
1. 同城雙活是什麼 同城雙活是一種容災架構的設計模式,主要用於提高系統的可用性和容錯性。它通常涉及在同一個城市內建立兩個數據中心(機房),這兩個數據中心同時對外提供服務,實現了高可用性和冗餘。 關鍵特點和優勢包括: 雙活部署: 兩個數據中心都處於活躍狀態,同時處理用戶請求。這樣,當一個數據中心發生 ...
1. 同城雙活是什麼
同城雙活是一種容災架構的設計模式,主要用於提高系統的可用性和容錯性。它通常涉及在同一個城市內建立兩個數據中心(機房),這兩個數據中心同時對外提供服務,實現了高可用性和冗餘。
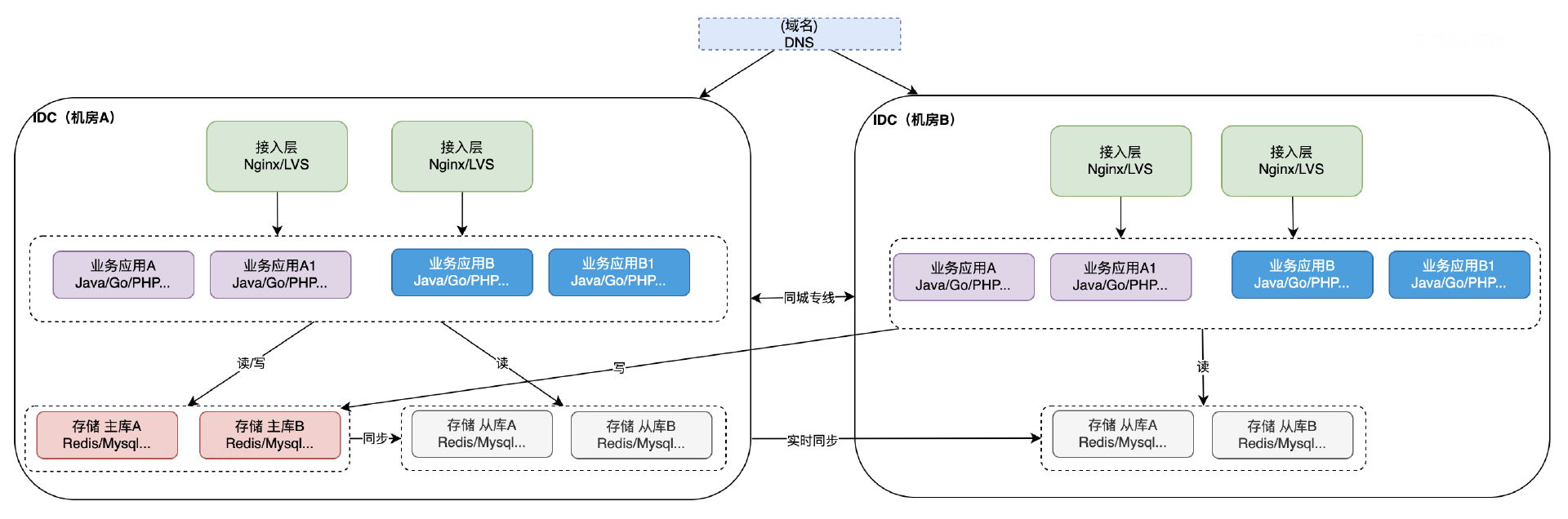
關鍵特點和優勢包括:
雙活部署: 兩個數據中心都處於活躍狀態,同時處理用戶請求。這樣,當一個數據中心發生故障或維護時,另一個數據中心可以繼續提供服務,確保業務的連續性。
故障隔離: 如果一個數據中心遇到故障,可以將流量切換到另一個正常工作的數據中心,減少服務中斷時間。
負載均衡: 雙活架構通常會利用DNS進行分流,讓流量按照一定比例分佈到兩個數據中心,提高整體性能和吞吐量。
降低延遲: 由於兩個數據中心都位於同一個城市,網路延遲相對較低,有助於提供更快的服務響應時間。
災難恢復: 在同城雙活的架構下,即使發生了災難性事件,比如自然災害,仍然有一個可用的數據中心,可以更迅速地進行災難恢復。
需要註意的是,同城雙活雖然提高了系統的可用性,但仍然存在無法解決的一些單點故障和問題,例如城市級別的停電或其他災難性事件。在一些對服務連續性要求極高的場景中,可能需要考慮更複雜的容災架構,如異地多活。
2. 什麼樣的業務需要同城雙活
任何對高可用有要求的業務都可以在容災架構上選擇同城雙活,同城雙活是異地多活的基礎。
3. 雙活的部署範圍
3.1 全量服務雙活or部分服務雙活
通常在同城雙活架構中不是所有業務服務都必須進行雙活部署,而是根據業務的特性和需求來進行選擇,因為這涉及到成本和複雜性的權衡。有些業務服務可能並不是那麼關鍵,或者其可用性要求並不高,在這種情況下,單活部署足夠滿足需求,同時減少了系統的複雜性和成本。
大多數公司會選擇對一些關鍵業務中需要高可用性的服務,進行雙活部署。而對非關鍵服務採取單活部署的方式,以平衡系統的可用性和成本。這樣,即使一個數據中心發生故障不會導致關鍵業務不可用。

3.2 哪一部分雙活?
1.挑選要雙活的業務
首先需要確定哪一個業務雙活,在一個互聯網公司通常有好多個業務,例如阿裡的淘寶、阿裡雲,位元組的頭條、抖音,滴滴的網約車,兩輪車等等。建立雙活首先確定好業務,然後找到業務中最核心的鏈路去建設雙活(確定哪個業務搞雙活通常和公司的戰略息息相關)

2.確定業務的核心鏈路
在業務領域,核心鏈路可能表示業務流程中最關鍵、最重要的步驟或環節。這些環節是直接影響業務成功的關鍵步驟,比如滴滴網約車業務中核心鏈路有乘客發單,司機接單,完單等等
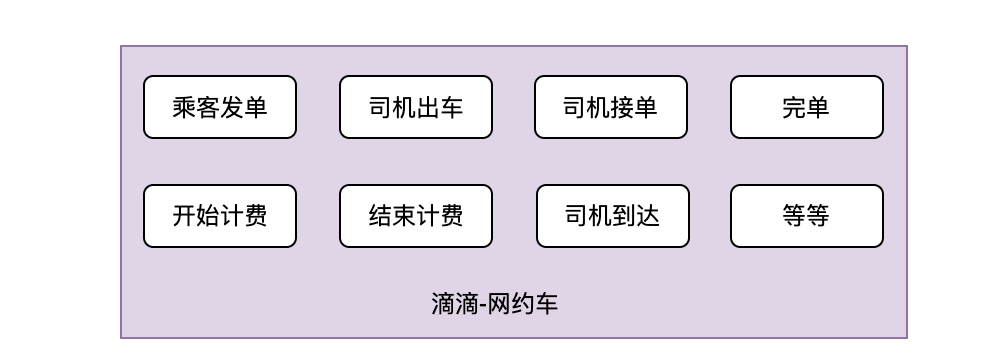
對核心業務的核心鏈路建設雙活,保證在單機房故障時核心鏈路在另一個機房可以繼續運轉,保證核心鏈路不受影響既是保證了業務的成交量不受影響,那麼整體的損失就相對較小。
在微服務盛行的時代,通常一條核心鏈路一定會包含多個服務,這其中會涉及到網關,業務服務,中台服務,中間件、存儲等等
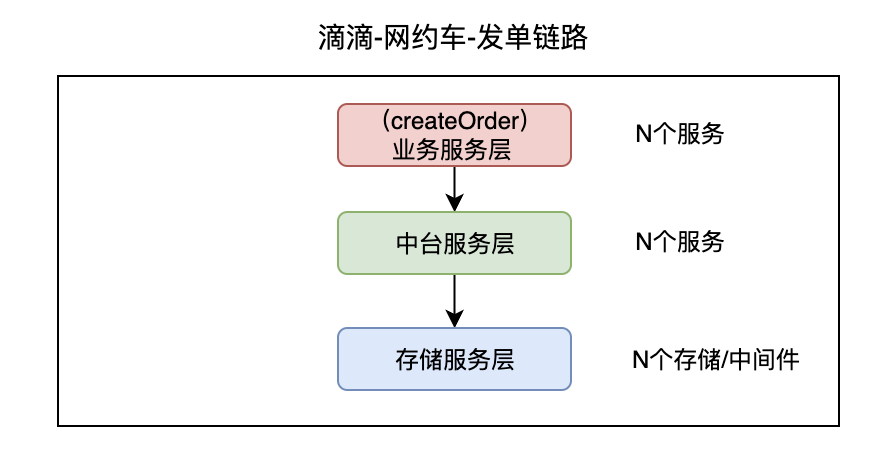
3.3 核心鏈路的服務如何梳理
通常一條核心鏈路中就包含了多個服務,那麼具體包含哪些服務(業務&存儲等),這些服務又該如何梳理呢?通常的做法:首先需要人工梳理標記,最起碼先標記處某一個鏈路的入口,例如乘客發單的入口是/create/order,然後結合全鏈路追蹤能力觀察從發單入口進來的流量( 生產流量,壓測流量,測試流量)都經過哪些服務從而梳理出發單鏈路所涉及到的服務。
不過在一個大公司內,由於各種歷史原因(懂的都懂)全鏈路追蹤很有可能覆蓋不全,那麼就需要再結合日誌以及監控等信息來彌補全鏈路追蹤斷鏈的情況,從而不斷的完善與標記這條核心鏈路中所涉及到的服務,整個核心鏈路標記與維護的過程,大多數公司都是從最開始的人工到後期慢慢形成產品,自動化進行標記。
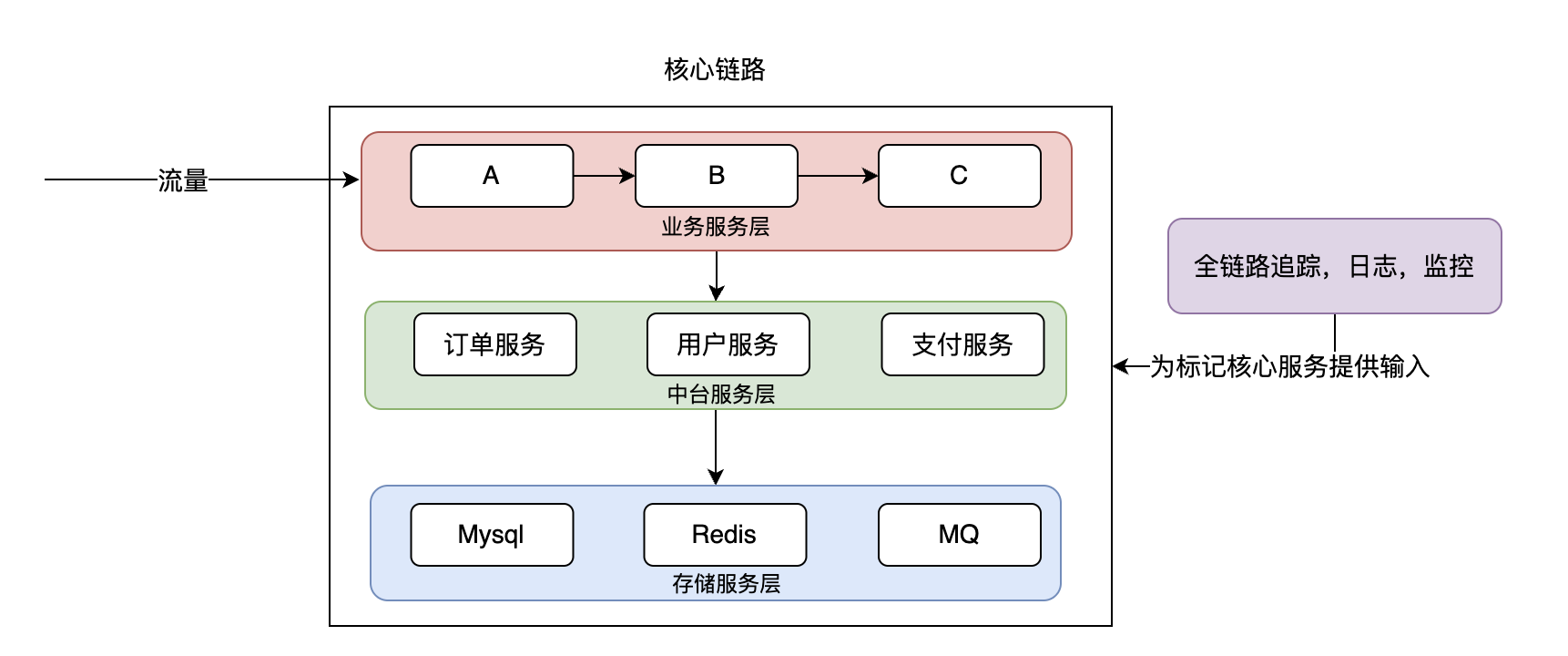
3.4 核心鏈路的問題
經過上面的梳理核心鏈路逐漸成型,但是問題也接踵而來。核心鏈路上的服務可能會越來越多,都要在雙活架構中等量部署到新機房嘛?
答案:所謂的核心服務也並不一定要全量部署到新機房做雙活,因為通過人工,全鏈路,日誌,監控等手段標記的核心服務往往是大而全的,這裡面標記出來的服務可能有很多,但是其中也有可能是弱依賴服務,弱依賴服務在同城雙活部署場景下並不是必須的。
-
強依賴服務:當一個服務是強依賴,意味著當這個服務出現故障不可用時,整個鏈路將會收到影響,甚至是整個系統的穩定性和可用性都會受到影響。
-
弱依賴服務:當一個服務是弱依賴,意味著當這個服務出現故障不可用時,系統仍然可以部分或完全運行。弱依賴的設計有助於系統的彈性和容錯性,因為系統的一部分可以在其他部分不可用的情況下繼續運行。
如果是在小公司可能不用考慮這件事,但在具有一定規模的公司內,核心鏈路上的服務也許也會很多。如果全量部署成本依然會很高,特別是在提倡降本增效的近幾年,雙活的成本也是需要控制的。所以如果要做到成本可控,那麼就需要找到核心鏈路中的強依賴服務部署在新機房做雙活。
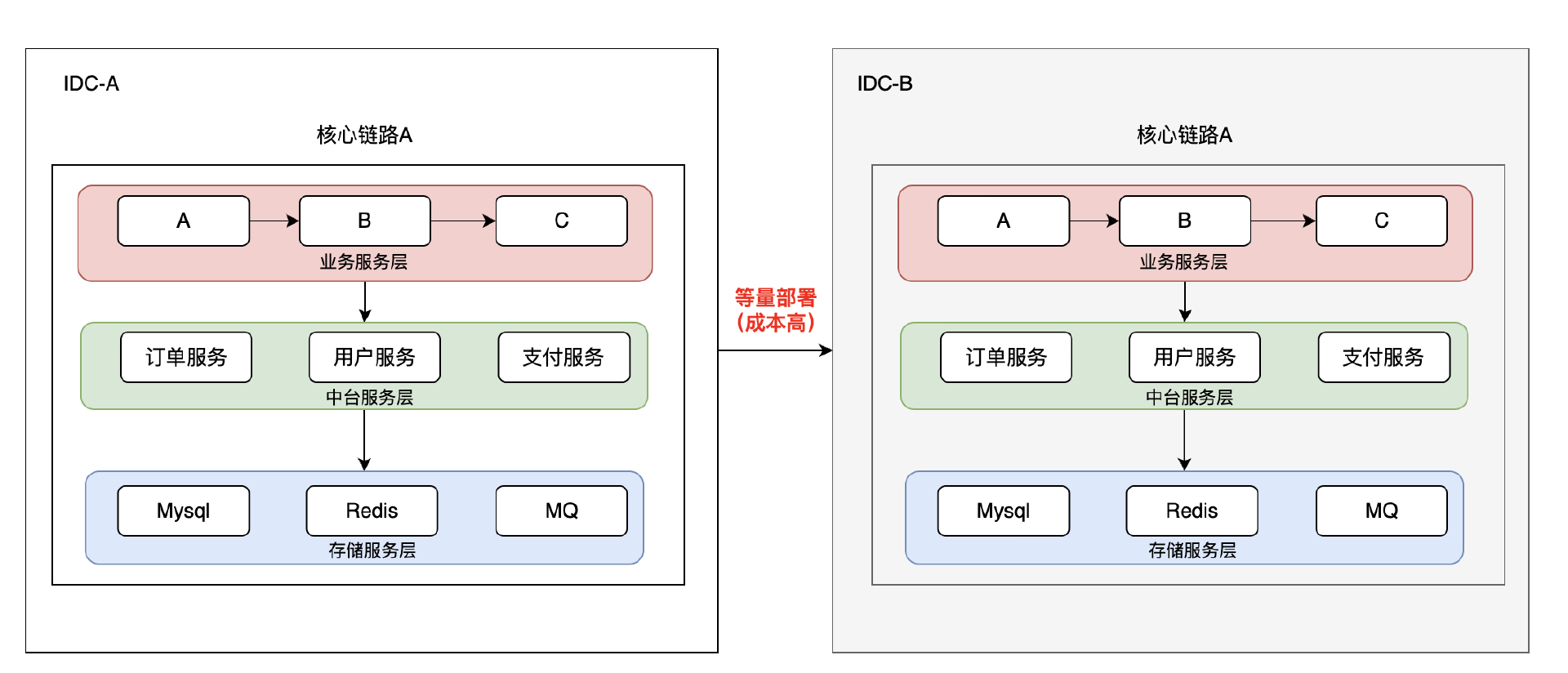
3.5 找到核心鏈路的最小集(強依賴)
如何識別核心鏈路中的強弱依賴?最簡單的就是研發/運維人員手動篩選,但是隨著系統變得複雜以及系統頻繁的變更,弱依賴服務也有可能變成強依賴服務,人工篩選成本太高而且準確性也難以得到保證。
如果你瞭解過混沌工程,也許會知道可以通過混沌工程主動模擬服務/介面故障,從而來梳理核心鏈路中服務的強弱依賴關係。梳理強弱依賴的好處 除了在雙活加固場景下找到需要雙活的最小鏈路集合,還可以針對強弱依賴做很多穩定性建設的事情,例如針對強依賴服務要建設限流能力,針對弱依賴服務要建設降級能力等等。這裡涉及到的細節特別多,包括流量的來源,混沌工程平臺的註入能力,核心鏈路的數據,可觀測的能力,穩態的定義等等,在本文就不展開講了,後面會單獨寫一篇文章介紹。

3.6 小結
在同城雙活中,不是所有業務都需要雙活,而是根據業務的關鍵性和可用性需求有選擇地進行部署。核心鏈路的確定和梳理是雙活實施的核心,找到核心鏈路中強依賴服務進行雙活部署是成本最小,最理想化的雙活部署範圍。
4. 同城雙活的其他關鍵因素
管控服務高可用
各種運維組件的管控層可用性往往會遭到忽視,但管控平臺的高可用特別特別重要的。有很多真實發生的故障往往是因為管控層高可用能力建設不到位,導致出現故障後不能快速恢復。這裡的細節特別多,舉幾個例子:
-
假設是自動化切流,切流的平臺在機房A單活或著對機房A的其他管控/存儲有強依賴,那麼當機房A故障時也無法完成切流動作,即使業務層和存儲層的雙活做的再好也沒有任何用。
-
假設故障時順利切流(無論是自動/手動),當機房B承接了全部流量後,那監控、預案,限流,擴容等平臺也不能在機房A單活或者對機房A的其他管控/存儲有強依賴,因為當全部流量都切到機房B時,很有可能出現容量不足的情況,那麼此時需要擴容/限流/降級等操作,如果這些操作依賴的管控平臺不好用,可能會導致機房B也出現問題。
由於管控平臺大多數是由不同的團隊進行研發,每一個管控平臺的架構可能都不同,管控平臺保證高可用的方案也都不一樣,不過通常有兩種:雙活或冷備,最終的目標只需要保證在故障時管控平臺在另一個機房可用即可。建設的思路一般都是梳理強弱依賴,對強依賴改造為弱依賴,若改造不了,則需要對強依賴服務在單機房內完成閉環調用,不能跨機房調用。
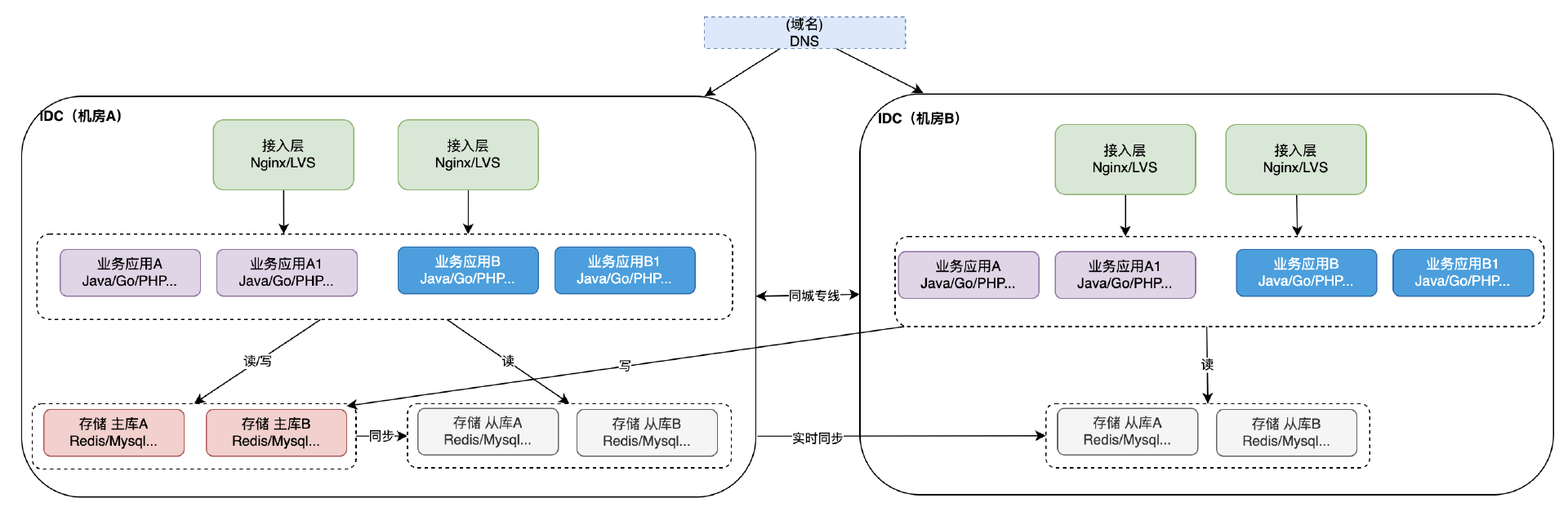
存儲服務高可用
在同城雙活的場景下,兩個機房間通過同城專線進行數據傳輸,延時相對較低。在這個背景下不同的存儲服務有不同的方案,這裡面挑兩個最常見的組件簡單介紹下,例如:
-
mysql
通常是主從模式部署,機房A部署主庫,機房B部署從庫,兩個機房間存儲會進行數據同步。這種場景下機房B的業務服務需要做改造將寫請求路由到機房1的主庫,將讀請求路由到本機房的從庫。(改造的方案可以利用中間件進行讀寫分離,例如shardingsphere,一般大廠也都有自研的存儲代理組件負責讀寫分離)
-
redis
業界通常的做法有主從架構、雙寫架構、雙向同步架構
-
主從架構:和mysql主從模式相同,機房A部署主庫,機房B部署從庫,使用原生主從複製保證數據一致性(類似於codis的設計思路)
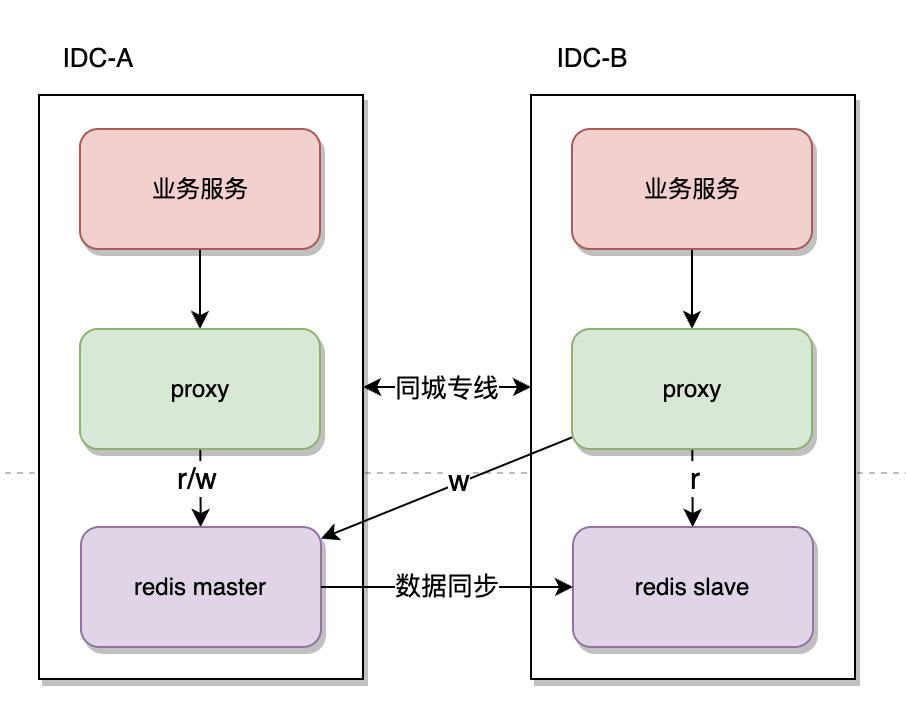
-
雙寫架構:雙機房都部署redis主庫和從庫,業務流量在單機房完成讀寫請求閉環,由proxy完成對端機房非同步寫,不過這種方案有可能由於網路問題導致雙機房redis數據不一致
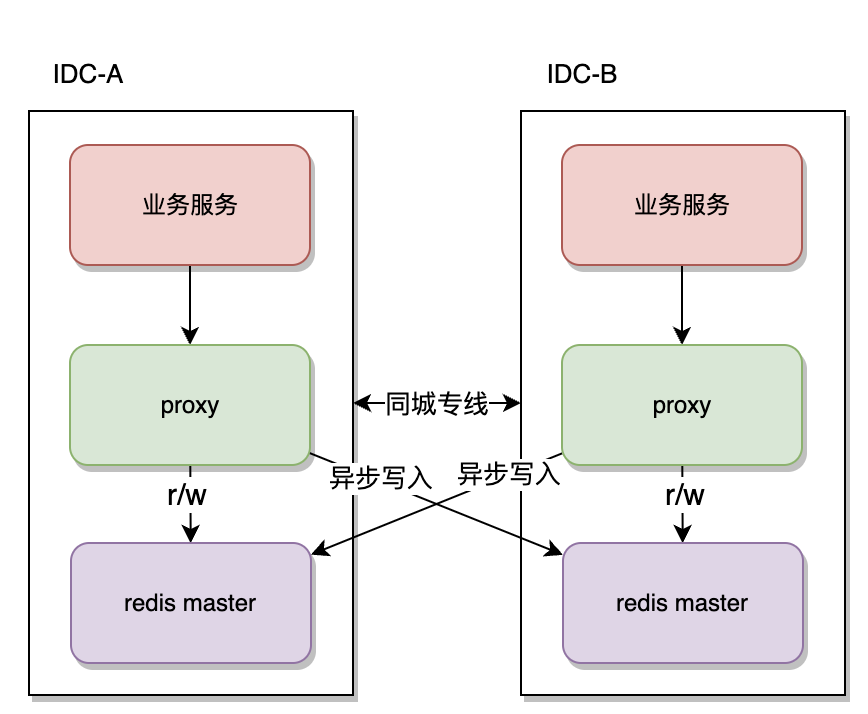
-
雙向同步架構:雙機房都部署redis主庫和從庫,業務流量單機房完成讀寫請求閉環,proxy不需要進行非同步寫入對端機房,在redis server層進行雙機房互相同步來保證數據一致性,需要解決數據衝突,要單獨開發、成本較高(雙向同步架構可以做為異地多活的基礎能力)

5. 如何驗證同城雙活是否可用
當整體的同城雙活工作都完成後,需要驗證甚至是定期驗證同城雙活的能力是否可用,避免真出故障時才發現工作做的不夠完善,也有可能因為架構的不斷演進導致同城雙活能力退化。那這裡還是可以藉助混沌工程思想,通過故障註入來對同城雙活的能力進行演練驗收。當模擬了單機房故障後,可以演練管控平臺是否能正常進行切流,擴容,限流,降級等一系列操作,觀察業務核心指標是否可以在雙活機房迅速恢復,從而判斷同城雙活是否符合預期。
演練驗證通常有兩種做法:
-
斷專線:如果同城雙活能力做的足夠好,足夠有信心,可以選擇直接針對兩個機房間的專線進行網路熔斷(例如交換機上down埠),這種方式簡單、粗暴、有效、可以較好的模擬單個機房故障。

-
精細化故障註入:通常在一個機房內部署的服務不僅僅只有做了雙活的業務,如果還有一些業務服務沒有做雙活,那麼上面直接斷專線演練肯定會影響這種單活的業務服務,所以需要按需去做精細化演練,例如對所有已經完成雙活的業務服務註入網路故障,讓其失聯(無法訪問其他服務/機房,也無法被其他服務訪問,來模擬雙活業務發生機房故障)
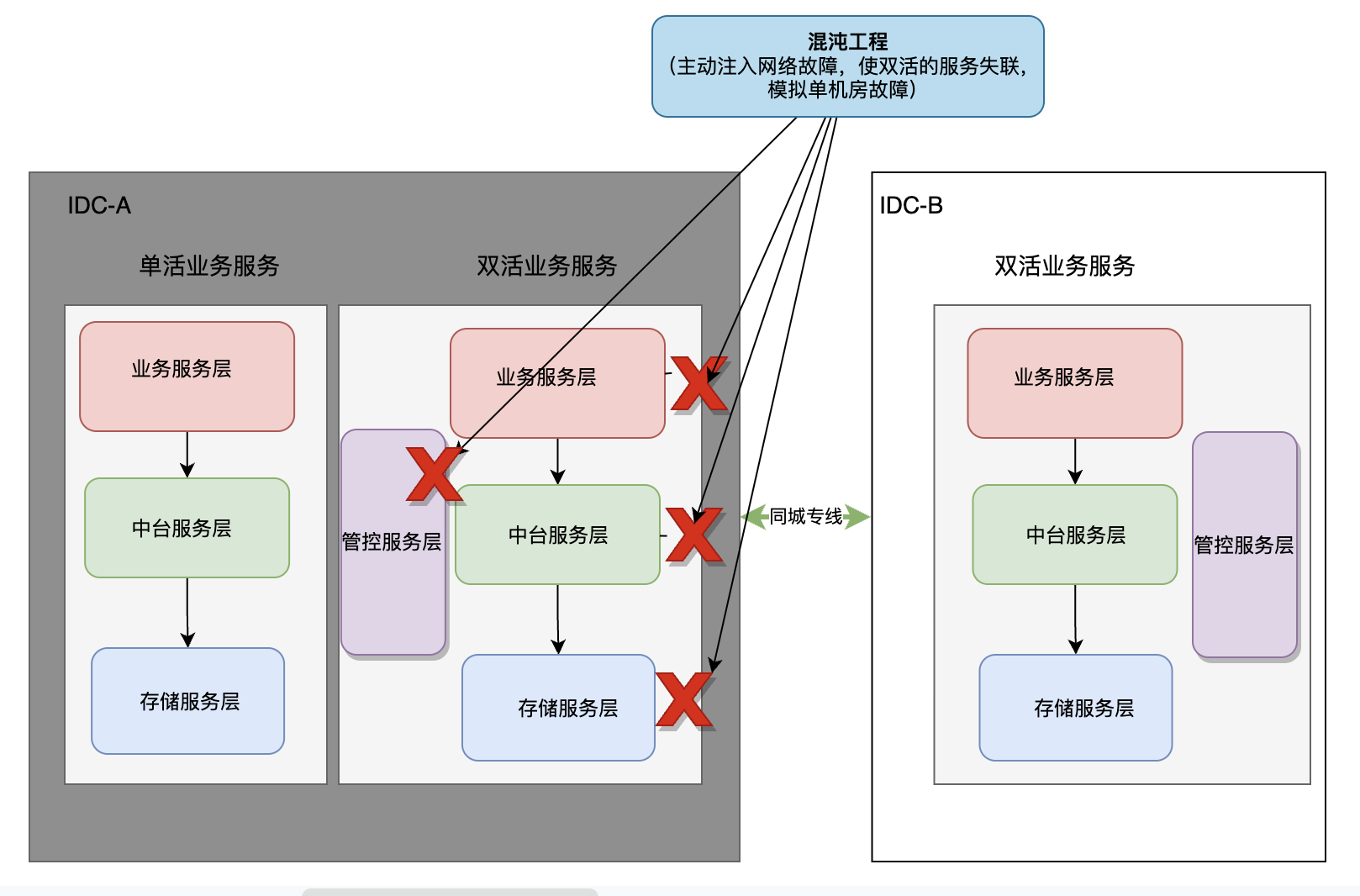
需要考慮如果用生產流量演練,可能會造成一定的損失,這裡要看接入層的分流能力,接入層可以提前將大部分流量切換到單個機房,然後留一小部分流量在低峰期進行演練驗證,降低損失。壓測流量的話需要考慮壓測流量的覆蓋度以及模擬度,如果不夠全面和真實那麼對演練和驗收的效果也都會打折扣。
6. 總結
同城雙活作為一種容災架構,通過在同一城市建立兩個數據中心,以確保在一個數據中心發生故障時,系統能夠快速切換到另一個數據中心,從而提高系統的可用性。在部署需要雙活的服務時,首先要仔細評估業務的關鍵性和可用性需求,梳理業務的核心鏈路是雙活的關鍵抓手,通過將核心鏈路中的強依賴服務作為重點部署對象,實現最小集的同城雙活部署,降低雙活成本。除了業務服務雙活以外,管控和存儲的高可用能力也是故障切換時的關鍵因素。
為了驗證同城雙活的可用性,可以利用混沌工程模擬單一數據中心的故障,進行演練關鍵操作,如切流、擴容、限流等,以確保系統能夠在故障發生時迅速而可靠地恢復。這種方法有助於發現潛在的問題並提前制定有效的故障應對方案,確保業務連續性和穩定性。
作者介紹
張斌斌(Github 賬號:binbin0325,公眾號:檸檬汁 Code)Sentinel-Golang Committer 、ChaosBlade Committer 、 Nacos PMC 、Apache Dubbo-Go Committer。目前主要關註於混沌工程、中間件以及雲原生方向。



