三、基本數據類型和計算(二) 1、字元 #include <iostream> int main() { std::cout << 65 << std::endl; //65是一個int類型的整數 std::cout << (char)65 << std::endl; //將其轉化為1個位元組的cha ...
三、基本數據類型和計算(二)
1、字元
#include <iostream>
int main()
{
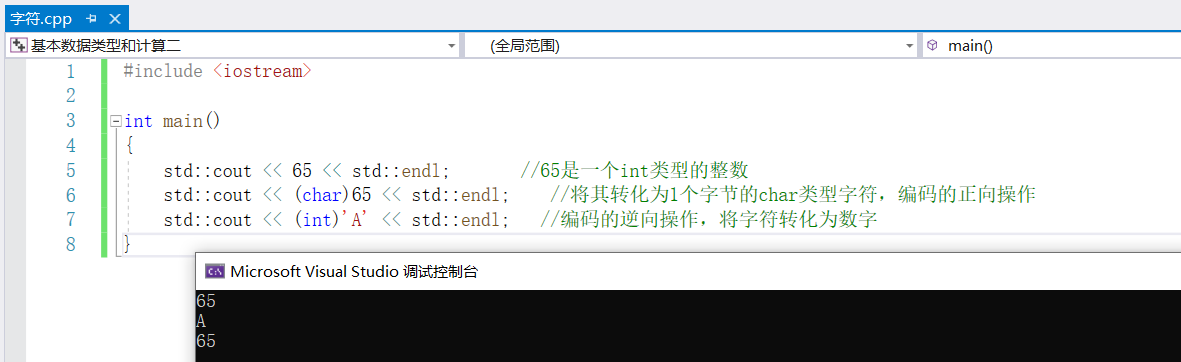
std::cout << 65 << std::endl; //65是一個int類型的整數
std::cout << (char)65 << std::endl; //將其轉化為1個位元組的char類型字元,編碼的正向操作
std::cout << (int)'A' << std::endl; //編碼的逆向操作,將字元轉化為數字
}
1)字元數據原理
| 記憶體數據 | 編碼規範 | 顯示 |
|---|---|---|
| 65 | ASCII | A |
原理:在記憶體中最終存儲的數據都是數字,字元本質上還是數字,顯示什麼樣的形式,取決於編碼規範的實現,上述代碼中編碼規範的實現是由std::cout類決定的。
ANSI
2)字元數據類型
| 類型 | 記憶體占用 | 說明 |
|---|---|---|
| char | 1 | ascii字元 |
| wchar_t | 2/4 | 寬位元組字元,使用L來說明變數 |
| char16_t | 2 | utf_16字元,使用一個u來說明變數 |
| char32_t | 4 | utf_32字元,使用一個U來說明變數 |
①chat類型
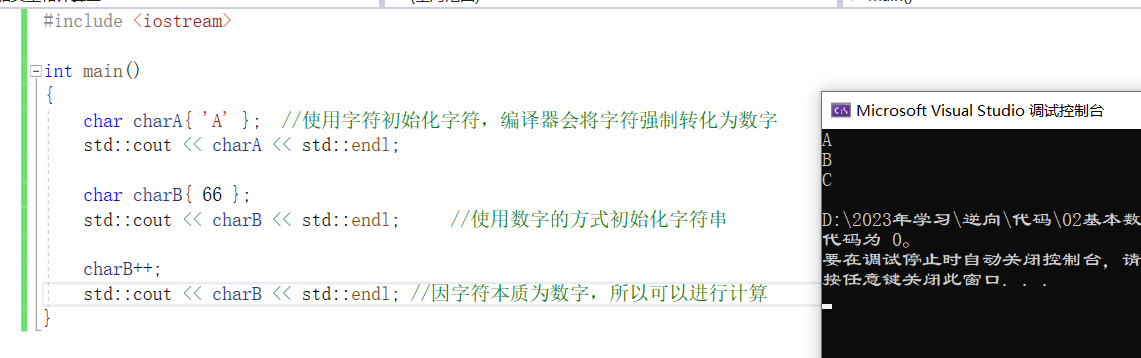
#include <iostream>
int main()
{
char charA{ 'A' }; //使用字元初始化字元,編譯器會將字元強制轉化為數字
std::cout << charA << std::endl;
char charB{ 66 };
std::cout << charB << std::endl; //使用數字的方式初始化字元串
charB++;
std::cout << charB << std::endl; //因字元本質為數字,所以可以進行計算
}
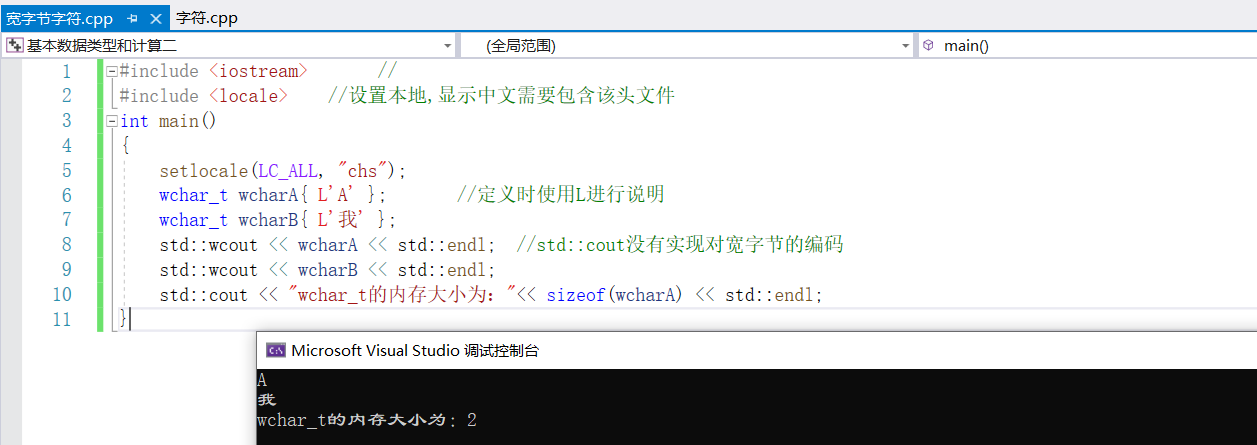
②wchar_t類型
該類型占用兩個位元組(無論是漢字、數字、字元),因編譯器不同,占用的位元組數不同(2位元組或4位元組),定義字元時要通過L來說明字元是一個寬位元組字元
#include <iostream> //
#include <locale> //設置本地,顯示中文需要包含該頭文件
int main()
{
setlocale(LC_ALL, "chs");
wchar_t wcharA{ L'A' }; //定義時使用L進行說明
wchar_t wcharB{ L'我' };
std::wcout << wcharA << std::endl; //std::cout沒有實現對寬位元組的編碼
std::wcout << wcharB << std::endl;
std::cout << "wchar_t的記憶體大小為:"<< sizeof(wcharA) << std::endl;
}
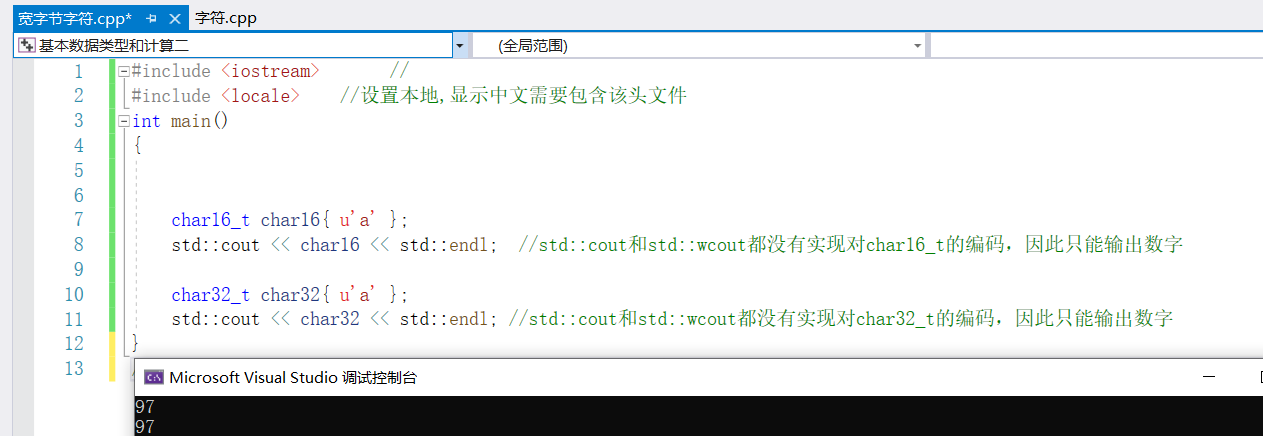
④char32_t、char16_t
為實現跨平臺的應用,引入了char32_t、char16_t,因為wchar_t因平臺不同占用的記憶體不同
#include <iostream> //
#include <locale> //設置本地,顯示中文需要包含該頭文件
int main()
{
char16_t char16{ u'a' };
std::cout << char16 << std::endl; //std::cout和std::wcout都沒有實現對char16_t的編碼,因此只能輸出數字
char32_t char32{ u'a' };
std::cout << char32 << std::endl; //std::cout和std::wcout都沒有實現對char32_t的編碼,因此只能輸出數字
}
3)ASCII編碼表
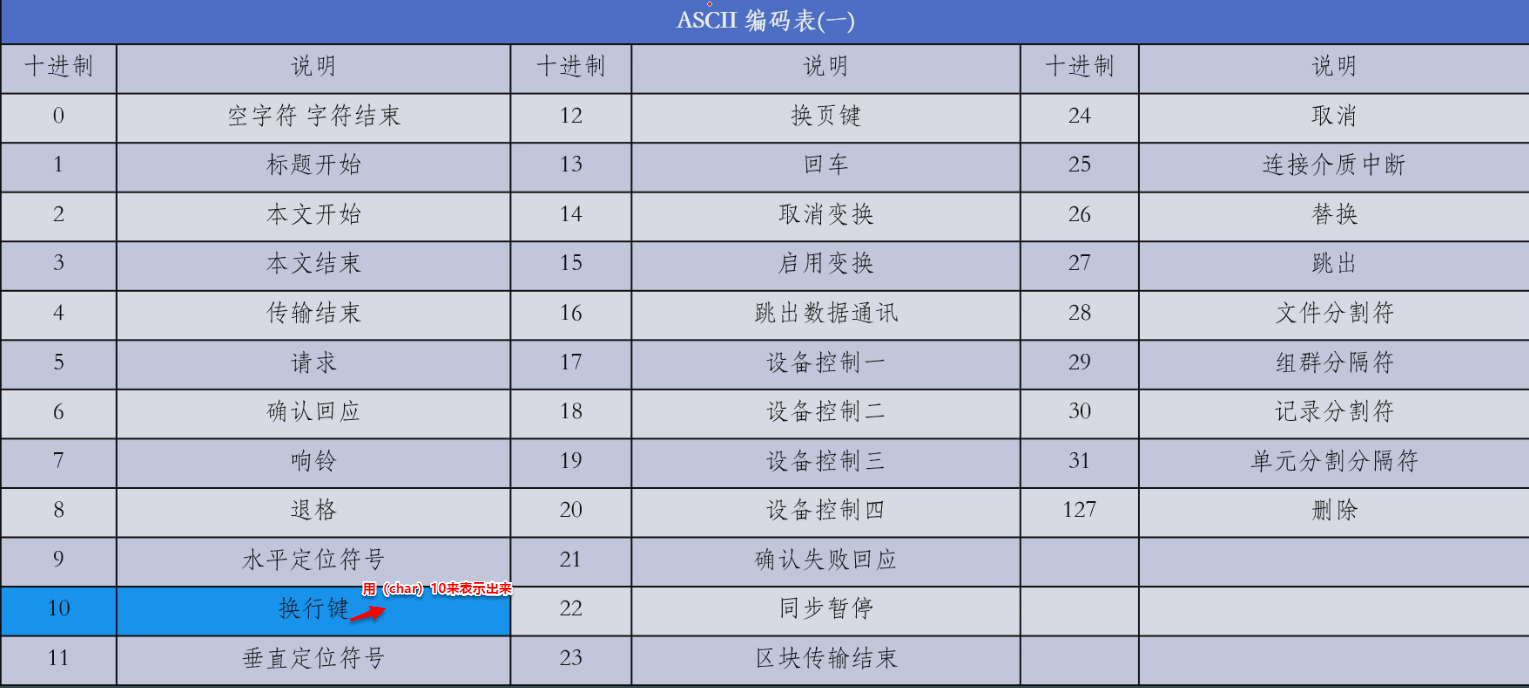
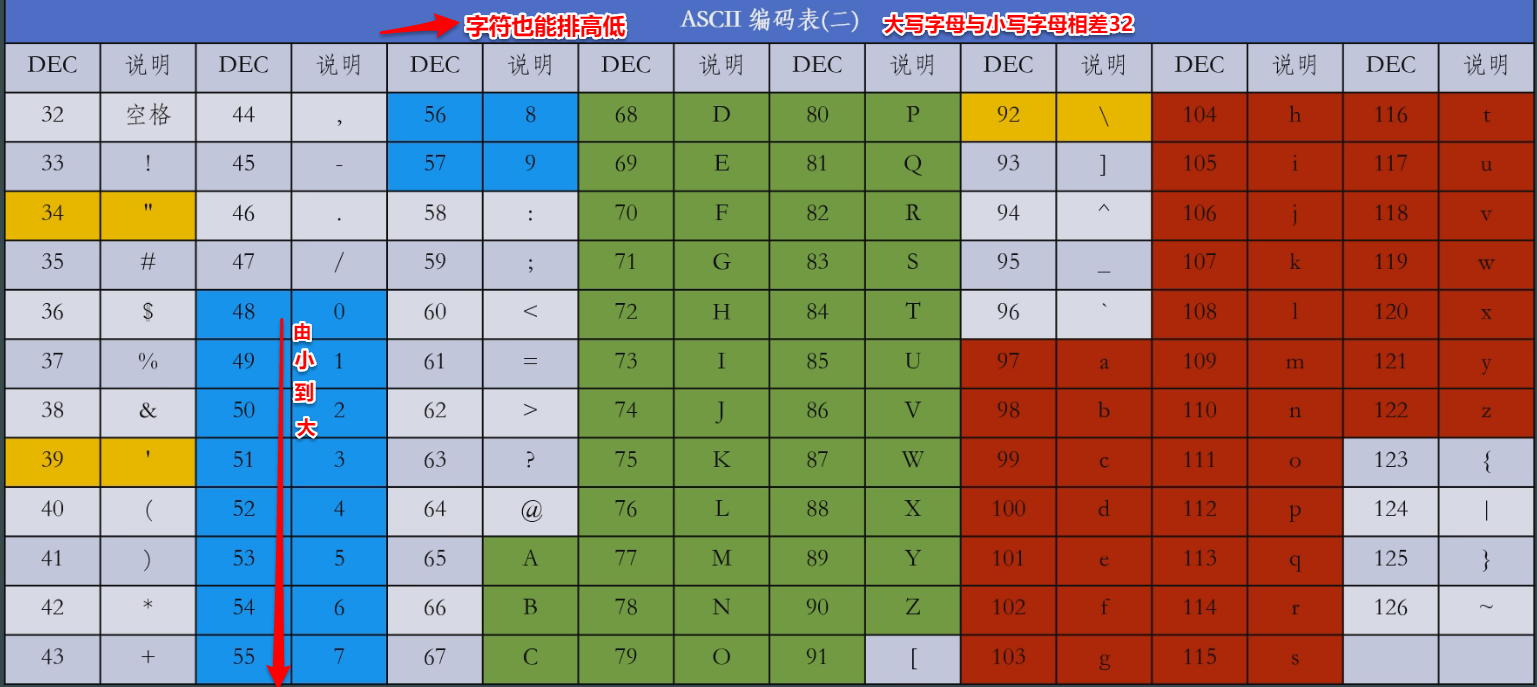
換行可以使用char(10)表示
//換行
#include <iostream>
int main()
{
std::cout << "Hello World!!" << char(10);
}
4)練習:用戶輸入一個小寫字母,轉化為大寫字母後輸出
//用戶輸入一個小寫字母,轉化為大寫字母後輸出
#include <iostream>
int main()
{
char userIn;
std::cout << "請輸入一個小寫字母:";
std::cin >> userIn;
userIn -= 32;
std::cout << "轉化後的大寫字母為:" << userIn << std::endl;
}
2、推斷類型
即不告訴編譯器使用什麼數據類型
1)auto類型
| 類型定義語法 | 示例 |
|---|---|
| auto 變數名 {初始值}; | auto a {200}; |
註:auto類型的變數必須初始化,負責編譯器無法判斷是什麼類型的變數
2)查看變數的類型
| 變數類型查看函數 | |
|---|---|
| typeid(變數).name |
#include <iostream>
int main()
{
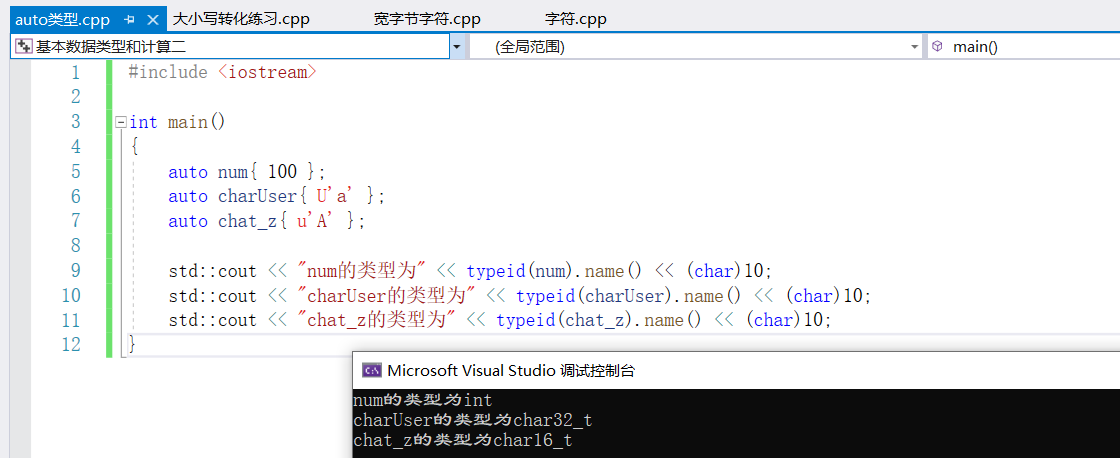
auto num{ 100 };
auto charUser{ U'a' }; //auto類型的變數必須初始化
auto chat_z{ u'A' };
std::cout << "num的類型為" << typeid(num).name() << (char)10;
std::cout << "charUser的類型為" << typeid(charUser).name() << (char)10;
std::cout << "chat_z的類型為" << typeid(chat_z).name() << (char)10;
}
註:日常不推薦使用auto類型,因為代碼閱讀性不好
3、格式化輸出流及轉義
1)格式化輸出流操作
作用:使用文字輸出更美化
註:加粗內容需要使用頭文件<iomanip>
| 格式化輸出流 | 含義 | 示例 |
|---|---|---|
| std::fixed | 以小數點模式輸出浮點數 | 3.1415926 |
| std::scientific | 以科學計數法輸出小數 | 3E100 |
| std::defaultfloat | 恢復預設的小數輸出,即將上述2個設置取消 | |
| std::setprecision(int) | 設置小數精度 | std::setprecision(2),輸出3.14 |
| std::dec | 以後輸出的數字採用十進位輸出 | 999 |
| std::hex | 以後輸出的數字採用十六進位輸出 | FFF |
| set::oct | 以後輸出的數字採用八進位輸出 | 777 |
| std::showbase | 十六進位和八進位顯示首碼 | 0xFF |
| std::shownobase | 關閉十六進位和八進位顯示首碼 | |
| std::setw(int) | 把輸出內容設置寬度,每次都需設置 | std::setw(10)輸出 999 |
| std::setfill(char) | 當顯示寬度超過字元快寬度時,用指定字元串填充剩餘內容 | **************999 |
| std::left | 設置字元對其模式為左對齊 | |
| std::right | 設置字元對其模式為右對齊 |
//格式化輸出及轉義
#include <iostream>
#include <iomanip>
int main() {
std::cout << std::fixed; //以小數點計數
std::cout << 3.1415926 << (char)10;
std::cout << std::scientific;//以科學計數法技術
std::cout << 3.1415926 << char(10);
std::cout << std::setprecision(2); //設置小數精度
std::cout << 3.1415926 << std::endl;
std::cout << std::hex; //以16進位輸出
std::cout << 100 << std::endl;
std::cout << std::oct; //以8進位輸出
std::cout << 100 << std::endl;
std::cout << std::dec; //以10進位輸出
std::cout << 100 << char(10);
std::cout<<std::setw(10) << 2222 << std::endl; //設置輸出寬度
//當顯示寬度超過字元寬度時,剩餘部分使用特定字元填充
std::cout << std::setfill('*') << std::setw(10) << 999 << std::endl; //
std::cout << std::right; //右對齊
std::cout << "helloworld" << std::endl;
}
//輸出內容

2)轉義
| 轉義序列 | 作用 |
|---|---|
| \n | 換行 |
| \\ | \ |
| ' | ' |
| \t | 製表符 |
| " | " |
| ? | ? |
| \b | 退格 |
| \a | 警告聲 |
4、運算優先順序
1)運算優先表
註:下表運算符從上到下依次優先運算
| 運算符 | 關聯性 |
|---|---|
| :: | 左(從左往右計算) |
| () [] -> . 尾碼++ 首碼-- typeid const_cast dynamic_cast static_cast reinterpret_cast | 左(從左往右計算) |
| ! ~ 一元+ 一元- 首碼++ 首碼-- & * (類型)sizeof new new[] delete delete[] | 右(從右往左計算) |
| .* ->* | 左(從左往右計算) |
| * / % | 左(從左往右計算) |
| + - | 左(從左往右計算) |
| << >> | 左(從左往右計算) |
| < <= > >= | 左(從左往右計算) |
| == != | 左(從左往右計算) |
| & | 左(從左往右計算) |
| ^ | 左(從左往右計算) |
| | | 左(從左往右計算) |
| && | 左(從左往右計算) |
| || | 左(從左往右計算) |
| ? : op= | 右(從右往左計算) |
| throw | 右(從右往左計算) |
| . | 左(從左往右計算) |
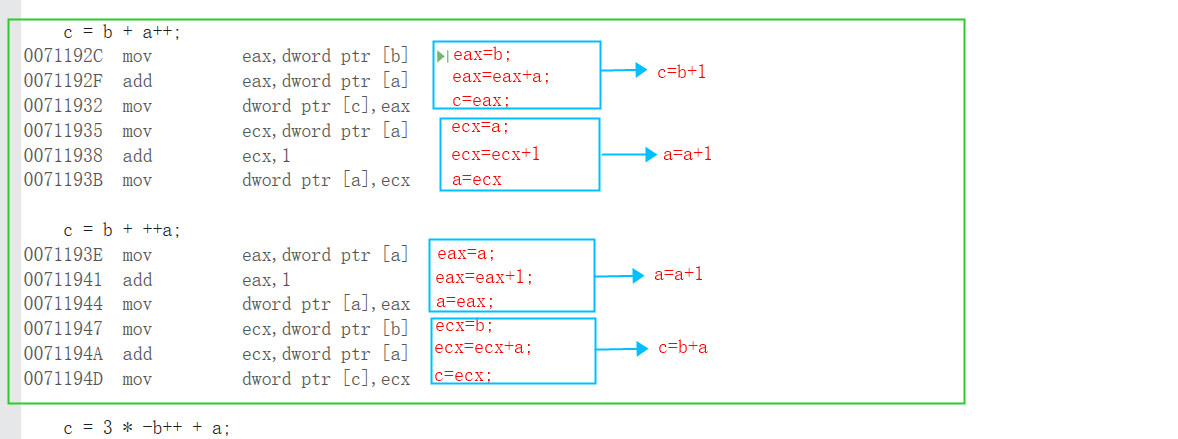
2)a++和++a的反彙編
#include <iostream>
int main()
{
int a{ 10 };
a++;
++a;
int b{ 5 };
int c{};
c = b + a++; //c=b+a;a=a+1 //尾碼優先
c = b + ++a; //a=a+1;c=b+a
c = 3 * -b++ + a; //正負在前,乘除、加減在後
std::cout << c << std::endl;
c = 2 * -b-- - a;
std::cout << c << std::endl;
}
①查看彙編的方法:先設置斷點,調試->視窗->反彙編
②a++和++a反彙編代碼
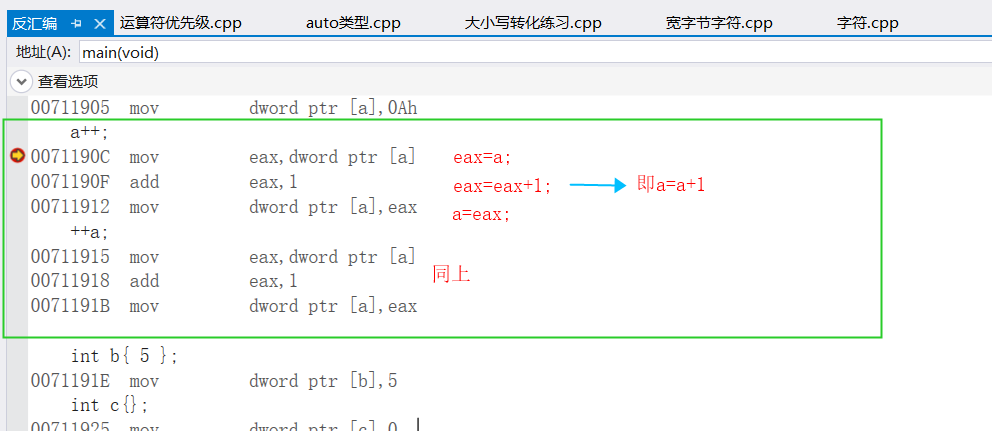
結論:++a和a++在不執行其他操作的時候,一樣
③c = b + a++和c = b + ++a彙編區別