
一、 智能文檔處理介紹 智能文檔處理(Intelligent Document Processing, IDP)是利用人工智慧(AI)、機器學習(ML)、電腦視覺(CV)、自然語言處理(NLP)等技術自動化地捕獲、理解、處理和分析文檔內容的過程。不同於傳統的文檔管理系統,IDP能夠處理結構化、半結 ...
一、 智能文檔處理介紹
智能文檔處理(Intelligent Document Processing, IDP)是利用人工智慧(AI)、機器學習(ML)、電腦視覺(CV)、自然語言處理(NLP)等技術自動化地捕獲、理解、處理和分析文檔內容的過程。不同於傳統的文檔管理系統,IDP能夠處理結構化、半結構化和非結構化的文檔,從而提取有用信息並將其轉換為可操作的數據。在數字化轉型的大背景下,企業和組織面臨著處理大量文檔數據的挑戰。傳統的方法依賴於人工輸入,不僅效率低下,而且容易出錯。智能文檔處理技術的出現,標志著從手動到自動化處理文檔的重要轉變,它通過將AI技術應用於文檔管理過程,極大地提高了處理速度和準確性,同時降低了成本。
智能文檔處理的發展離不開機器學習、深度學習、OCR(光學字元識別)和自然語言處理等關鍵技術的進步。早期的文檔處理主要依賴於模板匹配和規則-based的方法,這些方法在處理結構化文檔時效果不錯,但面對複雜的非結構化文檔時則顯得力不從心。隨著深度學習技術的突破,尤其是捲積神經網路(CNN)和迴圈神經網路(RNN)在圖像識別和文本處理領域的應用,使得IDP技術能夠更加精準地識別和理解文檔內容。此外,BERT、GPT等預訓練語言模型的出現,進一步推動了IDP技術在理解複雜語言結構和語義上的能力。
智能文檔處理技術的應用意義廣泛,涵蓋了金融、醫療、法律、教育等多個領域。在金融領域,IDP可以幫助銀行和保險公司自動化處理貸款申請、保險理賠等大量的文檔工作,提高審批速度和服務質量。在醫療領域,IDP能夠自動化處理病歷記錄、實驗報告等,提高醫療記錄的準確性和可訪問性。在法律領域,IDP可以輔助律師和法官快速查找和分析大量的法律文件和案件記錄,提高工作效率。智能文檔處理技術正處於快速發展之中,它不僅為企業帶來了高效率和成本節約,也為AI技術的應用開闢了新的領域。通過不斷的技術創新和應用實踐,IDP有望解決更多行業的痛點問題,為數字化轉型提供強有力的支持。
<合合TextIn textin.com - 合合信息旗下OCR雲服務產品 智能文檔處理雲台,提供一站式智能文檔處理產品服務,提供領先的智能文檔處理技術>
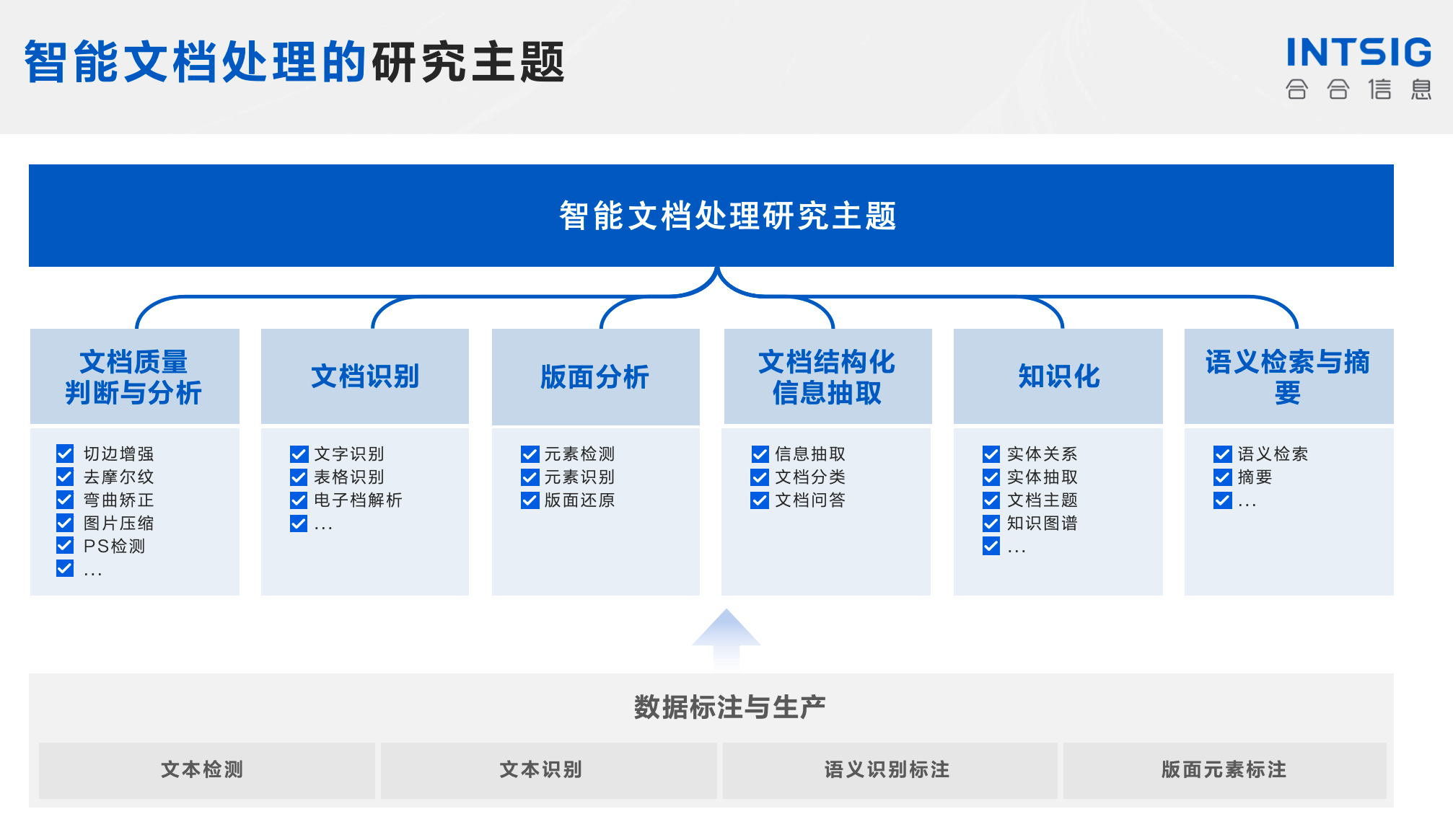

二、文檔格式解析
文檔格式解析是智能文檔處理(IDP)流程中的首要步驟,它涉及對文檔的結構和內容進行理解,為後續的圖像預處理、文字識別和信息提取等環節打下基礎。這一過程要求系統能夠處理和解析各種文檔格式,包括但不限於PDF、DOCX、XLSX、圖片格式(如JPG、PNG)等。
文檔格式解析指的是將各種格式的文檔轉換為機器可讀和可處理的數據結構的過程。這一過程涉及識別文檔的編碼格式、提取文本和元數據、理解文檔結構(如標題、段落、列表、表格等)以及處理嵌入的元素(如圖像、鏈接等)。
文檔格式解析在IDP流程中占據著至關重要的地位。首先,它直接影響到後續處理步驟的效率和準確性。正確解析文檔結構和內容能夠為文字識別和信息提取提供準確的輸入,減少錯誤傳遞。其次,文檔格式解析的靈活性和廣泛性決定了IDP系統能夠處理的文檔種類,進而影響系統的應用範圍和用戶體驗。
文檔格式解析技術主要由以下幾部分組成:
1. 格式識別與轉換:通過分析文件頭信息或使用文件擴展名,確定文檔的格式。針對特定格式的解析器將文檔轉換為統一的數據結構,以便進一步處理。
2. 結構分析:識別和提取文檔的邏輯結構,如章節、標題、段落、列表等。這一步驟通常需要利用機器學習或規則-based的方法來實現。
3. 元數據提取:從文檔中提取作者、創建日期、修改日期等元數據信息,這些信息在某些應用場景下非常重要。
4. 嵌入元素處理:對文檔中嵌入的圖像、鏈接、表格等元素進行識別和提取。對於圖像,可能需要調用OCR技術進行文字識別。
<合合TextIn textin.com - 合合信息旗下OCR雲服務產品 智能文檔處理雲台,提供一站式智能文檔處理產品服務,提供領先的智能文檔處理技術>
三、圖像增強技術解析
圖像增強技術是智能文檔處理(IDP)中的一個關鍵步驟,它通過改善圖像質量來提高後續文字識別(OCR)的準確率。這一技術不僅應用於傳統的文檔掃描圖像,也適用於數字攝影和視頻中的圖像處理。圖像增強技術指的是通過各種演算法和處理技術改善圖像質量的一系列方法。目標是通過提高圖像的可視性或轉換圖像的形式,使其更適合特定的應用,如提高OCR的識別準確率。圖像增強可以包括對比度增強、雜訊去除、銳化處理、去模糊等多種技術。
在IDP流程中,圖像增強的意義主要體現在以下幾個方面:
● 提高準確率:清晰的圖像可以顯著提高文字識別的準確率,尤其是對於低質量或受損圖像。
● 降低處理難度:增強後的圖像簡化了後續處理步驟,如版面分析和信息提取,因為圖像雜訊和失真等問題已經得到瞭解決。
● 增強可用性:某些情況下,原始文檔可能因為年代久遠、存儲條件不佳等原因變得難以閱讀,圖像增強技術可以恢復這些文檔的可用性。
圖像增強技術主要包括以下幾個方面:
1. 切邊增強:切邊增強是一種圖像處理技術,通過增強圖像中的邊緣信息來提高圖像的清晰度和對比度。該技術會突出顯示圖像中物體的邊緣輪廓,使其更加清晰鮮明,從而改善圖像的質量和可視效果。
2. 去摩爾紋:去摩爾紋技術是一種用於消除圖像中出現的摩爾紋現象的方法。摩爾紋是由於圖像採樣頻率與被拍攝物體紋理之間的相互作用而產生的干擾,常見於數字圖像和掃描圖像中。去摩爾紋技術通過數學演算法或濾波器處理來減少或消除這種干擾,從而提高圖像的質量和清晰度。
3. 彎曲矯正:彎曲矯正技術是一種用於修正圖像中出現的彎曲或畸變現象的方法。在圖像採集或傳輸過程中,由於設備或介質的問題,圖像可能會發生彎曲或失真,影響圖像的觀感和應用效果。彎曲矯正技術通過數學模型或幾何校正演算法來對圖像進行修正,使其恢復到原始狀態或更接近真實場景,提高圖像的可用性和可視化效果。
4. 去模糊:去模糊技術是一種用於消除圖像中模糊或不清晰部分的方法。圖像模糊可能是由於攝像機晃動、焦點不准或運動模糊等因素引起的。去模糊技術通過分析圖像模糊的原因並應用相應的演算法或濾波器來恢復圖像的清晰度和細節,使其更具可讀性和觀賞性。
<合合TextIn textin.com - 合合信息旗下OCR雲服務產品 智能文檔處理雲台,提供一站式智能文檔處理產品服務,提供領先的智能文檔處理技術>
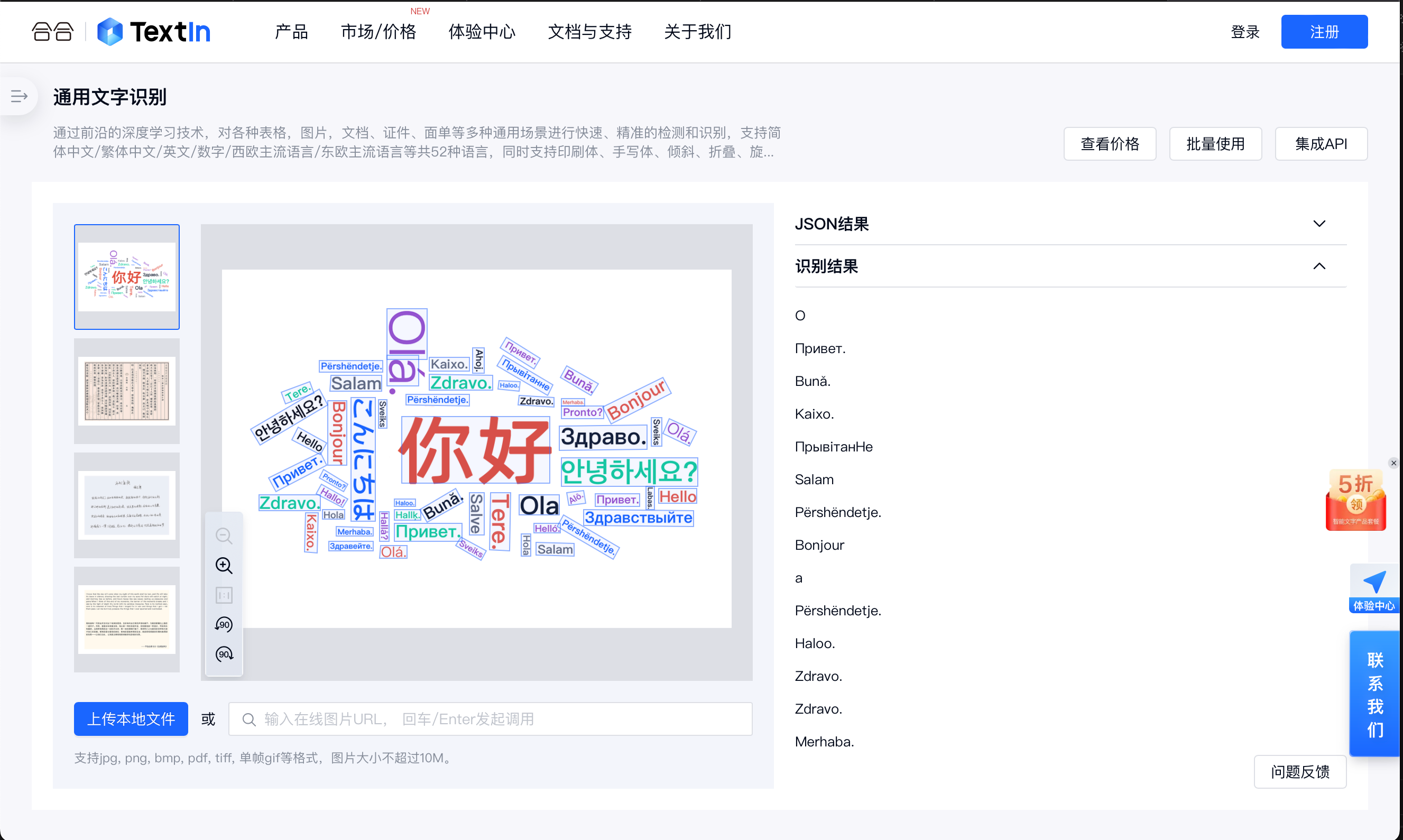
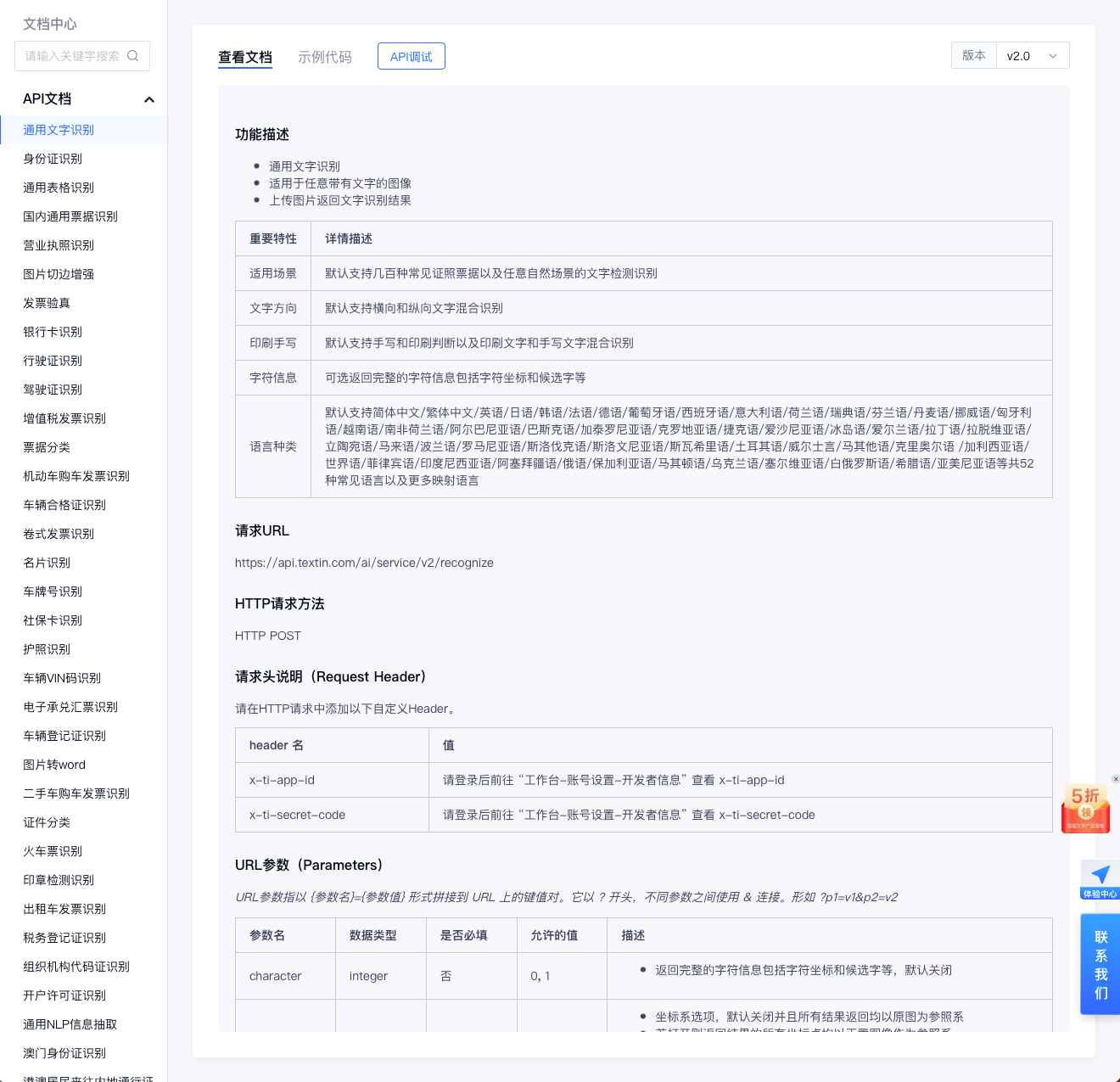
四、傳統文字識別OCR技術解析
文字識別技術,通常稱為光學字元識別(OCR),是智能文檔處理(IDP)中的核心環節。OCR技術使電腦能夠從圖像中識別和轉錄列印或手寫文本,將圖像文件轉換為可編輯和可搜索的文本數據。OCR技術通過分析圖像中的文字區域,識別出其中的字元,並將這些字元轉換為電子文本格式。這項技術能夠處理各種來源的文檔圖像,包括掃描文檔、照片中的文字以及屏幕截圖等。
傳統OCR技術的實現主要依賴以下幾個步驟:
1. 文字定位:通過檢測圖像中的文字區域,確定文字的位置和邊界。這一步驟通常採用邊緣檢測、連通區域分析等技術,以識別出圖像中的文字部分,並對其進行標記或邊界框定位。
2. 文字分割:將定位到的文字區域進行分割,將每個文字字元分離出來,為後續的文字識別做準備。文字分割通常使用投影分割、連通區域分割等方法,將文字區域劃分為單個字元或單詞。
3. 特征提取:對分割後的文字字元進行特征提取,將文字字元轉換成電腦可識別的特征向量或特征描述子。常用的特征提取方法包括形狀特征、結構特征、灰度特征等,用於描述文字字元的形態和結構特征。
4. 文字識別:利用模式識別演算法,對提取到的文字特征進行分類和識別,將文字字元轉換成對應的文本信息。
<合合TextIn textin.com - 合合信息旗下OCR雲服務產品 智能文檔處理雲台,提供一站式智能文檔處理產品服務,提供領先的智能文檔處理技術>
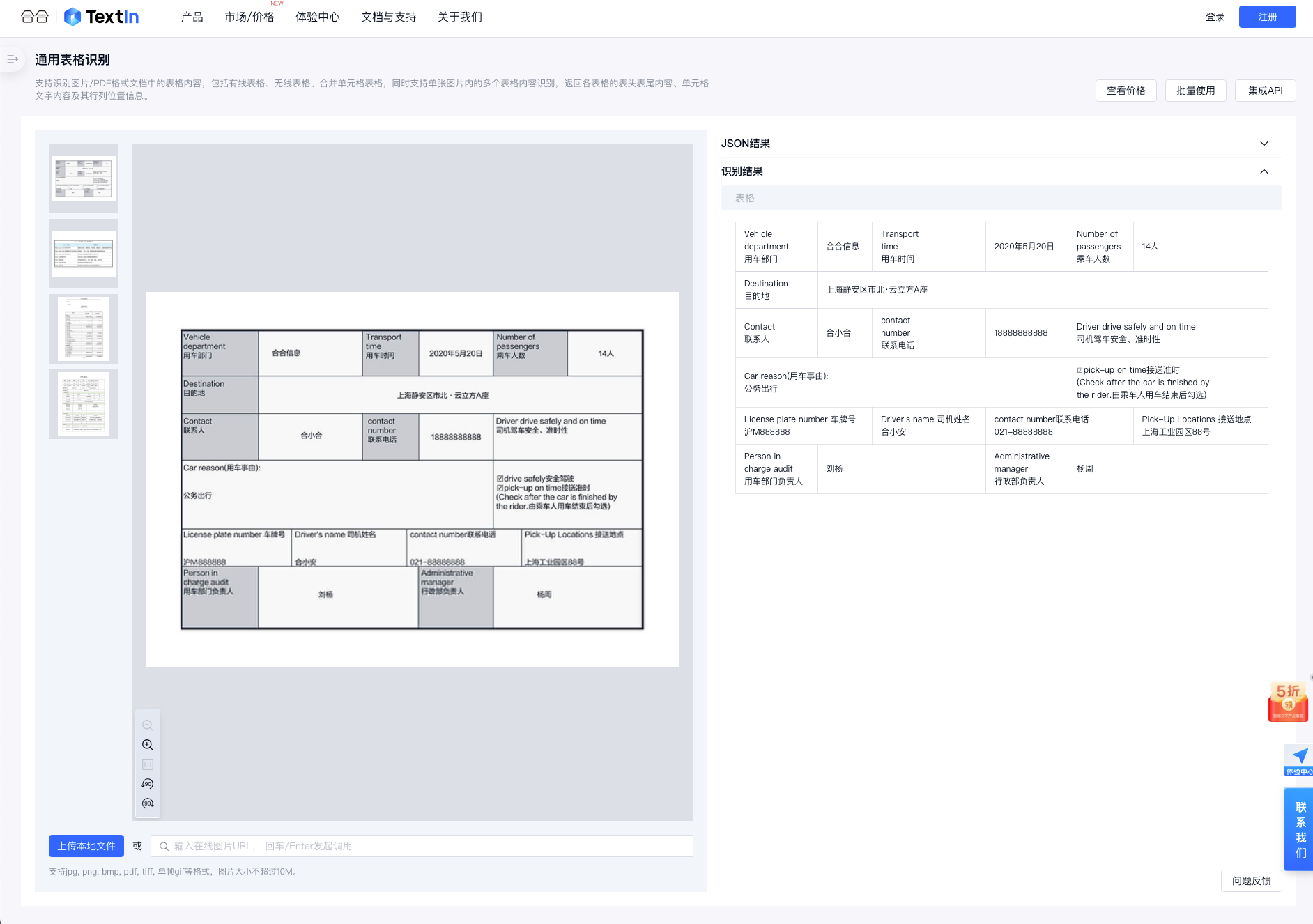
五、深度學習OCR技術解析
光學字元識別(Optical Character Recognition, OCR)技術,特別是基於深度學習的OCR,已成為智能文檔處理(IDP)領域的核心技術之一。深度學習OCR利用複雜的神經網路模型來識別和轉換圖像中的文字為機器可讀的形式。 深度學習OCR技術是指使用深度學習模型,特別是捲積神經網路(CNN)和迴圈神經網路(RNN),來識別圖像中的文字的技術。不同於傳統OCR技術,深度學習OCR能夠更好地處理字體變化、佈局複雜、背景嘈雜等問題,顯著提高了文字識別的準確率和魯棒性。
在IDP流程中,文字識別是將掃描的紙質文檔或數字圖像中的文字內容轉換為電子文本的關鍵步驟。深度學習OCR的應用不僅提高了識別精度,還極大地擴展了OCR技術的應用範圍,包括複雜文檔的處理、多語言識別、手寫文字識別等。此外,它還為後續的信息提取、內容理解提供了高質量的輸入。
深度學習OCR技術的實現主要依賴以下幾個步驟:
1. 數據收集與標註:收集大規模的帶有標註的圖像數據集,包括不同字體、大小、顏色和背景的文字圖像。這些圖像需要經過手工標註,標註每個字元的位置和對應的文本內容,以用於深度學習模型的訓練。
2. 數據預處理:對收集到的圖像數據進行預處理,包括圖像去雜訊、尺度歸一化、灰度化、裁剪等操作,以減少數據的雜訊和干擾,提高深度學習模型的訓練效果。
3. 模型選擇與訓練:選擇合適的深度學習模型架構,如捲積神經網路(CNN)、迴圈神經網路(RNN)、長短期記憶網路(LSTM)、轉錄者(Transformer)等,進行模型的訓練和優化。在訓練過程中,使用標註好的圖像數據集,通過反向傳播演算法和梯度下降優化演算法,不斷調整模型參數,使其能夠準確地識別文字。
4. 模型評估與調優:通過驗證集或測試集對訓練好的深度學習模型進行評估,包括識別準確率、召回率、精確率等指標的評估。根據評估結果,對模型進行調優和改進,以提高模型的識別準確性和泛化能力。
<合合TextIn textin.com - 合合信息旗下OCR雲服務產品 智能文檔處理雲台,提供一站式智能文檔處理產品服務,提供領先的智能文檔處理技術>
六、深度學習版面分析技術解析
版面分析是智能文檔處理(IDP)中的關鍵環節,它涉及對文檔頁面的結構和佈局進行分析,以識別和分類文檔中的各種元素,如文本塊、圖像、表格等。隨著深度學習技術的發展,版面分析的能力得到了顯著提升,使得處理複雜文檔佈局成為可能。 深度學習版面分析技術利用深度神經網路,尤其是捲積神經網路(CNN)和迴圈神經網路(RNN),對文檔頁面的佈局和結構進行自動分析和理解。這項技術能夠識別頁面上的不同元素類型,並理解它們之間的空間關係和邏輯結構,為後續的文本識別、內容提取和信息理解提供基礎。
在IDP流程中,版面分析的意義主要體現在以下幾個方面:
支持複雜文檔處理:深度學習技術使版面分析能夠處理多樣化和複雜的文檔佈局,提高了系統的適用範圍。
● 自動化內容提取:準確的版面分析為提取特定信息(如表格數據、標題、摘要等)提供了可能,進一步促進了文檔自動化處理的實現。
深度學習版面分析技術主要包括以下幾個關鍵步驟:
1. 元素檢測:利用深度學習模型,如目標檢測模型(如Faster R-CNN、YOLO、SSD等),對文檔圖像中的各種元素進行檢測和定位。這些元素可以包括文字、圖像、表格、標題等。通過元素檢測,可以確定文檔中不同元素的位置和邊界框,為後續的分析和處理提供基礎。
2. 元素分類:對檢測到的元素進行分類,區分文字、圖像、表格等不同類型的元素。這一步驟可以採用深度學習中的圖像分類模型或目標分類模型,對每個元素進行識別和分類,以便後續的結構解析和語義理解。
3. 結構解析:在元素檢測和分類的基礎上,進行文檔的結構解析,識別文檔中不同元素之間的關係和層次結構。這包括文本段落與標題的對應關係、表格中不同欄位的關係等。深度學習模型可以通過對文檔佈局和語義信息的分析,實現對文檔結構的自動解析和理解。
4. 版面校正:對檢測到的文檔元素進行版面校正,使其在整體文檔中的位置和排布更加合理和統一。這一步驟可以包括文本對齊、圖像矯正、表格對齊等操作,以提高文檔的可讀性和美觀性。版面校正也可以通過深度學習模型來實現,例如基於生成對抗網路(GAN)的版面重構方法。
<合合TextIn - 合合信息旗下OCR雲服務產品 智能文檔處理雲平臺提供一站式智能文檔處理產品服務,提供領先的版面分析技術產品>
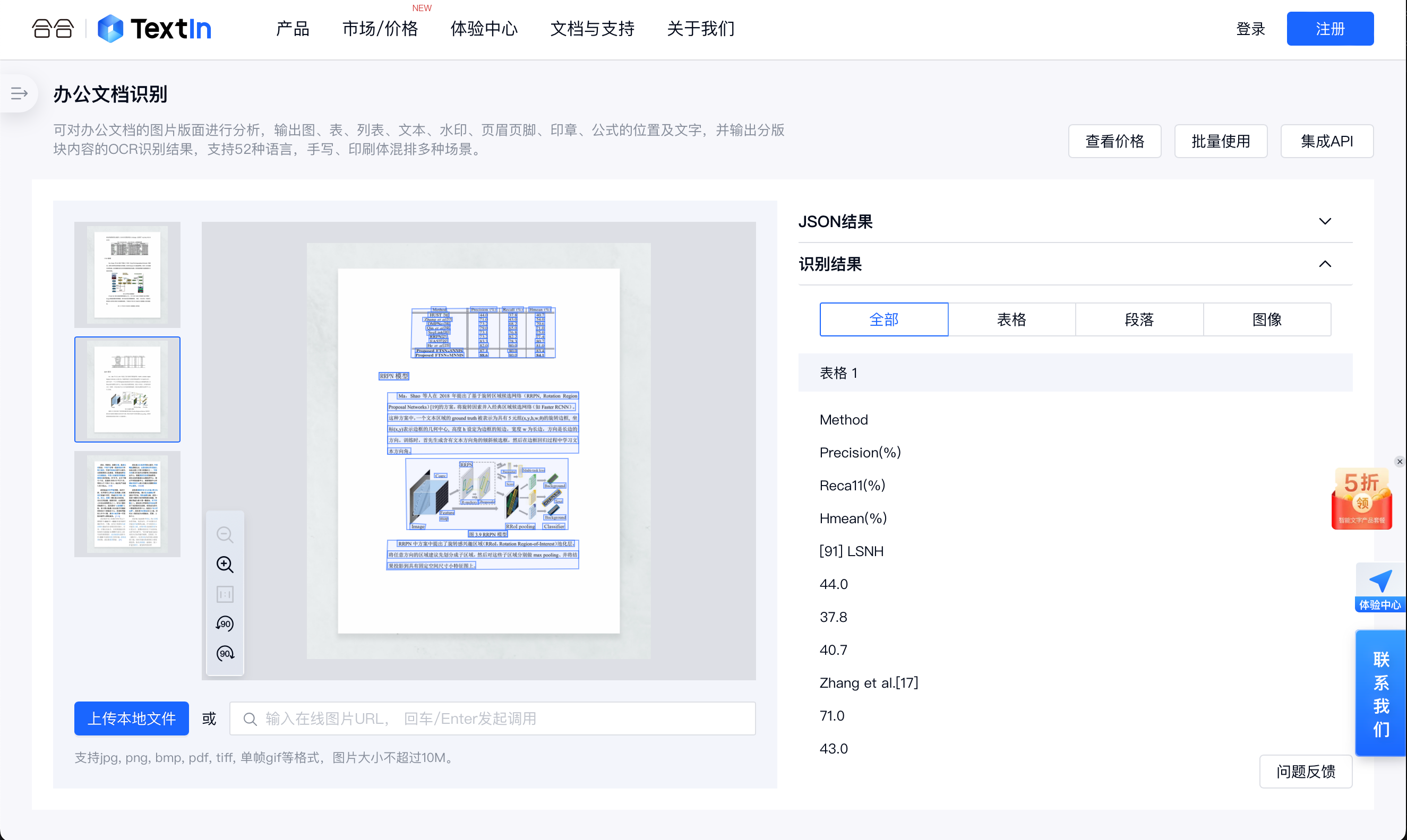
七、文檔分類
文檔分類是智能文檔處理(IDP)中的一個關鍵環節,它涉及自動將文檔按照其內容、用途或結構分類到預定義的類別中。隨著人工智慧和機器學習技術的發展,文檔分類的方法和效率都有了顯著的提升。本章節將從定義、流程中的意義、技術組成、技術發展等多個維度全面介紹文檔分類技術。文檔分類指的是利用電腦程式自動識別和歸類文檔的過程。這涉及到理解文檔的內容和結構,並將其分配到一個或多個預設的類別中。分類的依據可以是文檔的主題、風格、作者、發佈日期等多個維度。
文檔分類技術主要包括:
1. 使用圖片特征分類:圖片特征的分類主要依賴於從文檔中提取的視覺信息。這通常涉及到圖像處理和電腦視覺技術,用於識別文檔中的圖形、佈局和其他視覺元素。其中步驟包含特征提取、特征表示和降維、分類模型構建等步驟。
2. 使用文本特征分類:文本特征的分類依賴於文檔中的文字內容,涉及自然語言處理(NLP)技術,用於理解和分類文檔的語義內容。其中步驟包含文本預處理、特征提取、模型構建、模型評估等步驟。
<合合TextIn - 合合信息旗下OCR雲服務產品 智能文檔處理雲平臺提供一站式智能文檔處理產品服務,提供領先的文檔分類技術>
八、信息抽取
信息抽取(Information Extraction, IE)是智能文檔處理(IDP)中的關鍵技術之一,它涉及從非結構化或半結構化文檔中自動識別和提取出有價值的信息,如實體、關係、事件等。隨著自然語言處理(NLP)和機器學習技術的發展,信息抽取的能力和應用範圍不斷擴大。
信息抽取技術指的是利用電腦演算法從文本中自動識別和提取預定義類型的信息的過程。這些信息通常包括但不限於人名、地點、組織、時間表達、專有名詞、事件和實體之間的關係等。
意義
在IDP流程中,信息抽取的意義主要體現在:
● 支持決策和分析:通過從大量文檔中抽取關鍵信息,可以為決策制定和數據分析提供有價值的輸入。
● 提高自動化程度:自動化的信息抽取減少了人工審核和錄入的需要,提高了處理效率和準確性。
● 促進知識管理:信息抽取有助於構建知識庫,支持知識檢索和管理。
技術
信息抽取技術主要包括以下幾個關鍵組成部分:
1. 實體識別(Named Entity Recognition, NER):識別文本中的具名實體,如人名、地點和組織。
2. 關係抽取:識別文本中實體之間的關係,如“公司-CEO”或“人物-出生地”等。
3. 事件抽取:識別文本中的事件及其相關屬性和參與實體,如事件類型、時間、地點和參與者等。
4. 觀點抽取(Opinion Mining):從文本中抽取觀點、情感和評價,通常用於產品評論、市場分析等領域。
5. 術語抽取:從專業文檔中識別和提取關鍵術語和定義,用於構建術語庫或知識圖譜。
發展
信息抽取技術的發展經歷了以下幾個階段:
● 規則基礎方法:早期的信息抽取系統主要依賴於手工編寫的規則。這種方法在特定領域內效果明顯,但缺乏通用性和擴展性。
● 機器學習方法:隨著機器學習技術的發展,信息抽取開始採用監督學習、半監督學習和無監督學習方法。通過訓練模型識別文本模式,提高了抽取的準確率和靈活性。
● 深度學習方法:近年來,基於深度學習的信息抽取方法成為研究熱點,尤其是利用CNN、RNN和Transformer等神經網路模型。這些模型能夠更好地理解文本的深層次語義,顯著提高了信息抽取的性能。
● 端到端信息抽取:最新的研究趨勢是開髮端到端的信息抽取系統,這些系統能夠直接從原始文本中抽取出結構化信息,無需複雜流程。
<合合TextIn - 合合信息旗下OCR雲服務產品 智能文檔處理雲平臺提供一站式智能文檔處理產品服務,提供領先的信息抽取技術>

九、系統集成:將IDP處理後的數據集成到企業系統
系統集成在智能文檔處理(IDP)完成之後,將處理得到的結構化數據有效地集成到企業的業務系統中,對於提升企業的業務流程效率和推進企業信息化建設至關重要。這一過程需要將IDP系統與企業內部的各種業務系統(如CRM、ERP、CMS等)以及全球主流的企業軟體平臺進行有效對接。本章節將詳細介紹IDP處理後的數據如何通過多種方式集成到中國及全球的主流各種業務系統里,服務於企業業務流程和企業信息化。
數據集成的方式
API集成
● 定義:應用程式介面(API)提供了一種讓不同軟體系統彼此通信的方法。通過開發和使用API,IDP系統可以將結構化數據直接發送到目標業務系統。
● 應用場景:實時數據傳輸、需要高度定製化集成的場景。
文件導入/導出
● 定義:一種基礎但廣泛使用的數據集成方法,涉及將數據導出為通用格式(如CSV、XML、JSON等),然後導入到目標系統。
● 應用場景:批量數據處理、非實時數據更新需求。
資料庫集成
● 定義:直接通過資料庫級別的操作,將IDP處理後的數據存儲到企業的資料庫系統中,再由各業務系統從資料庫中讀取所需數據。
● 應用場景:數據量大、需要長期存儲和復用的場景。
集成到全球主流業務系統的示例
集成到CRM系統
● 場景:將客戶相關的文檔(如合同、通信記錄)處理後的數據自動更新到客戶關係管理(CRM)系統,以提供更準確的客戶視圖和服務。
● 技術方式:API集成、資料庫集成。
集成到ERP系統
● 場景:將發票、訂單等財務文檔處理後的數據自動錄入企業資源計劃(ERP)系統,簡化財務流程,提高財務處理速度和準確性。
● 技術方式:文件導入/導出、API集成。
集成到CMS系統
● 場景:將新聞、報告等內容文檔處理後的數據自動歸檔和分類到內容管理系統(CMS),加速內容的發佈流程。
● 技術方式:API集成、中間件技術。
集成到全球雲平臺
● 場景:將處理後的數據集成到阿裡雲、百度雲、AWS、Azure、Google Cloud等全球雲平臺提供的資料庫和應用服務中,利用雲平臺的強大計算和存儲能力支持企業的大數據分析和應用開發。
● 技術方式:API集成、中間件技術。
<合合TextIn - 合合信息旗下OCR雲服務產品 智能文檔處理雲平臺提供一站式智能文檔處理產品服務,提供API集成文檔、全語言示例代碼>
如有幫助,請多關註
TeahLead KrisChang,10+年的互聯網和人工智慧從業經驗,10年+技術和業務團隊管理經驗,同濟軟體工程本科,復旦工程管理碩士,阿裡雲認證雲服務資深架構師,上億營收AI產品業務負責人。

