
Pandas無疑是我們數據分析時一個不可或缺的工具,它以其強大的數據處理能力、靈活的數據結構以及易於上手的API贏得了廣大數據分析師和機器學習工程師的喜愛。 然而,隨著數據量的不斷增長,如何高效、合理地管理記憶體,確保Pandas DataFrame在運行時不會因記憶體不足而崩潰,成為我們每一個人必須面 ...
Pandas無疑是我們數據分析時一個不可或缺的工具,它以其強大的數據處理能力、靈活的數據結構以及易於上手的API贏得了廣大數據分析師和機器學習工程師的喜愛。
然而,隨著數據量的不斷增長,如何高效、合理地管理記憶體,確保Pandas DataFrame在運行時不會因記憶體不足而崩潰,成為我們每一個人必須面對的問題。
在這個信息爆炸的時代,數據規模呈指數級增長,如何優化記憶體使用,不僅關乎到程式的穩定運行,更直接關係到數據處理的效率和準確性。通過本文,你將瞭解到一些實用的記憶體優化技巧,幫助你在處理大規模數據集時更加得心應手。
1. 準備數據
首先,準備一些包含各種數據類型的測試數據集。
封裝一個函數(fake_data),用來生成數據集,數據集中包含後面用到的幾種欄位。
import pandas as pd
import numpy as np
def fake_data(size):
"""
根據測試數據集:
age:整數類型數值
grade:有限個數的字元串
qualified:是否合格
ability:能力評估,浮點類型數值
"""
df = pd.DataFrame()
df["age"] = np.random.randint(1, 30, size)
df["grade"] = np.random.choice(
[
"一年級",
"二年級",
"三年級",
"四年級",
"五年級",
"六年級",
],
size,
)
df["qualified"] = np.random.choice(["合格", "不合格"], size)
df["ability"] = np.random.uniform(0, 1, size)
return df
2. 檢測記憶體占用
使用上面封裝的函數(fake_data)先構造一個包含一百萬條數據的DataFrame。
df = fake_data(1_000_000)
df.head()
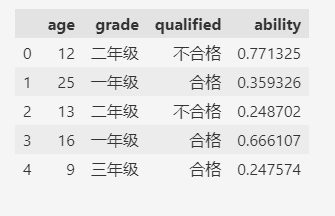
看看優化前的記憶體占用情況:
df.info()
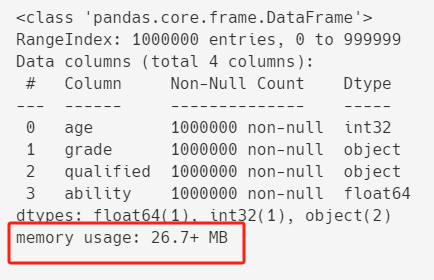
記憶體占用大約 26.7MB 左右。
3. 優化記憶體
接下來,我們開始一步步優化DataFrame的記憶體占用,
並測試每一步優化之後的記憶體使用情況和運行性能變化。
3.1. 優化整型數據
首先,優化整型數據的記憶體占用,也就是測試數據中的年齡(age)欄位。
從上面df.info()的結果中,我們可以看出,age的類型是int32(也就是用32位,8個位元組來存儲整數)。
對於年齡來說,用不到這麼大的整數,用int8(數值範圍:-128~127)來存儲綽綽有餘。
df["age"] = df["age"].astype("int8")
df.info()
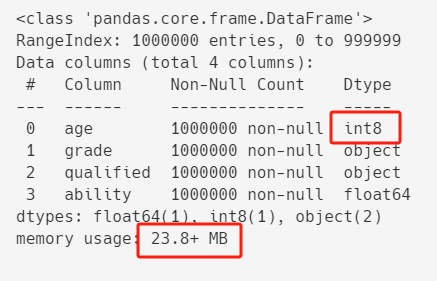
優化之後,記憶體占用從26.7+ MB減到23.8+ MB。
3.2. 優化浮點型數據
接下來優化浮點類型數據,也就是測試數據中的能力評估值(ability)。
測試數據中ability的值是6位小數,類型是float64,
轉換成float16可能會改變值,所以這裡轉換成float32。
df["ability"] = df["ability"].astype("float32")
df.info()
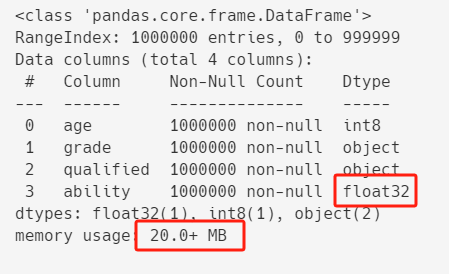
優化之後,記憶體占用進一步從23.8+ MB減到20.0+ MB。
3.3. 優化布爾型數據
接下來,優化測試數據中的是否合格(qualified),
這個值雖然是字元串類型,但是它的值只有兩種(合格和不合格),所以可以轉換成布爾類型。
df["qualified"] = df["qualified"].map({"合格": True, "不合格": False})
df.info()
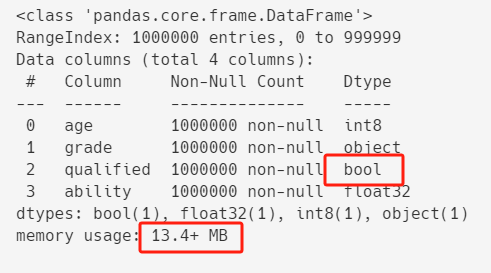
優化之後,記憶體占用進一步從20.0+ MB減到13.4+ MB。
3.4. 使用category類型
最後,我們再優化剩下的欄位--年級(grade)。
這個欄位也是字元串,不過它的值只有6個,雖然無法轉換成布爾類型(布爾類型只有兩種值True和False),但是它可以轉換為pandas中的 category 類型。
df["grade"] = df["grade"].astype("category")
df.info()
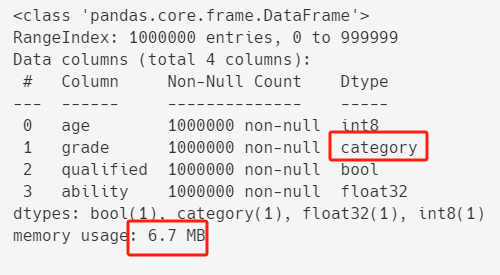
優化之後,記憶體占用進一步從13.4+ MB減到6.7+ MB。
4. 總結
各類欄位優化之後,記憶體占用從剛開始的26.7+ MB減到6.7+ MB,優化的效果非常明顯。
僅僅是數據類型的簡單調整,就帶來瞭如此之大的記憶體效率提升,
這也給我們帶來啟示,在數據分析的過程中,構造DataFrame時,也可以根據數值的範圍,特點等,
來賦予它合適的類型,不要一味簡單的使用字元串,或者預設的整數(int32),預設的浮點(float64)等類型。


