
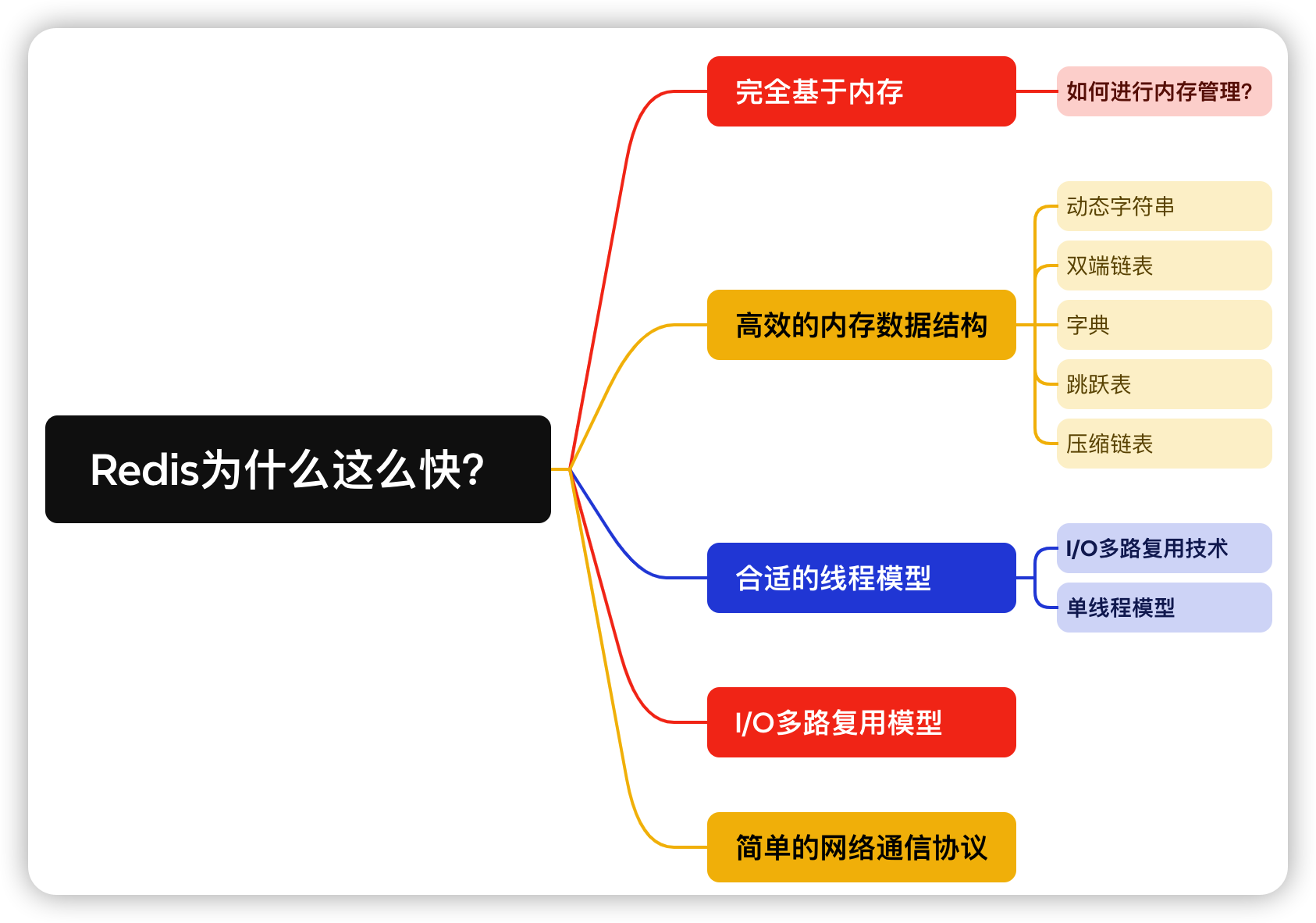
Redis通過結合純記憶體操作、單線程模型、IO多路復用技術和一系列精心設計的高效數據結構,實現了在高併發、低延遲場景下的優秀性能表現。 ...
引言
Redis是一個高性能的開源記憶體資料庫,以其快速的讀寫速度和豐富的數據結構支持而聞名。作為一個輕量級、靈活的鍵值存儲系統,Redis在各種應用場景下都展現出了驚人的性能優勢。無論是作為緩存工具、會話管理組件、消息傳遞媒介,還是在實時數據處理任務和複雜的分散式系統架構中,Redis均扮演了至關重要的角色。而Redis為什麼快的原因也是我們嘗嘗遇見的高頻面試問題。接下來我們就一起探討一下Redis快的原因。
本文將深入探討Redis之所以快速處理大規模數據的原因。我們將從Redis基於記憶體操作的特性、高效的記憶體數據結構、單線程模型、I/O多路復用技術、底層模型和優化技術、持久化機制以及網路通信協議等多個方面進行分析和討論。通過深入瞭解Redis內部機制和性能優化技術,我們可以更好地理解Redis之所以快速的根本原因,以及如何在實際應用中充分發揮其優勢。
完全基於記憶體
Redis作為一種記憶體導向型資料庫系統,其關鍵特性在於將所有數據實體,包括鍵值對及其相關的複雜數據結構,完全寄宿於記憶體之中。相較於依賴磁碟存儲的傳統資料庫系統,Redis巧妙地運用記憶體的高速讀寫特性,顯著提升了系統的響應速率與整體性能表現。
記憶體相對於磁碟具備無可比擬的讀寫速度優勢,使得Redis能夠即時、高效地處理數據存取。在讀取操作層面,Redis無需經過耗時的磁碟I/O過程,只需在記憶體空間內迅速定位所需數據,從而顯著降低了訪問延遲;而在寫入操作時,Redis同樣直接作用於記憶體區域,新數據能即刻生效,僅在執行持久化策略時,例如RDB快照或AOF日誌記錄,數據才會被非同步地或按需地同步至磁碟,以確保即使在系統重啟後數據仍能得以恢復,但此過程並不會妨礙Redis在常規操作中維持其卓越的性能表現。
說到這,我們就會想到,一臺伺服器的記憶體不是無限的,相反的是比較緊張的,Redis基於記憶體操作,那麼Redis究竟是如何在有限記憶體空間中進行精細且高效的記憶體管理呢?
過期鍵刪除
Redis支持為鍵設置過期時間(TTL),並且在鍵過期後會通過兩種方式自動刪除它們:
-
惰性刪除(Lazy Expire):在訪問某個鍵時,Redis會檢查該鍵是否已經過期,如果已經過期,則在訪問時將其刪除。這意味著只有當有客戶端嘗試訪問過期的鍵時,Redis才會執行刪除操作。這種方式的優勢在於避免了不必要的操作,只有在需要時才進行刪除,但缺點是可能會導致過期鍵在一段時間內仍然占用記憶體。
-
定期刪除(Active Expire):Redis周期性地(預設每秒10次)隨機抽取一部分鍵,並檢查它們的過期時間。如果發現某個鍵已經過期,則立即將其刪除。這種方式可以保證過期鍵在一定時間內被及時刪除,避免了過期鍵長時間占用記憶體。但定期刪除會帶來額外的CPU消耗,因為需要在每次抽取時檢查鍵的過期時間。
這兩種方式結合起來,可以有效地管理和清理過期鍵,保證Redis的記憶體使用在合理範圍內。同時,我們在日常開發中可以根據具體業務場景和需求調整過期策略的配置,以達到最佳的性能和記憶體利用率。
記憶體淘汰策略
記憶體淘汰策略是Redis用於釋放記憶體空間的一種機制,當記憶體空間不足時(達到或超過了配置的maxmemory),Redis會根據預先設置的淘汰策略來選擇要刪除的鍵,從而釋放記憶體空間。通過合理選擇和配置記憶體淘汰策略,可以有效地管理記憶體使用,防止記憶體溢出,並保證系統的穩定性和性能。
常見的記憶體淘汰策略:
-
LRU(最近最少使用):
LRU策略會刪除最近最少被訪問的鍵。Redis會記錄每個鍵最後一次被訪問的時間戳,並定期檢查這些時間戳,選擇最久未被訪問的鍵進行刪除。LRU策略適用於緩存場景,通常最久未被訪問的鍵可能是最不常用的,因此刪除這些鍵可以釋放更多的記憶體空間。 -
LFU(最不經常使用):
LFU策略會刪除最不經常被訪問的鍵。Redis會記錄每個鍵被訪問的頻率,並定期檢查這些頻率,選擇訪問頻率最低的鍵進行刪除。LFU策略適用於對訪問頻率較低的鍵進行淘汰,從而釋放記憶體空間。 -
TTL(鍵的過期時間):
TTL策略會刪除已經過期的鍵。Redis會定期檢查鍵的過期時間,並刪除已經過期的鍵。通過設置鍵的過期時間,可以自動清理不再需要的數據,釋放記憶體空間。 -
隨機刪除:
隨機刪除策略會隨機選擇一些鍵進行刪除。雖然這種策略不考慮鍵的使用頻率或過期時間,但在某些情況下可能會是一種簡單且有效的淘汰方式,尤其是在記憶體空間不足時。 -
淘汰固定數量的鍵:
淘汰固定數量的鍵策略會選擇要刪除的鍵的數量,然後按照一定的規則(如LRU或LFU)來選擇要刪除的鍵。這種策略可以保證每次淘汰都釋放固定數量的記憶體空間。
當Redis的記憶體使用達到配置的maxmemory限制時,就會觸發記憶體淘汰策略,以釋放記憶體空間。合理選擇記憶體淘汰策略,並根據系統的需求設置maxmemory參數,可以有效地管理記憶體使用,保證系統的穩定性和性能。通過合理配置記憶體限制和記憶體淘汰策略,可以有效地管理Redis的記憶體使用,保證系統在記憶體空間不足時能夠及時釋放記憶體,避免因記憶體溢出而導致系統性能下降或者崩潰。
修改記憶體
maxmemory只需要在redis.conf配置文件中配置maxmemory-policy參數即可。
記憶體碎片管理
記憶體碎片整理是指對Redis中的記憶體空間進行重新排列和整理,以減少記憶體碎片的數量和大小。記憶體碎片是指已分配但不再使用的記憶體塊,這些記憶體塊雖然被標記為已分配,但實際上並未被有效利用,造成了記憶體的浪費。
在Redis中,由於數據的增刪改查操作不斷進行,會導致記憶體空間中出現大量的記憶體碎片。這些記憶體碎片雖然單個很小,但如果積累起來會導致記憶體碎片化,降低記憶體利用率,影響系統的性能和穩定性。
為瞭解決記憶體碎片化的問題,Redis會定期進行記憶體碎片整理操作。記憶體碎片整理過程包括以下幾個步驟:
-
遍歷記憶體空間:Redis會遍歷整個記憶體空間,檢查每個記憶體塊的狀態,包括已分配和未分配的記憶體塊。
-
合併相鄰的空閑記憶體塊:Redis會嘗試合併相鄰的空閑記憶體塊,將它們合併成一個更大的記憶體塊。這樣可以減少記憶體碎片的數量,提高記憶體利用率。
-
移動數據:如果有必要,Redis可能會將數據從一個記憶體塊移動到另一個記憶體塊,以便更好地組織記憶體空間。這個過程可能會比較耗時,因為需要將數據從一個位置複製到另一個位置。
-
釋放不再使用的記憶體塊:最後,Redis會釋放那些不再使用的記憶體塊,以便它們可以被重新分配給新的數據。
通過定期進行記憶體碎片整理操作,Redis可以保持記憶體空間的連續性,減少記憶體碎片化的程度,提高記憶體利用率,從而提高系統的性能和穩定性。但是,記憶體碎片整理過程可能會消耗一定的系統資源,尤其是在記憶體碎片較多的情況下。所以,通常情況下,Redis會選擇在系統負載較低的時候進行碎片整理操作,以避免對系統性能產生不利影響。
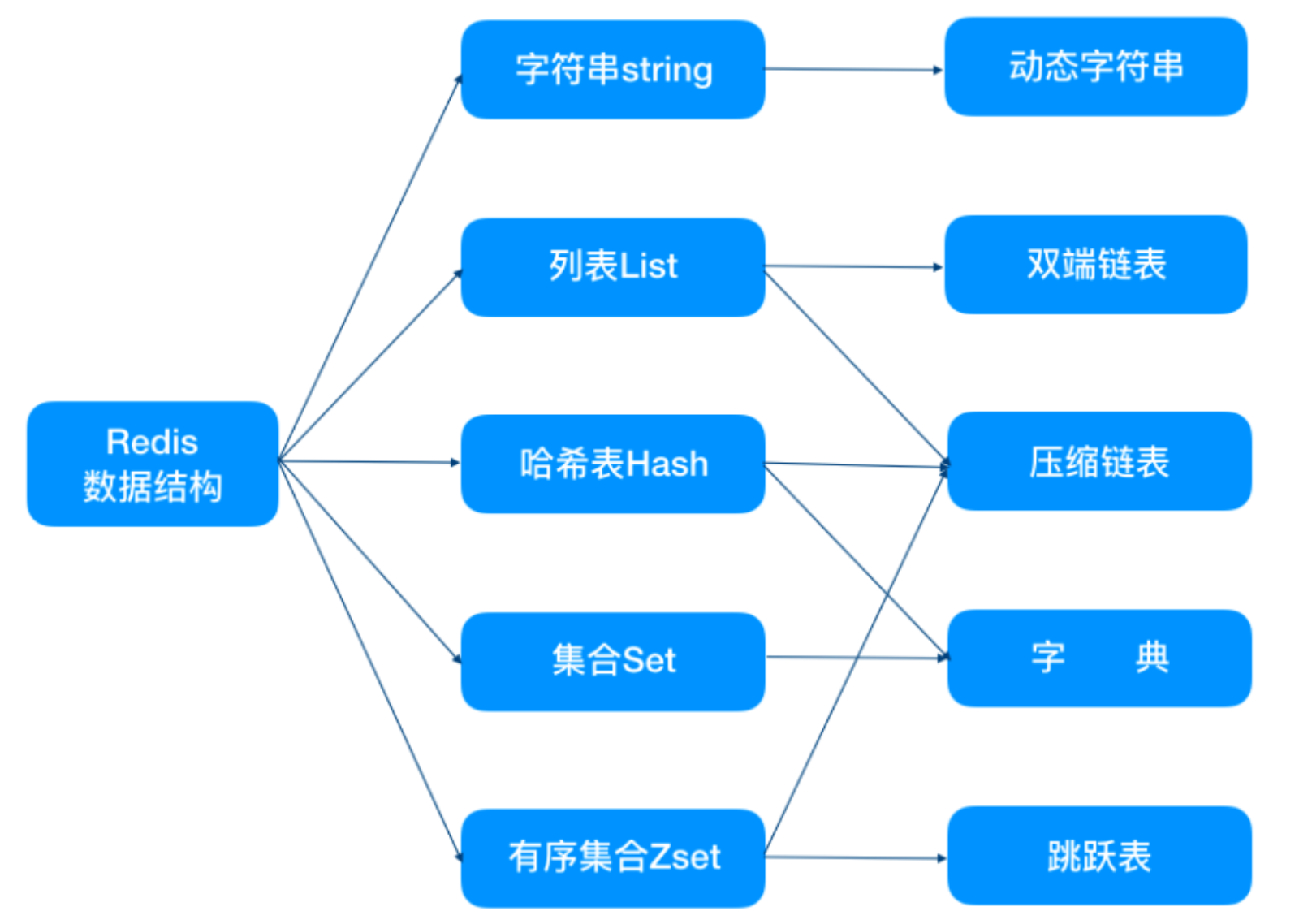
高效的記憶體數據結構
Redis作為一個記憶體資料庫系統,提供了豐富且高效的記憶體數據結構,包括字元串(String)、列表(List)、集合(Set)、有序集合(Sorted Set)、哈希(Hash)等。這些數據結構不僅具有簡單易用的特點,還能夠在記憶體中高效地存儲和操作數據,為Redis的快速性能提供了堅實的基礎。
動態字元串
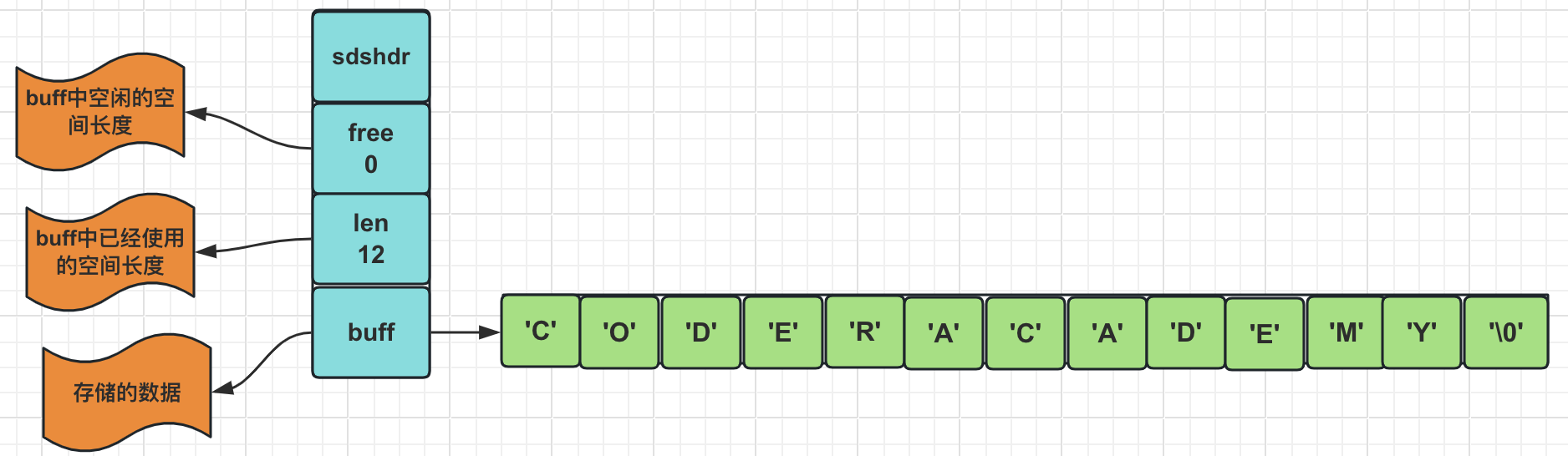
動態字元串是一種能夠動態擴展長度的字元串實現方式。在許多編程語言和數據結構中都有類似的實現,如C語言中的動態數組(dynamic array)。而SDS是Redis中的一種簡單動態字元串結構,它是一種動態大小的位元組數組,用於存儲和操作字元串數據。SDS是Redis內部數據結構的基礎,也是字元串數據結構的底層實現。它的結構如下:
/*
* redis中保存字元串對象的結構
*/
struct sdshdr {
//用於記錄buf數組中使用的位元組的數目,和SDS存儲的字元串的長度相等
int len;
//用於記錄buf數組中沒有使用的位元組的數目
int free;
//位元組數組,用於儲存字元串
char buf[]; //buf的大小等於len+free+1,其中多餘的1個位元組是用來存儲’\0’的
};
在C語言中傳統字元串是使用長度為N+1的字元數組來表示長度為 的字元串,並且字元串數組的最後一個元素總是空字元'\0'。

如果我們想要獲取上述CODERACADEMY的長度,我們需要從頭開始遍歷,直到遇到 '\0' 為止。
而Redis的SDS的數據結構使用一個len欄位記錄當前字元串的長度,使用free表示空閑的長度。想要獲取長度只需要獲取len欄位即可。
我們可以看出C語言獲取字元串長度的時間複雜度為O(N),而SDS獲取字元串長度的時間複雜度為O(1)。除此之外,SDS相對於C語言字元串還有如下區別:
| 特征 | C語言字元串 | SDS |
|---|---|---|
| 類型 | 靜態字元數組 | 動態字元串結構 |
| 記憶體管理 | 需手動分配和釋放記憶體 | 自動擴展和釋放記憶體 |
| 存儲空間 | 需要提前預留足夠的空間 | 根據需要動態調整大小 |
| 長度計算 | 需要遍歷整個字元串計算長度 | O(1)複雜度直接獲取字元串長度 |
| 二進位安全 | 不二進位安全 | 二進位安全 |
| 緩衝區溢出保護 | 不提供緩衝區溢出保護 | 提供緩衝區溢出保護 |
| 操作複雜度 | 操作複雜度隨字元串長度增加而增加 | 操作複雜度不受字元串長度影響 |
| 可拓展性 | 不易擴展,需要手動處理記憶體擴展 | 自動擴展,支持動態調整大小 |
| 細說下來,SDS相對於C語言字元串有如下優點: |
-
二進位安全: SDS可以存儲任意二進位數據,而不僅僅是文本字元串。這意味著SDS可以存儲包括圖片、視頻、音頻等在內的各種二進位數據,而不會受到特殊字元或者空字元的限制,具有更廣泛的適用性。
-
動態擴展: SDS的大小可以根據存儲的字元串長度動態調整,可以根據實際需要動態分配和釋放記憶體空間。這種動態擴展的能力使得SDS能夠處理任意長度的字元串數據,而不受到固定大小的限制。
-
O(1)複雜度的操作: SDS支持常數時間複雜度的操作,包括添加字元、刪除字元、修改字元等。無論字元串的長度是多少,這些操作的時間開銷都是固定的,具有高效的性能。
-
緩衝區溢出保護: SDS在存儲字元串時,會自動添加一個空字元('\0')作為字元串的結束標誌,保證字元串的有效性和安全性。這種緩衝區溢出保護能夠防止緩衝區溢出的問題,提高了系統的穩定性和安全性。
-
惰性空間釋放: 當SDS縮短字元串時,並不會立即釋放多餘的空間,而是將多餘的空間保留下來,以備後續的再利用。這種惰性空間釋放的策略可以減少記憶體分配和釋放的開銷,提高記憶體利用率。
這些優點使得SDS在Redis中被廣泛應用於存儲和操作字元串數據,為Redis的高性能和高可靠性提供了堅實的基礎。
雙端鏈表
Redis中的雙端鏈表是一種經過優化的數據結構,用於存儲有序的元素集合。它具有雙向鏈接的特性,每個節點都包含指向前一個節點和後一個節點的指針。
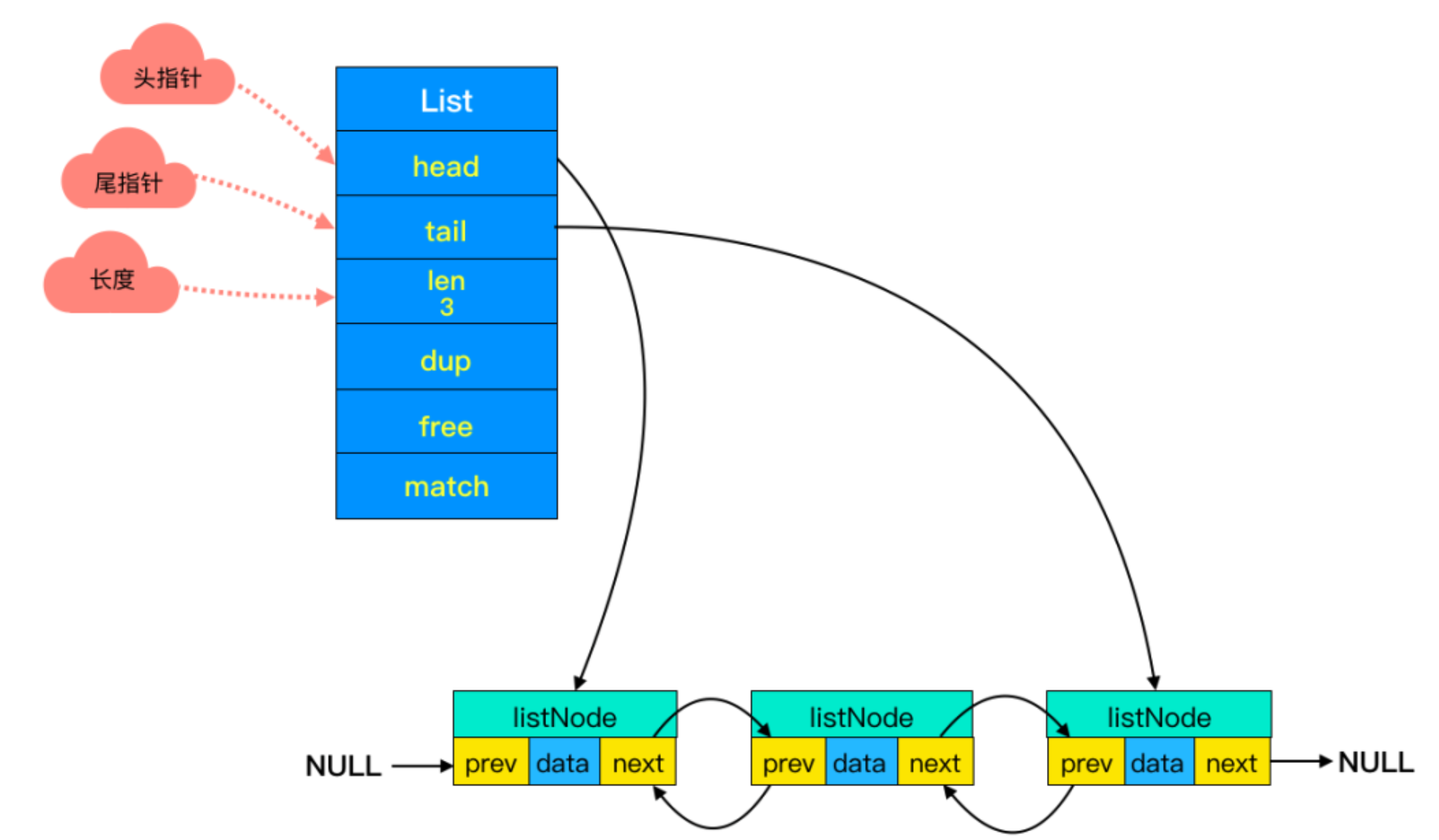
雙端鏈表中的節點是鏈表的基本構建單元,它存儲了鏈表中的數據元素以及指向前一個節點和後一個節點的指針。在Redis中,雙端鏈表節點的定義通常如下:
typedef struct listNode {
struct listNode *prev; // 指向前一個節點的指針
struct listNode *next; // 指向後一個節點的指針
void *value; // 存儲的數據元素
} listNode;
雙端鏈表中的節點包含了以下幾個關鍵屬性:
-
prev指針:
prev指針是指向前一個節點的指針,它指向鏈表中當前節點的前一個節點。如果當前節點是鏈表的頭節點,則prev指針為NULL。通過prev指針,可以在雙端鏈表中方便地向前遍歷節點。 -
next指針:
next指針是指向後一個節點的指針,它指向鏈表中當前節點的後一個節點。如果當前節點是鏈表的尾節點,則next指針為NULL。通過next指針,可以在雙端鏈表中方便地向後遍歷節點。 -
value數據域:
value數據域用於存儲鏈表節點所包含的數據元素。這個數據元素可以是任意類型的數據,因此在Redis中的雙端鏈表中,通常使用void *類型來表示。這種設計使得雙端鏈表可以存儲任意類型的數據元素。
通過這些屬性,雙端鏈表節點構成了鏈表的基本組成部分,它們通過prev和next指針連接在一起,形成了雙向鏈接的鏈表結構。
對於鏈表中描述鏈表整體屬性的元數據,它的結構如下:
typedef struct list {
listNode *head; // 頭節點指針
listNode *tail; // 尾節點指針
unsigned long len; // 鏈表長度
// 其他欄位...
} list;
從結構中可以看出元數據中還有兩個特殊的節點:頭節點(head node)和尾節點(tail node),它們分別位於鏈表的頭部和尾部。而他們的作用如下:
-
頭節點(head node):
頭節點是雙端鏈表中的第一個節點,也是鏈表的入口。它通常用於存儲鏈表的起始位置信息,以便快速定位鏈表的起始位置。在雙端鏈表中,頭節點的特點是沒有前一個節點,即頭節點的prev指針為NULL。頭節點通常用於存儲鏈表的頭部元數據或者哨兵節點。 -
尾節點(tail node):
尾節點是雙端鏈表中的最後一個節點,也是鏈表的結束位置。它通常用於存儲鏈表的結束位置信息,以便快速定位鏈表的結束位置。在雙端鏈表中,尾節點的特點是沒有後一個節點,即尾節點的next指針為NULL。尾節點通常用於存儲鏈表的尾部元數據或者哨兵節點。
在Redis中,通常會使用頭節點和尾節點來表示雙端鏈表的起始位置和結束位置,以方便對鏈表進行操作。Redis中的雙端鏈表常見操作如下:
- 頭節點(head):表示雙端鏈表的頭部節點,通過頭節點可以快速定位鏈表的起始位置,通常用於添加和刪除鏈表的頭部元素。
- 尾節點(tail):表示雙端鏈表的尾部節點,通過尾節點可以快速定位鏈表的結束位置,通常用於添加和刪除鏈表的尾部元素。
通過頭節點和尾節點,可以方便地對雙端鏈表進行頭部插入、尾部插入、頭部刪除、尾部刪除等操作,從而實現了對雙端鏈表的高效操作。
除了上述頭尾節點以外,鏈表的元數據中還有len參數,這個參數用於記錄鏈表的當前長度。每當鏈表中添加或刪除節點時,Redis會相應地更新len欄位的值,以反映鏈表的當前長度。這個參數與SDS里類似,獲取鏈表長度時不用再遍歷整個鏈表,直接拿到len值就可以了,這個時間複雜度是 O(1)。
壓縮列表
Redis中的壓縮列表(ziplist)是一種特殊的數據結構,用於存儲列表和哈希數據類型中的元素。壓縮列表通過將多個小的數據單元壓縮在一起,以節省記憶體空間,並提高訪問效率。
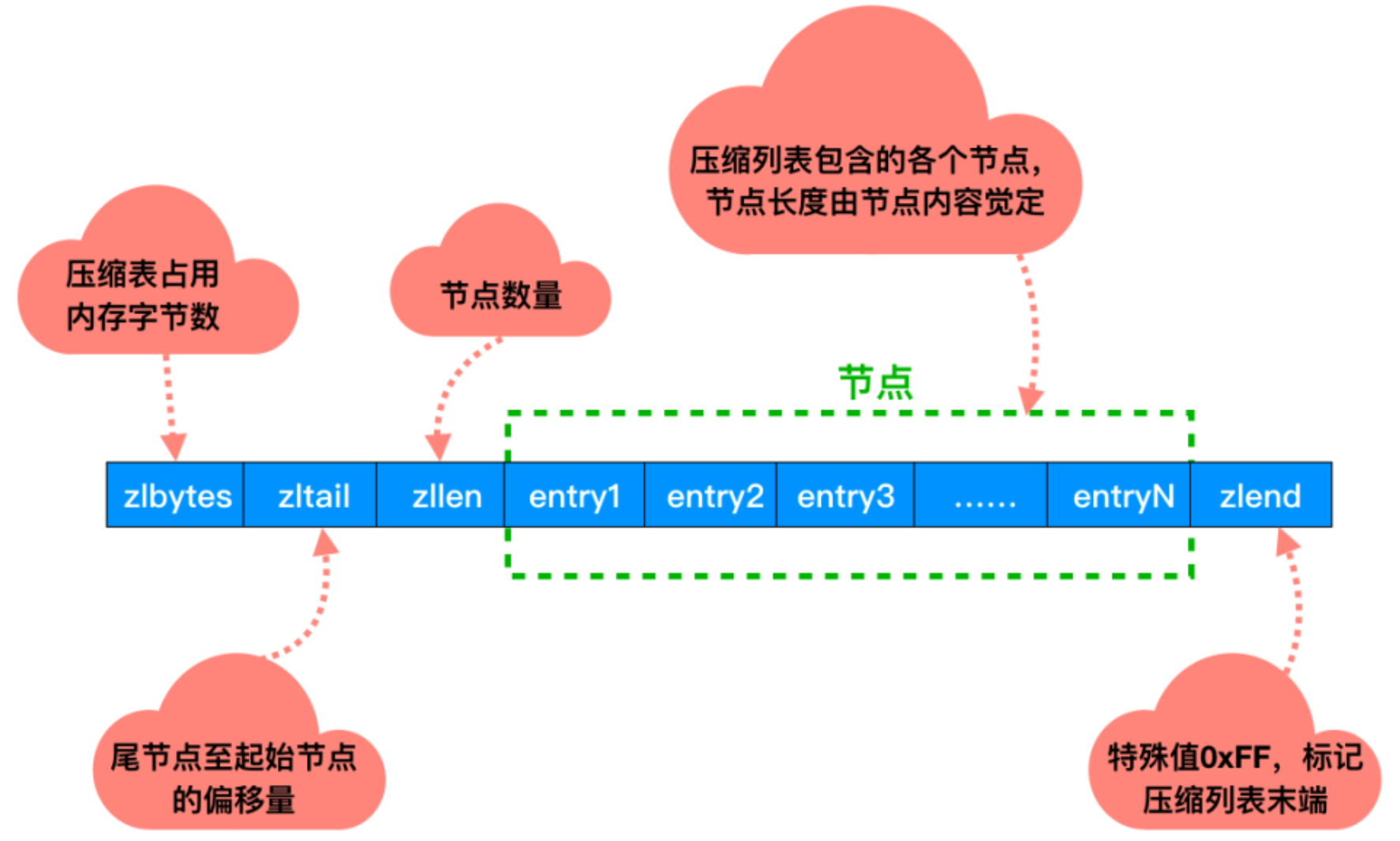
對於壓縮列表,它的主要作用如下:
-
緊湊的存儲形式: 壓縮列表以一種緊湊的方式存儲數據,將多個元素緊密地排列在一起,節省了存儲空間。在壓縮列表中,相鄰的元素可以共用同一個記憶體空間,這種緊湊的存儲形式可以大大減少記憶體的消耗。
-
靈活的編碼方式: 壓縮列表中的每個元素都可以採用不同的編碼方式進行存儲,包括整數編碼、字元串編碼和位元組數組編碼等。根據元素的類型和大小,壓縮列表會選擇合適的編碼方式來存儲數據,以進一步節省記憶體空間。
-
快速的隨機訪問: 壓縮列表支持快速的隨機訪問操作,可以通過下標索引來訪問壓縮列表中的任意元素。由於壓縮列表採用緊湊的存儲形式,因此可以通過簡單的偏移計算來實現快速的元素訪問,具有較高的訪問效率。
-
動態調整大小: 壓縮列表支持動態調整大小,可以根據實際需要自動擴展或收縮記憶體空間。當壓縮列表中的元素數量增加時,可以動態地分配額外的記憶體空間,以容納更多的元素;當元素數量減少時,可以釋放多餘的記憶體空間,以節省記憶體資源。
-
適用於小型數據集: 壓縮列表適用於存儲小型數據集,例如長度較短的列表或者哈希表。由於壓縮列表採用緊湊的存儲形式,並且支持快速的隨機訪問,因此特別適合於存儲數量較少但訪問頻繁的數據。
字典
在Redis中,字典(dictionary)是一種用於存儲鍵值對數據的數據結構,也稱為哈希表(hash table)。字典是Redis中最常用的數據結構之一,具有快速查找、動態調整大小、哈希衝突處理、迭代器支持等特點,適用於各種數據存儲和操作需求,實現鍵值對存儲和快速查找。
字典以鍵值對的形式存儲數據,每個鍵都與一個值相關聯。在Redis中,鍵和值都可以是任意類型的數據,如字元串、整數、列表或哈希表。
字典利用哈希表實現,具備快速查找的特性。通過將鍵映射到哈希表的索引位置,字典能以常數時間複雜度(O(1))內查找、插入和刪除鍵值對,即使在大型數據集中也能保持高效。
此外,字典支持動態調整大小,隨著鍵值對數量的變化,能自動擴展或收縮記憶體空間,以適應數據量的變化。
在存儲數據時,如果產生了哈希衝突,字典可以採用開放定址法或鏈表法等策略,根據哈希表的大小和負載因數選擇合適的衝突解決方法,確保查找性能高效。
跳躍表
跳躍表(Skip List)是一種基於鏈表的數據結構,它利用多級索引來加速查找操作,類似於平衡樹,但實現起來更加簡單,具有較好的平均查找性能。在Redis中,跳躍表用於有序集合(Sorted Set)數據類型的實現,提供了高效的有序數據存儲和檢索功能。
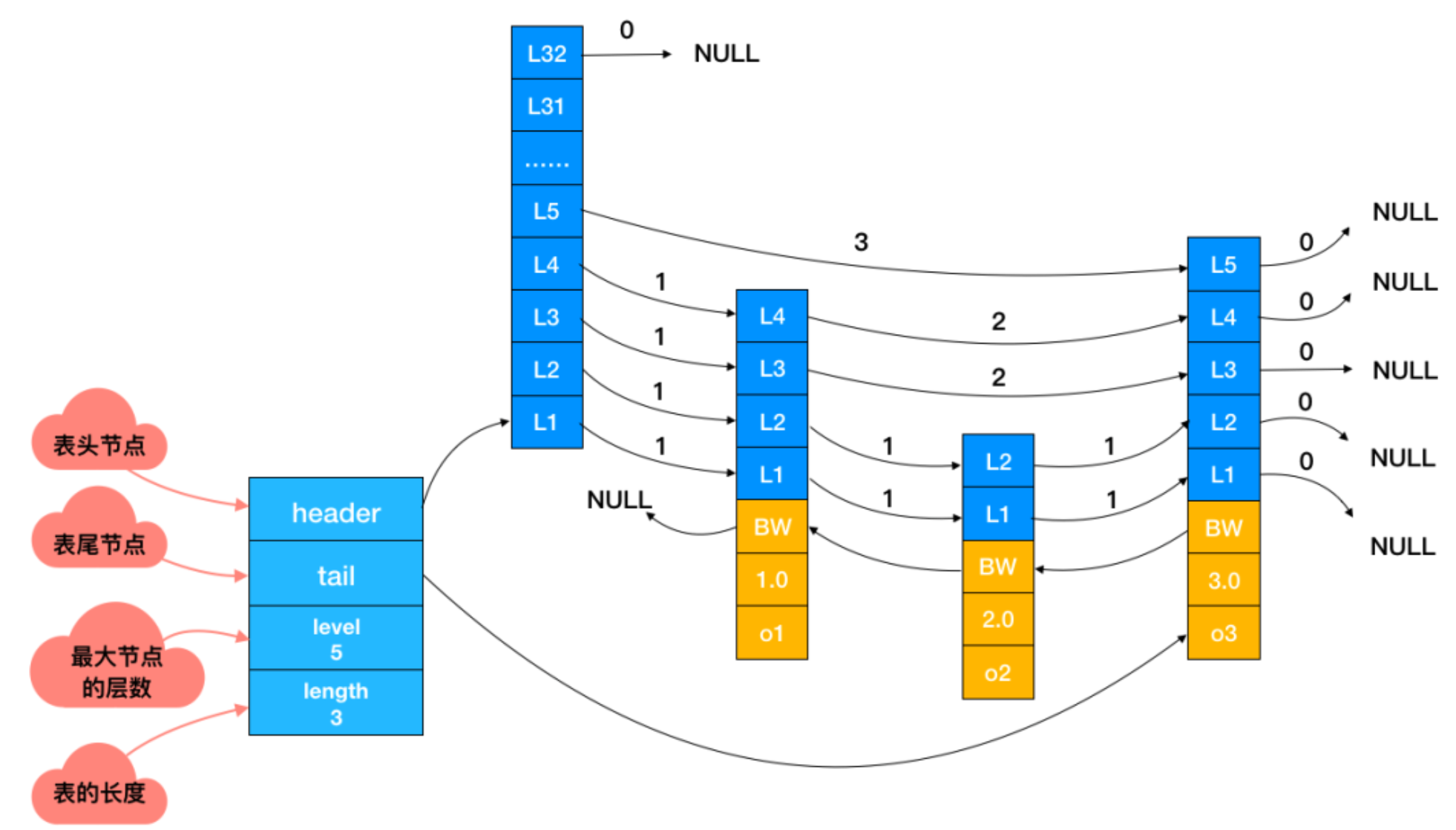
跳躍表通過維護多級索引,每個級別的索引都是原始鏈表的子集,用於快速定位元素。每個節點在不同級別的索引中都有一個指針,通過這些指針,可以在不同級別上進行快速查找,從而提高了查找效率。
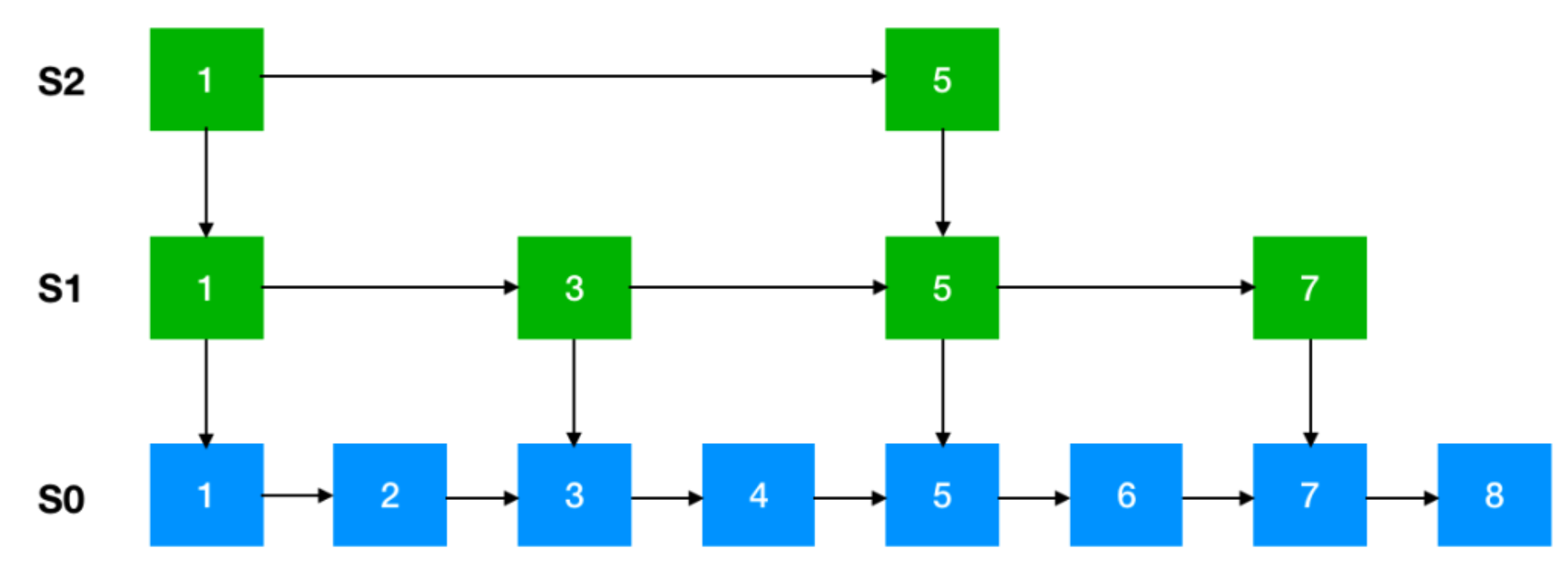
跳躍表的平均查找性能為O(log n),與平衡樹相當,但實現起來更加簡單。跳躍表通過多級索引來實現快速查找,使得查找時間隨著數據量的增加而呈對數增長。但是跳躍表的空間複雜度相對較高,因為它需要額外的空間來維護多級索引。不過跳躍表的空間占用通常是合理的,且具有可控性,可以根據實際需求調整級別和索引節點的數量,以平衡空間和性能的需求。
除此之外,跳躍表支持動態調整大小,可以根據實際需要自動擴展或收縮記憶體空間。當有序集合中的元素數量增加時,跳躍表會動態地增加級別和索引節點,以提高查找效率;當元素數量減少時,可以收縮跳躍表的大小,以節省記憶體資源。並且跳躍表的插入和刪除操作具有較高的效率,通過維護多級索引,可以在O(log n)的時間複雜度內完成插入和刪除操作。
單線程模型
Redis中的單線程模型是指Redis在其核心數據處理部分採用單一的主線程來執行網路IO操作、接收客戶端命令請求、執行命令操作以及返回結果。Redis服務端的網路IO和鍵值對讀寫操作都由一個線程統一負責,而諸如持久化、集群數據同步等任務則是由其他線程來執行。在單線程模型下,Redis伺服器是單線程運行的,即每個客戶端的請求都是依次順序執行的。
而使用單線程所帶來的好處:
-
避免上下文切換:
多線程環境下,線程間的上下文切換會帶來額外的CPU開銷。Redis通過單線程模型消除了多線程環境下的上下文切換成本,使得CPU資源更多地用於執行實際的命令處理。 -
簡化數據操作的併發控制:
單線程模型確保了同一時間內只有一個操作在處理數據,因此不需要使用鎖機制來保護數據的完整性,避免了多線程編程中常見的鎖競爭和死鎖問題,從而提高了系統的執行效率。 -
記憶體操作性能優越:
Redis是一個基於記憶體操作的資料庫,大部分操作都在記憶體中完成,本身就有很高的執行速度。單線程模型下,記憶體操作無需考慮併發控制,因此能夠實現更高的記憶體讀寫效率。
在日常開發中,我們通常會使用併發編程來提高服務的吞吐量。這時,我們可能會產生一個疑問:Redis的單線程模型是否能夠充分利用CPU資源呢?
實際上,由於Redis是基於記憶體的操作,使用Redis時,CPU很少會成為瓶頸。相反,Redis主要受限於伺服器記憶體和網路帶寬。例如,在典型的Linux系統上,通過使用pipelining技術,Redis能夠實現較高的吞吐量,每秒可以處理大量的請求。因此,如果應用程式主要使用O(N)或O(log(N))的命令,它幾乎不會對CPU資源造成過多的負載。綜上所述,考慮到單線程模型的實現簡單且CPU很少成為瓶頸,因此採用單線程方案是合理的選擇。
單線程模型限制了Redis的併發能力。由於只有一個線程在處理請求,無法充分利用多核處理器的性能優勢,所以可能到達服務端的請求不可能被立即處理。那麼Redis是如何保證單線程的資源利用率和處理效率呢?
IO多路復用技術:
Redis通過使用IO多路復用技術(如epoll、kqueue或select等),在一個線程內同時監聽多個socket連接,當有網路事件發生時(如讀寫就緒),再逐一處理。這樣可以處理大量併發連接,併在單線程中高效地調度網路事件,使得單線程也能應對高併發場景。所以Redis服務端,整體來看,就是一個以事件驅動的程式,它的操作都是基於事件的方式進行的。Redis的事件驅動架構如圖:
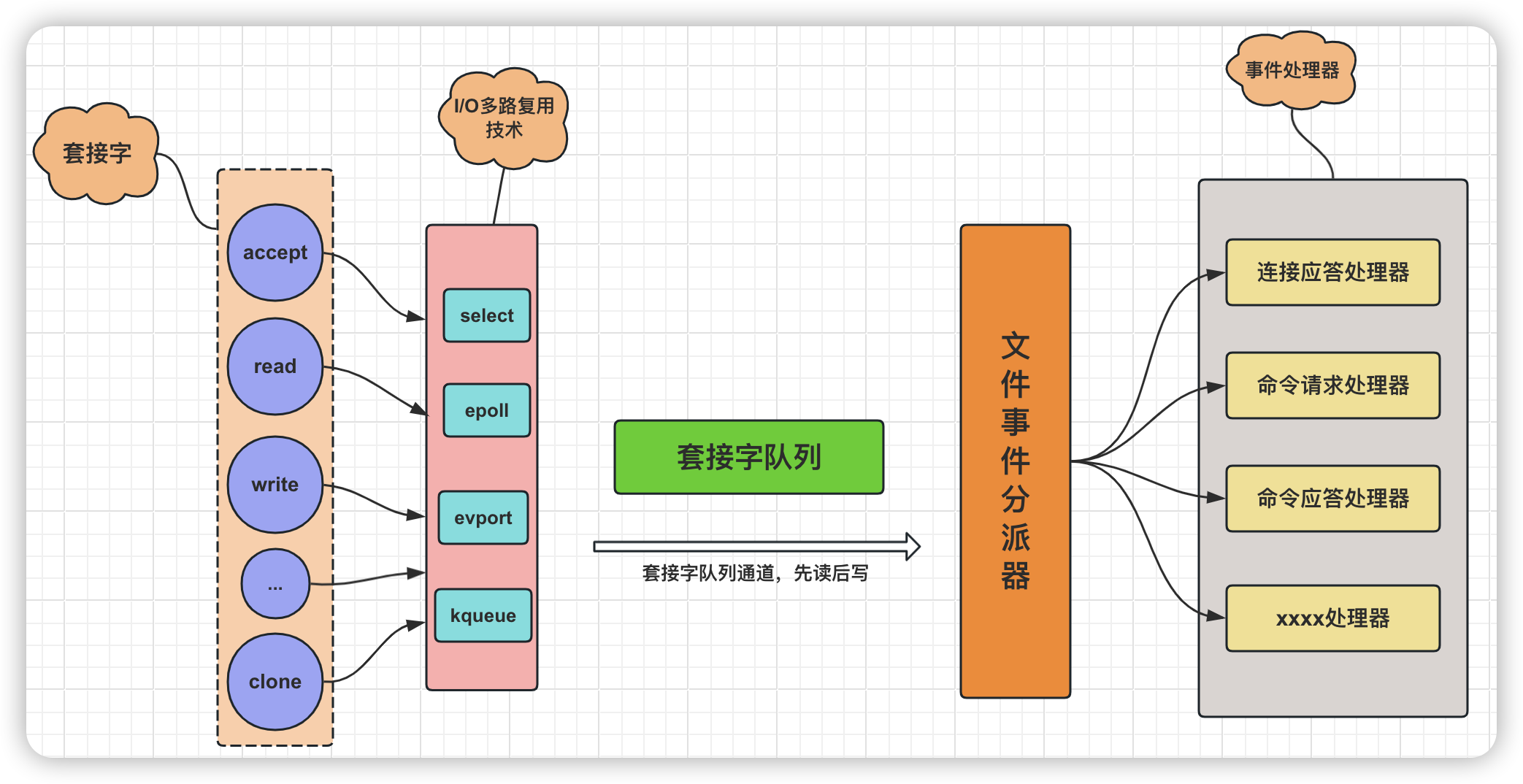
Redis的事件驅動架構是一種基於非阻塞I/O多路復用技術設計的高效處理併發請求的機制。在Redis中,事件驅動架構通過監聽和處理各種網路I/O事件以及定時事件,使得Redis服務端能夠在一個線程內高效地服務於多個客戶端連接,並執行相關的命令操作。
事件驅動架構主要由以下幾個組成部分構成:
-
套接字(Socket):
套接字是客戶端與Redis服務端之間進行通信的基礎介面,用於雙向數據傳輸。 -
I/O多路復用:
Redis服務端通過使用如epoll、kqueue等I/O多路復用技術,可以同時監聽多個套接字上的讀寫事件。當某個客戶端的套接字上有數據可讀或可寫時,內核會通知Redis服務端,而無需Redis反覆檢查每一個套接字狀態。
Redis預設使用的IO多路復用技術確實是epoll。其主要優點如下:
-
併發連接限制
相比於select和poll,epoll沒有預設的併發連接數限制,能夠處理的併發連接數只受限於系統資源,適合處理大規模併發連接。 -
記憶體拷貝優化
epoll採用事件註冊機制,僅關註和通知就緒的文件描述符,無需像select和poll那樣在每次調用時都拷貝整個文件描述符集合,從而減少了記憶體拷貝的開銷。 -
活躍連接感知
epoll提供了水平觸發(level-triggered)和邊緣觸發(edge-triggered)兩種模式,可以更準確地感知活躍連接,僅當有事件發生時才喚醒處理,避免了無效的輪詢操作,提升了事件處理的效率。 -
高效事件處理
epoll利用紅黑樹存儲待監控的文件描述符,並使用內核層面的回調機制,當有文件描述符就緒時,會直接通知應用程式,從而減少了CPU空轉和上下文切換的成本。
-
文件事件分派器(File Event Demultiplexer):
文件事件分派器是Redis事件驅動的核心組件,它負責將內核傳遞過來的就緒事件分發給對應的處理器。在Redis中,每個套接字都關聯了一個或多個事件處理器,如客戶端連接請求處理器、命令請求處理器和命令響應處理器等。 -
事件處理器(Event Handlers):
事件處理器是Redis中處理特定事件的實際執行者。當文件事件分派器接收到一個就緒事件時,它會調用對應的事件處理器來執行相應操作,如讀取客戶端的命令請求,執行命令並對結果進行編碼,然後將響應數據寫回客戶端。
而對於Redis中設計的事件主要分為兩個大類:
- 文件事件(File Events):主要對應網路I/O操作,包括客戶端連接請求(AE_READABLE事件)、客戶端命令請求(AE_READABLE事件)和服務端命令回覆(AE_WRITABLE事件)。
- 時間事件(Time Events):對應定時任務,如鍵值對過期檢查、持久化操作等。所有時間事件都被存放在一個無序鏈表中,每當時間事件執行器運行時,會遍歷鏈表並處理已到達預定時間的事件。
通過事件驅動架構,Redis能夠在一個線程內併發處理大量客戶端請求,而無需為每個客戶端創建獨立的線程。此外,由於Redis的高效記憶體管理、數據結構優化和單線程模型,避免了多線程環境下的鎖競爭和上下文切換開銷,從而實現了極高的吞吐量和響應速度。
在Redis 6.x版本中,雖然引入了多線程處理網路IO的部分,但核心命令執行依然保持單線程事件驅動的模型,以維持Redis原有的性能優勢。
IO多路復用模型
IO多路復用的核心在於內核關註的是應用程式的文件描述符而非直接監控連接本身。客戶端運行時產生的不同事件類型的套接字操作,會被內核捕獲。在伺服器端,I/O多路復用機制負責收集這些事件並將它們加入事件隊列,隨後通過文件事件分發器分發至對應事件處理器進行處理。
以Redis為例,在其單線程模型下,內核不間斷地監測所有客戶端socket的連接請求和數據傳輸狀況。只要檢測到任何socket上有待處理的動作,便會立即將控制權轉交給Redis線程。這樣一來,儘管僅依靠單線程,Redis仍能有效地處理多個併發的IO流。
select/epoll等IO多路復用技術提供了一種基於事件觸發的回調模式,每當有不同事件發生時,Redis能夠迅速調用相應的事件處理器,始終保持在處理事件的狀態,從而提升了其響應速度。
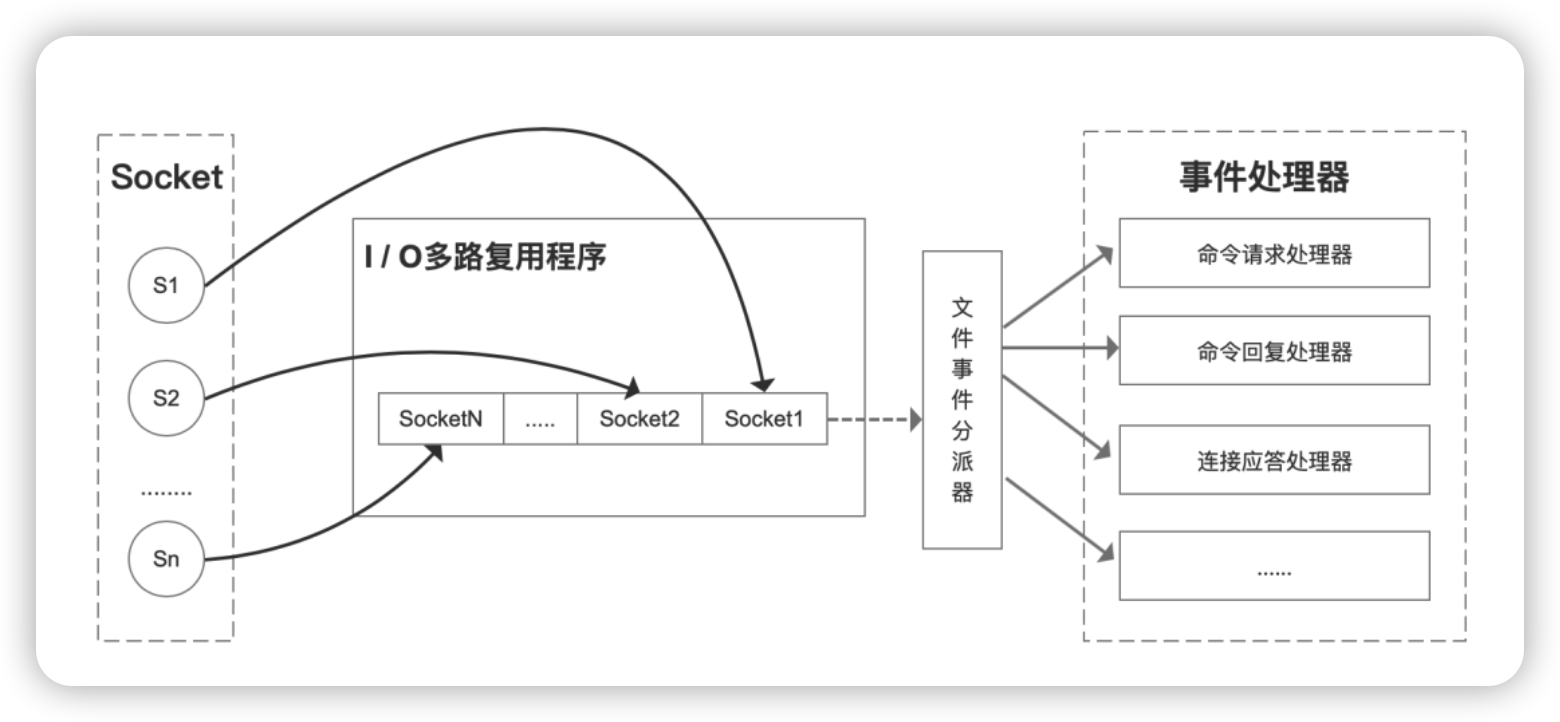
由於Redis線程並不會因為等待某個特定socket的IO操作完畢而停滯,它可以流暢地在多個客戶端間切換,即時響應每個客戶端的不同請求,從而實現在單線程環境下對大量併發連接的有效處理和高併發性能。
簡單高效的通信協議
Redis Cluster在集群內部通信中借鑒了Gossip協議的理念,採用了一種基於Gossip風格的消息傳播機制。這種機制能夠有效地將集群狀態和節點信息在集群中的各個節點間進行快速傳播和同步。類比於流行病的傳播模型,Gossip協議允許節點隨機選擇鄰居節點進行通信,從而在全網狀結構中快速傳播更新。
Redis Cluster、Consul和Apache Cassandra等分散式系統都採用了Gossip協議或者類似的機制來維護集群的健康狀態和一致性。通過Gossip協議,節點們可以高效地共用和更新集群的元數據,如節點加入、離開、故障轉移等信息。
然而,純粹的Gossip協議在實踐中可能存在信息冗餘的問題,即已接收到某一信息的節點在後續的傳播中可能會收到相同的信息。為了避免這種冗餘和提高通信效率,這些系統通常會對Gossip協議進行優化,例如在節點間記錄已知信息的狀態,避免重覆傳播已知的更新。即便如此,Gossip協議仍然是在大規模分散式系統中實現高可用性和強一致性的有效手段,其高效性體現在只需局部通信即可逐漸達成全局一致性,同時具備良好的擴展性和容錯性。
總結
最後,我們來總結一下,如何在面試中回答Redis為什麼快的原因:
-
純記憶體操作:
Redis利用記憶體進行數據存儲,其操作基於記憶體讀寫,由於記憶體訪問速度遠超硬碟,使得Redis在處理數據時具有極高的讀寫速度。特別是對於簡單的存取操作,由於線程在記憶體中執行的時間非常短,主要的時間消耗在於網路I/O,因此Redis在處理大量快速讀寫請求時表現出卓越的性能。 -
單線程模型:
Redis採用單線程模型處理客戶端請求,這一設計確保了操作的原子性,避免了多線程環境下的上下文切換和鎖競爭問題。這使得Redis在處理命令請求時能夠保持高度的確定性和一致性,同時也簡化了編程模型,降低了併發控制的複雜性。 -
IO多路復用技術:
Redis通過採用IO多路復用模型,如epoll,能夠在一個線程中高效地處理多個客戶端連接。單線程輪詢監聽多個套接字描述符,並將資料庫的讀、寫、連接建立和關閉等操作轉化為事件,通過自定義的事件分離器和事件處理器來高效地處理這些事件,從而避免了在等待IO操作時的阻塞。 -
高效數據結構:
-
Redis的整體設計圍繞高效數據結構展開,其中包括但不限於全局哈希表(字典),該結構提供O(1)的平均時間複雜度,並通過rehash操作動態調整哈希桶數量,減少哈希衝突,採用漸進式rehash避免一次性操作過大導致的阻塞。
-
除此之外,Redis還廣泛應用了多種優化過的數據結構,如壓縮表(ziplist)用於存儲短數據以節省記憶體,跳躍表(skiplist)用於有序集合提供快速的範圍查詢,以及其他如列表、集合等數據結構,均針對不同場景進行深度優化,確保了在讀取和操作數據時的高性能。
本文已收錄於我的個人博客:碼農Academy的博客,專註分享Java技術乾貨,包括Java基礎、Spring Boot、Spring Cloud、Mysql、Redis、Elasticsearch、中間件、架構設計、面試題、程式員攻略等


