
在我們講解這個案例前,我們先來瞭解/預熱一下SQL Server的兩個概念:鍵查找(key lookup)和RID查找(RID lookup),通常,當查詢優化器使用非聚集索引進行查找時,如果所選擇的列或查詢條件中的列只部分包含在使用的非聚集索引和聚集索引中時,就需要一個查找(lookup)來檢索其 ...
在我們講解這個案例前,我們先來瞭解/預熱一下SQL Server的兩個概念:鍵查找(key lookup)和RID查找(RID lookup),通常,當查詢優化器使用非聚集索引進行查找時,如果所選擇的列或查詢條件中的列只部分包含在使用的非聚集索引和聚集索引中時,就需要一個查找(lookup)來檢索其他欄位來滿足請求。對一個有聚簇索引的表來說是一個鍵查找(key lookup),對一個堆表來說是一個RID查找(RID lookup),這種查找即是——書簽查找(bookmark lookup)。在其他資料庫概念中,可能又叫回表查詢之類的概念。
那麼我們先來構造案例所需的測試環境。下麵測試環境為SQL Server 2014。
SELECT * INTO TEST FROM SYS.OBJECTS
CREATE CLUSTERED INDEX PK_TEST ON TEST(OBJECT_ID, NAME,CREATE_DATE)
CREATE INDEX IX_TEST_N1 ON TEST(PARENT_OBJECT_ID, TYPE)
UPDATE STATISTICS TEST WITH FULLSCAN;
如上所示,表TEST在欄位OBJECT_ID, NAME,CREATE_DATE建立了聚集索引,然後下麵這種查詢語句,你查看其實際執行計劃
SELECT OBJECT_ID, NAME,CREATE_DATE,PARENT_OBJECT_ID, TYPE
FROM TEST WHERE PARENT_OBJECT_ID=2255213;
你會發現,SQL Server優化器走索引IX_TEST_N1查找就返回了所有數據。沒有書簽查找(回表查詢),那麼這是為什麼呢?朋友這樣問我的時候,我還真沒有想明白。難道索引IX_TEST_N1中也會存儲OBJECT_ID, NAME,CREATE_DATE的值? 當然你構造其它的案例時,有可能是索引IX_TEST_N1掃描就返回了數據。不會發生書簽查找。
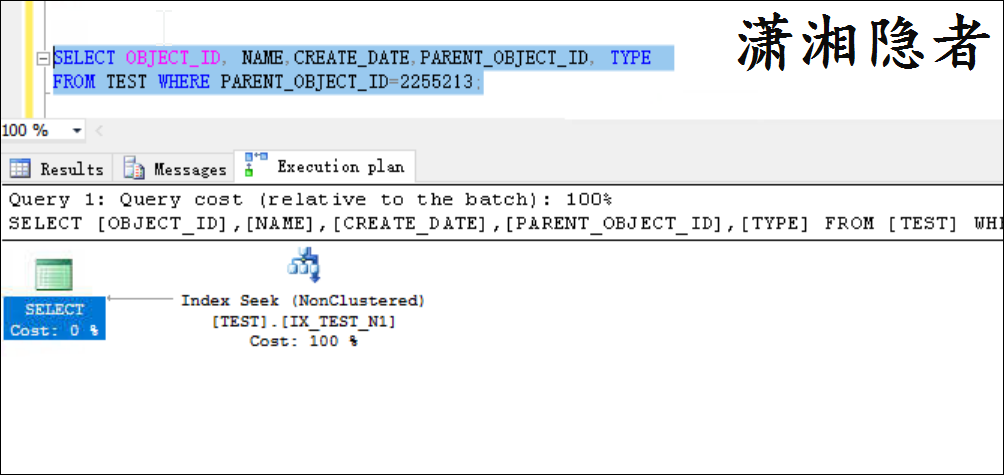
後面才想明白,非聚集索引中的索引行指向數據行的指針稱為行定位器。 行定位器的結構取決於數據頁是存儲在堆中還是聚集表中。 對於堆,行定位器是指向行的指針。 對於聚集表,行定位器是聚集索引鍵。這是不是有點眼熟,類似於MySQL InnoDB的二級索引(Secondary Index)會自動補齊主鍵,將主鍵列追加到二級索引列後面。所以執行計劃就走索引IX_TEST_N1查找就能返回數據了。根本不需要書簽查找(回表查詢)。如果查詢語句多一個欄位或者是SELECT *的話,你就會看到書簽查找了。如下所示
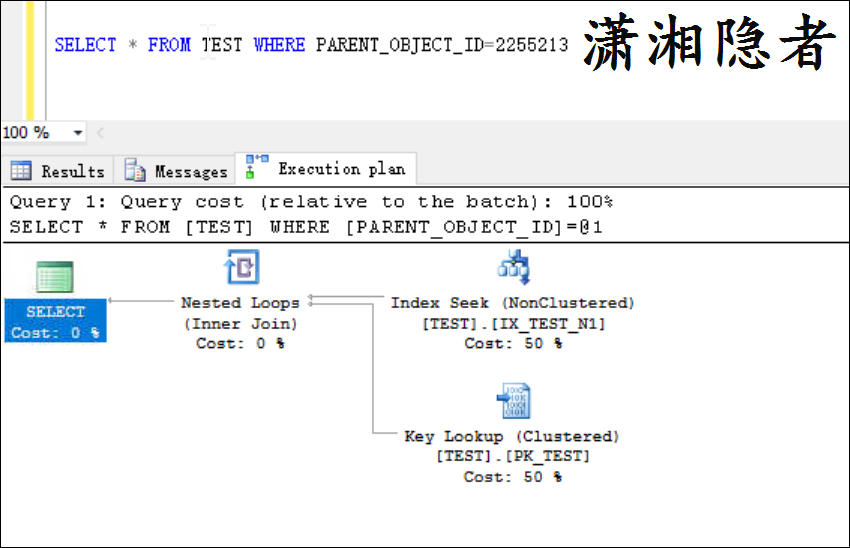
PS:有些技術落下久了,感覺就生疏、荒廢了一樣。真的是業精於勤荒於嬉!
 掃描上面二維碼關註我
如果你真心覺得文章寫得不錯,而且對你有所幫助,那就不妨幫忙“推薦"一下,您的“推薦”和”打賞“將是我最大的寫作動力!
本文版權歸作者所有,歡迎轉載,但未經作者同意必須保留此段聲明,且在文章頁面明顯位置給出原文連接.
掃描上面二維碼關註我
如果你真心覺得文章寫得不錯,而且對你有所幫助,那就不妨幫忙“推薦"一下,您的“推薦”和”打賞“將是我最大的寫作動力!
本文版權歸作者所有,歡迎轉載,但未經作者同意必須保留此段聲明,且在文章頁面明顯位置給出原文連接.

