
廢話不多說,龍年騰雲特效送給大家 預覽 線上預覽 龍年騰雲 源碼 龍是使用的 svg,你也可以替換成其他樣式的龍,而雲是圖片轉化成的 base64 編碼,所以整個文件就是一個 html。 <!DOCTYPE html> <html lang="en"> <head> <meta charset="U ...
XPath 通常用來進行網站、XML (APP )和數據挖掘,通過元素和屬性的方式來獲取指定的節點,然後抓取需要的信息。
學習 XPath 語法之前,首先瞭解一下一些概念。
概念介紹
節點之間的關係
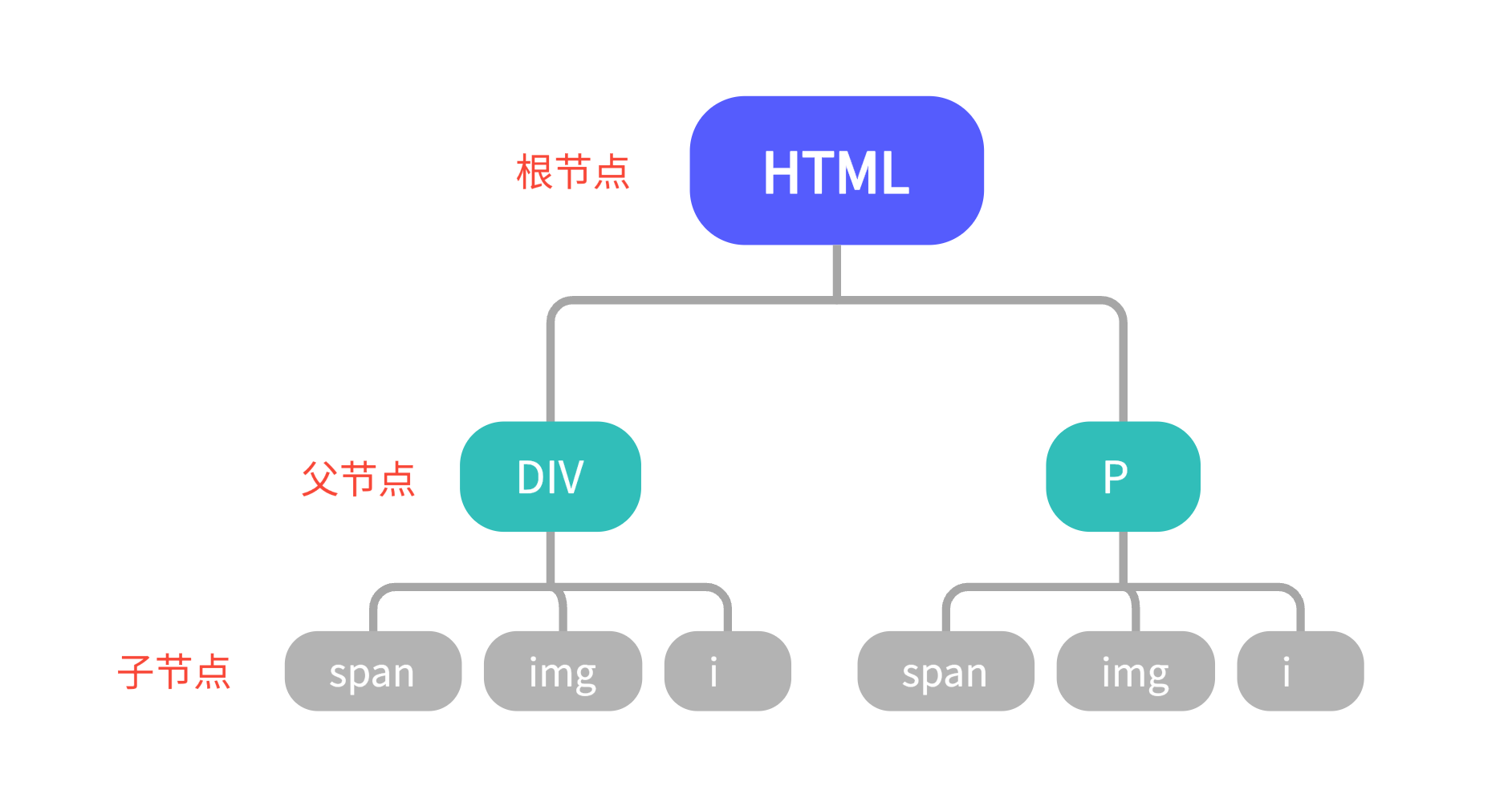
以上面的 HTML 節點樹為例,節點之間包含了下列的關係:
- 父節點 (Parent): HTML 是 DIV 和 P 節點的父節點;
- 子節點 (Child):DIV 和 P 是 HTML 的子節點;
- 兄弟節點 (Sibling):擁有同樣的一個父節點,DIV 和 P 就是兄弟節點。類似的 span、img 和 i 也是兄弟節點。
- 祖先節點 (Ancestor):html 是 span 的祖先節點,隔開一級;
- 後代節點 (Descendant):span 是 HTML 的後代節點,隔開一級。
除了瞭解這些概念,parent、sibling 等關鍵詞也非常關鍵,在匹配複雜的結構時常常用到。
絕對和相對路徑
xpath 中絕對路徑使用 / 開始,比如:/html/body/div[1]/a/img,絕對路徑較長,其中可能包含變化的部分,不建議單獨使用絕對路徑來選擇元素,最好配合其它語法。
比如下麵的情況單獨使用絕對路徑進行定位就會出錯:
// 本意是匹配第三個div下的span,但因為第一個div因為是動態顯隱的,導致匹配第而個div匹配到之前的第三個了
/html/body/div[2]/span
相對路徑以 // 開始,比如 //*[@class],表示只要包含 class 屬性的元素均可匹配,無論從哪一個節點開始。
下麵是一些常見選擇節點示例:
| 表達式 | 說明 | 舉例 |
|---|---|---|
| / | 下一個節點,或者根節點開始 | /html/body/div |
| // | 從任意節點開始 | //img |
| . | 選取當前節點 | //a/. |
| .. | 當前節點的父節點 | //a/.. |
| @ | 選取包含某屬性的元素 | //div[@class]或//@class |
| * | 表示任意元素或者任意屬性 | //*[@class] |
除此之外,通過谷歌瀏覽器-元素上審查元素-複製 xpath,可以直接獲取絕對路徑和相對路徑。
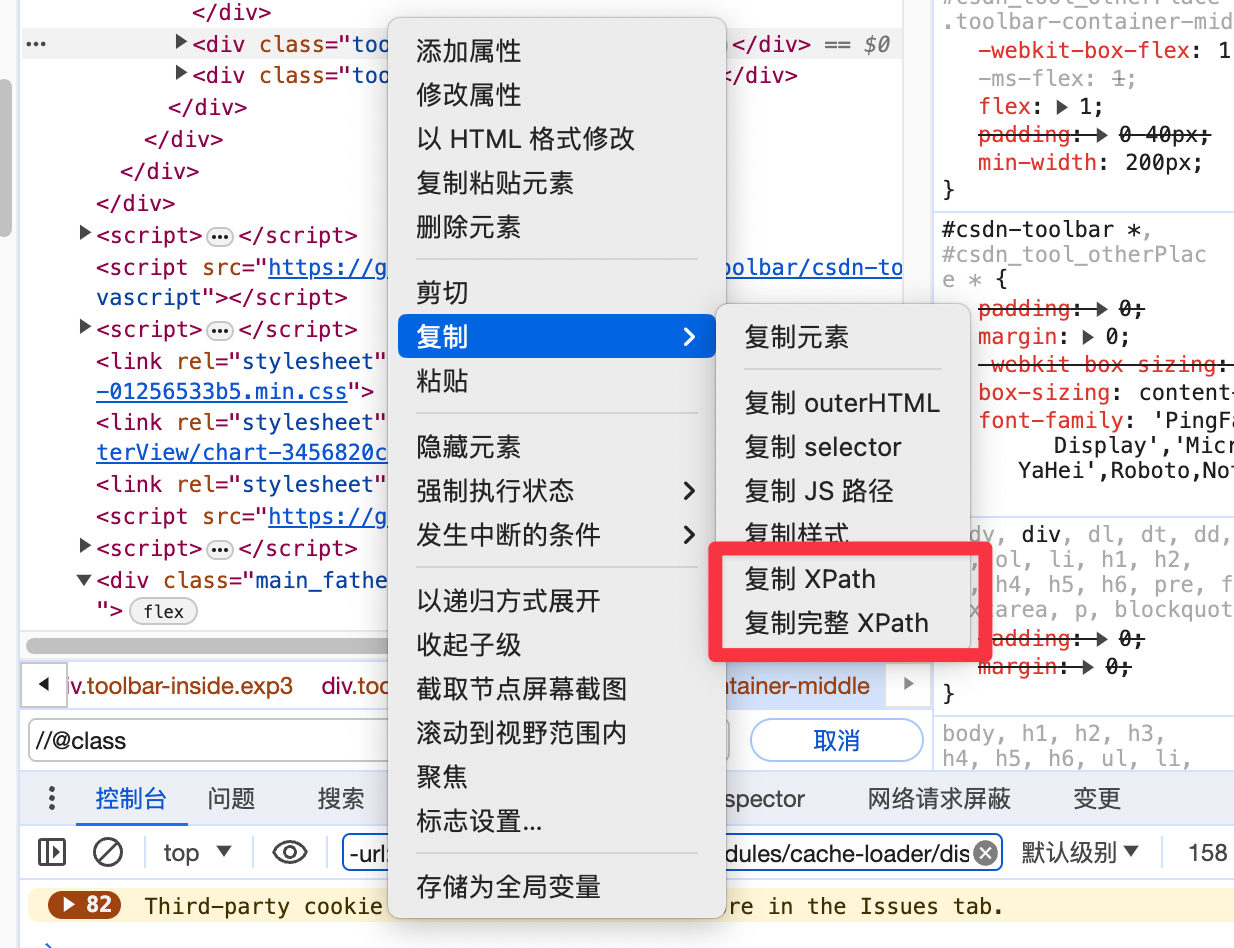
但複製下來的代碼,通常還需要進行一些修改,才能具備通用性。
基礎語法
定位需要的信息通常通過元素、屬性名、屬性值以及三者結合等方式進行。
下麵來分別看一下,也這段 html 代碼為例:
<div id="app">
<p class="title">喜歡的動物</p>
<ul>
<li class="cat">貓</li>
<li class="dog">狗</li>
<li id="panda">熊貓</li>
</ul>
<p class="title">喜歡的電影</p>
<ul>
<li>阿甘正傳</li>
<li>霸王別姬</li>
<li>阿凡達</li>
</ul>
<p>其它不需要信息</p>
</div>
1. 通過元素名定位
示例:
1.1 //div/p
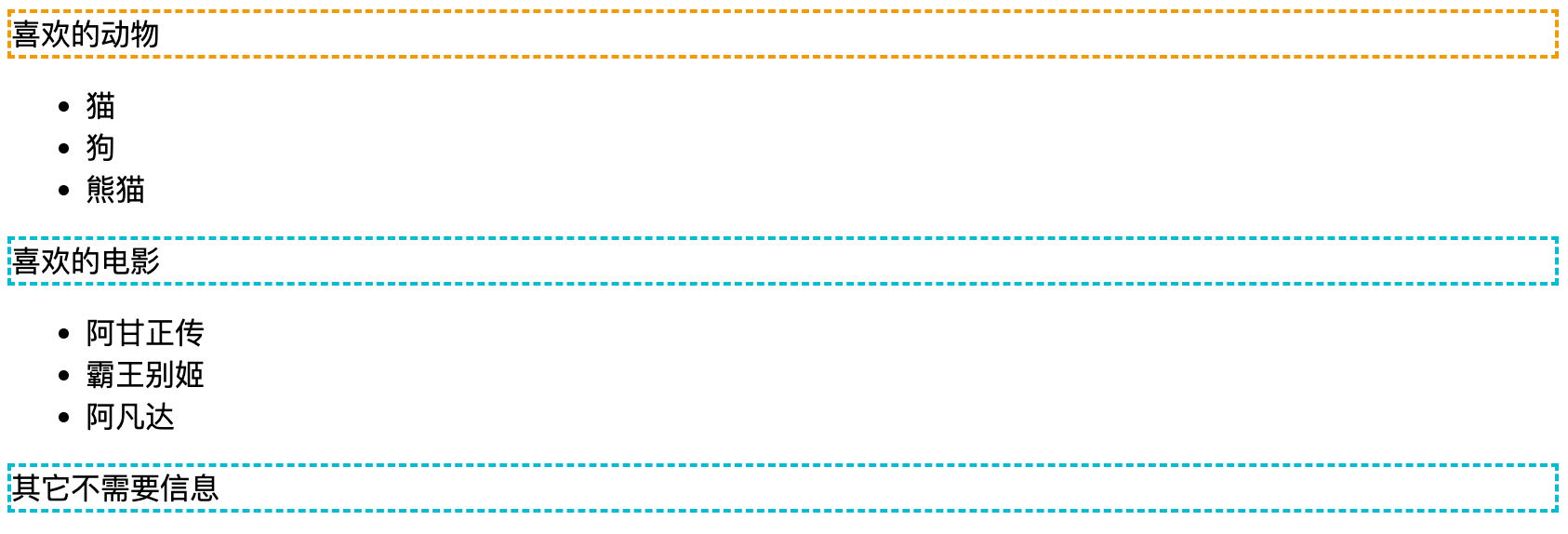
定位所有 div 下的 p 子元素,可以是任何 div,只要這個 div 的子節點包含 p 就可以匹配
1.2 //ul

會定位從任何節點開始的 ul 元素
1.3 /html/body/div/p

使用絕對路徑定位元素,必須從 /html 開始,否則最好使用 // 相對路徑開始
2. 通過屬性名定位
通過元素是否包含某個屬性來進行定位,屬性名需要使用 @ 開始,同時放在 [] 內
2.1 //*[@class]
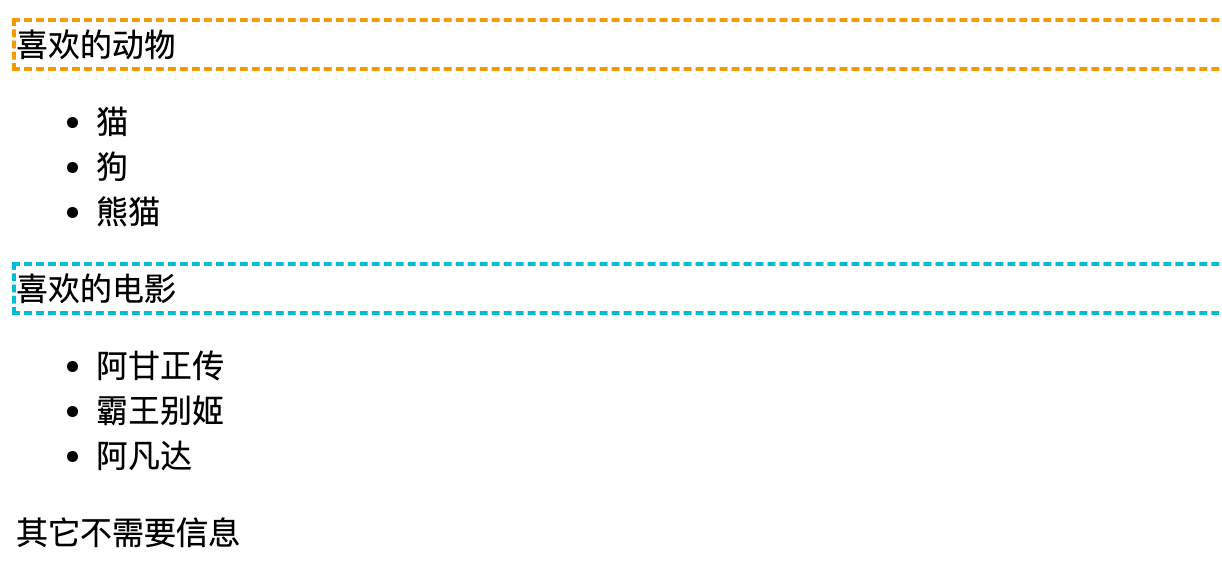
定位包含 class 屬性的元素
2.2 //@class

這種語法定位到的是屬性裡面的具體值 title,而不是元素,所有沒有元素沒選中
3. 通過屬性值定位
示例:
//li[@class="cat"]

定位包含 class 屬性,值為 cat 的 li 屬性元素
4. 使用邏輯運算符定位
常用邏輯運算符包括:and、or、not 三種
示例:
4.1 //li[@class and @class="cat"]

選中包含 class 屬性,並且屬性值為 cat 的 li 元素對象。
4.2 //li[@class or @id]

選中包含 class 或者 id 屬性的 li 元素對象。
4.3 //li[not(@class)]
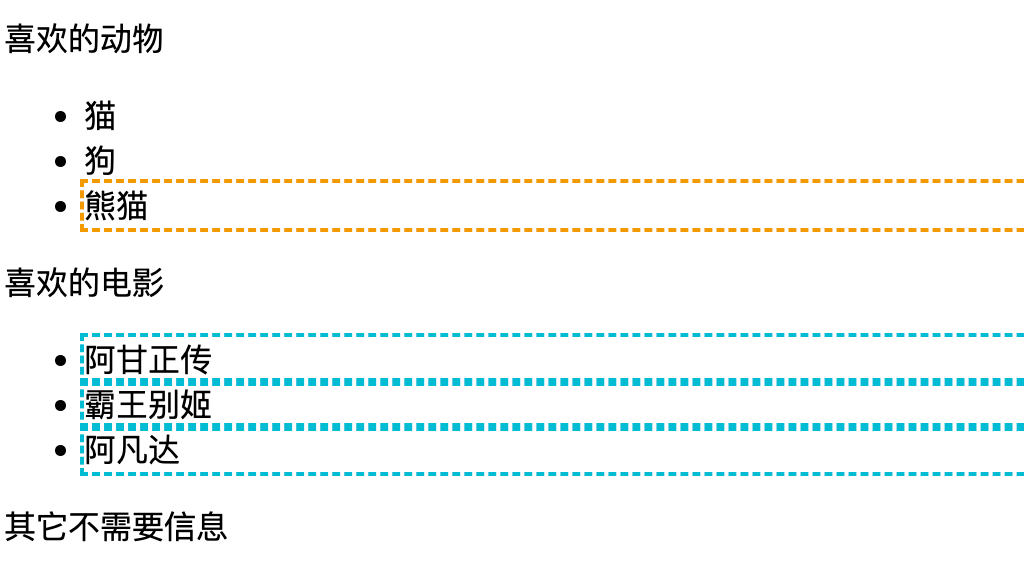
選中不包含 class 屬性的 li 元素對象。
5. 使用謂語定位
5.1 //li[1]
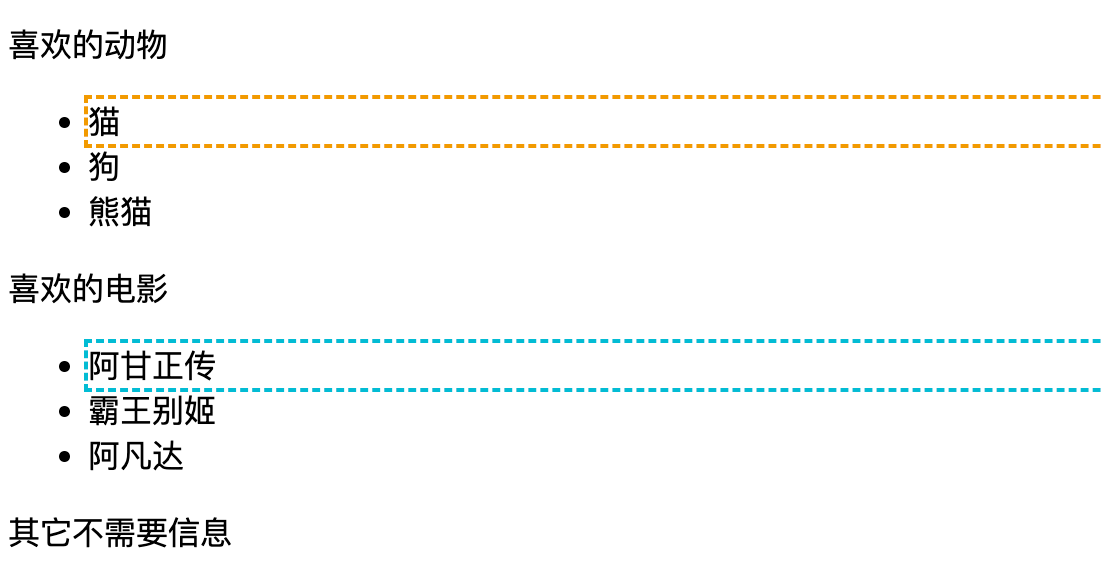
定位任意元素下的第一個 li。
註意
xpath 中索引從 1 開始。
5.2 (//li)[1]

兩者區別如下:
//li[1]任意元素下第一個li,也就是說這個 li 在任意的 ul 下是第一個就會被選中
(//li)[1]將所有的 li 選出來的結果數組中取第一個,這兩者是完全不同的含義
6. 使用文本定位
使用元素中文本的內容進行定位。
示例:
6.1 //li[text()="貓"]

選中文本內容為 貓 的 li 元素對象。
6.2 //*[contains(text(),"喜歡")]
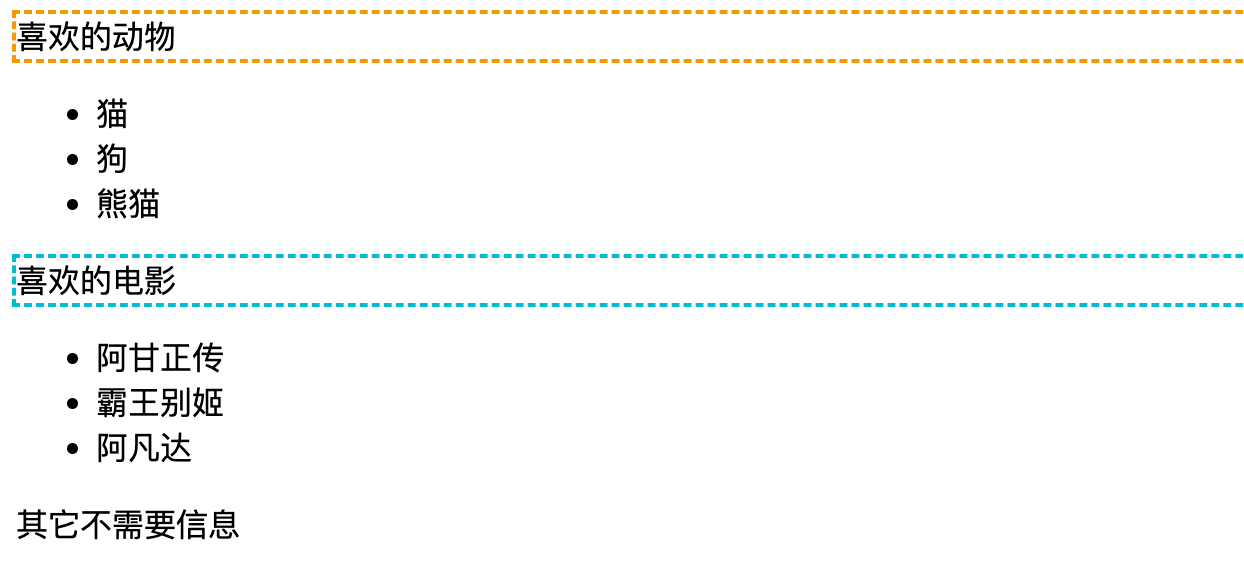
選中任意元素文本中包含 喜歡 兩個字的元素,其中 * 表示所有元素是通配符,contains() 表示包含函數。
類似的有:starts-with 和 ends-with 函數,表示以什麼字元開始和字元結尾的文本。
節點選擇器
除了相對和絕對選擇之外,下麵這些選擇器在處理較複雜的匹配場景可以發揮關鍵作用。
parent:::選中父級節點,/..也是選中父級,但是通常parent::用於寫在[]裡面作為條件來判斷child:::選中子級節點,/也是選中子級,通常也是作為條件來使用preceding-sibling:::選中同一層級的前面所有兄弟節點following-sibling:::選中同一層級的後面所有兄弟節點ancestor:::選中祖先節點,包括父級以及更上層的節點descendant:::選中當前節點下麵的所有節點,包括子級
舉例:
//*[ancestor::div]

選中所有元素中,上級是 div 的元素,其實也就是選中了所有元素,來看看這個
//ancestor::div

只選中了一個元素。
兩者的區別如下:
//*[ancestor::div]選中的*表示所有元素,這些元素條件是[ancestor::div]父級及以上有 div。
//ancestor::div選中的是作為別人父級及以上的 div,也就是選中的是 div,這個 div 的是別人的父級或者爺級等
兩者是完全不同的概念
美團 APP 匹配示例
看了半天 HTML,我們來瞭解一下 APP 中的 XML,通常匹配 APP 比網頁複雜太多,基本就那幾個元素,而且屬性名基本都一樣,所以常用的手段還是使用各種條件來進行限制匹配,下麵來看一個例子。
<android.view.View index="5" class="android.view.View" text="" checked="false" clickable="true">
<android.widget.TextView index="1" class="android.widget.TextView" text="象山酥院(湛江印象匯店)" checked="false"/>
<android.widget.TextView index="2" class="android.widget.TextView" text="" checked="false" clickable="true"/>
<android.view.View index="3" class="android.view.View" text="" checked="false">
<android.widget.TextView index="0" class="android.widget.TextView" text="5.0" checked="false" />
</android.view.View>
<android.widget.TextView index="4" class="android.widget.TextView" text="周銷量 872" checked="false" />
</android.view.View>
<android.view.View index="5" class="android.view.View" text="" checked="false" clickable="true">
<android.widget.TextView index="1" class="android.widget.TextView" text="蜜雪冰城" checked="false"/>
<android.widget.TextView index="2" class="android.widget.TextView" text="" checked="false" clickable="true"/>
<android.view.View index="3" class="android.view.View" text="" checked="false">
<android.widget.TextView index="0" class="android.widget.TextView" text="5.0" checked="false"/>
</android.view.View>
<android.widget.TextView index="4" class="android.widget.TextView" text="周銷量 2322" checked="false"/>
</android.view.View>
上面代碼為美團的城市列表頁面的 UI XML 代碼,其中每個元素都包含大量相同的屬性和屬性值,關鍵在於整個頁面,任何地方基本就是 android.view.View 和 android.widget.TextView ,像匹配 HTML 那樣元素顯然行不通。
示例:獲取兩個商品的評分
//*[@text and ancestor::*/following-sibling::*[contains(@text, '周銷量')]]
規則解釋:獲取任何包含 text 屬性的元素,它的父級的的兄弟元素必須是一個 text 值中包含 "周銷量"的元素。
我這裡沒有使用 [1][2][3] 來定位,是因為不同商品的屬性很多時候不一樣。
通常還是根據想要的元素的位置,以及相鄰元素的特征來定位,首先找到獨特的文本,比如上面的周銷量是固定會出現的,還有 ¥ 符號也可以,這些都是位置和文本值固定的,找到這個的位置,再去定位需要的元素的位置。
工具推薦
- 谷歌瀏覽器-審查元素-
ctrl + f,可以直接輸入 xpath 語句 - 谷歌瀏覽器-selectorshub 插件,文中使用的是這個插件


