
這裡給大家分享我在網上總結出來的一些知識,希望對大家有所幫助 一、故事的開始 最近產品又開始整活了,本來是毫無壓力的一周,可以小摸一下魚的,但是突然有一天跟我說要做一個在網頁端截屏的功能。 作為一個工作多年的前端,早已學會了儘可能避開麻煩的需求,只做增刪改查就行! 我立馬開始了我的反駁,我的理由是市 ...
這裡給大家分享我在網上總結出來的一些知識,希望對大家有所幫助

一、故事的開始
最近產品又開始整活了,本來是毫無壓力的一周,可以小摸一下魚的,但是突然有一天跟我說要做一個在網頁端截屏的功能。
作為一個工作多年的前端,早已學會了儘可能避開麻煩的需求,只做增刪改查就行!
我立馬開始了我的反駁,我的理由是市面上截屏的工具有很多的,微信截圖、Snipaste都可以做到的,自己實現的話,一是比較麻煩,而是性能也不會很好,沒有必要,把更多的時間放在核心業務更合理!
結果產品跟我說因為公司內部有個可以用來解析圖片,生成文本OCR的演算法模型,web端需要支持截取網頁中部分然後交給模型去訓練,微信以及其他的截圖工具雖然可以截圖,但需要先保存到本地,再上傳給模型才行。
網頁端支持截圖後可以在在截屏的同時直接上傳給模型,減少中間過程,提升業務效率。
我一聽這產品小嘴巴巴的說的還挺有道理,沒有辦法,只能接了這個需求,從此命運的齒輪開始轉動,開始了我漫長而又曲折的思考。
二、我的思考
在實現任何需求的時候,我都會在自己的腦子中大概思考一下,評估一下它的難度如何。我發現web端常見的需求是在一張圖片上截圖,這個還是比較容易的,只需要準備一個canvas,然後利用canvas的方法 drawImage就可以截取這個圖片的某個部分了。
示例如下:
<!DOCTYPE html>
<html>
<head>
<title>截取圖片部分示例</title>
</head>
<body>
<canvas id="myCanvas" width="400" height="400"></canvas>
<br>
<button onclick="cropImage()">截取圖片部分</button>
<br>
<img id="croppedImage" alt="截取的圖片部分">
<br>
<script>
function cropImage() {
var canvas = document.getElementById('myCanvas');
var ctx = canvas.getContext('2d');
var image = new Image();
image.onload = function () {
// 在canvas上繪製整張圖片
ctx.drawImage(image, 0, 0, canvas.width, canvas.height);
// 截取圖片的一部分,這裡示例截取左上角的100x100像素區域
var startX = 0;
var startY = 0;
var width = 100;
var height = 100;
var croppedData = ctx.getImageData(startX, startY, width, height);
// 創建一個新的canvas用於顯示截取的部分
var croppedCanvas = document.createElement('canvas');
croppedCanvas.width = width;
croppedCanvas.height = height;
var croppedCtx = croppedCanvas.getContext('2d');
croppedCtx.putImageData(croppedData, 0, 0);
// 將截取的部分顯示在頁面上
var croppedImage = document.getElementById('croppedImage');
croppedImage.src = croppedCanvas.toDataURL();
};
// 設置要載入的圖片
image.src = 'your_image.jpg'; // 替換成你要截取的圖片的路徑
}
</script>
</body>
</html>
一、獲取像素的思路
但是目前的這個需求遠不止這樣簡單,因為它的對象是整個document,需要在整個document上截取一部分,我思考了一下,其實假設如果瀏覽器為我們提供了一個api,能夠獲取到某個位置的像素信息就好了,這樣我將選定的某個區域的每個像素信息獲取到,然後在一個像素一個像素繪製到canvas上就好了。
我本以為我發現了一個很好的方法,可遺憾的是經過調研瀏覽器並沒有為我們提供類似獲取某個位置像素信息的API。
唯一為我們提供獲取像素信息的是canvas的這個API。
<!DOCTYPE html>
<html>
<head>
<title>獲取特定像素信息示例</title>
</head>
<body>
<canvas id="myCanvas" width="400" height="400"></canvas>
<br>
<button onclick="getPixelInfo()">獲取特定像素信息</button>
<br>
<div id="pixelInfo"></div>
<script>
function getPixelInfo() {
var canvas = document.getElementById('myCanvas');
var ctx = canvas.getContext('2d');
// 繪製一些內容到canvas
ctx.fillStyle = 'red';
ctx.fillRect(50, 50, 100, 100);
// 獲取特定位置的像素信息
var x = 75; // 替換為你想要獲取的像素的x坐標
var y = 75; // 替換為你想要獲取的像素的y坐標
var pixelData = ctx.getImageData(x, y, 1, 1).data;
// 提取像素的顏色信息
var red = pixelData[0];
var green = pixelData[1];
var blue = pixelData[2];
var alpha = pixelData[3];
// 將信息顯示在頁面上
var pixelInfo = document.getElementById('pixelInfo');
pixelInfo.innerHTML = '在位置 (' + x + ', ' + y + ') 的像素信息:<br>';
pixelInfo.innerHTML += '紅色 (R): ' + red + '<br>';
pixelInfo.innerHTML += '綠色 (G): ' + green + '<br>';
pixelInfo.innerHTML += '藍色 (B): ' + blue + '<br>';
pixelInfo.innerHTML += 'Alpha (透明度): ' + alpha + '<br>';
}
</script>
</body>
</html>
瀏覽器之所以沒有為我們提供相應的API獲取像素信息,停下來想想也是有道理的,甚至是必要的,因為假設瀏覽器為我們提供了這個API,那麼惡意程式就可以通過這個API,不斷的獲取你的瀏覽器頁面像素信息,然後全部繪製出來。一旦你的瀏覽器運行這個段惡意程式,那麼你在瀏覽器乾的什麼,它會一覽無餘,相當於在網路的世界里裸奔,毫無隱私可言。
二、把DOM圖片化
既然不能走捷徑直接拿取像素信息,那就得老老實實的把document轉換為圖片,然後調用canvas的drawImage這個方法來截取圖片了。
在前端領域其實99%的業務場景早已被之前的大佬們都實現過了,相應的輪子也很多。我問了一下chatGPT,它立馬給我推薦了大名鼎鼎的html2canvas,這個庫能夠很好的將任意的dom轉化為canvas。這個是它的官網。
我會心一笑,因為這不就直接能夠實現需求了,很容易就可以寫出下麵的代碼了:
html2canvas(document.body).then(function(canvas) {
// 將 Canvas 轉換為圖片數據URL
var src = canvas.toDataURL("image/png");
var image = new Image();
image.src = src;
image.onload = ()=>{
const canvas = document.createElement("canvas")
const ctx = canvas.getContext("2d");
const width = 100;
const height = 100;
canvas.width = width;
canvas.height = height;
// 截取以(10,10)為頂點,長為100,寬為100的區域
ctx.drawImage(image, 10, 10, width, height , 0 , 0 ,width , height);
}
});
上面這段代碼就可以實現截取document的特定的某個區域,需求已經實現了,但是我看了一下這個html2canvas庫的資源發現並沒有那麼簡單,有兩個點並不滿足我希望實現的點:
1.大小
當我們將html2canvas引入我們的項目的時候,即便壓縮過後,它的資源也有近200kb:
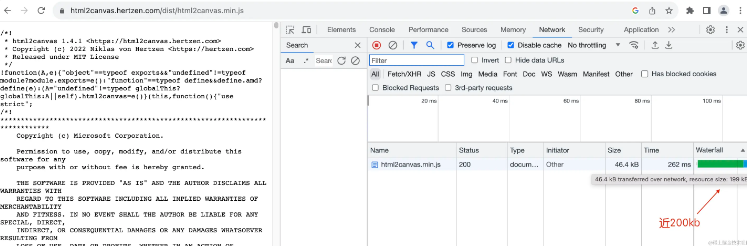
要知道整個react和react-dom的包壓縮過後也才不到150kb,因此在項目只為了一個單一的功能引入一個複雜的資源可能並不划算,引入一個複雜度高的包一個是它會增加構建的時間,另一方面也會增加打包之後的體積。
如果是普通的web工程可能情有可原,但是因為我會將這需求做到插件當中,插件和普通的web不一樣的一點,就是web工程如果更新之後,客戶端是自動更新的。但是插件如果更新了,需要客戶端手動的下載插件包,然後再在瀏覽器安裝,因此包的大小儘可能小才好,如果一個插件好幾十MB的話,那客戶端肯定煩死了。
2.性能
作為業內知名的html2canvas庫,性能方面表現如何呢?
我們可以看看它的原理,一個dom結構是如何變成一個canvas的呢!
它的源碼在這裡:核心的實現是canvas-renderer.ts這個文件。
當html2canvas拿到dom結構之後,首先為了避免副作用給原dom造成了影響,它會克隆一份全新的dom,然後遍歷DOM的每一個節點,將其扁平化,這個過程中會收集每個節點的樣式信息,尤其是在界面上的佈局的幾何信息,存入一個棧中。
然後再遍歷棧中的每一個節點進行繪製,根據之前收集的樣式信息進行繪製,就這樣一點點的繪製到提前準備的和傳入dom同樣大小的canvas當中,由於針對很多特殊的元素,都需要處理它的繪製邏輯,比如iframe、input、img、svg等等。所以整個代碼就比較多,自然大小就比較大了。
整個過程其實需要至少3次對整個dom樹的遍歷才可以繪製出來一個canvas的實例。
這個就是這個繪製類的主要實現方法:

可以看到,它需要考慮的因素確實特別多,類似寫這個瀏覽器的繪製引擎一樣,特別複雜。
要想解決以上的大小的瓶頸。
第一個方案就是可以將這個資源動態載入,但是一旦動態載入就不能夠在離線的環境下使用,在產品層面是不能接受的,因為大家可以想一想如果微信截圖的功能在沒有網路的時候就使用不了,這個肯定不正常,一般具備工具屬性的功能應該儘可能可以做到離線使用,這樣才好。
因此相關的代碼資源不能夠動態載入。
dom-to-image
正當我不知道如何解決的時候,我發現另外了一個庫dom-to-image,我發現它打包後的大小隻有10kb左右,這其實已經一個很可以接受的體積了。這個是它的github主頁。好奇的我想知道它是怎麼做到只有這麼小的體積就能夠實現和html2canvas幾乎同樣的功能的呢?於是我就研究了一下它的實現。
dom-to-image的實現利用了一個非常靈活的特性--image可以渲染svg。
我們可以複習一下img標簽的src可以接受什麼樣的類型:這裡是mdn的說明文檔:
可以接受的格式要求是:
- APNG(動態可移植網路圖形)——無損動畫序列的不錯選擇(GIF 性能較差)。
- AVIF(AV1 圖像文件格式)——靜態圖像或動畫的不錯選擇,其性能較好。
- GIF(圖像互換格式)——簡單圖像和動畫的不錯選擇。
- JPEG(聯合圖像專家組)——有損壓縮靜態圖像的不錯選擇(目前最流行的格式)。
- PNG(攜帶型網路圖形)——對於無損壓縮靜態圖像而言是不錯的選擇(質量略好於 JPEG)。
- SVG(可縮放矢量圖形)——矢量圖像格式。用於必須以不同尺寸準確描繪的圖像。
- WebP(網路圖片格式)——圖像和動畫的絕佳選擇。
如果我們使用svg格式來渲染圖片就可以是這樣的方式:
<!DOCTYPE html>
<html>
<head>
<title>渲染SVG</title>
</head>
<body>
<h1>SVG示例</h1>
<img src="example.svg" alt="SVG示例">
</body>
</html>
但是也可以是這樣的方式:<!DOCTYPE html>
<html>
<head>
<title>渲染SVG字元串</title>
</head>
<body>
<div id="svg-container">
<!-- 這裡是將SVG內容渲染到<img>標簽中 -->
<img id="svg-image" src="data:image/svg+xml, <svg xmlns='http://www.w3.org/2000/svg' width='100' height='100'><circle cx='50' cy='50' r='40' stroke='black' stroke-width='2' fill='red' /></svg>" alt="SVG圖像">
</div>
</body>
</html>
把svg的標簽序列化之後直接放在src屬性上,image也是可以成功解析的,只不過我們需要添加一個頭部:data:image/svg+xml, 。
令人興奮的是,svg並不是只支持svg語法,也支持將其他的xml類型的語法比如html嵌入在其中。antv的x6組件中有非常多這樣的應用例子,我給大家截圖看一下:
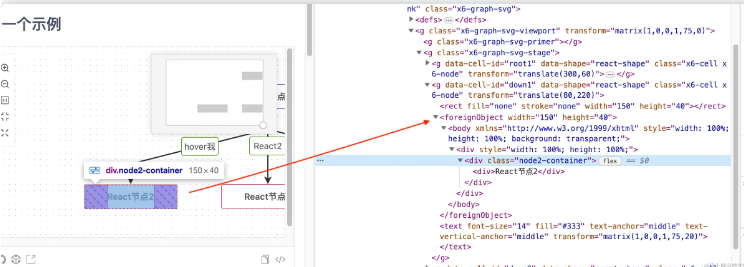
在svg中可以通過foreignObject這個標簽來嵌套一些其他的xml語法,比如html等,有了這一特性,我們就可以把上面的例子改造一下:
<!DOCTYPE html>
<html>
<head>
<title>渲染SVG字元串</title>
</head>
<body>
<div id="svg-container">
<!-- 這裡是將SVG內容渲染到<img>標簽中 -->
<img
id="svg-image"
src="data:image/svg+xml, <svg xmlns='http://www.w3.org/2000/svg' width='100' height='100'><circle cx='50' cy='50' r='40' stroke='black' stroke-width='2' fill='red' /><foreignObject>{ 中間可以放 dom序列化後的結果呀 }</foreignObject></svg>"
alt="SVG圖像"
>
</div>
</body>
</html>
所以我們可以將dom序列化後的結構插到svg中,這不就天然的形成了一種dom->image的效果麽?下麵是演示的效果:<!DOCTYPE html>
<html>
<head>
<title>渲染SVG字元串</title>
</head>
<body>
<div id="render" style="width: 100px; height: 100px; background: red"></div>
<br />
<div id="svg-container">
<!-- 這裡是將SVG內容渲染到<img>標簽中 -->
<img id="svg-image" alt="SVG圖像" />
</div>
<script>
const perfix =
"data:image/svg+xml;charset=utf-8,<svg xmlns='http://www.w3.org/2000/svg' width='100' height='100'><foreignObject x='0' y='0' width='100%' height='100%'>";
const surfix = "</foreignObject></svg>";
const render = document.getElementById("render");
render.setAttribute("xmlns", "http://www.w3.org/1999/xhtml");
const string = new XMLSerializer()
.serializeToString(render)
.replace(/#/g, "%23")
.replace(/\n/g, "%0A");
const image = document.getElementById("svg-image");
const src = perfix + string + surfix;
console.log(src);
image.src = src;
</script>
</body>
</html>

如果你將這個字元串直接通過瀏覽器打開,也是可以的,說明瀏覽器可以直接識別這種形式的媒體資源正確解析對應的資源:
data:image/svg+xml;charset=utf-8,<svg xmlns='http://www.w3.org/2000/svg' width='100' height='100'><foreignObject x='0' y='0' width='100%' height='100%'><div id="render" style="width: 100px; height: 100px; background: red" xmlns="http://www.w3.org/1999/xhtml"></div></foreignObject></svg>
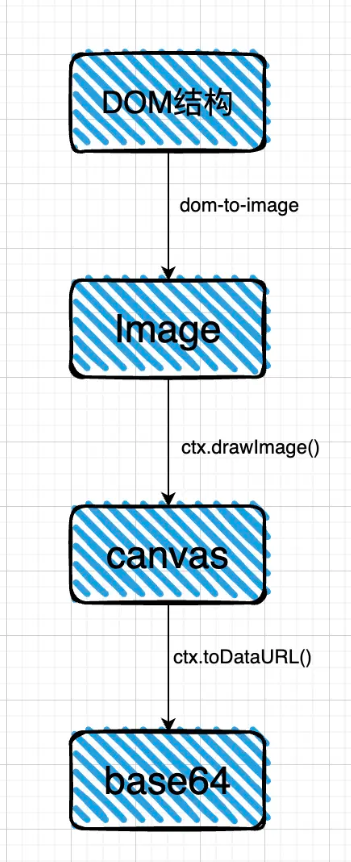
實不相瞞這個就是dom-to-image的核心原理,性能肯定是不錯的,因為它是調用瀏覽器底層的渲染器。
通過這個dom-to-image我們可以很好的解決資源大小和性能這兩個瓶頸的點。
三、優化
這個庫打包後的產物是umd規範的,並且是統一暴露出來的全局變數,因此不支持treeshaking。

但是很多方法比如toJpeg、toBlob、等方法我們其實都用不到,所以打包了很多我們不需要的產物,於是其實我們可以把核心的實現自己寫一遍,使用1-2kb的空間就可以做到這一點。
經過以上的思考我們就可以基本上確定方案了:
基於dom-to-image的原理,實現一個簡易的my-dom-to-image,大約只需要100行代碼左右就可以做到。
然後將document.body轉化為image,再從這個image中截取特定的部分。
好了,以上就是我關於這個需求的一些思考,如果掘友也有一些其他非常有意思的需求,歡迎評論區討論我們一起頭腦風暴啊!!!
利用插件
其實針對截屏,如果只用純web技術,確實有點麻煩,但是如果說我們利用插件去做就非常簡單了,我們只需要藉助一個API就可以獲取一個tab的截屏數據。
chrome.tabs.captureVisibleTab(
windowId,
{ format: 'png' }
, function(dataUrl) {
const img = new Image();
img.src = dataUrl; // 將圖像添加到頁面或進行其他操作
document.body.appendChild(img);
});
所以說如果你有精力,可以和你的產品商量一下能不能把這個需求做到一個插件裡面,你可以開發一個插件去做這件事情。不必擔心不懂插件相關的技術,因為我已經幫你寫了一個插件專欄,點擊這裡查看。裡面有插件開發入門的大部分內容,快來看看吧!
四、維護 -- 這個內容非重點,可以跳過
9.13日更
文章發佈後,針對這個需求有很多掘友提出了新的想法和思路,給思考的掘友們點贊(๑•̀ㅂ•́)و✧,我大概整理一下評論區的方案:
有一位掘友提到了一個庫 rasterizeHTML.js。
從名字來看是想要柵格化HTML,通俗來講把HTML畫出來的意思,我以前還真不知道還有這個庫,學習了,他的核心源碼就是下麵這一段:

說白了,還是一樣,利用svg可以包含html的特點去做的,和dom-to-image的思想差不多。
另外一位掘友提到了一個API:navigator.mediaDevices.getDisplayMedia,我大概試了一下,應該是不滿足需求的,因為這個API的調用必須需要用戶手動賦予許可才可以,你一調用它,就會彈出賦予許可權的提示框,就像下麵這樣:
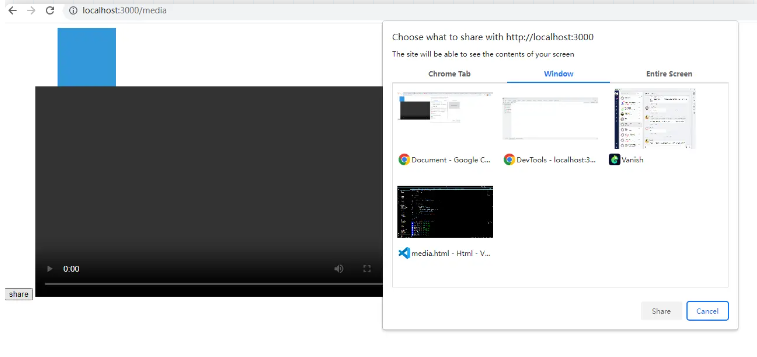
即便用戶同意了,可以得到一個MediaStream被稱為媒體流的對象,但是這個對象內部肯定封裝了屏幕的像素信息,但是壓根沒把這個東西暴露給用戶,反正我找遍了它的幾乎所有屬性,沒看到它把像素信息暴露出來了。它是方便用戶直接在video上使用而設計的。可以用它來做類似屏幕共用的功能。
但是既然已經將像素繪製到了video上實際上就可以將其轉化為canvas,我們可以像下麵這樣的方式去做:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>共用屏幕</title>
<style>
.animated-box {
width: 100px;
height: 100px;
background-color: #3498db;
position: relative;
animation-name: slideIn;
animation-duration: 2s; /* 動畫持續時間 */
animation-timing-function: ease; /* 動畫時間函數 */
animation-fill-mode: forwards; /* 動畫結束後保持最終狀態 */
animation-iteration-count: infinite;
}
/* 定義動畫關鍵幀 */
@keyframes slideIn {
0% {
left: 100px; /* 起始位置 -100px 左側 */
}
50% {
left: 0; /* 結束位置 0 左側 */
}
100% {
left: 100px;
}
}
</style>
</head>
<body>
<div class="animated-box"></div>
<button onclick="share()">share</button>
<video src="" id="video" width="640" height="360" controls></video>
<canvas id="canvasElement" width="640" height="360"></canvas>
<script>
let tracks;
function share() {
try {
navigator.mediaDevices
.getDisplayMedia({ video: true })
.then((mediaStream) => {
const videoElement = document.getElementById("video");
const canvasElement = document.getElementById("canvasElement");
videoElement.srcObject = mediaStream;
const ctx = canvasElement.getContext("2d");
// 在每個AnimationFrame繪製視頻幀
function drawFrame() {
ctx.drawImage(
videoElement,
0,
0,
canvasElement.width,
canvasElement.height
);
const imageData = ctx.getImageData(
0,
0,
canvasElement.width,
canvasElement.height
);
// 在 imageData 中獲取像素信息
// imageData.data 包含了每個像素的RGBA數據
// 您可以處理這些數據以獲取所需的信息
// 例如,獲取特定坐標的像素顏色值:imageData.data[(y * imageData.width + x) * 4]
console.log(imageData);
requestAnimationFrame(drawFrame);
}
// 啟動繪製迴圈
requestAnimationFrame(drawFrame);
});
} catch (e) {
console.log("Unable to acquire screen capture: " + e);
}
}
</script>
</body>
</html>
演示效果:
本文轉載於:
https://juejin.cn/post/7276694924137463842
如果對您有所幫助,歡迎您點個關註,我會定時更新技術文檔,大家一起討論學習,一起進步。



