
什麼是大數據 大數據(Big Data)是指在傳統數據處理方法難以處理的情況下,需要新的處理模式來具有更強的決策力、洞察發現力和過程優化能力的海量、高增長率和多樣化的信息資產。大數據的特征通常被概括為“4V”,即: Volume(容量):大數據的規模非常龐大,通常以 TB(太位元組)、PB(拍位元組)或 ...
翻譯
論文來源:bitcask-intro.pdf (riak.com)
背景介紹
Bitcask的起源與Riak分散式資料庫的歷史緊密相連。在Riak的K/V集群中,每個節點都使用了可插拔的本地存儲;幾乎任何結構的K/V存儲都可以用作每個主機的存儲引擎。這種可插拔性使得Riak的處理能夠並行化,從而可以在不影響代碼庫其他部分的情況下改進和測試存儲引擎。
有很多類似的本地K/V存儲系統,包括但不限於Berkeley DB、Tokyo Cabinet和Innostore。在評估此類存儲引擎時,我們想實現的目標包括:
- 讀取或寫入每個項目的低延遲
- 高吞吐量,尤其是在寫入隨機項目的傳入流時
- 處理比RAM大得多的數據集的能力,無退化
- 故障友好性,在快速恢復和不丟失數據方面都很好
- 易於備份和恢復
- 相對簡單、可理解(因而可支持)的代碼結構和數據格式
- 訪問負載大或容量大時的可預測行為
- 允許在Riak中輕鬆預設使用的許可證
實現其中一些目標並不困難,但是想實現所有目標就不那麼容易了。
現有的本地K/V存儲系統(包括但不限於作者編寫的系統)均未達到上述所有目標。當我們在與Eric Brewer討論這個問題時,他關於哈希表日誌合併的關鍵見解是:這樣做可能會比LSM樹更快或更快。
這導致我們以新的視角探索了20世紀80年代和90年代首次開發的日誌結構化文件系統所使用的一些技術。這次探索導致了Bitcask的誕生,它是一個能夠完全實現上述所有目標的存儲系統。雖然Bitcask最初是為了給Riak使用而誕生,但是它的設計很通用,因此也可以作為其他應用程式的本地K/V存儲。
模型描述
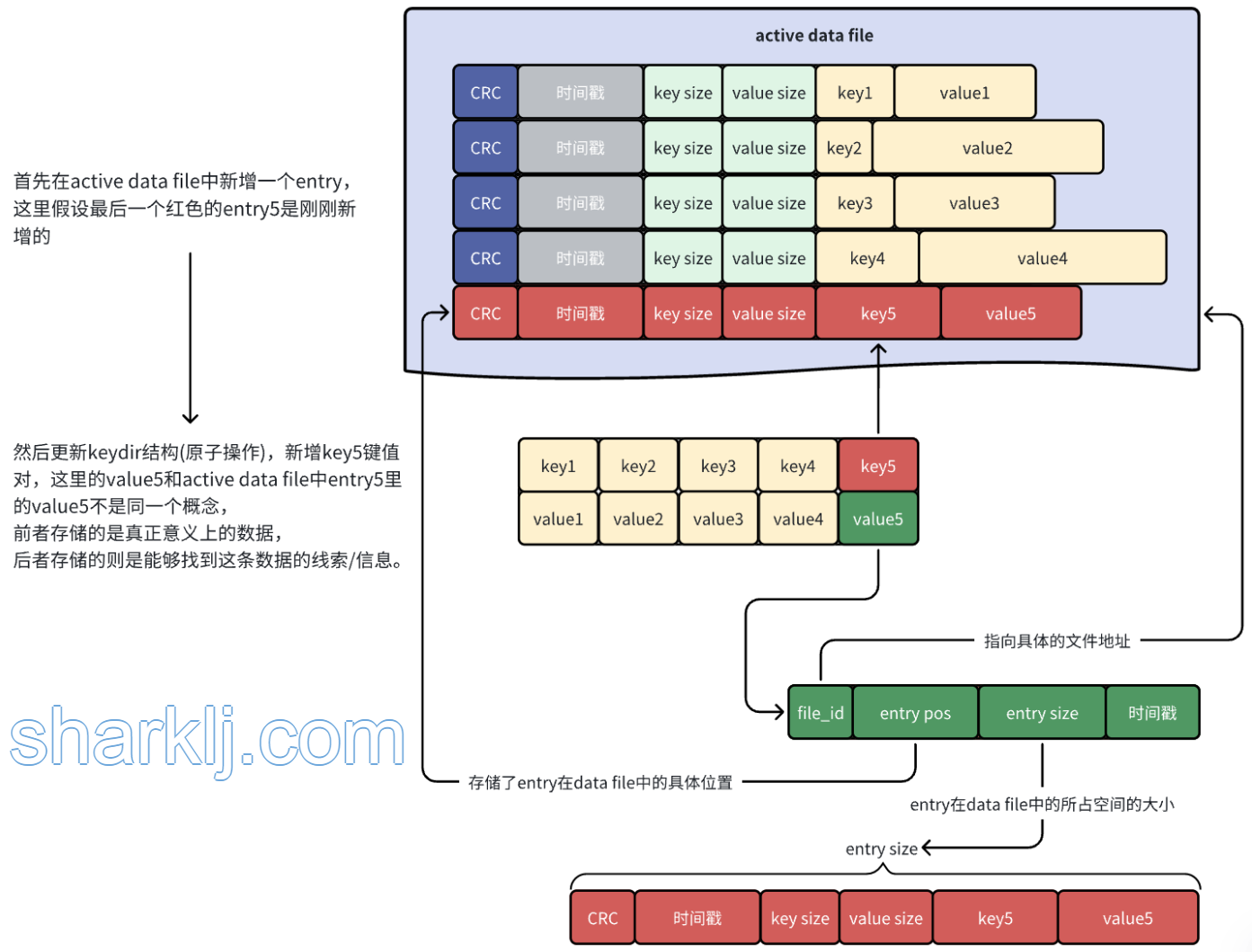
active data file
最終採用的模型在概念上非常簡單。Bitcask實例是一個目錄,我們強制規定在給定時間內,只有一個操作系統進程可以打開該Bitcask進行寫入。您可以將該進程有效地視為“資料庫伺服器”。在任何時候,該目錄中都有一個文件由伺服器進行寫入操作。當該文件達到一定大小時,它將被關閉,並創建一個新的活動文件。[font color="#FFA500"]一旦文件被關閉,無論是出於有意還是由於伺服器退出,它都被視為不可變的,並且永遠不會被再次打開進行寫入。[/font]
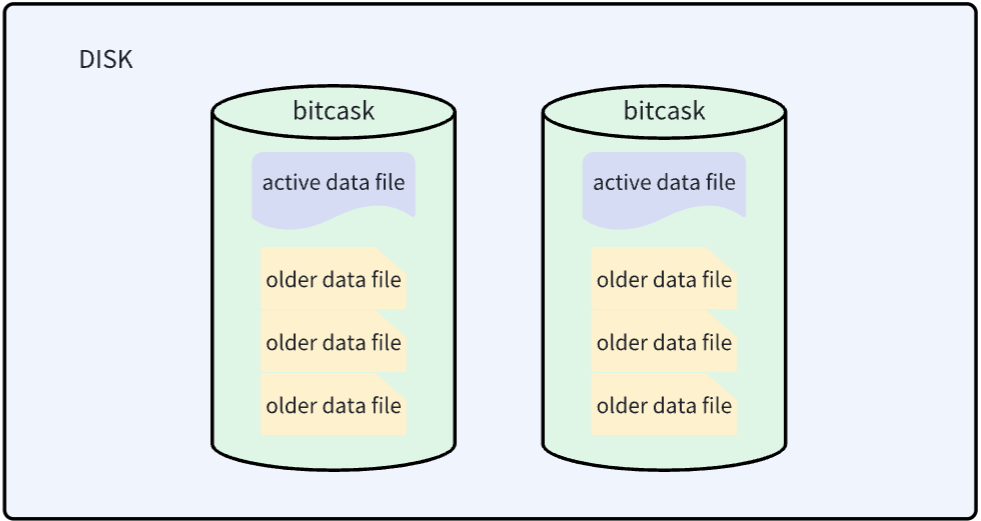
活動文件,也就是上文提到的active data file,只能以追加的方式寫入,這意味著順序寫入的同時不需要磁碟定址。
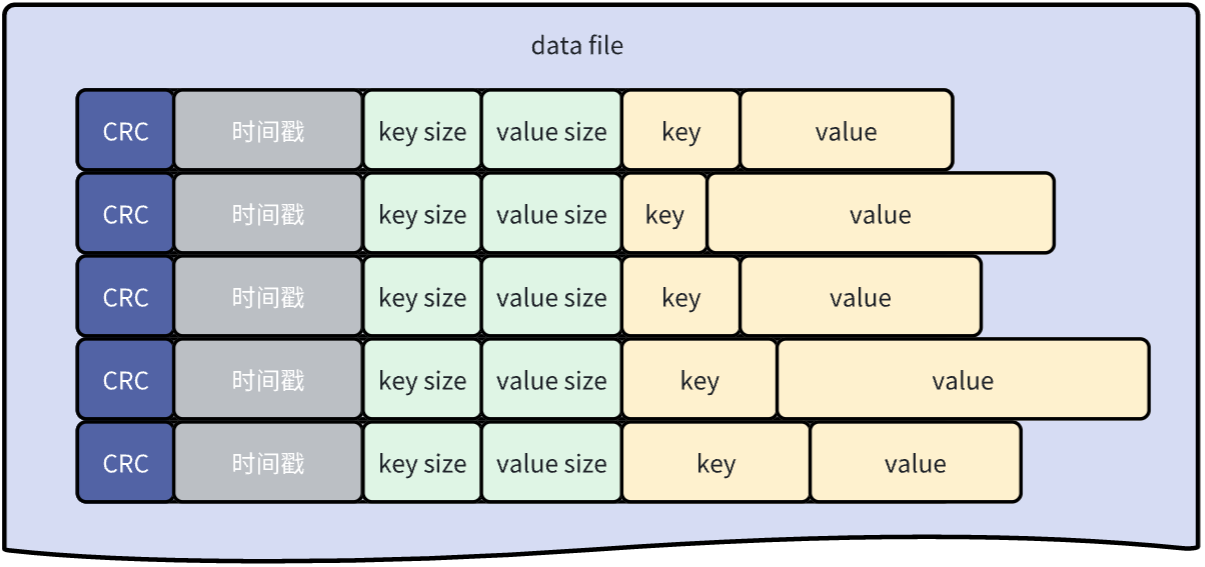
文件中的每個鍵值對entry的格式如下:

每次寫入時,都只是向active data file追加一個新的entry。刪除操作只是寫入一個特殊的墓碑值(可以理解為是一個特殊標記),它將在下一次合併時被刪除。因此,Bitcask數據文件無非是這些entry的線性序列:
keydir
在active data file中完成追加操作後,接著去記憶體中更新一個名為keydir的數據結構。keydir是一個哈希表(在本論文中它是一個哈希表,也可以是其他數據結構),它將Bitcask中的每個key映射到一個固定大小的結構,這個結構記錄了這個key寫在哪個文件、該鍵在該文件中的偏移量以及大小。
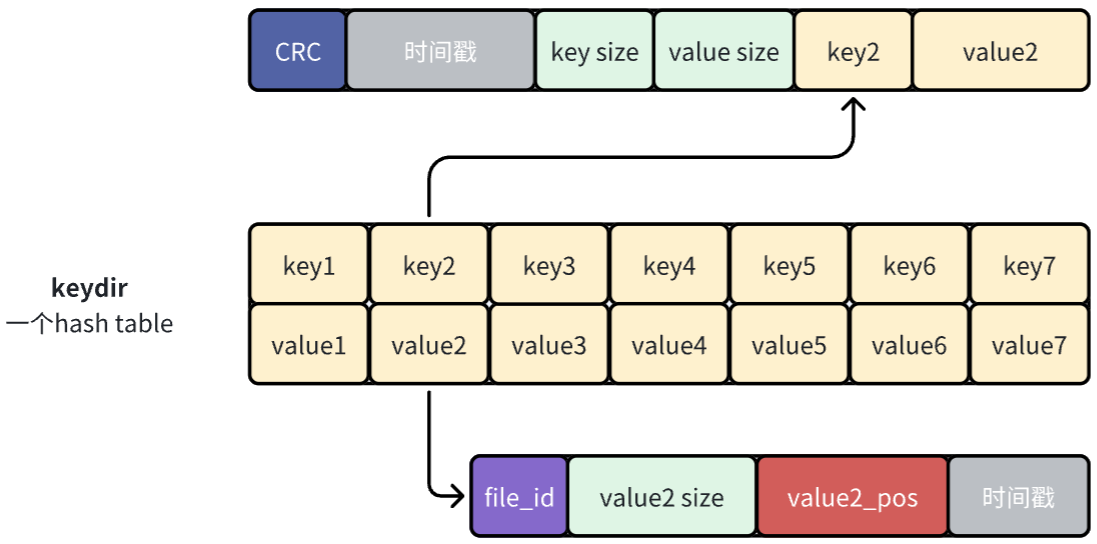
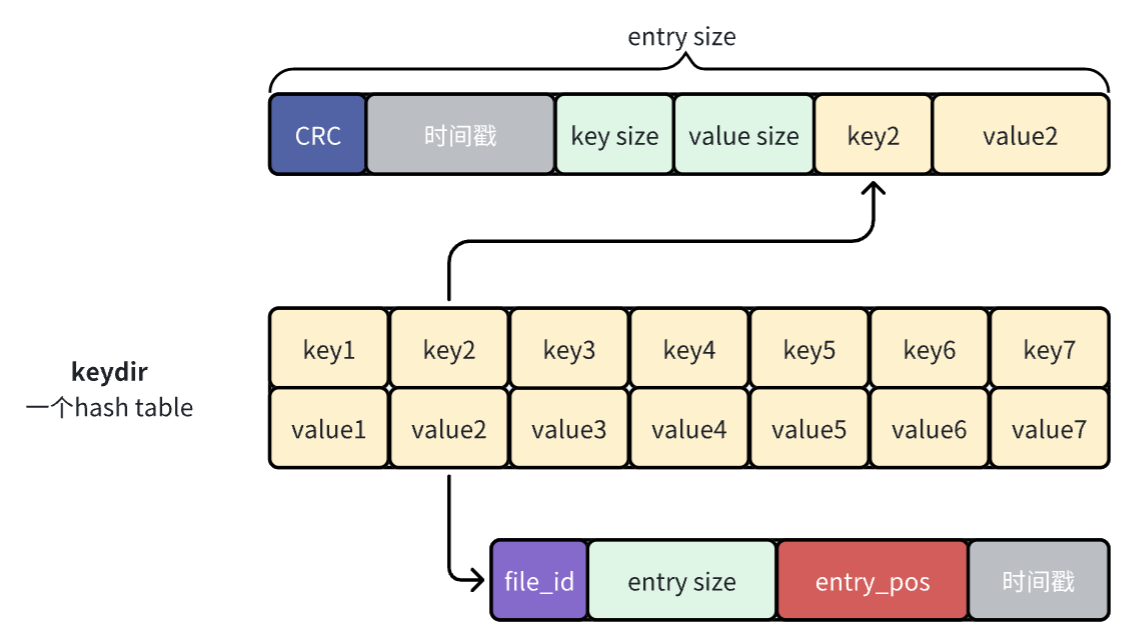
一開始我覺得上面這張圖就是對bitcask中哈希表存儲內容的正確理解,但是後來覺得下麵這個圖才是,因為哈希表的value存儲的應該是entry的信息,而不是entry中value的信息。原論文中的圖有比較大的迷惑性。
數據寫入與讀取
數據的寫入其實在上面兩節已經介紹過了,為了方便理解記憶就再總結一下。
寫入很簡單,就是往bitcask中追加一條entry,然後更新keydir(原子操作),將剛剛新增的entry的信息存儲起來,就像下麵這樣:
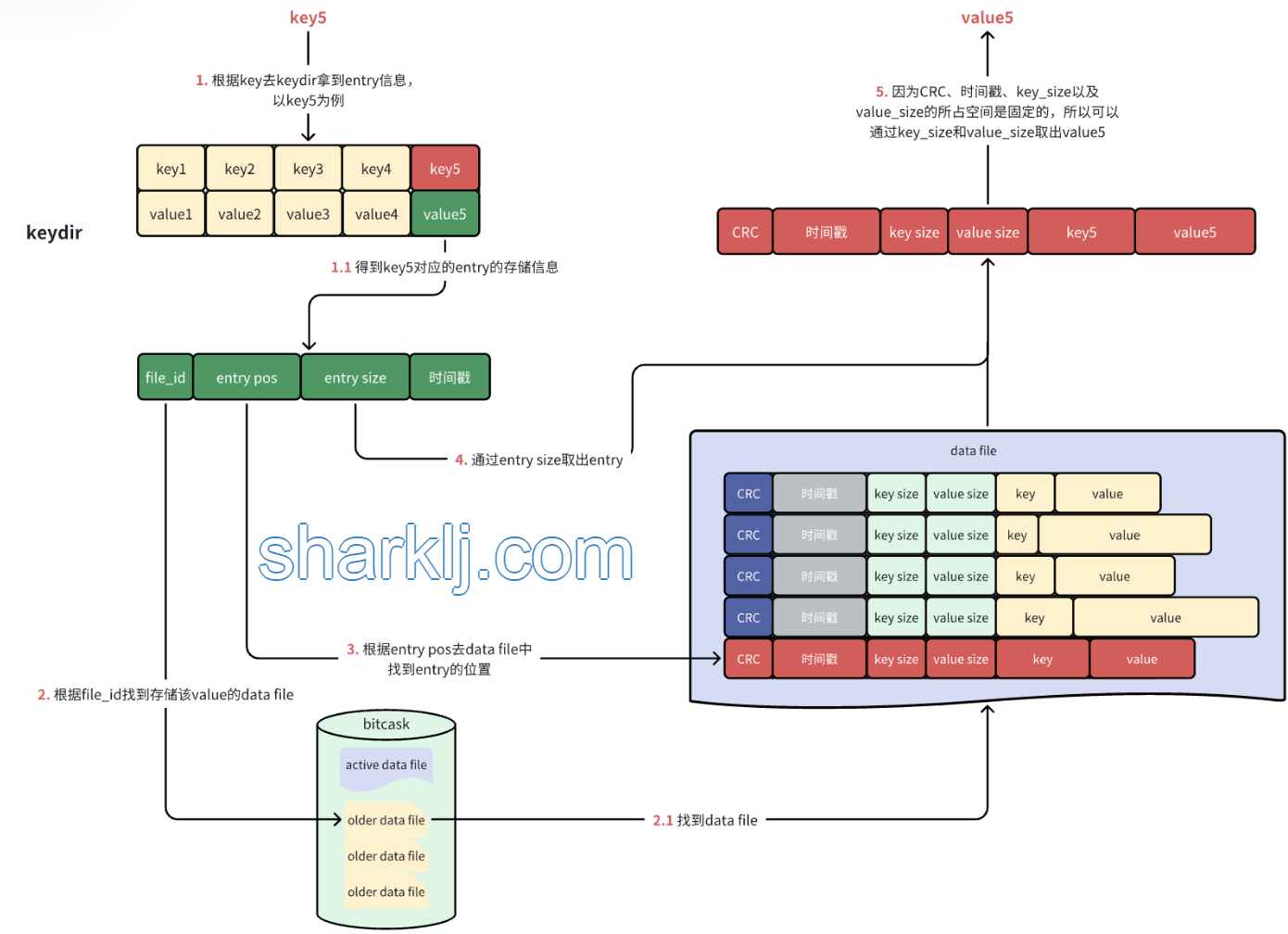
數據的讀取流程則是先拿著key去keydir中取出相應的entry信息,然後根據entry中提供的信息去data file中取出key對應的value,就像下麵這樣:
數據合併
因為bitcask刪除的數據的方式是通過追加一條相同key的entry實現的,所以文件的size會越來越大,就需要定期的合併文件,合併的過程是這樣的:
- 先遍歷所有的
old data file,將所有的有效數據進行合併,如果有多個entry含有相同的key,則只保留最新的entry,有點像Redis中的AOF, - 合併完成後,
old data file會變成merge data file,且數量也會減少,例如10個old data file合併成5個merge data file。 - 因為
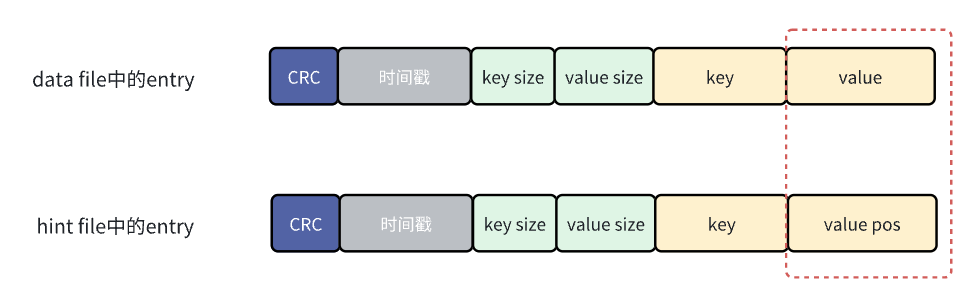
bitcask是在記憶體中構建索引,也就是之前提到的keydir,構建keydir需要在啟動的時候掃描所有的data file,如果數據量很大,那麼構建索引的過程就會很耗時,為瞭解決這個問題,bitcask在合併數據的時候還會為每個merge data file生成一個hint file,這個hint file中存儲的也是一堆entry,這些entry的格式和data file中的entry保持一致,唯一的區別就是data file中的entry存儲的value是真實數據,而hint file中entry的value存儲的是數據的位置。
結束
目前對bitcask的理解也就是這些了,肯定有不准確的地方,想要徹底弄明白也只能自己手搓一個kv存儲才行。有任何問題都可以在評論區交流。


