
1.字元集 在電腦科學中,信息的存儲和處理都是基於二進位數的,這是因為二進位數在電腦硬體層面上實現起來最為簡單和高效。二進位數由兩個基本元素組成:0和1,這兩個元素可以通過電子器件(如晶體管)的開關狀態來輕鬆表示。而我們在屏幕上看到的數字、英文、標點符號、漢字等字元是二進位數轉換之後的結果。按照 ...
1.字元集
在電腦科學中,信息的存儲和處理都是基於二進位數的,這是因為二進位數在電腦硬體層面上實現起來最為簡單和高效。二進位數由兩個基本元素組成:0和1,這兩個元素可以通過電子器件(如晶體管)的開關狀態來輕鬆表示。而我們在屏幕上看到的數字、英文、標點符號、漢字等字元是二進位數轉換之後的結果。按照某種規則,將字元存儲到電腦中,稱為編碼 。反之,將存儲在電腦中的二進位數按照某種規則解析顯示出來,稱為解碼 。
-
字元編碼(Character Encoding) : 就是一套自然語言的字元與二進位數之間的對應規則。
-
字元集:也叫編碼表。是一個系統支持的所有字元的集合,包括各國家文字、標點符號、圖形符號、數字等。
2.常見的字元編碼
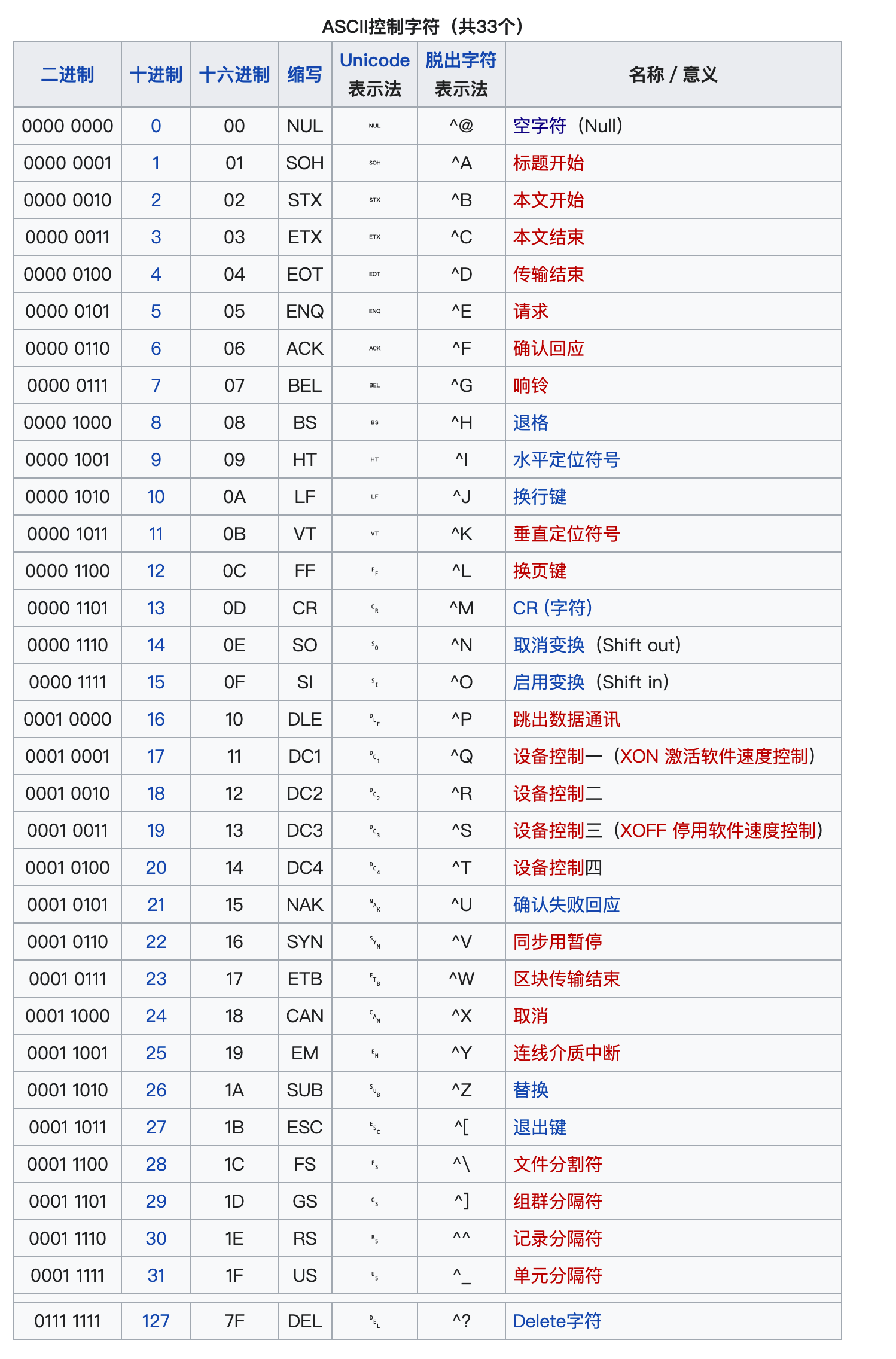
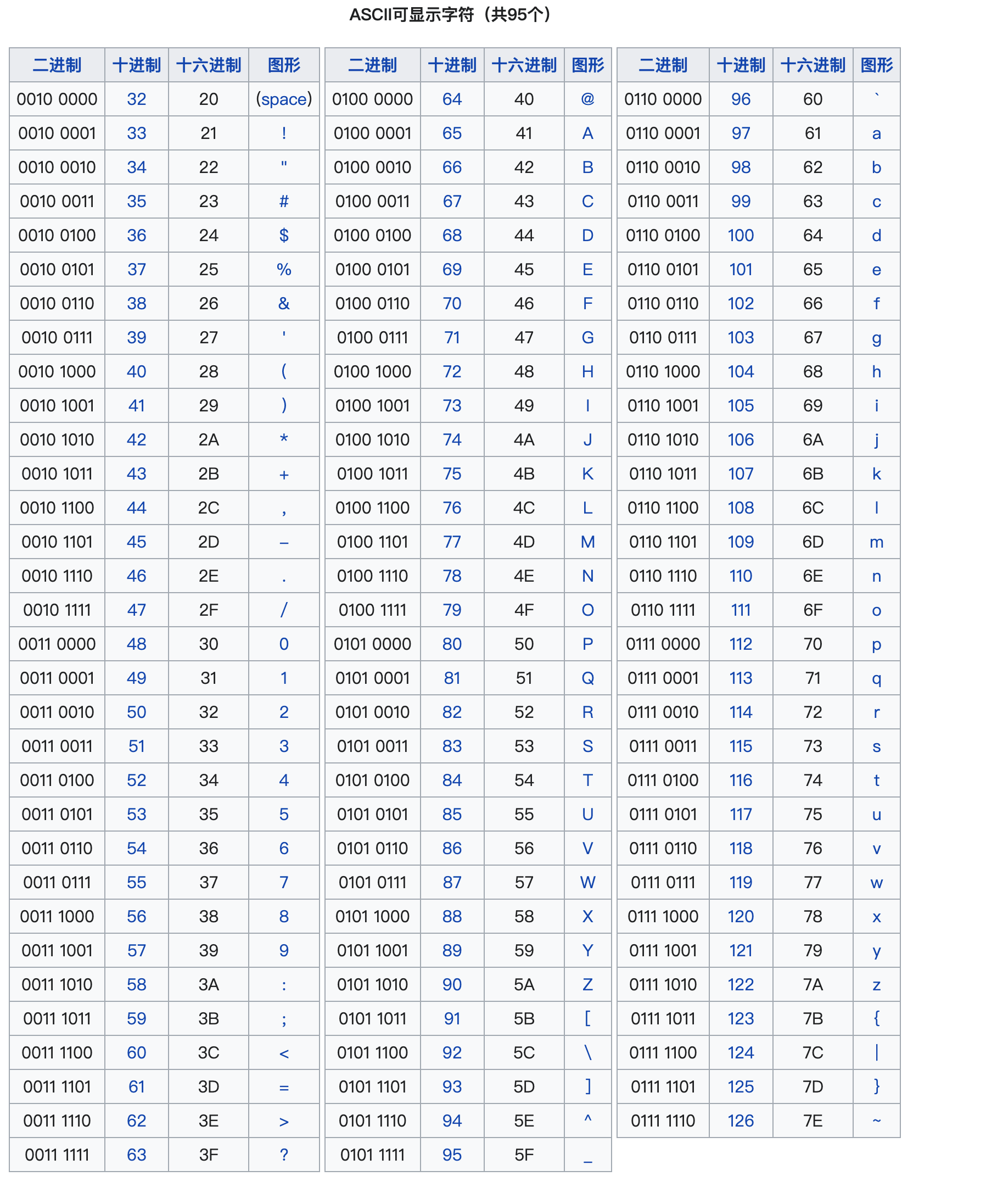
2.1 ASCII碼(American Standard Code for Information Interchange,美國信息交換標準代碼)
-
1961年,美國制定了一套字元編碼,對
英語字元與二進位位之間的關係,做了統一規定。這被稱為ASCII碼。 -
ASCII碼用於顯示現代英語,主要包括控制字元(回車鍵、退格、換行鍵等)和可顯示字元(英文大小寫字元、阿拉伯數字和西文符號)。
-
基本的ASCII字元集,使用7位(bits)表示一個字元(最前面的1位統一規定為0),共
128個字元。比如:空格“SPACE”是32(二進位00100000),大寫的字母A是65(二進位01000001)。 -
缺點:不能表示所有字元。
2.2 ISO-8859-1字元集
ISO-8859-1字元集,正式編號為ISO/IEC 8859-1:1998,又稱Latin-1或“西歐語言”,是國際標準化組織內ISO/IEC 8859系列字元集的第一個8位字元集,相容ASCII編碼。以下是對ISO-8859-1字元集的詳細概述:
一、基本介紹
- 名稱:ISO-8859-1,又稱Latin-1或“西歐語言”。
- 正式編號:ISO/IEC 8859-1:1998。
- 基礎:以ASCII為基礎,擴展了ASCII字元集。
二、特點
-
字元範圍:ISO-8859-1字元集總共包含256個字元(即8位二進位數所能表示的範圍)。
-
字元分類:
-
較低部分(從1到127之間的代碼):這部分是最初的ASCII字元集,包括0-9的數字、大寫和小寫英文字母表(A-Z, a-z),以及一些特殊字元(如標點符號、控制字元等)。
-
較高部分(從160到255之間的代碼):這部分包含了西歐國家使用的字元和一些被廣泛使用的特殊字元,它們全都有實體名稱。這些字元主要是為了支持使用附加符號的拉丁字母語言。
-
三、支持的語言
ISO-8859-1字元集支持多種西歐語言,包括但不限於:
阿爾巴尼亞語
巴斯克語
布列塔尼語
加泰羅尼亞語
丹麥語
荷蘭語
法羅語
弗里西語
加利西亞語
德語
格陵蘭語
冰島語
愛爾蘭蓋爾語
義大利語
拉丁語
盧森堡語
挪威語
葡萄牙語
里托羅曼斯語
蘇格蘭蓋爾語
西班牙語
瑞典語
此外,雖然英語沒有重音字母,但仍會標明為ISO/IEC 8859-1編碼。同時,歐洲以外的部分語言,如南非荷蘭語、斯瓦希里語、印尼語及馬來語、菲律賓他加洛語等,也可使用ISO/IEC 8859-1編碼。
四、歷史與替代
-
歷史版本:ISO-8859-1字元集曾推出過ISO 8859-1:1987版,後更新為ISO/IEC 8859-1:1998版。
-
替代情況:儘管ISO-8859-1廣泛用於西歐語言,但由於其字元集的限制(如不支持法語中的œ、Œ、Ÿ和芬蘭語中的Š、š、Ž、ž等字元),它於1998年被ISO/IEC 8859-15所取代。ISO/IEC 8859-15在ISO-8859-1的基礎上增加了這些字元,並同時加入了歐元符號。
五、應用與影響
- 瀏覽器預設字元集:ISO-8859-1是大多數瀏覽器預設的字元集之一,用於在網頁上正確顯示西歐語言的文本。
- 相容性:由於其廣泛的應用和歷史地位,ISO-8859-1字元集在許多系統和應用程式中仍然保持著良好的相容性。
2.3 GBxx的字元集
GBxx字元集是中國為了顯示和處理中文字元而制定的一系列字元集標準,其中“GB”代表“國家標準”(Guobiao)的縮寫。這些字元集涵蓋了從基本的漢字編碼到更廣泛字元支持的多個版本。
以下是對GBxx字元集的一些主要版本的詳細概述:
-
GB2312
-
全稱:《信息交換用漢字編碼字元集·基本集》,又稱GB0,由中國國家標準總局發佈,1981年5月1日實施。
-
GB2312是中華人民共和國國家標準簡體中文字元集(簡體中文表),一個小於127的字元的意義與原來相同,即向下相容ASCII碼。但兩個大於127的字元連在一起時,就表示一個漢字,這樣大約可以組合了包含
7000多個簡體漢字,此外數學符號、羅馬希臘的字母、日文的假名們都編進去了,這就是常說的"全形"字元,而原來在127號以下的那些符號就叫"半形"字元了。 -
採用雙位元組編碼,每個漢字或符號由兩個位元組表示。第一個位元組稱為“高位位元組”,第二個位元組稱為“低位位元組”。
-
-
GBK
最常用的中文編碼-
全稱:《漢字內碼擴展規範(GBK)》1.0版,由中華人民共和國全國信息技術標準化技術委員會1995年制定。
-
GBK是對GB 2312的擴展,增加了對更多漢字和符號的支持,包括部分GB 2312未收錄的漢字、繁體字、日文假名等。GBK總計擁有23940個碼位,共收入21886個漢字和圖形符號。
-
同樣採用
雙位元組編碼,但編碼範圍更廣,總體編碼範圍為8140-FEFE。
-
-
GB18030
-
全稱:國家標準GB 18030-2005《信息技術 中文編碼字元集》,是中華人民共和國現時最新的內碼字集。
-
GB 18030是對GBK的進一步擴展,支持更多的字元,包括中國國內少數民族的文字、繁體漢字以及日韓漢字等。共收錄漢字70,244個,採用多位元組編碼,每個字可以由1個、2個或4個位元組組成。
-
與GB 2312-1980完全相容,與GBK基本相容,並支持GB 13000及Unicode的全部統一漢字。
-
2.4 UniCode字元集
Unicode編碼,全稱Unicode標準(The Unicode Standard),也被稱為統一碼、標準萬國碼、單一碼等,是一種用於表示文本字元的標準編碼系統。Unicode將世界上所有的文字用2個位元組統一進行編碼,為每個字元設定唯一的二進位編碼,以滿足跨語言、跨平臺進行文本處理的要求。以下是Unicode編碼的詳細概述:
一、背景與目的
-
背景:傳統的字元編碼方案,如ASCII碼,只能表示一種語言的字元,無法同時支持多種語言的字元,導致不同語言的字元無法混合出現在一個文本中。此外,不同國家和地區的字元編碼標準各異,也造成了字元顯示和處理的混亂。
-
目的:Unicode編碼的目的是為每種語言中的每個字元設定一個統一且唯一的二進位編碼,以滿足跨語言、跨平臺進行文本轉換和處理的需求。
二、編碼特點
-
唯一性:Unicode為每個字元分配了一個唯一的標識符,稱為“碼點”(Code Point),通常以十六進位數表示,首碼為“U+”。
-
廣泛性:Unicode字元集包含了幾乎所有語言的字元,包括漢字、拉丁字母、數字、標點符號、符號等,以及特殊的控制字元。
-
擴展性:Unicode字元集還在不斷擴展,每個新版本都會加入更多新的字元。截至當前時間(2024年),Unicode已經收錄了超過14萬個字元。
三、Unicode的局限性
-
第一,英文字母只用一個位元組表示就夠了,如果用更多的位元組存儲是
極大的浪費。 -
第二,如何才能
區別Unicode和ASCII?電腦怎麼知道兩個位元組表示一個符號,而不是分別表示兩個符號呢? -
第三,如果和GBK等雙位元組編碼方式一樣,用最高位是1或0表示兩個位元組和一個位元組,就少了很多值無法用於表示字元,
不夠表示所有字元。
所以Unicode在很長一段時間內無法推廣,直到互聯網的出現,為解決Unicode如何在網路上傳輸的問題,於是面向傳輸的眾多
UTF(UCS Transfer Format)標準出現。
具體來說,有三種編碼方案:UTF-8、UTF-16和UTF-32。
四、編碼方式
-
Unicode是字元集,UTF-8、UTF-16、UTF-32是三種
將數字轉換到程式數據的編碼方案。顧名思義,UTF-8就是每次8個位傳輸數據,而UTF-16就是每次16個位。其中,UTF-8 是在互聯網上使用最廣的一種 Unicode 的實現方式。-
UTF-8:一種變長編碼方式,可以使用1到4個位元組表示Unicode字元集中的任何字元,並且相容ASCII編碼。
-
UTF-16:使用16位或32位(代理對)表示Unicode字元,根據位元組序的不同,可以分為UTF-16LE(小端序)和UTF-16BE(大端序)。
-
UTF-32:固定使用32位(4個位元組)表示Unicode字元,同樣根據位元組序的不同,可以分為UTF-32LE和UTF-32BE。
-
-
Unicode碼點:Unicode定義了字元集中每個字元的唯一碼點,如漢字“中”的Unicode碼點是U+4E2D。
-
互聯網工程工作小組(IETF)要求所有互聯網協議都必須支持UTF-8編碼。所以,我們開發Web應用,也要使用UTF-8編碼。UTF-8 是一種
變長的編碼方式。它可以使用 1-4 個位元組表示一個符號它使用一至四個位元組為每個字元編碼,編碼規則:-
128個US-ASCII字元,只需一個位元組編碼。
-
拉丁文等字元,需要二個位元組編碼。
-
大部分常用字(含中文),使用三個位元組編碼。
-
其他極少使用的Unicode輔助字元,使用四位元組編碼。
-
-
舉例:
Unicode符號範圍 | UTF-8編碼方式
(十六進位) | (二進位)
————————————————————|—–—–—–—–—–—–—–—–—–—–—–—–—–—–
0000 0000-0000 007F | 0xxxxxxx(相容原來的ASCII)
0000 0080-0000 07FF | 110xxxxx 10xxxxxx
0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
註意
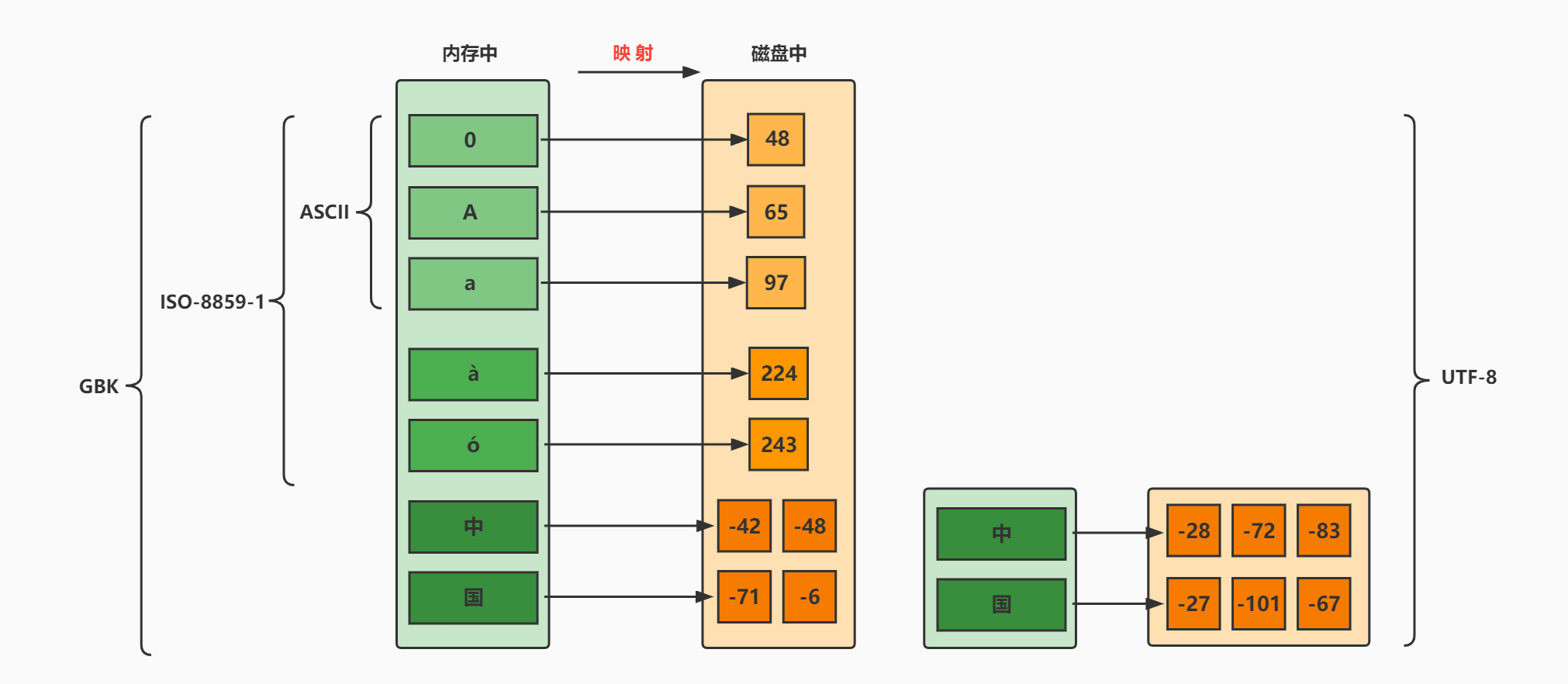
在中文操作系統上,ANSI(美國國家標準學會、AMERICAN NATIONAL STANDARDS INSTITUTE: ANSI)編碼即為GBK;在英文操作系統上,ANSI編碼即為ISO-8859-1。


