
- 什麼是狀態?狀態有什麼作用? - 如果你來設計,對於一個流式服務,如何根據不斷輸入的數據計算呢? - 又如何做故障恢復呢? ...
- 什麼是狀態?狀態有什麼作用?
- 如果你來設計,對於一個流式服務,如何根據不斷輸入的數據計算呢?
- 又如何做故障恢復呢?
一、為什麼要管理狀態
流計算不像批計算,數據是持續流入的,而不是一個確定的數據集。在進行計算的時候,不可能把之前已經輸入的數據全都保存下來,然後再和新數據合併計算。效率低下不說,記憶體也扛不住。
另外,如果程式出現故障重啟,沒有之前計算過的狀態保存,那麼也就無法再繼續計算了。
因此,就需要一個東西來記錄各個運算元之前已經計算過值的結果,當有新數據來的時候,直接在這個結果上計算更新。這個就是狀態。
常見的流處理狀態功能如下:
- 數據流中的數據有重覆,我們想對重覆數據去重,需要記錄哪些數據已經流入過應用,當新數據流入時,根據已流入過的數據來判斷去重。
- 檢查輸入流是否符合某個特定的模式,需要將之前流入的元素以狀態的形式緩存下來。比如,判斷一個溫度感測器數據流中的溫度是否在持續上升。
- 對一個時間視窗內的數據進行聚合分析,分析一個小時內某項指標的75分位或99分位的數值。
- 線上機器學習場景下,需要根據新流入數據不斷更新機器學習的模型參數。
二、state 簡介
Flink的狀態是由運算元的子任務來創建和管理的。一個狀態更新和獲取的流程如下圖所示,一個運算元子任務接收輸入流,獲取對應的狀態,根據新的計算結果更新狀態。
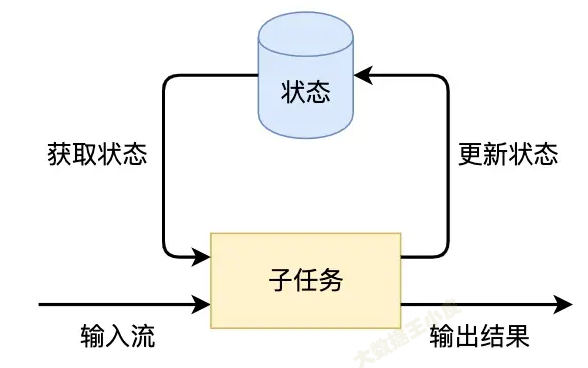
狀態的保存:
需要考慮的問題:
- container 異常後,狀態不丟
- 狀態可能越來越大
因此,狀態不能直接放在記憶體中,以上兩點問題都無法保證。
需要有一個外部持久化存儲方式,常見的如放到 HDFS 中。(此部分讀者感興趣可自行搜索資料探索)
三、Flink 狀態類型
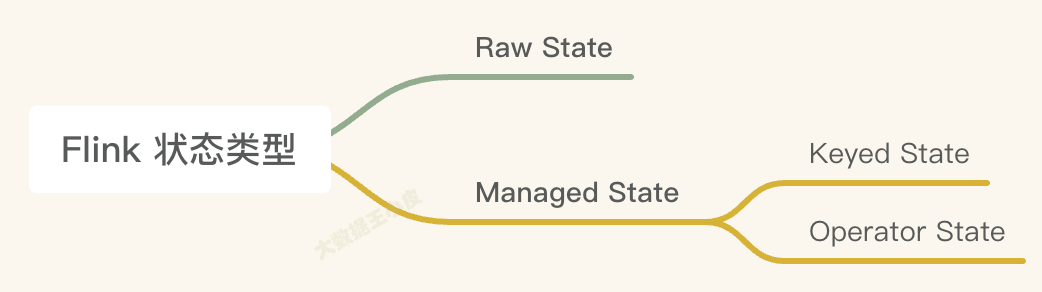
一)Managed State 和 Raw State
- Managed State 是由 Flink 管理的。Flink幫忙存儲、恢復和優化。
- Raw State 是開發者自己管理的,需要自己序列化(較少用到)。
在 Flink 中推薦用戶使用Managed State管理狀態數據 ,主要原因是 Managed State 能夠更好地支持狀態數據的重平衡以及更加完善的記憶體管理。
| Managed State | Raw State | |
|---|---|---|
| 狀態管理方式 | Flink Runtime 管理,自動存儲,自動恢復,記憶體管理方式上優化明顯 | 用戶自己管理,需要用戶自己序列化 |
| 狀態數據結構 | 已知的數據結構 value , list ,map | flink不知道你存的是什麼結構,都轉換為二進位位元組數據 |
| 使用場景 | 大多數場景適用 | 需要滿足特殊業務,自定義operator時使用,flink滿足不了你的需求時候,使用複雜 |
下文將重點介紹Managed State。
二)Keyed State 和 Operator State
Managed State 又有兩種類型:Keyed State 和 Operator State。
| keyed state | operator state | |
|---|---|---|
| 適用場景 | 只能應用在 KeyedSteam 上 | 可以用於所有的運算元 |
| State 處理方式 | 每個 key 對應一個 state,一個 operator 處理多個 key ,會訪問相應的多個 state | 一個 operator 對應一個 state |
| 併發改變 | 併發改變時,state隨著key在實例間遷移 | 併發改變時需要你選擇分配方式,內置:1.均勻分配 2.所有state合併後再分發給每個實例 |
| 訪問方式 | 通過RuntimeContext訪問,需要operator是一個richFunction | 需要你實現CheckPointedFunction或ListCheckPointed介面 |
| 支持數據結構 | ValuedState, ListState, Reducing State, Aggregating State, MapState, FoldingState(1.4棄用) |
只支持 listState |
Keyed State
簡單來說,通過 keyBy 分組的就會用到 Keyed State。就是按照分組來的狀態。(Keyed State 是Operator State的特例,區別在於 Keyed State 事先按照 key 對數據集進行了分區,每個 Key State 僅對應ー個Operator和 Key 的組合。)
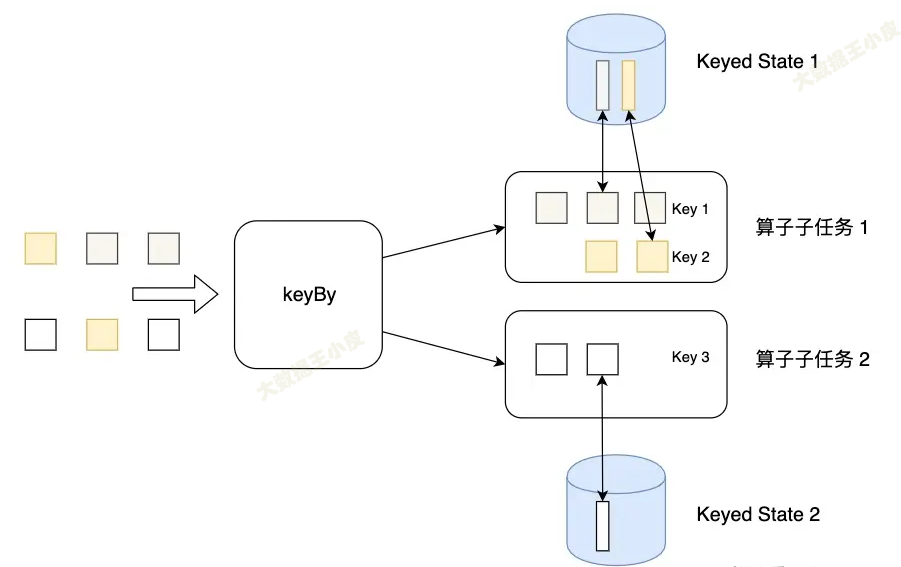
Keyed State可以通過 Key Groups 進行管理,主要用於當運算元並行度發生變化時,自動重新分佈Keyed State數據 。分配代碼如下:
// KeyGroupRangeAssignment.java
public static int computeKeyGroupForKeyHash(int keyHash, int maxParallelism) {
return MathUtils.murmurHash(keyHash) % maxParallelism;
}
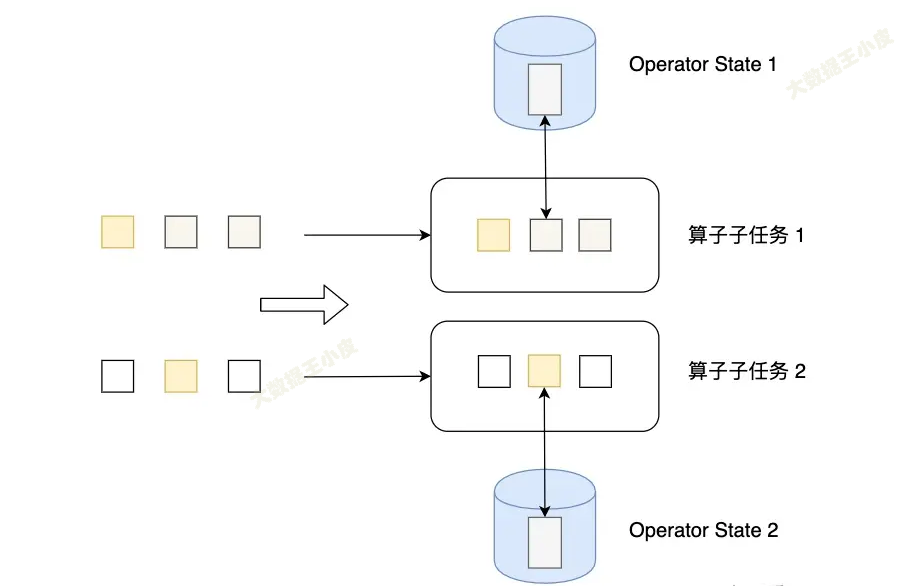
Operator State
Operator State 可以用在所有運算元上,每個運算元子任務或者說每個運算元實例共用一個狀態,流入這個運算元子任務的數據可以訪問和更新這個狀態。
例如 Kafka Connector 中,每一個並行的 Kafka Consumer 都在 Operator State 中維護當前 Consumer 訂閱的 partiton 和 offset。
三)Flink 實現類
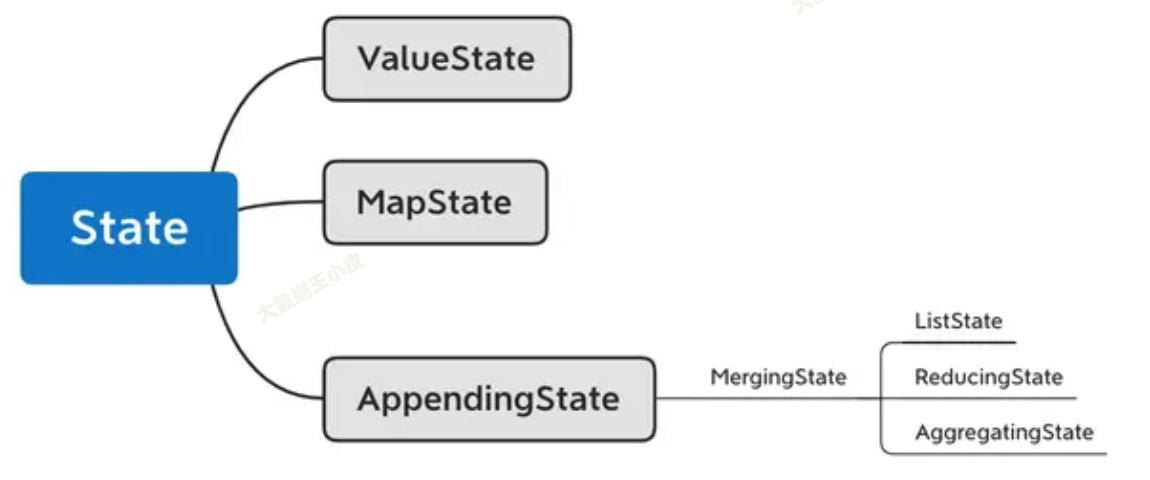
在開發中,需要保存的狀態也有不同的數據結構,那麼 Flink 也提供了相應的類。
如上圖所示:
ValueState[T]保存單一變數狀態MapState[K, V]同 java map,保存 kv 型狀態ListState[T]數組類型狀態ReducingState[T]單一狀態,將原狀態和新狀態合併後再更新AggregatingState[IN, OUT]同樣是合併更新,只不過前後數據類型可以不一樣
四、實踐
實現一個簡單的計數視窗。
輸入數據是一個元組 Tuple2.of(1L, 3L),把元組的第一個元素當作 key(在示例中都 key 都是 “1”),第二個元素當 value。
該函數將出現的次數以及總和存儲在 ValueState 中。 一旦出現次數達到 2,則將平均值發送到下游,並清除狀態重新開始。 請註意,我們會為每個不同的 key(元組中第一個元素)保存一個單獨的值。
public class CountWindowAverage extends RichFlatMapFunction<Tuple2<Long, Long>, Tuple2<Long, Long>> {
/**
* The ValueState handle. The first field is the count, the second field a running sum.
*/
private transient ValueState<Tuple2<Long, Long>> sum;
@Override
public void flatMap(Tuple2<Long, Long> input, Collector<Tuple2<Long, Long>> out) throws Exception {
// access the state value
Tuple2<Long, Long> currentSum = sum.value();
// update the count
currentSum.f0 += 1;
// add the second field of the input value
currentSum.f1 += input.f1;
// update the state
sum.update(currentSum);
// if the count reaches 2, emit the average and clear the state
if (currentSum.f0 >= 2) {
out.collect(new Tuple2<>(input.f0, currentSum.f1 / currentSum.f0));
sum.clear();
}
}
@Override
public void open(Configuration config) {
ValueStateDescriptor<Tuple2<Long, Long>> descriptor =
new ValueStateDescriptor<>(
"average", // the state name
TypeInformation.of(new TypeHint<Tuple2<Long, Long>>() {}), // type information
Tuple2.of(0L, 0L)); // default value of the state, if nothing was set
sum = getRuntimeContext().getState(descriptor);
}
}
// this can be used in a streaming program like this (assuming we have a StreamExecutionEnvironment env)
env.fromElements(Tuple2.of(1L, 3L), Tuple2.of(1L, 5L), Tuple2.of(1L, 7L), Tuple2.of(1L, 4L), Tuple2.of(1L, 2L))
.keyBy(value -> value.f0)
.flatMap(new CountWindowAverage())
.print();
// the printed output will be (1,4) and (1,5)
四、小結
本節我們介紹了 Flink 狀態,是用於流式計算中中間數據存儲和故障恢復的。
Flink 狀態分為 Raw State 和 Manage State,其中 Manage State 中又包含 Keyed State 和 Operator State。最重要的是 Keyed State 要重點理解和掌握。
在編程開發過程中,針對不同的數據結構,Flink 提供了對應的 State 類。並提供了一個 state demo 代碼供學習。
參考文章:
七、Flink入門--狀態管理_flink流式任務如何保證7*24小時運行-CSDN博客
Flink狀態管理詳解:Keyed State和Operator List State深度解析
爆肝 3 月,3w 字、15 章節詳解 Flink 狀態管理!(建議收藏)-騰訊雲開發者社區-騰訊雲(較詳細)
Flink 筆記二 Flink的State--狀態原理及原理剖析_flink key state是每個key對應一個state還是每個分區對應一個state-CSDN博客(源碼剖析)
Flink 狀態管理詳解(State TTL、Operator state、Keyed state)-騰訊雲開發者社區-騰訊雲
Flink 源碼閱讀筆記(10)- State 管理


