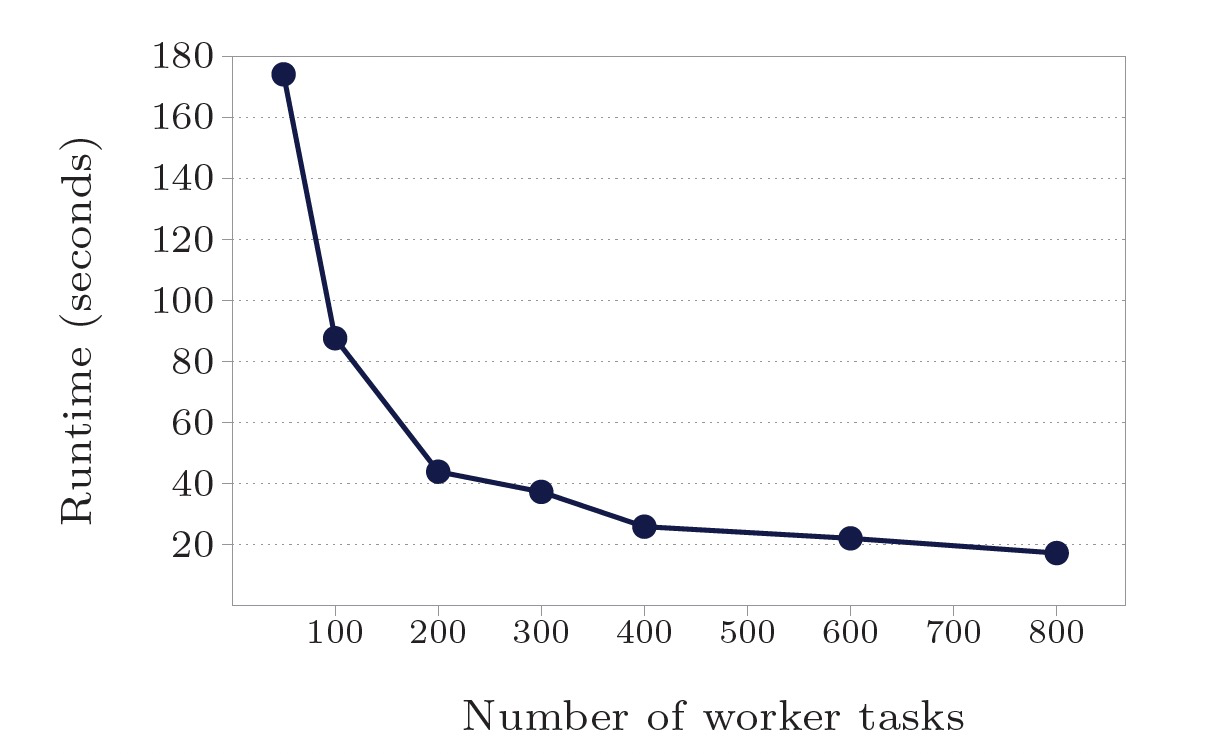
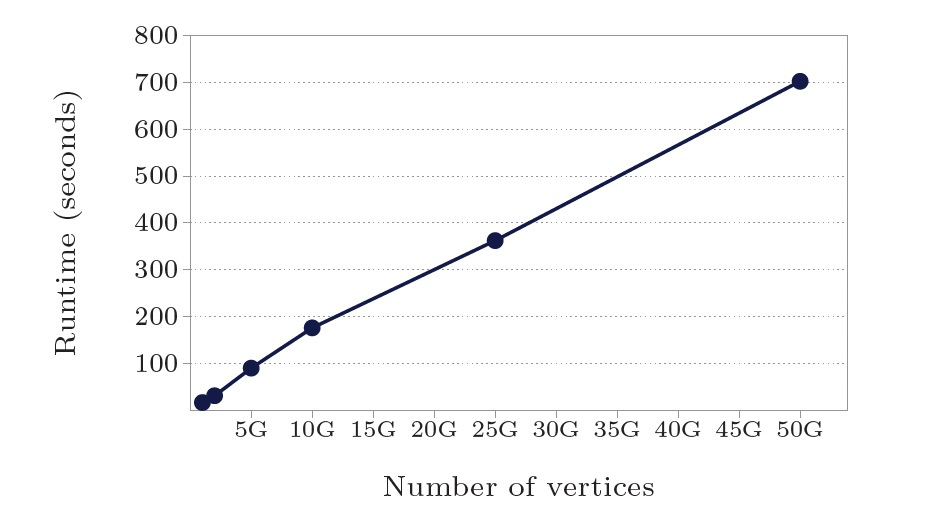
使用最短路徑演算法測試:
- 點/邊規模10億:worker數50-800,計算時間174s-17.3s,16x worker加速10x。
- worker數800:點/邊規模10億-500億,計算時間17.3s-702s,計算時間線性增長。
總結
- Pregel受BSP計算模型啟發,採用了“think like a vertex”方式的編程API。
- Pregel可以滿足10億規模的圖計算的性能、擴展性和容錯能力。
- Pregel被設計於稀疏圖上的計算,通信主要發生在邊上,稠密圖中的熱點會導致性能問題。
若本文對你有所幫助,您的 關註 和 推薦 是我分享知識的動力!

