
大數據框架下,常用的數據更新策略有三種: COW: copy-on-write, 寫時複製; MOR: merge-on-read, 讀時合併; MOW: merge-on-write, 寫時合併; hudi等數據湖倉框架,常用的是前兩種實現數據更新。而Doris則主要用後兩種更新數據。 COW 在 ...
大數據框架下,常用的數據更新策略有三種:
COW: copy-on-write, 寫時複製;
MOR: merge-on-read, 讀時合併;
MOW: merge-on-write, 寫時合併;
hudi等數據湖倉框架,常用的是前兩種實現數據更新。而Doris則主要用後兩種更新數據。
COW
在數據寫入的時候,複製一份原來的拷貝,在其基礎上添加新數據,創建數據文件的新版本。新版本文件包括舊版本文件的記錄以及來自傳入批次的記錄(全量最新)。
正在讀數據的請求,讀取的是最近的完整副本,這類似Mysql 的MVCC的思想。
在java的類庫中就有一個CopyOnWriteArrayList,而linux的fork子進程的內部機制也是通過COW實現。可以說,COW是比較常用的數據更新方案。
MOR
新插入的數據存儲在delta log 中,定期再將delta log合併進行parquet數據文件。讀取數據時,會將delta log跟老的數據文件做merge。
這個merge的過程一般是多路歸併排序的實現:查詢時將重覆的 Key 排在一起,併進行聚合操作,其中高版本 Key 的會覆蓋低版本的 Key,最終只返回給用戶版本最高的那一條記錄。
hudi中,數據表的存儲類型主要是MOR,參考: Hudi-表的存儲類型及比較
MOW
將被覆蓋和被更新的數據進行標記刪除,同時將新的數據寫入新的文件。在查詢的時候, 所有被標記刪除的數據都會在文件級別被過濾掉,讀取出來的數據就都是最新的數據,消除掉了讀時合併中的數據聚合過程,並且能夠在很多情況下支持多種謂詞的下推。
別的大數據框架我沒有查到相關的信息,這個的應用主要是在Doris的Unique數據模型中,即通過MOW實現了Unique數據模型下的數據更新。
Doris的MOW的實現方案是: Delete + Insert。即在數據寫入時通過一個主鍵索引查找到被覆蓋的 Key,將其標記為刪除。 參考自微軟的 SQL Server 在 2015 年 VLDB 上發表的論文《Real-Time Analytical Processing with SQL Server》中提出的方案。
Delete + Insert
這篇論文提出了數據寫入時將舊的數據標記刪除(使用一個 Delete Bitmap 的數據結構),並將新數據記錄在 Delta Store 中,查詢時將 Base 數據、Delete Bitmap、Delta Store 中的數據 Merge 起來以得到最新的數據。整體方案如下圖所示
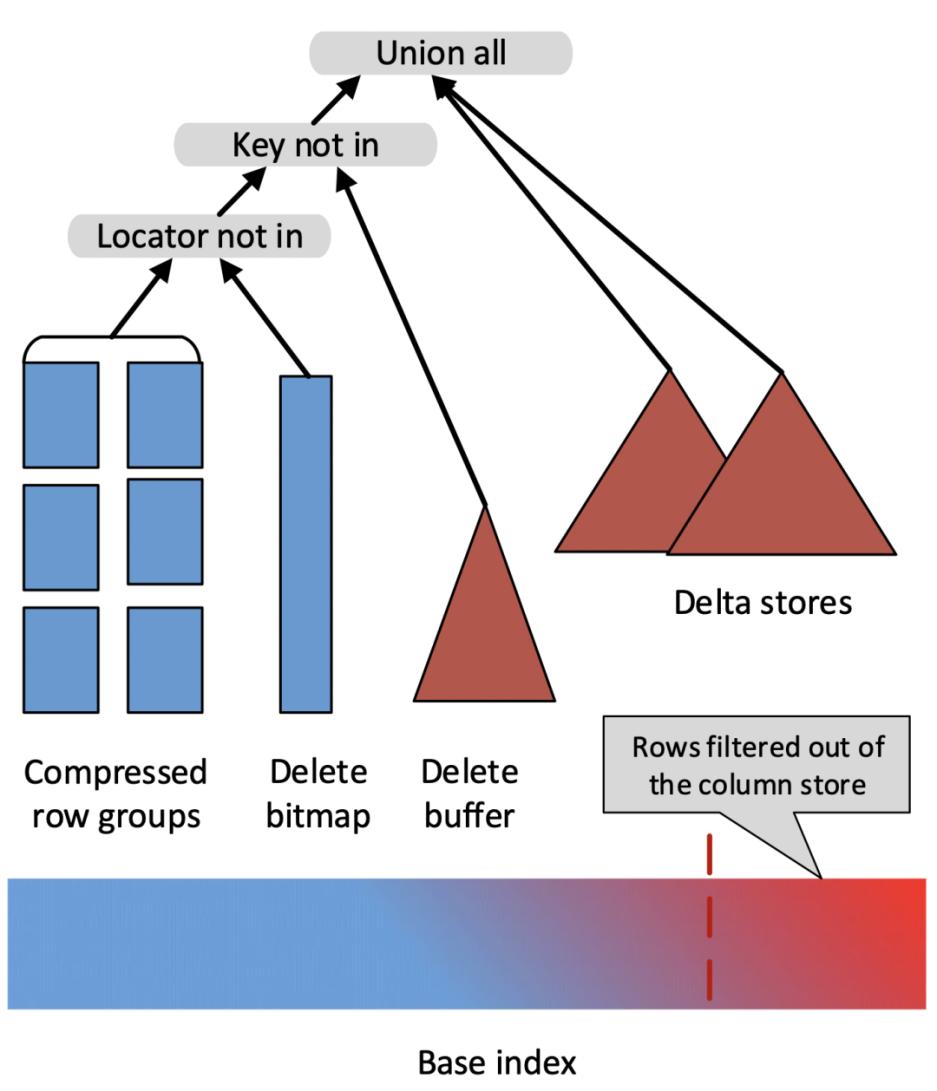
其優點是,任何一個有效的主鍵只存在於一個地方(要麼在 Base Data 中,要麼在 Delta Store 中),這樣就避免了查詢過程中的大量歸併排序的消耗,同時 Base 數據中的各種豐富的列存索引也仍然有效。
簡單來講,Merge-On-Write 的處理流程是:
- 對於每一條 Key,查找它在 Base 數據中的位置(rowsetid + segmentid + 行號)
- 如果 Key 存在,則將該行數據標記刪除。標記刪除的信息記錄在 Delete Bitmap中,其中每個 Segment 都有一個對應的 Delete Bitmap
- 將更新的數據寫入新的 Rowset 中,完成事務,讓新數據可見(能夠被查詢到)
- 查詢時,讀取 Delete Bitmap,將被標記刪除的行過濾掉,只返回有效的數據
總結
之所以會有這篇文章,主要是想總結一下大數據框架下常用的(準實時/實時)數據更新的常用解決方案,畢竟解決方案是通用的,只是實現方式會有差異。
關於更詳細的內容與實現,請參考:
10x 查詢性能提升,全新 Unique Key 的設計與實現


