
SQL(結構化查詢語言)的演變從IBM的SystemR開始,經過ANSI的標準化,近年來SQL標準變得更加豐富和複雜。SQL的特點包括綜合統一、高度非過程化、面向集合的操作方式以及提供多種使用方式的統一語法結構。在資料庫實例中,基本表獨立存在,而視圖是基本表導出的虛表,用於供人查看。資料庫模式結構包... ...
3.1 SQL概述
3.1.1 產生與發展
最早在IBM的關係資料庫管理系統原型SystemR上實現,後來美國國家標準局(ANSI)批准SQL作為關係資料庫語言的美國標準,同年公佈了SQL標準文本。近些年來SQL標準的內容越來越豐富和複雜。目前沒有任何一個資料庫系統能夠支持SQL標準的所有概念和特性,同時不少軟體廠商對SQL基本命令集合進行了不同程度的修改和擴充,又可以支持標準外的一些功能特性。
3.1.2 SQL的特點
SQL的主要特點包括以下幾部分:
1.綜合統一
資料庫系統的主要功能是通過資料庫支持的數據語言來實現的。
非關係模型的數據語言一般分為:
- 模式數據定義語言(模式DDL)
- 外模式數據定義語言(外模式DDL)
- 數據存儲有關的描述語言(DSDL)
- 數據操縱語言(DML)
曾經的用戶資料庫投入運行後,如果需要修改模式,必須停止現有資料庫的運行,修改模式並且編譯後再重裝資料庫,十分麻煩。而SQL可以獨立完成資料庫生命周期中的全部活動。因此用戶在資料庫系統投入使用後還可以根據需要隨時的逐步的修改模式,並不影響資料庫運行,從而使得系統具有良好的可擴展性。
2.高度非過程化
非關係資料庫模型的數據操縱語言是面向過程的語言。而使用SQL的時候,只需要提出“做什麼”而無需知名怎麼做,因此無需瞭解存取路徑。這個工作由系統自動完成。
3.面向集合的操作方式
SQL採用幾何操作方式,對於CRUD的操作以及操作對象、查找結果等操作都可以對元組集合進行操作。
4.以統一語法結構提供多種使用方式
SQL既是獨立的語言,也是嵌入式語言。SQL可以嵌入到高級語言的程式中,而且無論是獨立使用還是嵌入使用,其語法結構是基本一致的嗎,因此統一了在不同語境下的語法使用。
3.1.3 SQL的基本概念

用戶可以使用SQL對基本表和視圖進行基本操作,他們都是關係集合。
基本表是本身獨立存在的表,在關係資料庫管理系統中一個關係對應一個基本表。一個或者多個基本表對應一個存儲文件,一個表可以帶若幹索引,索引也可以存放在存儲文件中。視圖是一個或者幾個基本表導出的表,他不獨立存儲在資料庫中,也就是視圖是一個虛表,其中的信息是一個或者幾個基本表的映射,通常用於供人查看。存儲文件是數據的物理形式,存儲文件的邏輯結構組成了關係資料庫的內模式,其物理結構對最終用戶是隱蔽的。
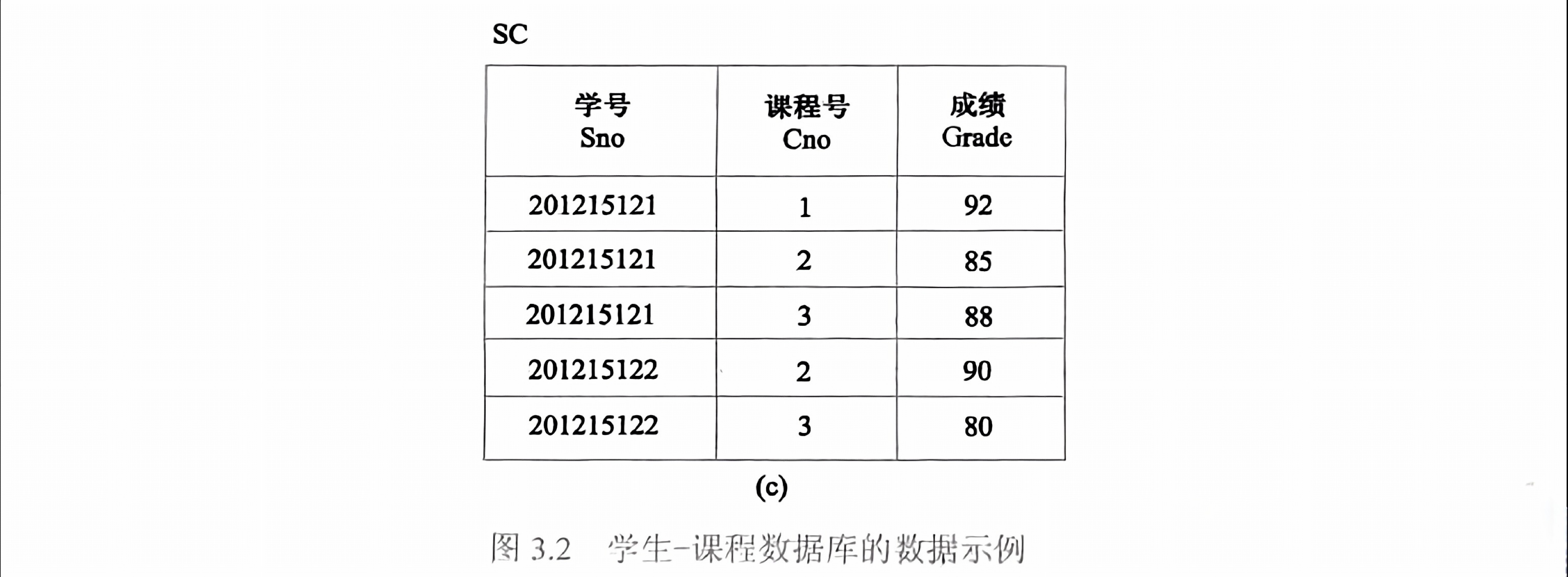
3.2 資料庫實例
圍繞如下資料庫定義:


3.3 數據定義
關係資料庫系統支持三級模式結構,其模式、外模式和內模式中的基本對象有模式、表、視圖和索引等。

一個關係資料庫管理系統的實例中可以建立多個資料庫,一個資料庫中可以建立多個模式,一個模式下包含多個表、視圖和索引等資料庫對象。下文中的語句<>括弧中的為輸入內容,[]括弧內的是可選內容
3.3.1 模式的定義和刪除
模式定義語句如下:
CREATE SCHEMA <SCHEMA NAME> AUTHORIZATION <USER NAME> [<TABLE DEFINE>|<VIEW DEFINE>]
創建模式需要擁有資料庫管理員許可權,或者獲得了資料庫管理員授予的CREATE SCHEMA許可權。在創建模式的時候也可以執行創建基本表、視圖等語句。定義模式實際上定義了一個命名空間,在這個空間中可以進一步定義該模式包含的資料庫對象,比如基本表、視圖、索引等。從語句可以看出,定義模式的同時需要將該模式的管理許可權授權給某用戶。
刪除模式語句如下:
DROP SCHEMA <SCHEMA NAME\88888>
<CASCADE|RESTRICT>
其中CASCADE和RESTRICT兩者必選其一,CASCADE(級聯)表示刪除該模式的同時將模式中所有資料庫對象都刪除,RESTRICT(限制)指的是如果模式中定義了下屬的資料庫對象,則拒絕執行刪除語句,除非該模式沒有下屬的對象。
3.3.1 模式的定義和刪除
模式定義語句如下:
CREATE SCHEMA <SCHEMA NAME> AUTHORIZATION <USER NAME> [<TABLE DEFINE>|<VIEW DEFINE>]
創建模式需要擁有資料庫管理員許可權,或者獲得了資料庫管理員授予的CREATE SCHEMA許可權。在創建模式的時候也可以執行創建基本表、視圖等語句。定義模式實際上定義了一個命名空間,在這個空間中可以進一步定義該模式包含的資料庫對象,比如基本表、視圖、索引等。從語句可以看出,定義模式的同時需要將該模式的管理許可權授權給某用戶。
刪除模式語句如下:
DROP SCHEMA <SCHEMA NAME\88888>
<CASCADE|RESTRICT>
其中CASCADE和RESTRICT兩者必選其一,CASCADE(級聯)表示刪除該模式的同時將模式中所有資料庫對象都刪除,RESTRICT(限制)指的是如果模式中定義了下屬的資料庫對象,則拒絕執行刪除語句,除非該模式沒有下屬的對象。
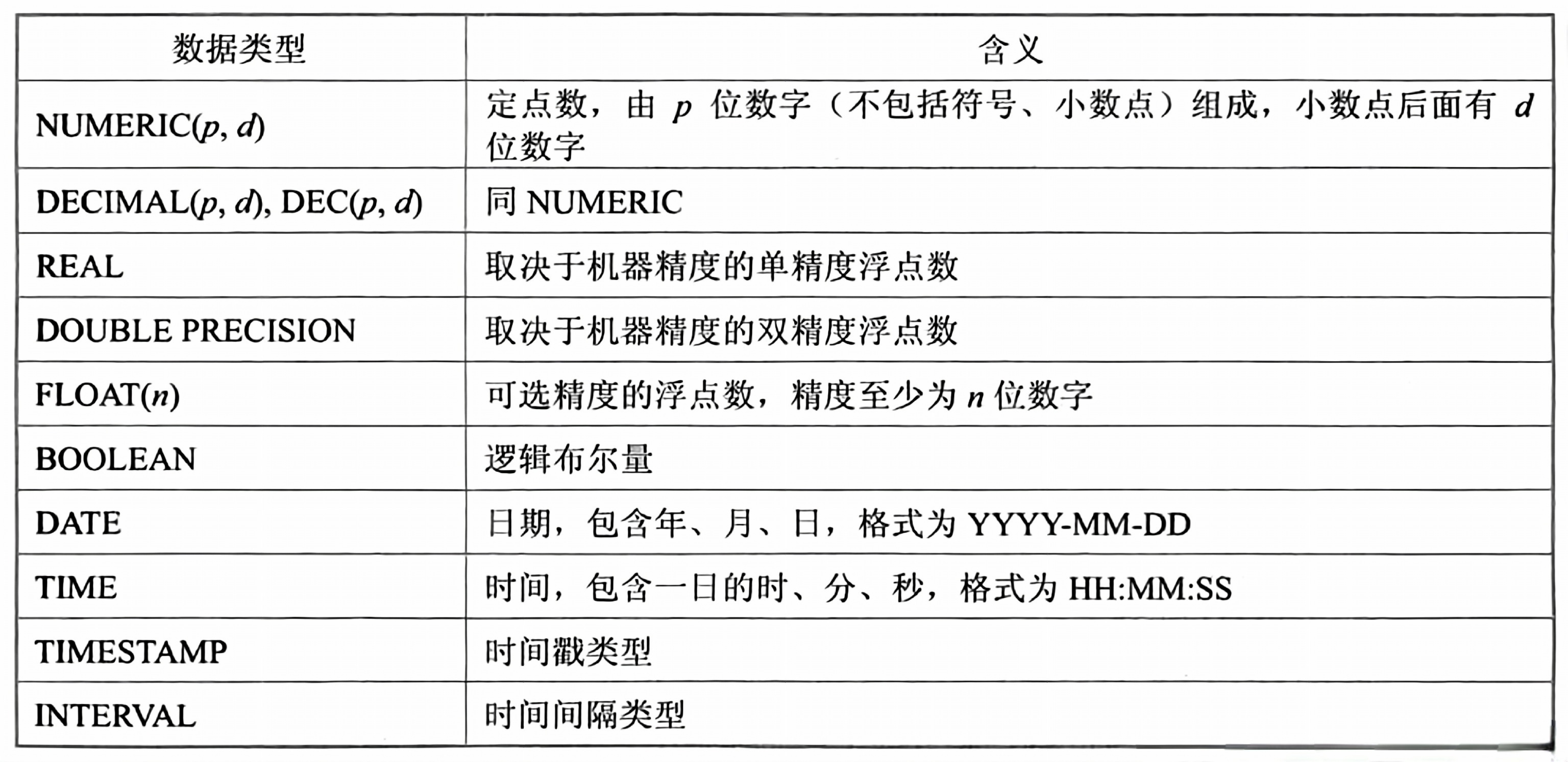
3.3.2 基本表的定義、刪除和修改
1. 常見數據類型

2.定義基本表
定義基本表的格式如下:
CREATE TABLE <TABLE NAME> (
<列名><數據類型>[列完整性約束條件],
[<列名><數據類型>[列完整性約束條件],…]
[表完整性約束條件]
)
其中主要的列完整性約束條件有:
- PRIMARY KEY 主鍵
- FOREIGN KEY (外碼名) REFERENCES 被參照表(被參照列) 外鍵
- NOT NULL 非空
- UNIQUE 唯一值
3.修改基本表
ALTER TABLE <TABLE NAME>
[ADD [COLUME] <新列名><數據類型>[完整性約束]] -- 新增表項
[ADD <表級完整性約束>] -- 增加表約束
[DROP [COLUME] <列名> [CASCADE|RESTRICT]] -- 刪除表項
[DROP CONSTRAINT <完整性約束名> [RESTRICT|CASCADE]] -- 刪除表約束
[ALTER COLUME <列名><數據類型>] -- 修改列數據類型
其中ADD用於新增內容,DROP用於刪除內容。DROP COLUMN用於刪除列,如果指定了CASCADE則會在刪除列之前先刪除引用該列的其他對象,比如視圖;如果指定了RESTRICT,則如果對象被引用,則RDBMS會拒絕刪除該列。DROP CONSTRAINT 用於刪除指定的完整性約束條件。ALTER COLUMN子句用於修改原有列的定義。
4.刪除基本表
DROP TABLE <表名> [RESTRICT|CASCADE]
如果是RESTRICT,則刪除是有約束條件的,基本表不能被其他表的約束所引用(比如外鍵),不能有視圖,也不能有觸發器,不能有存儲過程或者函數。如果有則刪除失敗。如果選擇CASCADE,則該表刪除沒有限制條件,刪除基本表的同時相關的依賴一併刪除。
5.模式和表
一個模式包含了多個基本表,每一個基本表都屬於一個模式,當定義一個基本表的時候有三種方法定義它所屬的模式:
方法一:在表名中明顯給出模式名
CREATE TABLE “S-T”.Student(…) -- Student的模式是S-T
方法二:在創建模式語句中同時創建表
方法三,設置所屬模式,在創建表時不需要給出模式名
使用語句
SHOW search_path
可以顯示當前的搜索路徑
6.索引的建立和刪除
當表的數據量比較大的時候,查詢操作會比較耗時,因此建立索引可以加快查詢速度。資料庫索引類似於圖書的目錄,能夠快速定位到需要查詢的內容。資料庫索引會有多種類型,包括順序文件上的索引、B+樹索引、散列索引等等。索引雖然會加速查詢速度,但是需要占用一定記憶體空間,當基本表更新的時候,索引也要做出變更,因此需要一些維護開銷。一般來說,建立和刪除索引由索資料庫管理員或者表的屬主(owner)負責完成。關係資料庫管理系統在執行查詢時會自動選擇合適的索引,用戶不能顯式選擇索引。索引是關係資料庫內部實現技術,屬於內模式範疇。
常見索引形式
- 順序文件索引是針對按照指定屬性值升序或者降序的存儲關係。
- B+樹索引是將索引屬性組織成B+樹的形式,B+樹的葉節點為屬性值和相應的元組指針。B+樹具有動態平衡的優點
- 散列索引是建立若幹個同,將索引屬性按照其散列函數映射到相應的桶中
- 點陣圖索引是用位向量記錄索引屬性中可能出現的值,每一個位向量對應一個可能值。
建立索引
在SQL語句中,建立索引語句如下:
CREATE [UNIQUE] [CLUSTER] INDEX 索引名
ON <表名>(<列名>[<次序>] [, <列名>[<次序>]])
表名是基本表名字,
索引可與建立在該表的一列或者多列上,各列之間用逗號分隔,次序欄位可選ASC(升序)和DESC(降序)
UNIQUE指該索引每一個索引值對應唯一的數據記錄;CLUSTER指建立聚簇索引,聚簇索引會在後面介紹到
修改和刪除
ALTER INDEX <舊索引名> RENAME TO <新索引名>
DROP INDEX <索引名>


