
本章將和大家分享 Elasticsearch 的一些基本操作。話不多說,下麵我們直接進入主題。 一、索引庫操作 1、settings屬性 settings屬性可以設置索引庫的一些配置信息,例如:配置分片數和副本數、配置自定義分詞器等。 其中分片數量只能在一開始創建索引庫的時候指定,後期不能修改。副本 ...
本章將和大家分享 Elasticsearch 的一些基本操作。話不多說,下麵我們直接進入主題。
一、索引庫操作
1、settings屬性
settings屬性可以設置索引庫的一些配置信息,例如:配置分片數和副本數、配置自定義分詞器等。
其中分片數量只能在一開始創建索引庫的時候指定,後期不能修改。副本數量可以隨時修改。
2、mapping屬性
mapping屬性是對索引庫中文檔的約束,常見的mapping屬性包括:
1)type:欄位數據類型,常見的數據類型在上一章已經介紹過了,此處就不再做過多的描述了。
2)index:是否需要創建倒排索引,預設值為true,如果設置為false那麼表明該欄位不能被檢索,不構建倒排索引。因此,需要根據具體的業務判斷該欄位將來是否需要參與檢索,如果需要的話就設置為true,否則就設置為false。
3)analyzer:使用哪種分詞器,一般結合text(可分詞的文本)數據類型一起使用。
4)properties:該欄位的子欄位。
3、創建索引庫
ES中通過Restful請求操作索引庫、文檔。請求內容用DSL語句來表示。創建索引庫和mapping的DSL語法如下:
PUT /索引庫名稱 { "mappings": { "properties": { "欄位名":{ "type": "text", //分詞 "analyzer": "ik_smart" //指定分詞器 }, "欄位名2":{ "type": "keyword", //不分詞 "index": "false" //不創建倒排索引,不參與搜索 }, "欄位名3":{ "type": "object", //對象類型 "properties": { "子欄位": { "type": "keyword" } } }, // ...略 } } }
示例:
# 創建索引庫 PUT /my_index { "mappings": { "properties": { "info":{ "type": "text", "analyzer": "ik_smart" }, "email":{ "type": "keyword", "index": false }, "name":{ "type": "object", "properties": { "firstName":{ "type":"keyword" }, "lastName":{ "type":"keyword" } } } } } }
運行結果如下所示:
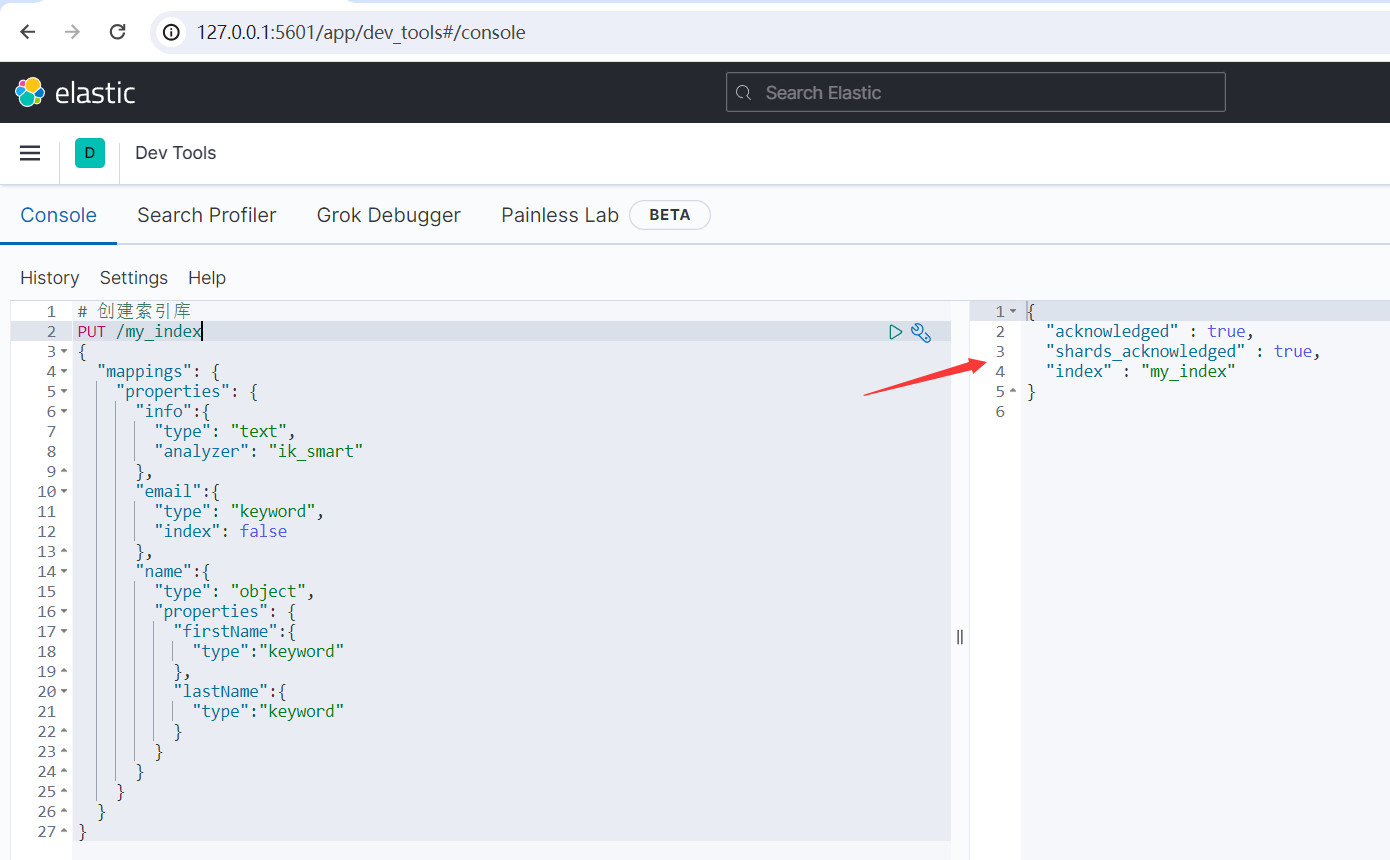
{ "acknowledged" : true, "shards_acknowledged" : true, "index" : "my_index" }
4、查看索引庫
查看索引庫語法:
GET /索引庫名
示例:
# 查看索引庫
GET /my_index
運行結果如下所示:
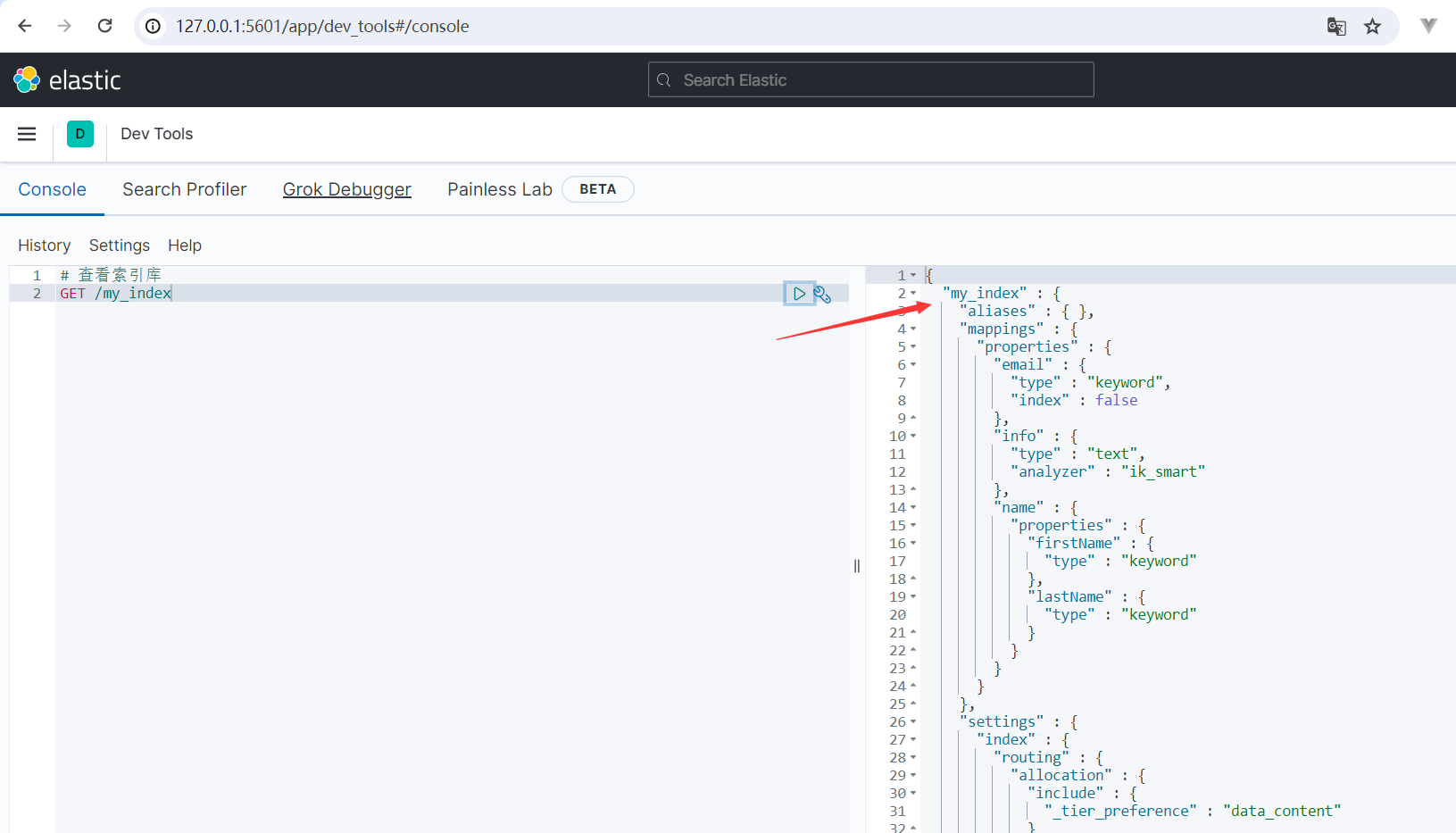
{ "my_index" : { "aliases" : { }, "mappings" : { "properties" : { "email" : { "type" : "keyword", "index" : false }, "info" : { "type" : "text", "analyzer" : "ik_smart" }, "name" : { "properties" : { "firstName" : { "type" : "keyword" }, "lastName" : { "type" : "keyword" } } } } }, "settings" : { "index" : { "routing" : { "allocation" : { "include" : { "_tier_preference" : "data_content" } } }, "number_of_shards" : "1", "provided_name" : "my_index", "creation_date" : "1701011238882", "number_of_replicas" : "1", "uuid" : "qb-XkR5xQ2y7WvohoWVw_Q", "version" : { "created" : "7120199" } } } } }
5、修改索引庫
索引庫和mapping一旦創建無法修改,但是可以添加新的欄位,語法如下:
PUT /索引庫名/_mapping { "properties": { "新欄位名":{ "type": "integer" } } }
示例:
# 修改索引庫,添加新的欄位 PUT /my_index/_mapping { "properties": { "age": { "type": "integer" } } }
運行結果如下所示:
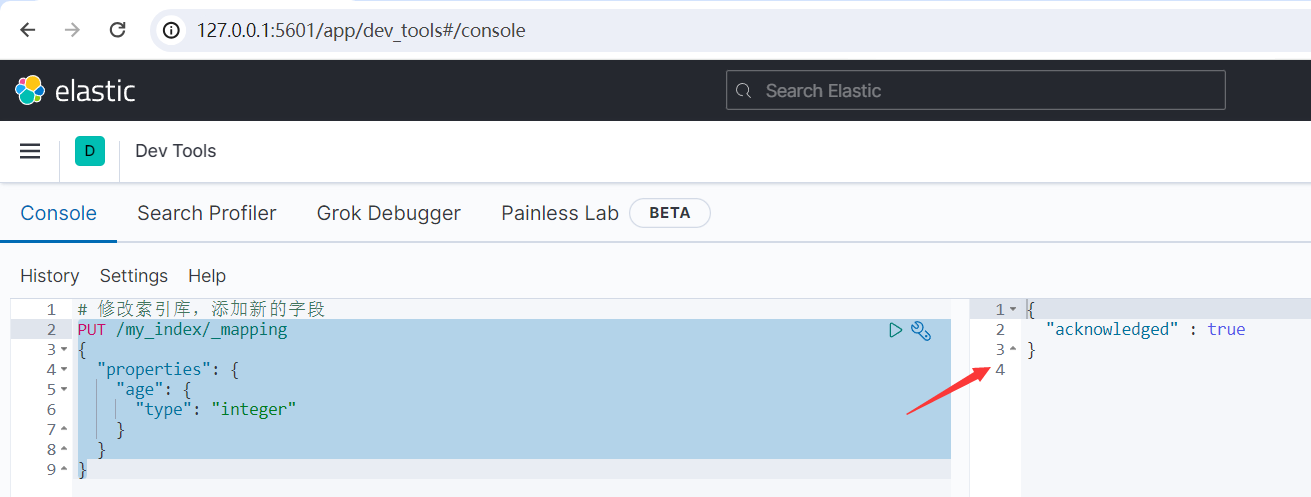
6、刪除索引庫
刪除索引庫的語法:
DELETE /索引庫名
示例:
# 刪除索引庫
DELETE /my_index
運行結果如下所示:
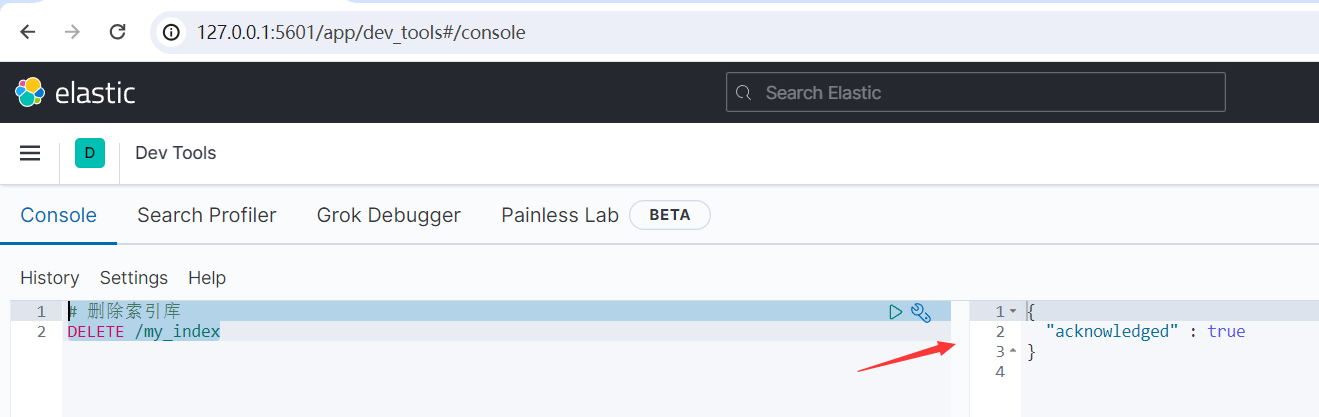
二、文檔操作
1、新增文檔
新增文檔的DSL語法如下:
POST /索引庫名/_doc/文檔id { "欄位1": "值1", "欄位2": "值2", "欄位3": { "子屬性1": "值3", "子屬性2": "值4" }, // ... }
示例:
# 新增文檔 POST /my_index/_doc/1 { "info": "黑馬程式員菜鳥學員", "email": "[email protected]", "name": { "firstName": "武", "lastName": "王" } }
運行結果如下所示:
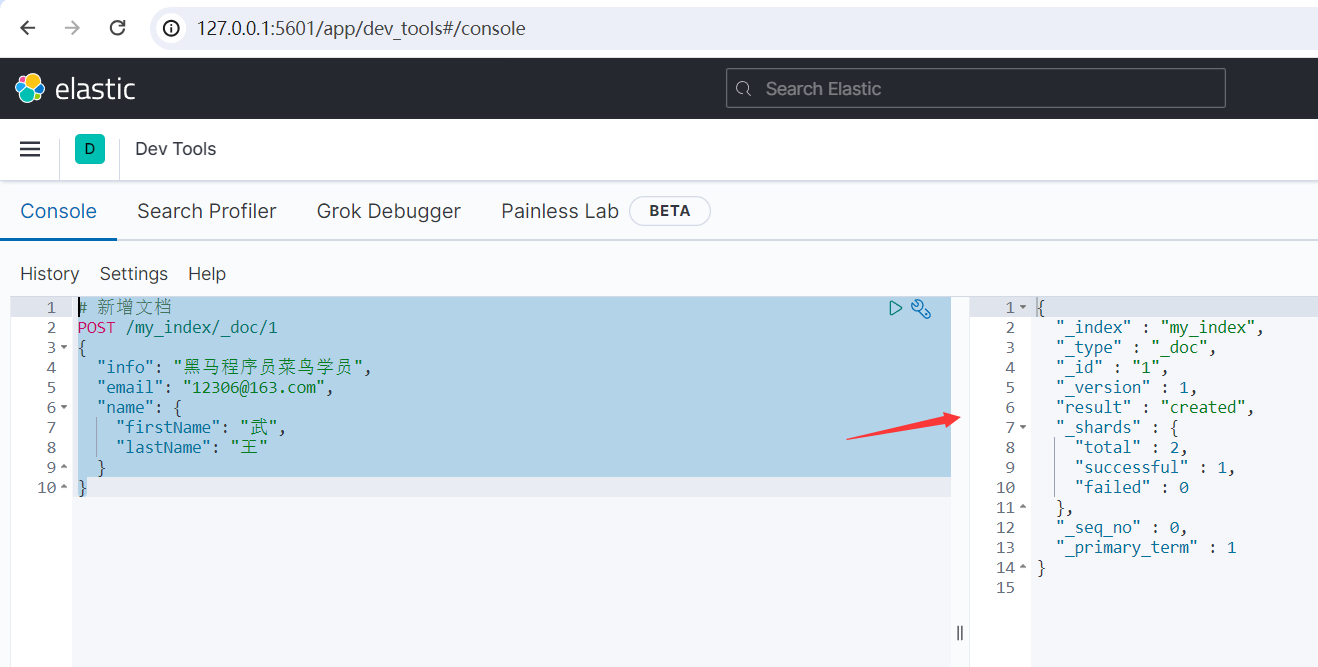
{ "_index" : "my_index", "_type" : "_doc", "_id" : "1", "_version" : 1, "result" : "created", "_shards" : { "total" : 2, "successful" : 1, "failed" : 0 }, "_seq_no" : 0, "_primary_term" : 1 }
2、查詢文檔
查詢文檔的DSL語法如下:
GET /索引庫名/_doc/文檔id
示例:
# 查詢文檔 GET /my_index/_doc/1
運行結果如下所示:
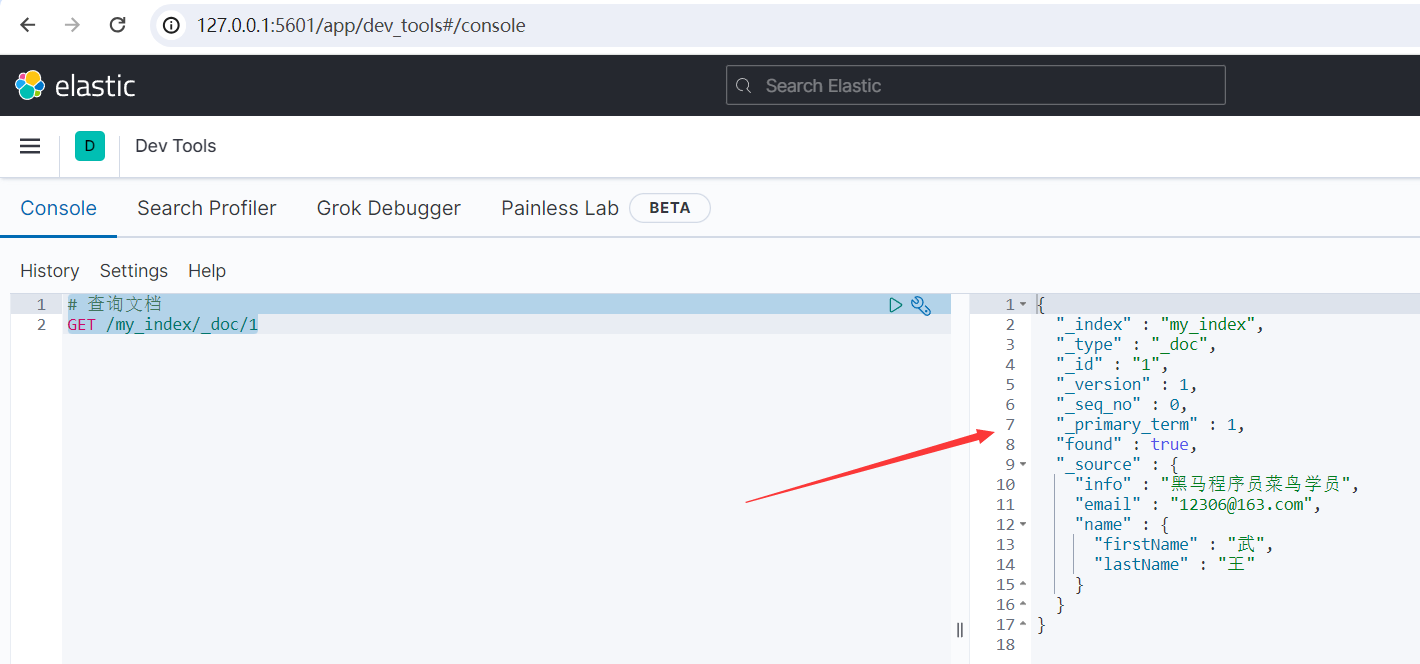
{ "_index" : "my_index", "_type" : "_doc", "_id" : "1", "_version" : 1, "_seq_no" : 0, "_primary_term" : 1, "found" : true, "_source" : { "info" : "黑馬程式員菜鳥學員", "email" : "[email protected]", "name" : { "firstName" : "武", "lastName" : "王" } } }
3、修改文檔
方式一:全量修改文檔,會刪除舊文檔,添加新文檔。該方式既可以修改文檔,也可以新增文檔。對應的DSL語法如下:
PUT /索引庫名/_doc/文檔id { "欄位1": "值1", "欄位2": "值2", // ... 略 }
示例:
# 全量修改文檔 PUT /my_index/_doc/1 { "info": "黑馬程式員菜鳥學員,奧利給", "email": "[email protected]", "name": { "firstName": "武", "lastName": "王" } }
運行結果如下所示:
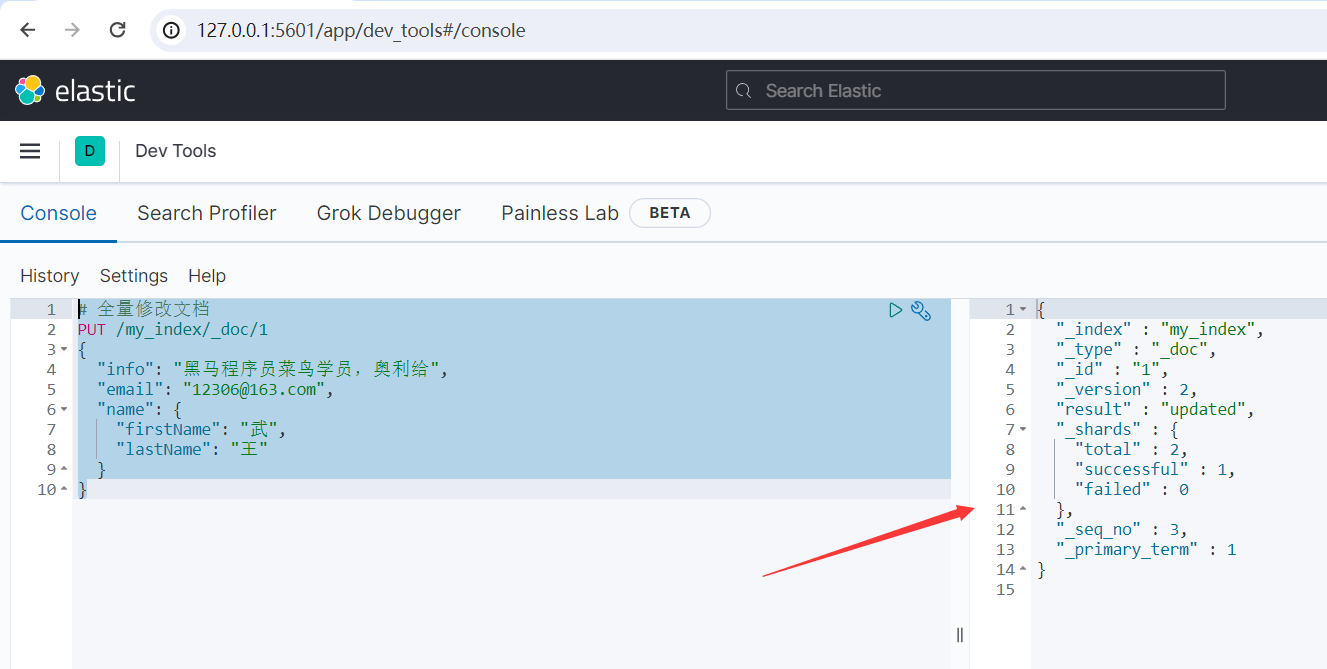
方式二:局部修改(增量修改)文檔欄位,修改指定欄位值。對應的DSL語法如下:
POST /索引庫名/_update/文檔id { "doc": { "欄位名": "新的值", } }
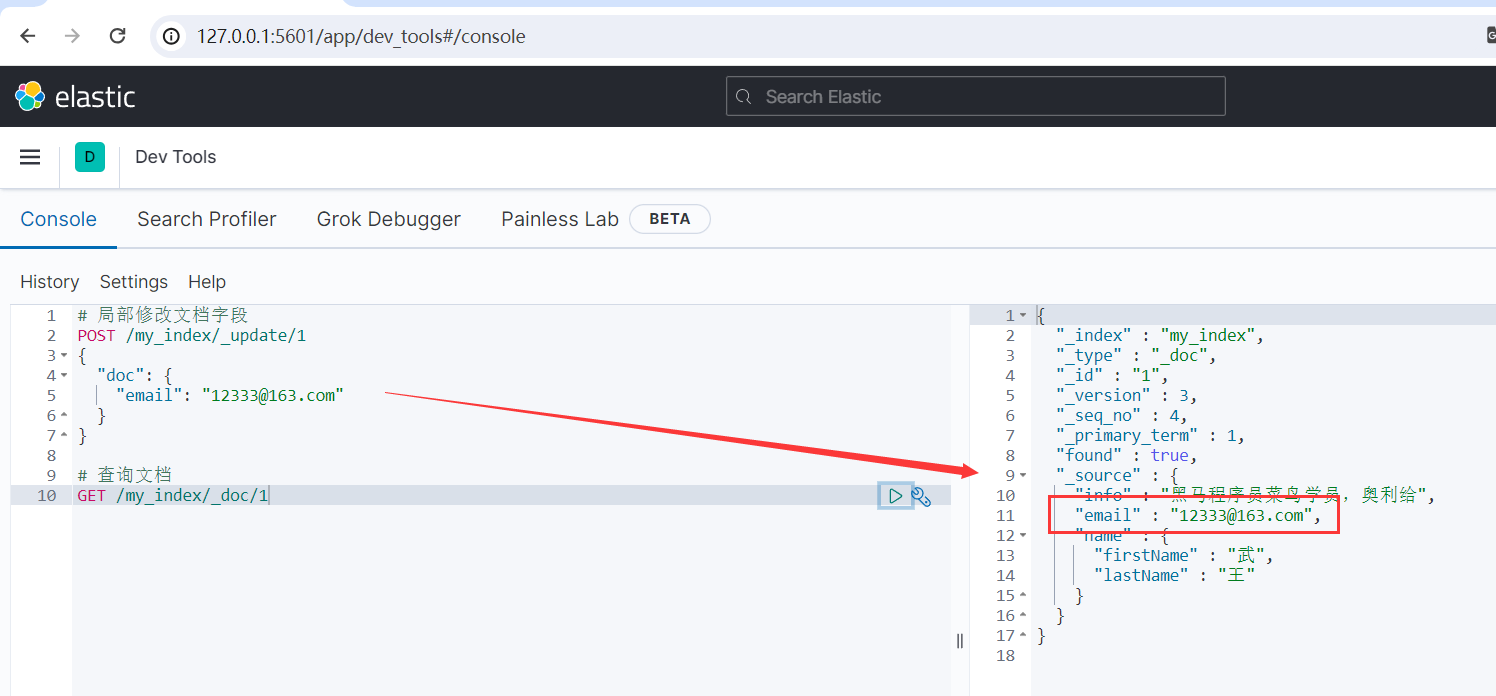
示例:
# 局部修改文檔欄位 POST /my_index/_update/1 { "doc": { "email": "[email protected]" } }
運行結果如下所示:
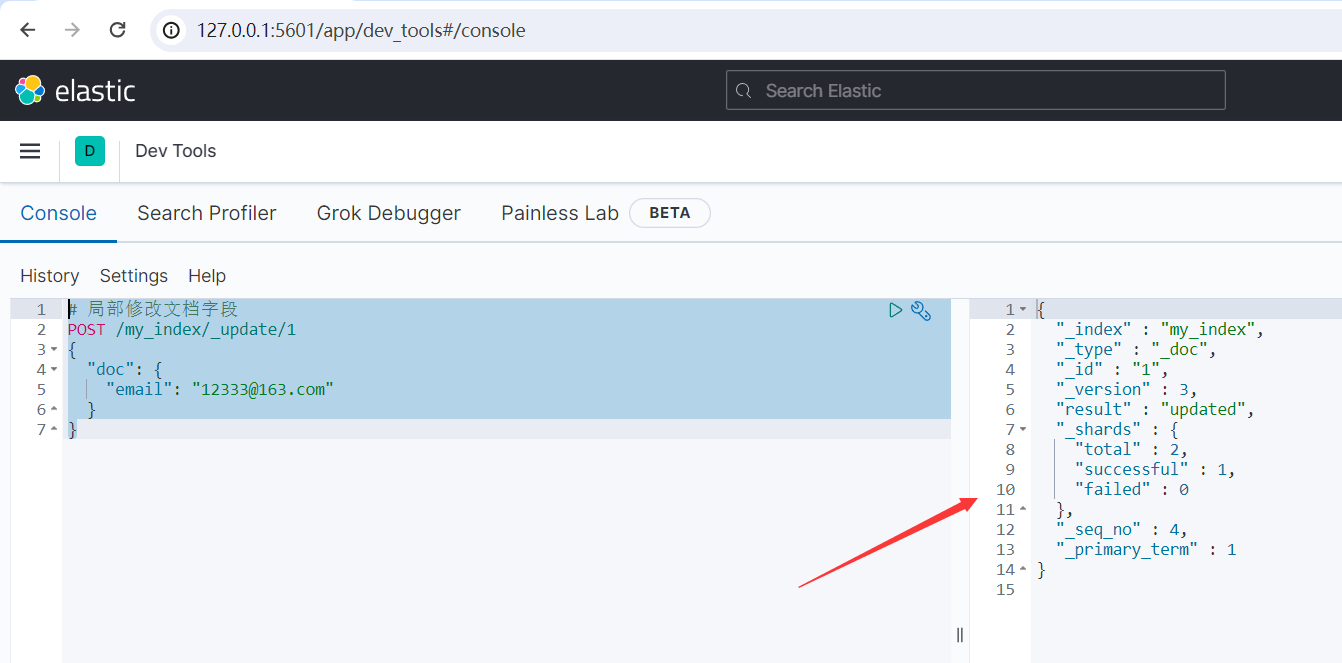
4、刪除文檔
刪除文檔的DSL語法如下:
DELETE /索引庫名/_doc/文檔id
示例:
# 刪除文檔 DELETE /my_index/_doc/1
運行結果如下所示:
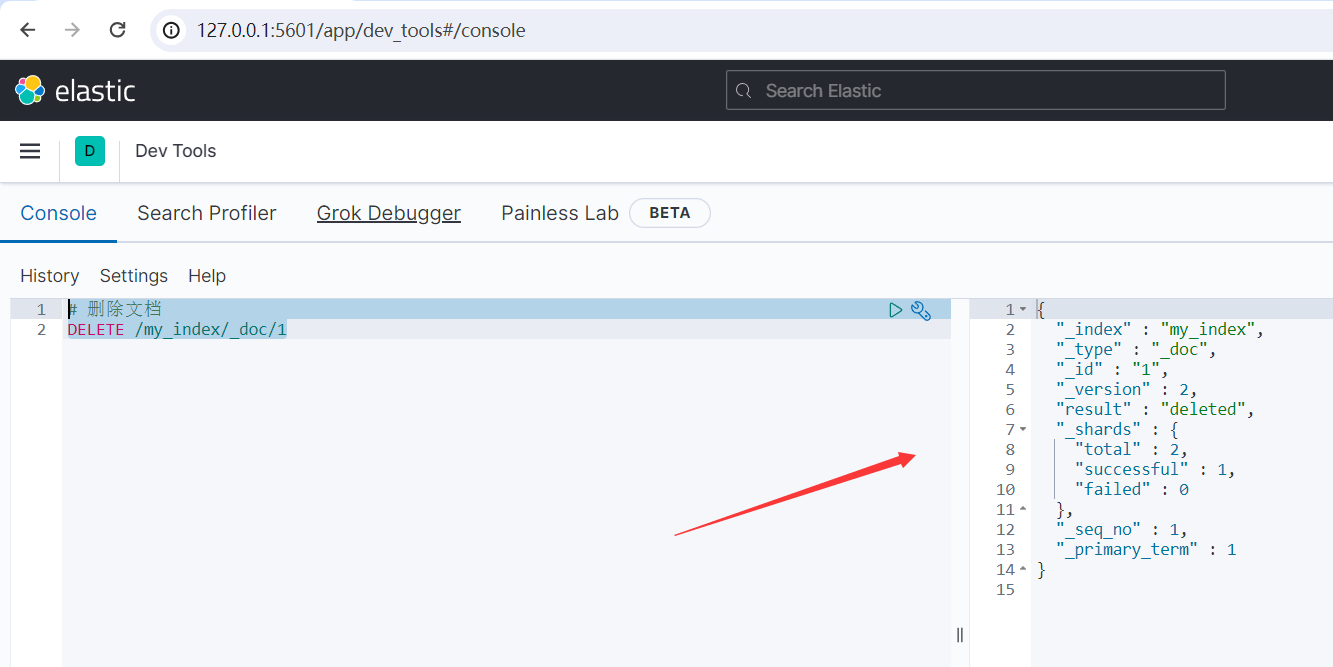
{ "_index" : "my_index", "_type" : "_doc", "_id" : "1", "_version" : 2, "result" : "deleted", "_shards" : { "total" : 2, "successful" : 1, "failed" : 0 }, "_seq_no" : 1, "_primary_term" : 1 }
三、Query DSL 查詢語法
1、數據準備
案例:根據提供的酒店數據創建索引庫,索引庫名稱為hotel,mapping屬性根據資料庫表結構來定義。
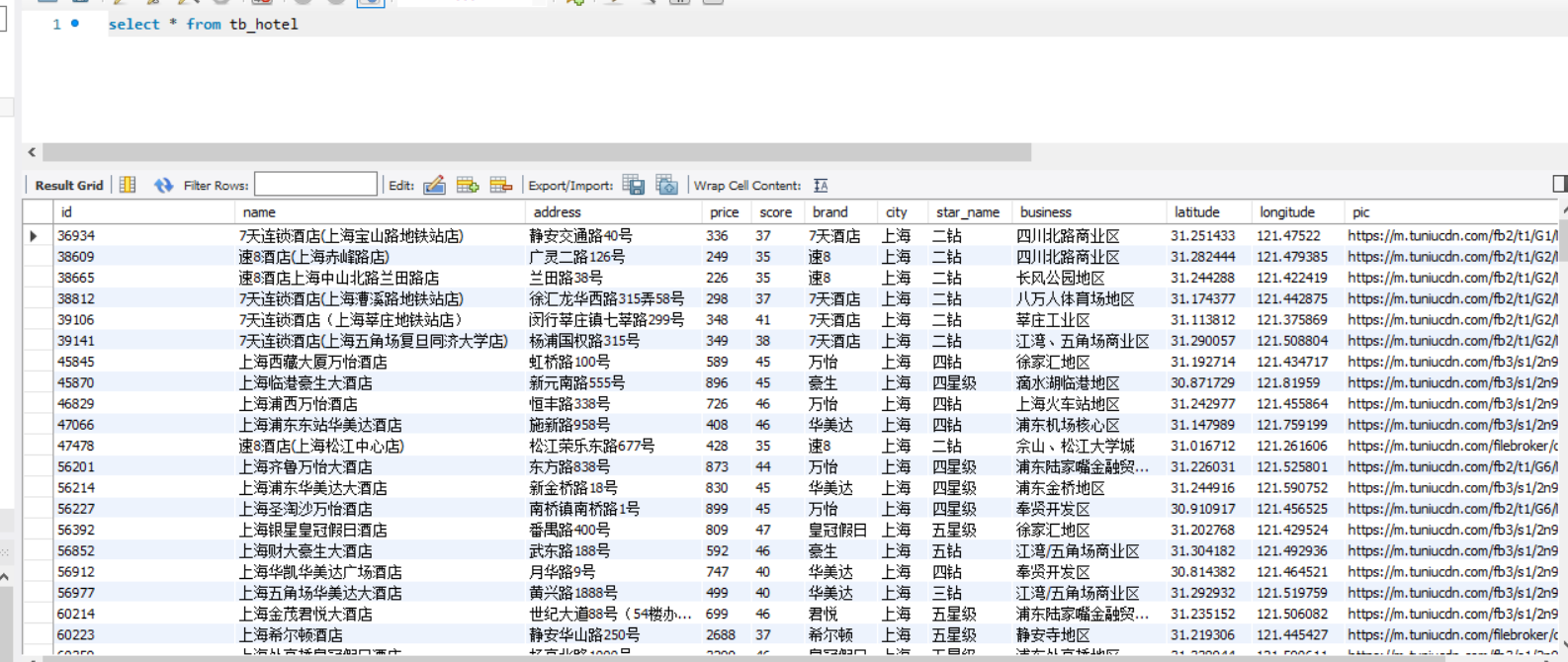
其中 MySQL 資料庫中 tb_hotel 酒店表的表結構如下所示:
CREATE TABLE `tb_hotel` ( `id` bigint(20) NOT NULL COMMENT '酒店id', `name` varchar(255) NOT NULL COMMENT '酒店名稱;例:7天酒店', `address` varchar(255) NOT NULL COMMENT '酒店地址;例:航頭路', `price` int(10) NOT NULL COMMENT '酒店價格;例:329', `score` int(2) NOT NULL COMMENT '酒店評分;例:45,就是4.5分', `brand` varchar(32) NOT NULL COMMENT '酒店品牌;例:如家', `city` varchar(32) NOT NULL COMMENT '所在城市;例:上海', `star_name` varchar(16) DEFAULT NULL COMMENT '酒店星級,從低到高分別是:1星到5星,1鑽到5鑽', `business` varchar(255) DEFAULT NULL COMMENT '商圈;例:虹橋', `latitude` varchar(32) NOT NULL COMMENT '緯度;例:31.2497', `longitude` varchar(32) NOT NULL COMMENT '經度;例:120.3925', `pic` varchar(255) DEFAULT NULL COMMENT '酒店圖片;例:/img/1.jpg', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
首先分析其數據結構,在創建相應索引庫做 mapping 映射時要考慮的問題,如下:
1)欄位名、數據類型、是否參與搜索、是否分詞、如果分詞,分詞器是什麼?
2)ES中支持兩種地理坐標數據類型,具體要使用哪一種?
- geo_point:由緯度(latitude)和經度(longitude)確定的一個點。例如:"32.8752345, 120.2981576"
- geo_shape:有多個geo_point組成的複雜幾何圖形。例如一條直線,"LINESTRING (-77.03653 38.897676, -77.009051 38.889939)"
很明顯我們的酒店在地球上就是一個小點,因此要使用 geo_point 類型。
3)欄位拷貝,可以使用 copy_to 屬性將當前欄位拷貝到指定欄位。
示例:
"all": { "type": "text", "analyzer": "ik_max_word" }, "brand": { "type": "keyword", "copy_to": "all" }
分析完成後,接著我們就可以去創建相應的索引庫了,如下所示:
# 創建酒店數據索引庫 PUT /hotel { "settings": { "analysis": { "analyzer": { "text_anlyzer": { "tokenizer": "ik_max_word", "filter": "py" }, "completion_analyzer": { "tokenizer": "keyword", "filter": "py" } }, "filter": { "py": { "type": "pinyin", "keep_full_pinyin": false, "keep_joined_full_pinyin": true, "keep_original": true, "limit_first_letter_length": 16, "remove_duplicated_term": true, "none_chinese_pinyin_tokenize": false } } } }, "mappings": { "properties": { "id": { "type": "keyword" }, "name": { "type": "text", "analyzer": "text_anlyzer", "search_analyzer": "ik_smart", "copy_to": "all" }, "address": { "type": "keyword", "index": false }, "price": { "type": "integer" }, "score": { "type": "integer" }, "brand": { "type": "keyword", "copy_to": "all" }, "city": { "type": "keyword" }, "starName": { "type": "keyword" }, "business": { "type": "keyword", "copy_to": "all" },

