
ClickHouse是用於分析的OLAP資料庫,因此典型的使用場景是處理相對較少的請求 — 從每小時幾個到每秒幾十甚至幾百個不等 — 但會影響到大量數據(幾GB/數百萬行)。 但是在其他情況下,它的表現如何?讓我們嘗試用大量小請求來測試ClickHouse如何處理。這將幫助我們更好地瞭解可能的使用場 ...
ClickHouse是用於分析的OLAP資料庫,因此典型的使用場景是處理相對較少的請求 — 從每小時幾個到每秒幾十甚至幾百個不等 — 但會影響到大量數據(幾GB/數百萬行)。
但是在其他情況下,它的表現如何?讓我們嘗試用大量小請求來測試ClickHouse如何處理。這將幫助我們更好地瞭解可能的使用場景範圍和限制。
本文分為兩個部分:
- 連接基準測試和測試設置
- 涉及實際數據的最大QPS的場景
環境
對於初始測試,我選擇了一臺舊工作站:
- 4核 Intel(R) Core(TM) i5-2400 CPU @ 3.10GHz
- 8GB RAM
- SSD硬碟
- CentOS 7
本文中呈現的結果是從該電腦收集的,但當然,很有趣的是在更強大的硬體上重覆這些測試。我把這項任務交給我們的讀者,這樣你就可以在自己的硬體上測試ClickHouse在不同場景下的最大QPS。如果你這樣做了,請分享你的結果!為了運行基準測試,我還創建了一組腳本,可以在Altinity的GitHub上免費獲取:https://github.com/Altinity/clickhouse-sts/。這些腳本需要Docker(我使用的是v18.09)和Bash。要運行測試套件,只需克隆GitHub存儲庫,併在根文件夾中運行‘make test’命令。它會在你的主機上執行所有測試(需要幾個小時),並將結果放入一個CSV文件中,稍後可以在Excel、Pandas或ClickHouse本身中進行分析。當然,你也可以分享你的發現,以便與本文中的結果進行比較。
這些腳本使用了以下工具:
- https://github.com/wg/wrk,一個輕量級且快速的HTTP基準測試工具,允許創建不同的HTTP工作負載
- ClickHouse發行版中包含的clickhouse-benchmark工具,用於本地協議ClickHouse測試
這兩個工具都允許你創建所需併發量的負載(模擬不同數量的併發客戶端),並測量每秒處理的查詢數和延遲百分位數。
關於ClickHouse處理併發請求的幾點說明
預設情況下,ClickHouse可以處理高達4096個入站連接(max_connections在伺服器配置文件中設置),但只會同時執行100個查詢(max_concurrent_queries),因此所有其他客戶端將在隊列中等待。客戶端請求可以保持在隊列中的最長時間由queue_max_wait_ms設置定義(預設為5000或5秒)。這是一個用戶/配置文件設置,因此用戶可以定義較小的值,在隊列過長的情況下提示異常。http連接的長連接超時預設相對較短 — 3秒(keep_alive_timeout設置)。
還有許多高級網路相關設置,用於微調不同的超時、輪詢間隔、監聽回溯大小等設置。
HTTP ping:HTTP伺服器的理論最大吞吐量
首先,讓我們檢查ClickHouse自身使用的HTTP伺服器有多快。換句話說,伺服器可以處理多少個“無所事事”的請求。
對於HTTP,兩種主要情況很重要:
- 使用保持連接(保持持久連接進行多個請求,而無需重新連接)
- 不使用保持連接(每個請求都建立新連接)
此外,預設情況下ClickHouse的日誌級別非常詳細(‘trace’)。對於每個查詢,它會嚮日志文件寫入幾行,這對於調試很好,但當然會增加一些額外的延遲。因此,我們還要檢查禁用日誌的相同2種場景。
我們對不同併發級別進行了測試,以模擬不同數量的同時連接的客戶端(一個接一個地發送請求)。每個測試執行15秒,然後取每秒處理的平均請求數。
結果:
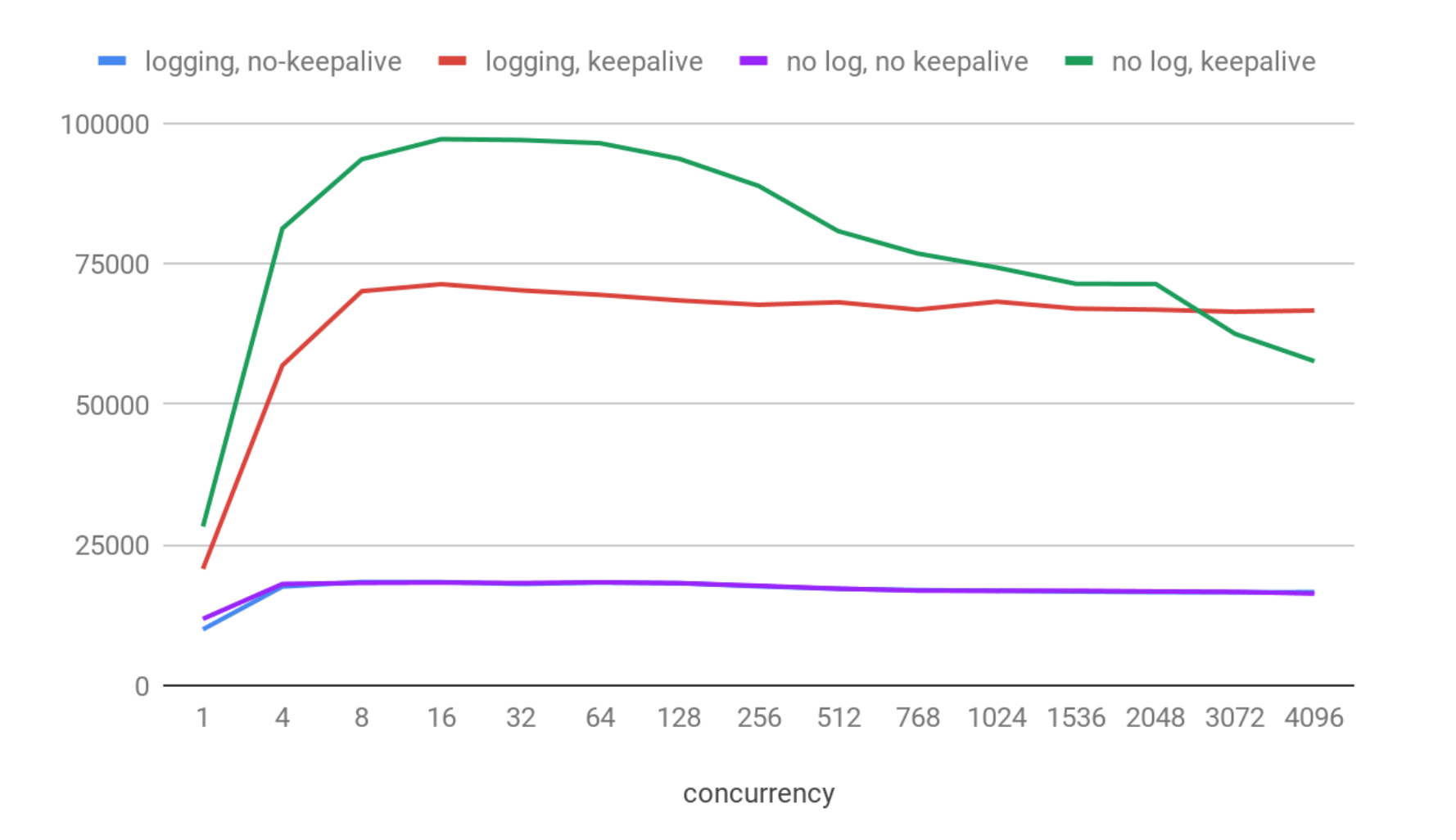
在X軸上,您可以看到同時連接的客戶端數。在Y軸上,我們有每個特定場景中每秒處理的平均請求數。
好吧,結果看起來不錯:
- 在每個場景中,在8到64個併發連接之間,QPS的最大值都在那台機器上。
- 最大吞吐量約為97K QPS,啟用保持連接並禁用日誌。
- 啟用日誌時,速度要慢大約30%,大約為71K QPS。
- 兩個不使用保持連接的變體要慢得多(約為18.5 kqps),甚至在這裡看不出日誌開銷。這是預期的,因為使用保持連接,ClickHouse肯定可以處理更多的ping,因為跳過了為每個請求建立連接的額外成本。
現在我們對最大理論可能吞吐量有了感覺,以及ClickHouse Web伺服器可以實現的併發級別。實際上,ClickHouse的HTTP伺服器實現相當快。例如,NGINX在相同的機器上使用預設設置大約可以提供30K每秒。
SELECT 1
讓我們再進一步,檢查一個微不足道的 ‘SELECT 1’ 請求。這樣的查詢在查詢解析階段被‘執行’,因此這將展示‘網路 + 授權 + 查詢解析器 + 格式化結果’的理論最大吞吐量,即真實請求永遠不會更快。
我們將測試使用保持連接和不使用保持連接的http和https選項,以及本地客戶端(安全和非安全)。
結果如下:
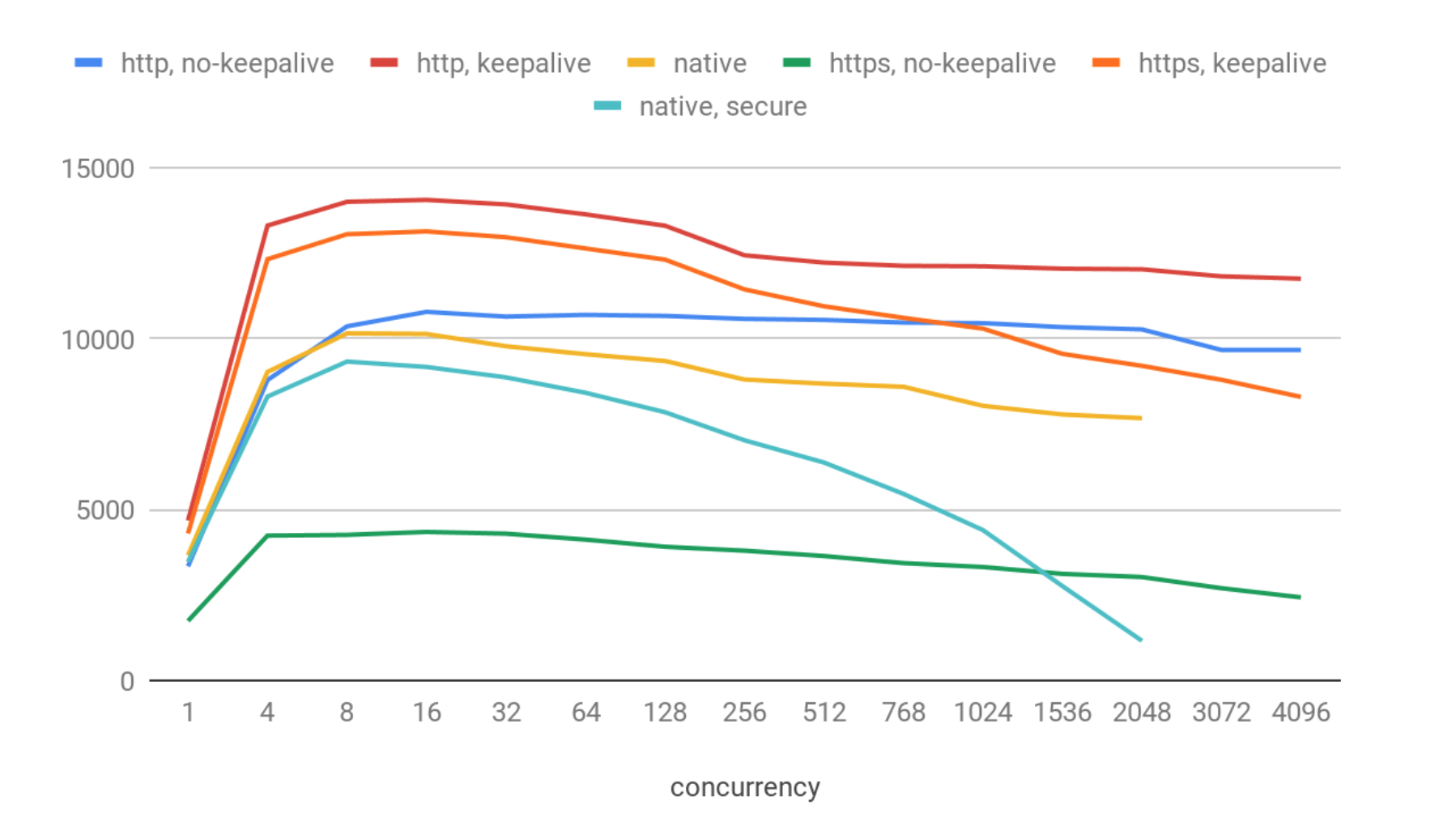
這些結果與簡單的ping相比顯示了相當大的降級。我們得到了:
- 最佳情況下約為14K QPS:http & 保持連接。
- https & 保持連接情況稍差(13K QPS)。在這種情況下,https的開銷並不顯著。
- http 不使用保持連接時約為10.7 kqps。
- 本地客戶端(不安全)約為10.1 kqps。
- 本地客戶端(安全)約為9.3 kqps。
- 無保持連接的https表現相當差,約為4.3 kqps。
在最高併發級別上,我們註冊了幾十個連接錯誤(即少於0.01%),這很可能是由於操作系統層面的套接字重用問題引起的。ClickHouse在該測試中表現穩定,我沒有註冊到任何明顯的問題。
本地協議顯示的性能比http更差可能會讓人驚訝,但實際上這是預期的:本地TCP/IP更加複雜,具有許多額外的協議特性。它不適合高QPS,而是適合傳輸大塊數據。
此外,在本地客戶端中,隨著併發性增加,QPS會出現相當大的下降,在更高的併發級別(>3000)時系統會變得不響應並返回無結果。這很可能是由於clickhouse-benchmark工具為每個連接使用一個單獨的線程,線程數和上下文切換過多導致的。
現在讓我們看看延遲,即每個客戶端等待答案的時間。這個數字在每個請求中會有所變化,因此圖表顯示了每種情況下延遲的90th percentile。這意味著90%的用戶得到的答案比顯示的數字更快。
延遲(90th percentile)– 1-256 併發級別
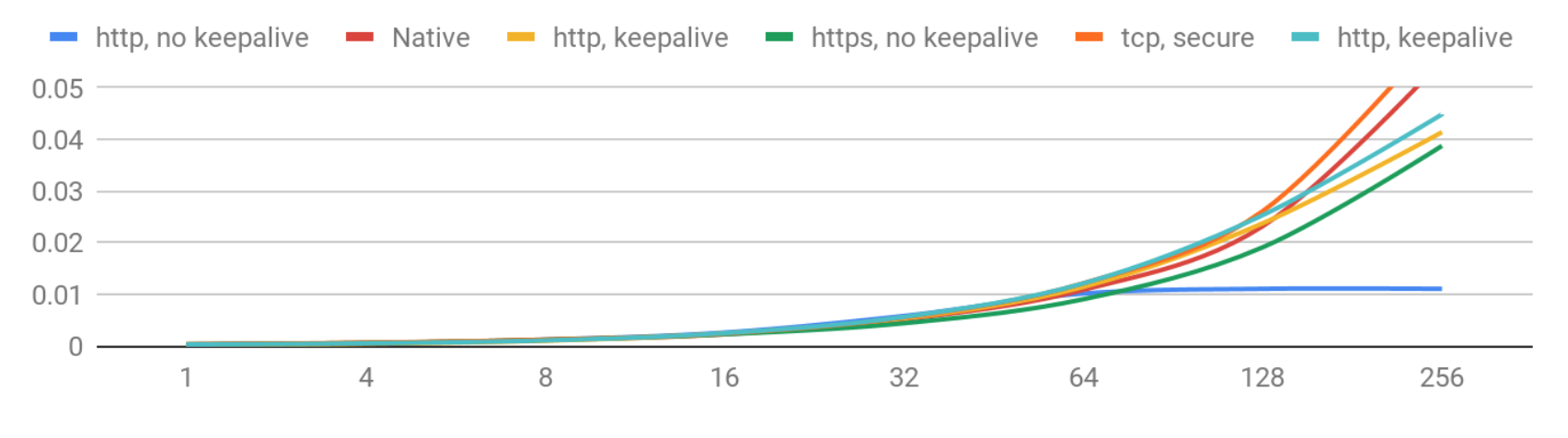
隨著併發性的增長,延遲的惡化是可以預料的。目前看起來非常不錯:如果您少於256個併發用戶,您可以期望延遲在50毫秒以下。
讓我們看看高併發性會如何影響。
延遲(90th percentile)– >256 併發級別
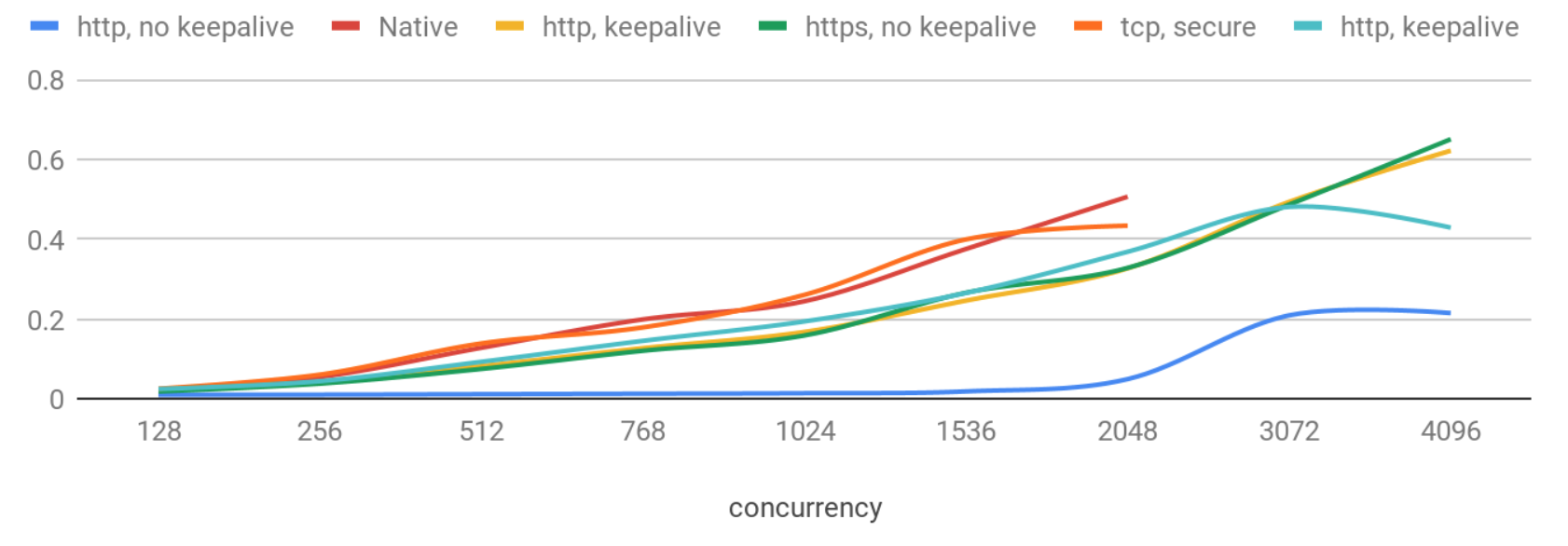
現在延遲的惡化更為顯著,而且本地協議再次顯示出最差的結果。
有趣的是,不使用保持連接的http請求表現非常穩定,並且即使有2K併發用戶,延遲也低於50ms。沒有保持連接時,延遲更加可預測,並且標準差在併發性增加時保持較小,但QPS會略有降低。這可能與Web伺服器的實現細節有關:例如,當使用每個連接一個線程時,線程上下文切換可能會減慢伺服器速度,併在一定併發級別後增加延遲。
我們還檢查了其他設置,如max_concurrent_queries、queue_max_wait_ms、max_threads、network_compression_method、enable_http_compression以及一些輸出格式。在這種情況下調整它們的影響大多是可以忽略的。
多線程的影響
預設情況下,ClickHouse使用多個線程處理更大的查詢,以有效利用所有CPU核心。
然而,如果您有大量併發連接,多線程將會增加上下文切換、重新加入線程和工作同步方面的額外成本。
為了衡量併發連接與多線程之間的相互作用,讓我們來看一下使用預設多線程設置和max_threads=1設置進行的合成選擇,以找到最大的100K個隨機數的差異。
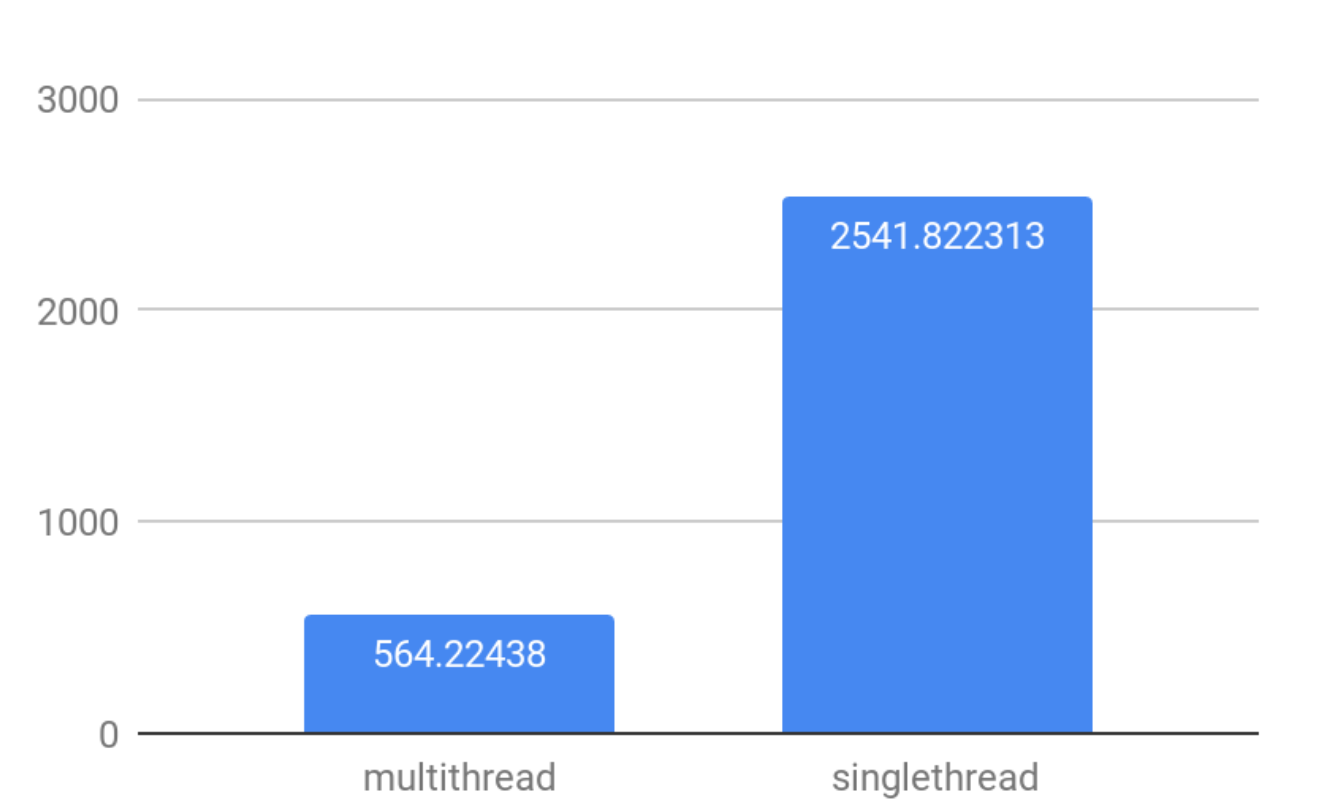
結論非常簡單:在高併發場景中實現更高的QPS,使用max_threads=1設置。
未完待續…
本文涵蓋了對ClickHouse的一般連接性測試。我們檢查了伺服器本身的速度有多快,它可以處理多少簡單查詢以及哪些設置會影響高併發場景下的QPS。請查看後續文章,我們將深入估算在鍵值場景中實際查詢的最大QPS,這將為測試案例添加數據。
關註我,緊跟本系列專欄文章,咱們下篇再續!
作者簡介:魔都技術專家兼架構,多家大廠後端一線研發經驗,各大技術社區頭部專家博主。具有豐富的引領團隊經驗,深厚業務架構和解決方案的積累。
負責:
- 中央/分銷預訂系統性能優化
- 活動&優惠券等營銷中台建設
- 交易平臺及數據中台等架構和開發設計
目前主攻降低軟體複雜性設計、構建高可用系統方向。
參考:
本文由博客一文多發平臺 OpenWrite 發佈!


