面試題 海量數據里查詢某一固定首碼的key 生產上如何限制 keys * / flushdb / flushall 等危險命令以防止誤刪誤用? MEMORY USAGE 命令用過嗎? BigKey問題,多大算big?如何發現?如何刪除?如何處理? BigKey你做過調優嗎?惰性釋放lazyfree了 ...
海量數據里查詢某一固定首碼的key
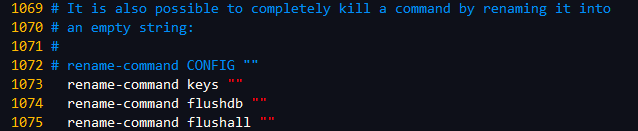
生產上如何限制 keys * / flushdb / flushall 等危險命令以防止誤刪誤用?
MEMORY USAGE 命令用過嗎?
BigKey問題,多大算big?如何發現?如何刪除?如何處理?
BigKey你做過調優嗎?惰性釋放lazyfree瞭解過嗎?
MoreKey問題,生產上Redis資料庫有1000萬條記錄,如何遍歷?
MoreKey案例
大批量往Redis中插入100萬條測試數據
試試keys * 遍歷查詢花費多少秒?試試就逝世,足足花費了二十幾秒!
生產上如何限制 keys * / flushdb / flushall 等危險命令以防止誤刪誤用?
通過redis.conf配置文件設置禁用
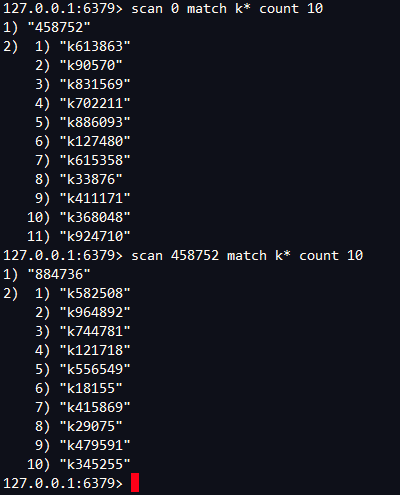
不用keys * 應該用什麼?SCAN
詳情見官方文檔:
SCAN cursor [MATCH pattern] [COUNT count]
-
cursor - 游標。
-
pattern - 匹配的模式。
-
count - 指定從數據集里返回多少元素,預設值為 10 。
什麼是 Redis 增量遍歷?
SCAN 命令是一個基於游標的迭代器,每次被調用之後, 都會向用戶返回一個新的游標, 用戶在下次迭代時需要使用這個新游標作為 SCAN 命令的游標參數, 以此來延續之前的迭代過程。
非常特別,它不是從第一維數組的第零位一直遍歷到末尾,而是採用了高位進位加法來遍歷。之所以使用這樣特殊的方式進行遍歷,是考慮到字典的擴容和縮容時避免槽位的遍歷重覆和遺漏。
雖然
SCAN 返回一個包含兩個元素的數組:
第一個元素是用於進行下一次迭代的新游標, 第二個元素則是一個數組, 這個數組中包含了所有被迭代的元素。如果新游標返回零表示迭代已結束。
SCAN的遍歷順序
BigKey案例
多大算big
參考《阿裡雲Redisson開發規範》

string和二級結構
string是value,最大512MB,但是 ≥ 10KB 就是BigKey
list、hash、set、zset,個數超過5000就是BigKey(by the way,它們都可以存儲超過40億個元素)
危害
-
記憶體不均,集群遷移困難
-
大key導致超時刪除
-
網路流量阻塞
如何產生
社交類:王心凌粉絲列表,典型案例粉絲逐步遞增
彙總統計:某個報表,年月日經年累月的積累
如何發現
redis-cli --bigkeys
優點:給出每種數據結構Top 1 bigkey,同時給出每種數據類型的鍵值個數+平均大小
不足:想查詢大於10kb的所有key,--bigkeys參數就無能為力了,需要用到memory usage來計算每個鍵值的位元組數
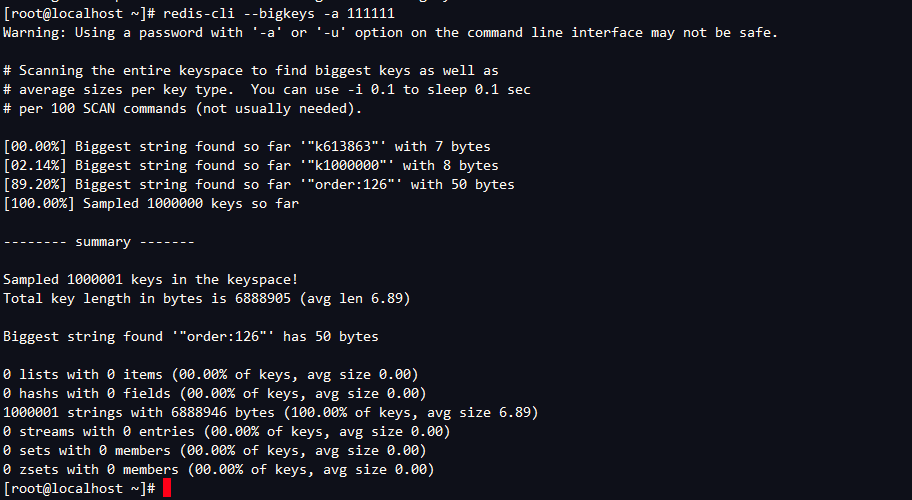
redis-cli -h 127.0.0.1 -p 6379 -a 111111 --bigkeys
# 每隔 100 條 scan 指令就會休眠 0.1s,ops 就不會劇烈抬升,但是掃描的時間會變長
redis-cli -h 127.0.0.1 -p 7001 –-bigkeys -i 0.1
MEMORY USAGE key MEMORY USAGE key [SAMPLES count]
詳情見官網:
返回的結果是 key 的值以及為管理該 key 分配的記憶體總位元組數。
對於嵌套數據類型,可以使用選項 SAMPLES,其中 count 表示抽樣的元素個數,預設值為 5 。當需要抽樣所有元素時,使用 SAMPLES 0 。

如何刪除
參考《阿裡雲Redisson開發規範》
String
一般用del,過於龐大用unlink;
hash
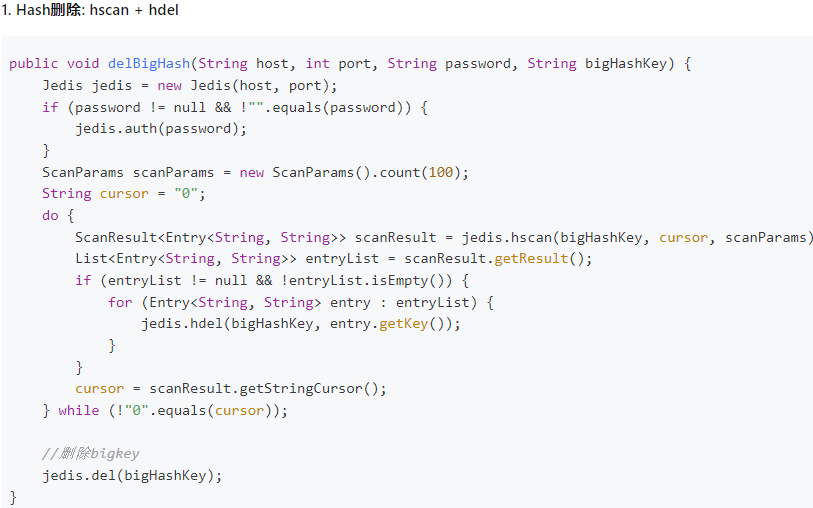
使用hscan每次獲取少量field-value,再使用hdel刪除每個field。
命令:
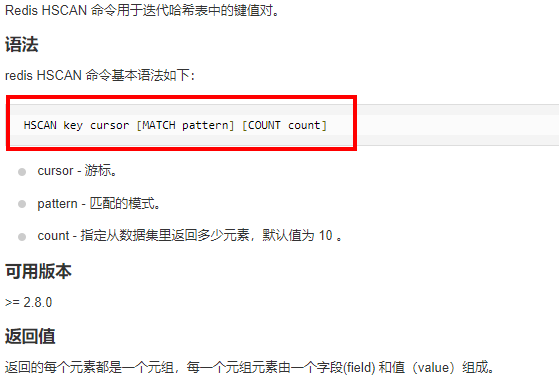
阿裡手冊:
list
命令
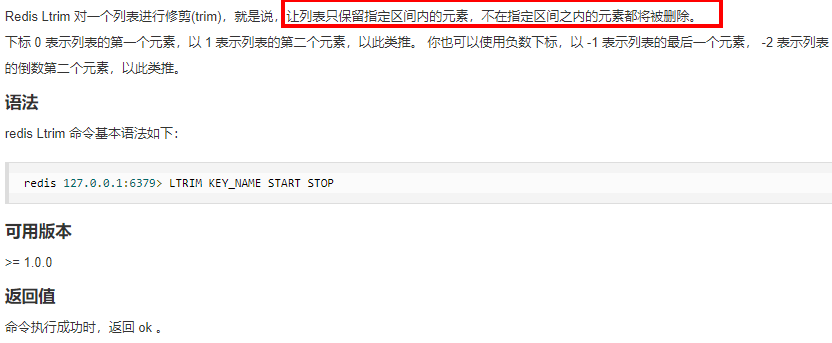
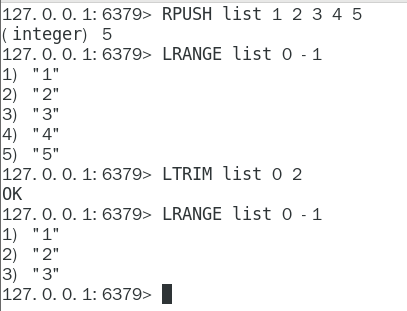
阿裡手冊:
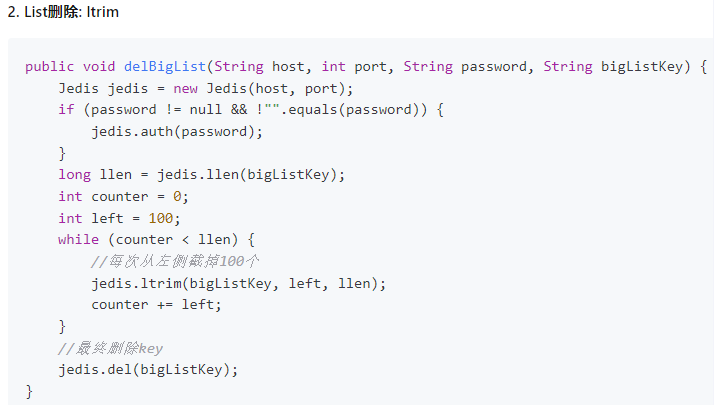
set
使用sscan每次獲取部分元素,再使用srem命令刪除每個元素
命令

阿裡手冊
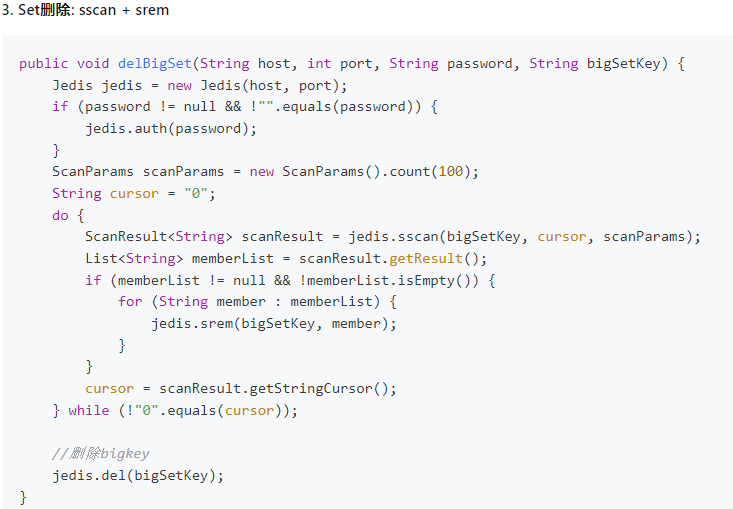
zset
使用zscan每次獲取部分元素,再使用 ZREMRANGEBYRANK 命令刪除每個元素
命令


阿裡手冊
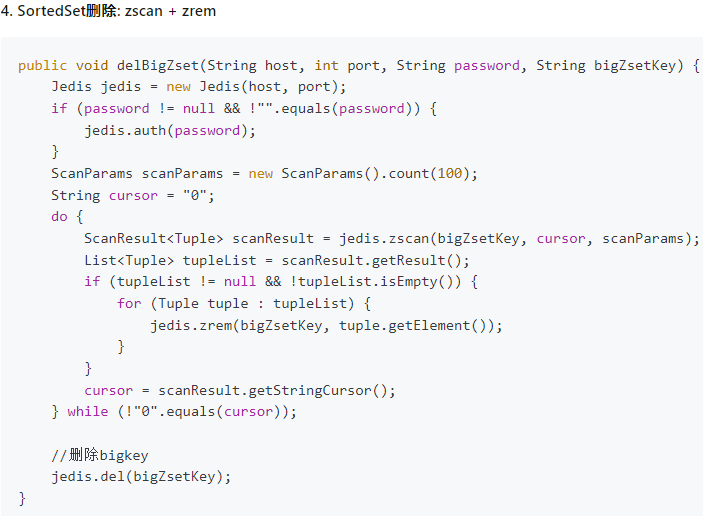
BigKey生產調優
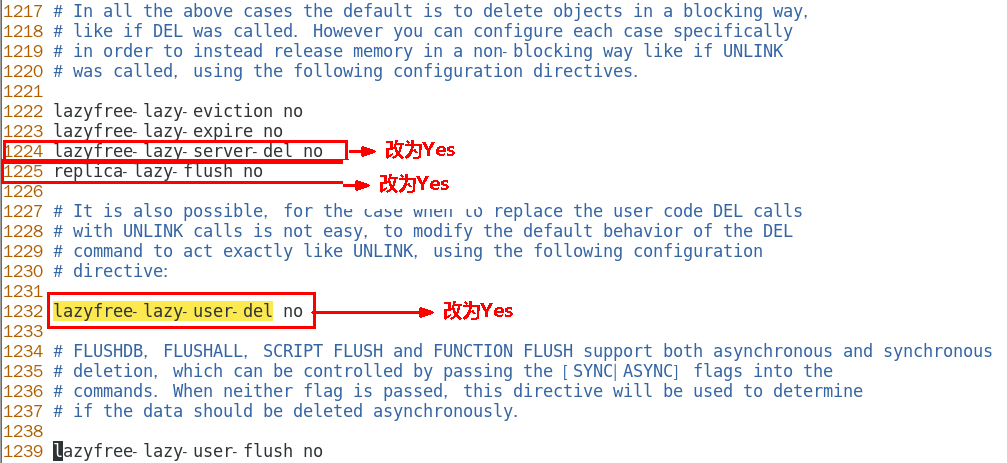
redis.conf 配置文件 LAZY FREEING 相關說明
阻塞和非阻塞刪除命令

優化配置