
1. 本篇文章目標 將下麵的excel中的寄存器表單讀入並構建一個字典 2. openpyxl的各種基本使用方法 2.1 打開工作簿 wb = openpyxl.load_workbook('test_workbook.xlsx') 2.2 獲取工作簿中工作表名字並得到工作表 ws = wb[wb. ...
1. 本篇文章目標
將下麵的excel中的寄存器表單讀入並構建一個字典

2. openpyxl的各種基本使用方法
2.1 打開工作簿
wb = openpyxl.load_workbook('test_workbook.xlsx')
2.2 獲取工作簿中工作表名字並得到工作表
ws = wb[wb.sheetnames[0]]
wb.sheetnames 會返回一個列表,列表中是每個工作表的名稱,數據類型為str。執行上述代碼後ws就是獲取的工作表。
2.3 讀取某個單元格的值
d = ws.cell(row=1, column=1).value
print(d)
使用sheet.cell會返回cell對象,再使用cell.value才能返回單元格的值,執行上述代碼的結果如下:

2.4 按行讀取
按行讀取可以用iter_rows()方法。
for row in ws.iter_rows():
print(row)
執行上述代碼的輸出如下:

由圖可知,該方法應當是一個迭代器,返回的是row是一個tuple,裡邊是各個單元格cell。可以按照如下方法獲取每列的值。
import pprint as pp
excel_list = []
for row in ws.iter_rows():
row = list(row)
for i in range(len(row)):
row[i] = row[i].value
excel_list.append(row)
pp.pprint(excel_list)
這裡用到了一個模塊pprint,用來使列印出的列表、字典等美觀易讀。print結果如下:
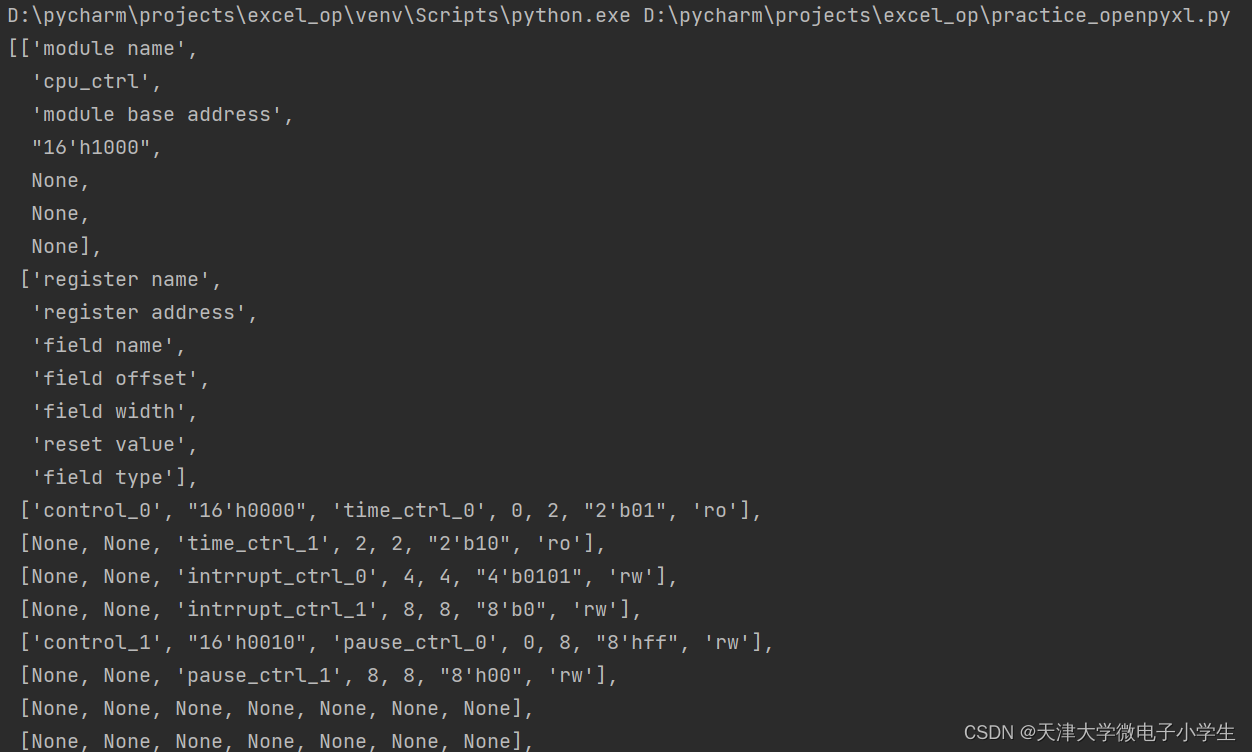
可以看到已經將excel中的內容構建了一個列表,但是下邊一些沒有內容的行也讀了進來,儘管每個單元的值是None,這是因為之前對下邊的行做過編輯,然後又刪掉,導致這些無內容的單元具有單元格格式,openpyxl會將這些單元格也識別進來,所以要想避免這種情況,使用xlrd庫是一種辦法,或者採用下麵的辦法:
excel_list = []
for row in ws.iter_rows():
row = list(row)
if row[3].value != None:
for i in range(len(row)):
row[i] = row[i].value
excel_list.append(row)
pp.pprint(excel_list)
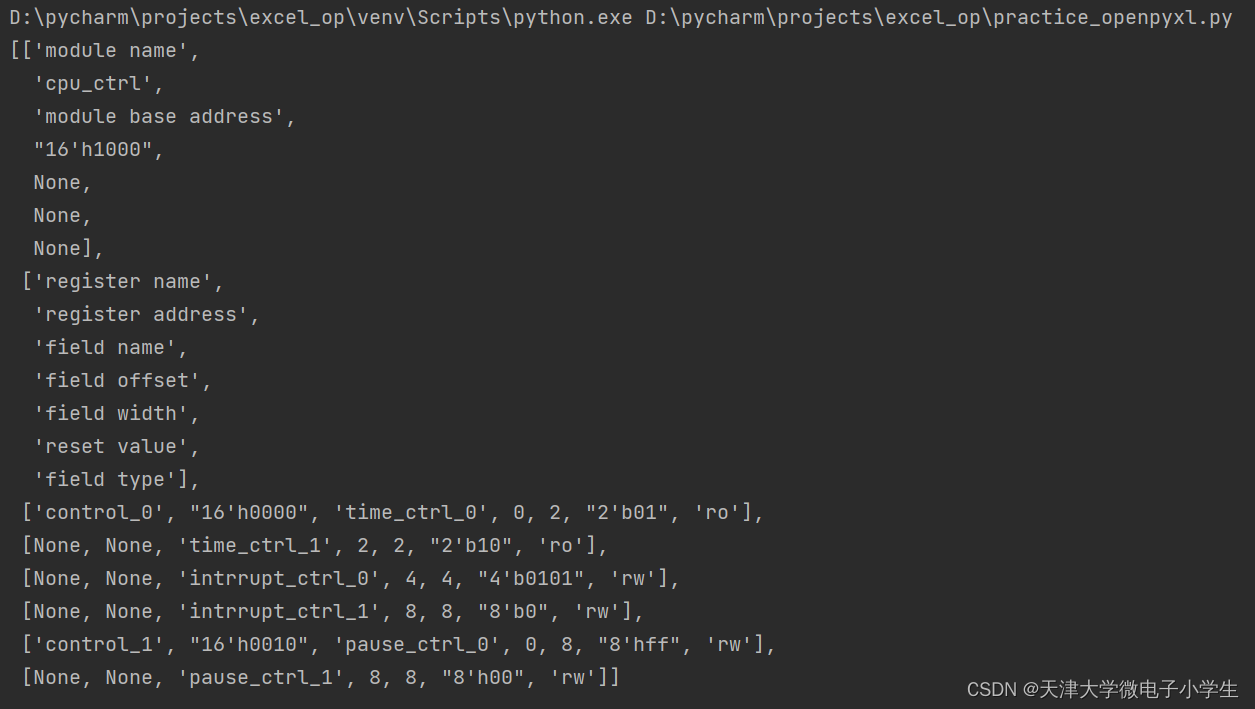
執行結果如下,可以看到全為None的行被過濾掉了。
按列讀取方法類似,使用iter_cols()。
2.5切片讀取
有時候我們並不想讀取表格裡的全部內容,只想讀取一部分,這時候可以用iter_rows()和iter_cols()的切片功能。
excel_list = []
for row in ws.iter_rows(min_row=2, min_col=2, max_row=3, max_col=3):
row = list(row)
if row[1].value != None:
for i in range(len(row)):
row[i] = row[i].value
excel_list.append(row)
pp.pprint(excel_list)
執行結果如下,可以看到只獲取了表格二行二列至三行三列的內容。

2.6 利用表格行列坐標直接獲取單元格、單元格的值、切片
除了上述使用sheet.cell(row, col)來獲取單元格值,以及iter_rows/cols獲取行、列、切片外,還可以直接用excel的行列坐標表示來獲取上述內容。
pp.pprint(ws['B3']) #獲取B3單元格的cell對象
pp.pprint(ws['B3'].value) #獲取B3單元格cell對象的值
pp.pprint(ws['A1':'B2']) # 獲取A1:B2這個切片的cell們
pp.pprint(ws['A:B']) # 獲取A列到B列的所有cell對象
pp.pprint(ws[1:2]) # 獲取行1到行2兩行的所有cell對象
這裡要註意使用這種切片、獲取行列對象值的時候不能直接用.value方法,.value只是單獨cell即一個單元格的cell時才能直接用,所以要想用這種方法獲取切片、行列的值時要配合遍歷、列表等方法構建。
2.7快速獲得工作表的行們和列們
使用sheet.rows 和sheet.cols。
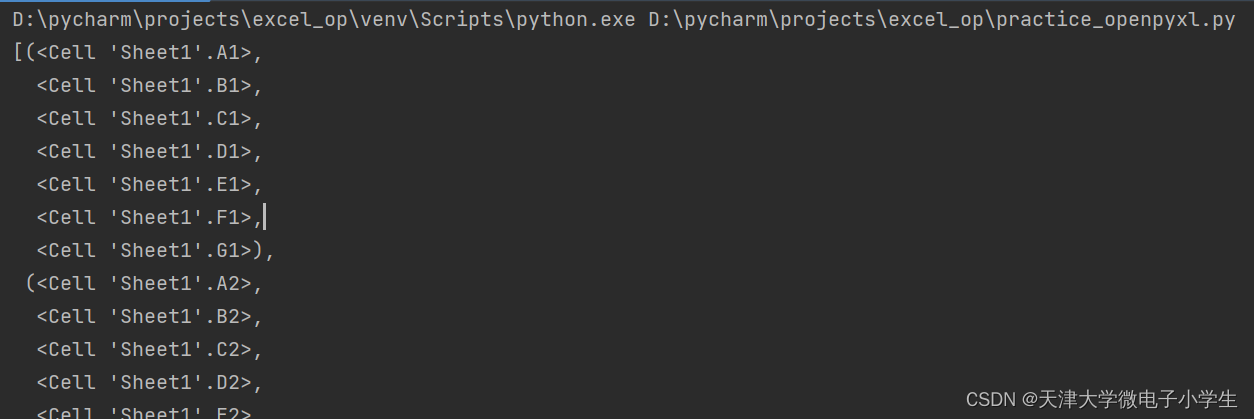
pp.pprint(list(ws.rows))
執行結果如下:
3.構建本任務所需字典
代碼如下:
class ReadRegListExcel:
def __init__(self, this_ws):
self.reg_dic = {}
self.ws = this_ws
def excel_max_rows(self):
max_rows = 0
for row in ws.rows:
if row[3].value != None:
max_rows += 1
return max_rows
def construct_dic(self):
max_rows = self.excel_max_rows()
self.reg_dic['module name'] = self.ws.cell(row=1, column=2).value
self.reg_dic['module base address'] = self.ws.cell(row=1, column=4).value
self.reg_dic['registers'] = []
row = 3
all_rows = list(self.ws.rows)
print(all_rows)
while row <= max_rows:
if all_rows[row-1][0].value != None:
self.reg_dic['registers'].append({})
self.reg_dic['registers'][-1]['register name'] = all_rows[row-1][0].value
self.reg_dic['registers'][-1]['register address'] = all_rows[row-1][1].value
self.reg_dic['registers'][-1]['fields'] = [[value.value for value in all_rows[row-1][2:7]]]
else:
self.reg_dic['registers'][-1]['fields'].append([value.value for value in all_rows[row-1][2:7]])
row += 1
return self.reg_dic
if __name__ == "__main__":
reg_dic_obj = ReadRegListExcel(ws)
reg_dic = reg_dic_obj.construct_dic()
pp.pprint(reg_dic)
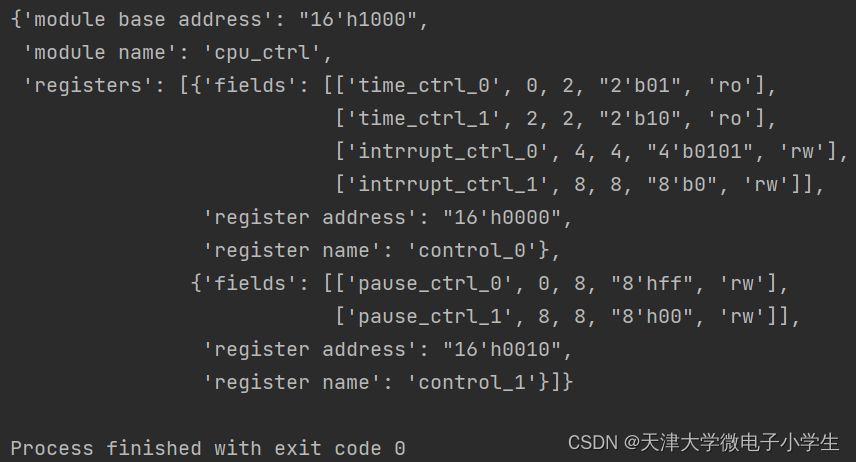
最後得到的寄存器字典如下:
至此讀入寄存器列表文件並構建出結構化的寄存器字典任務完成。

