
pandas中的cut函數可將一維數據按照給定的區間進行分組,併為每個值分配對應的標簽。其主要功能是將連續的數值數據轉化為離散的分組數據,方便進行分析和統計。 1. 數據準備 下麵的示例中使用的數據採集自王者榮耀比賽的統計數據。數據下載地址:https://databook.top/。 導入數據: ...
pandas中的cut函數可將一維數據按照給定的區間進行分組,併為每個值分配對應的標簽。
其主要功能是將連續的數值數據轉化為離散的分組數據,方便進行分析和統計。
1. 數據準備
下麵的示例中使用的數據採集自王者榮耀比賽的統計數據。
數據下載地址:https://databook.top/。
導入數據:
# 2023年世冠比賽選手的數據
fp = r"D:\data\player-2023世冠.csv"
df = pd.read_csv(fp)
# 這裡只保留了下麵示例中需要的列
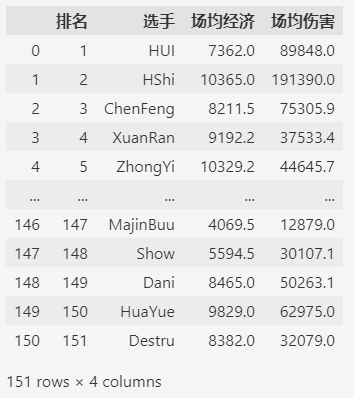
df = df.loc[:, ["排名", "選手", "場均經濟", "場均傷害"]]
df
2. 使用示例
每個選手的“場均經濟”和“場均傷害”是連續分佈的數據,為了整體瞭解所有選手的情況,
可以使用下麵的方法將“場均經濟”和“場均傷害”分類。
2.1. 查看數據分佈
首先,可以使用直方圖的方式看看數據連續分佈的情況:
import matplotlib.pyplot as plt
df.loc[:, ["場均經濟", "場均傷害"]].hist()
plt.show()
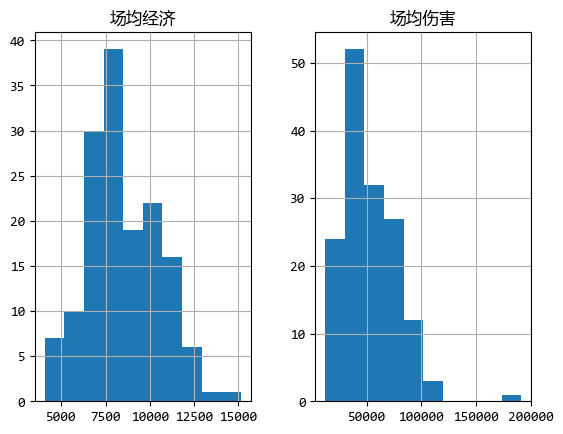
圖中的橫軸是“經濟”和“傷害”的數值,縱軸是選手的數量。
2.2. 定製分佈參數
從預設的直方圖中可以看出大部分選手的“場均經濟”和“場均傷害”大致在什麼範圍,
不過,為了更精細的分析,我們可以進一步定義自己的分類範圍,看看各個分類範圍內的選手數量情況。
比如,我們將“場均經濟”分為3塊,分別為低(0~5000),中(5000~10000),高(10000~20000)。
同樣,對於“場均傷害”,也分為3塊,分別為低(0~50000),中(50000~100000),高(100000~200000)。
bins1 = [0, 5000, 10000, 20000]
bins2 = [0, 50000, 100000, 200000]
labels = ["低", "中", "高"]
s1 = "場均經濟"
s2 = "場均傷害"
df[f"{s1}-分類"] = pd.cut(df[s1], bins=bins1, labels=labels)
df[f"{s2}-分類"] = pd.cut(df[s2], bins=bins2, labels=labels)
df
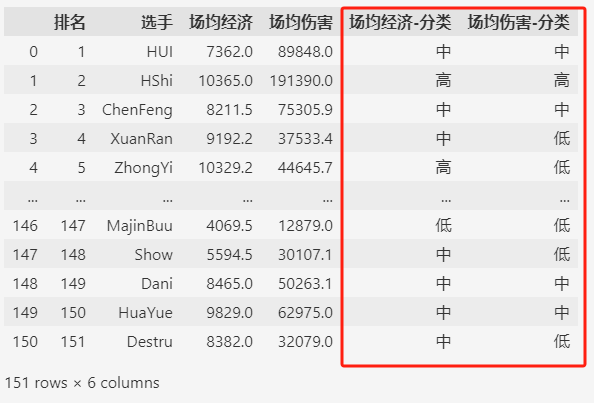
分類之後,選手被分到3個類別之中,然後再繪製直方圖。
df.loc[:, f"{s1}-分類"].hist()
plt.title(f"{s1}-分類")
plt.show()
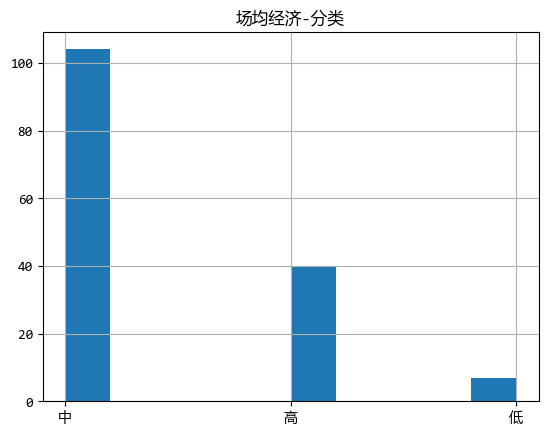
從這個圖看出,大部分選手都是“中”,“高”的經濟,說明職業選手很重視英雄發育。
df.loc[:, f"{s2}-分類"].hist()
plt.title(f"{s2}-分類")
plt.show()
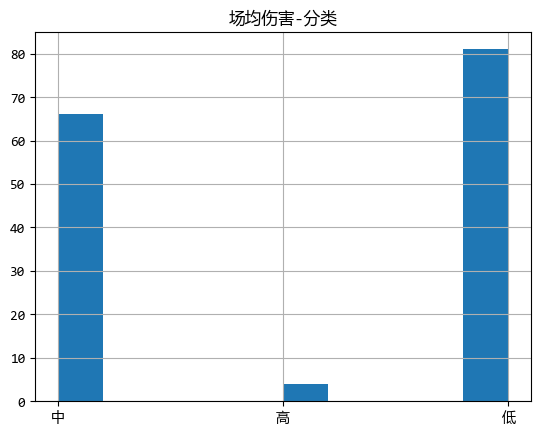
從圖中可以看出,打出高傷害的選手比例並不高,可能職業比賽中,更多的是團隊作戰。
3. 總結
總的來說,cut函數的主要作用是將輸入的數值數據(可以是一維數組、Series或DataFrame的列)按照指定的間隔或自定義的區間邊界進行劃分,併為每個劃分後的區間分配一個標簽。
這樣,原始的連續數據就被轉化為了離散的分組數據,每個數據點都被分配到了一個特定的組中,從而方便後續進行分析和統計。

